Presentation Slides
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Syllabus for Post Graduate Programme in Music
1 Appendix to U.O.No.Acad/C1/13058/2020, dated 10.12.2020 KANNUR UNIVERSITY SYLLABUS FOR POST GRADUATE PROGRAMME IN MUSIC UNDER CHOICE BASED CREDIT SEMESTER SYSTEM FROM 2020 ADMISSION NAME OF THE DEPARTMENT: DEPARTMENT OF MUSIC NAME OF THE PROGRAMME: MA MUSIC DEPARTMENT OF MUSIC KANNUR UNIVERSITY SWAMI ANANDA THEERTHA CAMPUS EDAT PO, PAYYANUR PIN: 670327 2 SYLLABUS FOR POST GRADUATE PROGRAMME IN MUSIC UNDER CHOICE BASED CREDIT SEMESTER SYSTEM FROM 2020 ADMISSION NAME OF THE DEPARTMENT: DEPARTMENT OF MUSIC NAME OF THE PROGRAMME: M A (MUSIC) ABOUT THE DEPARTMENT. The Department of Music, Kannur University was established in 2002. Department offers MA Music programme and PhD. So far 17 batches of students have passed out from this Department. This Department is the only institution offering PG programme in Music in Malabar area of Kerala. The Department is functioning at Swami Ananda Theertha Campus, Kannur University, Edat, Payyanur. The Department has a well-equipped library with more than 1800 books and subscription to over 10 Journals on Music. We have gooddigital collection of recordings of well-known musicians. The Department also possesses variety of musical instruments such as Tambura, Veena, Violin, Mridangam, Key board, Harmonium etc. The Department is active in the research of various facets of music. So far 7 scholars have been awarded Ph D and two Ph D thesis are under evaluation. Department of Music conducts Seminars, Lecture programmes and Music concerts. Department of Music has conducted seminars and workshops in collaboration with Indira Gandhi National Centre for the Arts-New Delhi, All India Radio, Zonal Cultural Centre under the Ministry of Culture, Government of India, and Folklore Academy, Kannur. -

Applying Natural Language Processing and Deep Learning Techniques for Raga Recognition in Indian Classical Music
Applying Natural Language Processing and Deep Learning Techniques for Raga Recognition in Indian Classical Music Deepthi Peri Dissertation submitted to the Faculty of the Virginia Polytechnic Institute and State University in partial fulfillment of the requirements for the degree of Master of Science in Computer Science and Applications Eli Tilevich, Chair Sang Won Lee Eric Lyon August 6th, 2020 Blacksburg, Virginia Keywords: Raga Recognition, ICM, MIR, Deep Learning Copyright 2020, Deepthi Peri Applying Natural Language Processing and Deep Learning Tech- niques for Raga Recognition in Indian Classical Music Deepthi Peri (ABSTRACT) In Indian Classical Music (ICM), the Raga is a musical piece’s melodic framework. It encom- passes the characteristics of a scale, a mode, and a tune, with none of them fully describing it, rendering the Raga a unique concept in ICM. The Raga provides musicians with a melodic fabric, within which all compositions and improvisations must take place. Identifying and categorizing the Raga is challenging due to its dynamism and complex structure as well as the polyphonic nature of ICM. Hence, Raga recognition—identify the constituent Raga in an audio file—has become an important problem in music informatics with several known prior approaches. Advancing the state of the art in Raga recognition paves the way to improving other Music Information Retrieval tasks in ICM, including transcribing notes automatically, recommending music, and organizing large databases. This thesis presents a novel melodic pattern-based approach to recognizing Ragas by representing this task as a document clas- sification problem, solved by applying a deep learning technique. A digital audio excerpt is hierarchically processed and split into subsequences and gamaka sequences to mimic a textual document structure, so our model can learn the resulting tonal and temporal se- quence patterns using a Recurrent Neural Network. -

CARNATIC MUSIC (CODE – 032) CLASS – X (Melodic Instrument) 2020 – 21 Marking Scheme
CARNATIC MUSIC (CODE – 032) CLASS – X (Melodic Instrument) 2020 – 21 Marking Scheme Time - 2 hrs. Max. Marks : 30 Part A Multiple Choice Questions: Attempts any of 15 Question all are of Equal Marks : 1. Raga Abhogi is Janya of a) Karaharapriya 2. 72 Melakarta Scheme has c) 12 Chakras 3. Identify AbhyasaGhanam form the following d) Gitam 4. Idenfity the VarjyaSwaras in Raga SuddoSaveri b) GhanDharam – NishanDham 5. Raga Harikambhoji is a d) Sampoorna Raga 6. Identify popular vidilist from the following b) M. S. Gopala Krishnan 7. Find out the string instrument which has frets d) Veena 8. Raga Mohanam is an d) Audava – Audava Raga 9. Alankaras are set to d) 7 Talas 10 Mela Number of Raga Maya MalawaGoula d) 15 11. Identify the famous flutist d) T R. Mahalingam 12. RupakaTala has AksharaKals b) 6 13. Indentify composer of Navagrehakritis c) MuthuswaniDikshitan 14. Essential angas of kriti are a) Pallavi-Anuppallavi- Charanam b) Pallavi –multifplecharanma c) Pallavi – MukkyiSwaram d) Pallavi – Charanam 15. Raga SuddaDeven is Janya of a) Sankarabharanam 16. Composer of Famous GhanePanchartnaKritis – identify a) Thyagaraja 17. Find out most important accompanying instrument for a vocal concert b) Mridangam 18. A musical form set to different ragas c) Ragamalika 19. Identify dance from of music b) Tillana 20. Raga Sri Ranjani is Janya of a) Karahara Priya 21. Find out the popular Vena artist d) S. Bala Chander Part B Answer any five questions. All questions carry equal marks 5X3 = 15 1. Gitam : Gitam are the simplest musical form. The term “Gita” means song it is melodic extension of raga in which it is composed. -
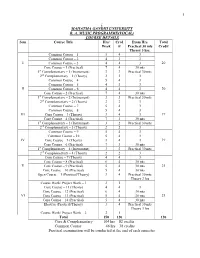
1 ; Mahatma Gandhi University B. A. Music Programme(Vocal
1 ; MAHATMA GANDHI UNIVERSITY B. A. MUSIC PROGRAMME(VOCAL) COURSE DETAILS Sem Course Title Hrs/ Cred Exam Hrs. Total Week it Practical 30 mts Credit Theory 3 hrs. Common Course – 1 5 4 3 Common Course – 2 4 3 3 I Common Course – 3 4 4 3 20 Core Course – 1 (Practical) 7 4 30 mts 1st Complementary – 1 (Instrument) 3 3 Practical 30 mts 2nd Complementary – 1 (Theory) 2 2 3 Common Course – 4 5 4 3 Common Course – 5 4 3 3 II Common Course – 6 4 4 3 20 Core Course – 2 (Practical) 7 4 30 mts 1st Complementary – 2 (Instrument) 3 3 Practical 30 mts 2nd Complementary – 2 (Theory) 2 2 3 Common Course – 7 5 4 3 Common Course – 8 5 4 3 III Core Course – 3 (Theory) 3 4 3 19 Core Course – 4 (Practical) 7 3 30 mts 1st Complementary – 3 (Instrument) 3 2 Practical 30 mts 2nd Complementary – 3 (Theory) 2 2 3 Common Course – 9 5 4 3 Common Course – 10 5 4 3 IV Core Course – 5 (Theory) 3 4 3 19 Core Course – 6 (Practical) 7 3 30 mts 1st Complementary – 4 (Instrument) 3 2 Practical 30 mts 2nd Complementary – 4 (Theory) 2 2 3 Core Course – 7 (Theory) 4 4 3 Core Course – 8 (Practical) 6 4 30 mts V Core Course – 9 (Practical) 5 4 30 mts 21 Core Course – 10 (Practical) 5 4 30 mts Open Course – 1 (Practical/Theory) 3 4 Practical 30 mts Theory 3 hrs Course Work/ Project Work – 1 2 1 Core Course – 11 (Theory) 4 4 3 Core Course – 12 (Practical) 6 4 30 mts VI Core Course – 13 (Practical) 5 4 30 mts 21 Core Course – 14 (Practical) 5 4 30 mts Elective (Practical/Theory) 3 4 Practical 30 mts Theory 3 hrs Course Work/ Project Work – 2 2 1 Total 150 120 120 Core & Complementary 104 hrs 82 credits Common Course 46 hrs 38 credits Practical examination will be conducted at the end of each semester 2 MAHATMA GANDHI UNIVERSITY B. -

CARNATIC MUSIC (CODE – 032) CLASS – X (Melodic Instrument) 2020 – 21 Sample Question Paper
CARNATIC MUSIC (CODE – 032) CLASS – X (Melodic Instrument) 2020 – 21 Sample Question Paper Time - 2 hrs. Max. Marks : 30 Part A Multiple Choice Questions: Attempts any of 15 Question all are of Equal Marks : 1. Raga Abhogi is Janya of a) Karaharapriya b) NataBhiravi c) HariKambhoji d) DheeraSankaraBharanam 2. 72 Melakarta Scheme has a) 6 Chakaras b) 9 Chakras c) 12 Chakras d) 36 Chakras 3. Identify AbhyasaGhanam form the following a) Kriti b) Raga Malika c) Tillana d) Gitam 4. Idenfity the VarjyaSwaras in Raga SuddoSaveri a) Madhyama – Nisha Dam b) GhanDharam – NishanDham c) NishaDham- Rishabam d) Dhaviatam – Nadgtanan 5. Raga Harikambhoji is a a) Audava Raga b) Shadava Raga c) Bhashanga Raga d) Sampoorna Raga 6. Identify popular vidilist from the following a) S BalaChander b) M. S. Gopala Krishnan c) G. N. BalaSubrmanyam d) PopanasamSiram 7. Find out the string instrument which has frets a) Violin b) Thanpur c) Sarangi d) Veena 8. Raga Mohanam is an a) Audav-Shadava Raga b) Shadava – Audava Raga c) Janaka- Raga d) Audava – Audava Raga 9. Alankaras are set to a) 9 Talas b) 5 Talas c) 6 Talas d) 7 Talas 10 .Mela Number of Raga Maya MalawaGoula a) 22 b) 28 c) 20 d) 15 11. Identify the famous flutist a) LalgadiJayaraman b) Papanaseem Sivan c) S. BalaChander d) T R. Mahalingam 12. RupakaTala has AksharaKals a) 3 b) 6 c) 9 d) 12 13. Indentify composer of Navagrehakritis a) Balamurali Krishna b) KoliswaraIyer c) MuthuswaniDikshitan d) G. N. Balasubramanam 14. Essential angas of kriti are a) Pallavi-Anuppallavi- Charanam b) Pallavi –multifplecharanma c) Pallavi – MukkyiSwaram d) Pallavi – Charanam 15. -

Carnatic Music Theory Year I
CARNATIC MUSIC THEORY YEAR I BASED ON THE SYLLABUS FOLLOWED BY GOVERNMENT MUSIC COLLEGES IN ANDHRA PRADESH AND TELANGANA FOR CERTIFICATE EXAMS HELD BY POTTI SRIRAMULU TELUGU UNIVERSITY ANANTH PATTABIRAMAN EDITION: 2.6 Latest edition can be downloaded from https://beautifulnote.com/theory Preface This text covers topics on Carnatic music required to clear the first year exams in Government music colleges in Andhra Pradesh and Telangana. Also, this is the first of four modules of theory as per Certificate in Music (Carnatic) examinations conducted by Potti Sriramulu Telugu University. So, if you are a music student from one of the above mentioned colleges, or preparing to appear for the university exam as a private candidate, you’ll find this useful. Though attempts are made to keep this text up-to-date with changes in the syllabus, students are strongly advised to consult the college or univer- sity and make sure all necessary topics are covered. This might also serve as an easy-to-follow introduction to Carnatic music for those who are generally interested in the system but not appearing for any particular examination. I’m grateful to my late guru, veteran violinist, Vidwan. Peri Srirama- murthy, for his guidance in preparing this document. Ananth Pattabiraman Editions First published in 2009, editions 2–2.2 in 2017, 2.3–2.5 in 2018, 2.6 in 2019. Latest edition available at https://beautifulnote.com/theory Copyright This work is copyrighted and is distributed under Creative Commons BY-NC-ND 4.0 license. You can make copies and share freely. -

Department of Indian Music Name of the PG Degree Program
Department of Indian Music Name of the PG Degree Program: M.A. Indian Music First Semester FPAC101 Foundation Course in Performance – 1 (Practical) C 4 FPAC102 Kalpita Sangita 1 (Practical) C 4 FPAC103 Manodharma Sangita 1 (Practical) C 4 FPAC114 Historical and Theoretical Concepts of Fine Arts – 1 C 4 ( Theory) FPAE101 Elective Paper 1 - Devotional Music - Regional Forms of South India E 3 (Practical) FPAE105 Elective Paper 2 - Compositions of Muttusvami Dikshitar (Practical) E 3 Soft Skills Languages (Sanskrit and Telugu)1 S 2 Second Semester FPAC105 Foundation Course in Performance – 2 (Practical) C 4 FPAC107 Manodharma Sangita 2 (Practical) C 4 FPAC115 Historical and Theoretical Concepts of Fine Arts – 2 ( Theory) C 4 FPAE111 Elective Paper 3 - Opera – Nauka Caritram (Practical) E 3 FPAE102 Elective Paper 4 - Nandanar caritram (Practical) E 3 FPAE104 Elective Paper 5 – Percussion Instruments (Theory) E 3 Soft Skills Languages (Kannada and Malayalam)2 S 2 Third Semester FPAC108 Foundation Course in Performance – 3 (Practical) C 4 FPAC106 Kalpita Sangita 2 (Practical) C 4 FPAC110 Alapana, Tanam & Pallavi – 1 (Practical) C 4 FPAC116 Advanced Theory – Music (Theory) C 4 FPAE106 Elective Paper 6 - Compositions of Syama Sastri (Practical) E 3 FPAE108 Elective Paper 7 - South Indian Art Music - An appreciation (Theory) E 3 UOMS145 Source Readings-Selected Verses and Passages from Tamiz Texts ( S 2 Theory) uom1001 Internship S 2 Fourth Semester FPAC117 Research Methodology (Theory) C 4 FPAC112 Project work and Viva Voce C 8 FPAC113 Alapana, -

Narada Gana Lola
nArada gAna lOla Ragam: Atana { 29th Melakartha Shankarabharanam Janyam} https://en.wikipedia.org/wiki/Atana ARO: S R₂ M₁ P N₂ Ṡ || AVA: Ṡ N₂ D₂ P M₁ P G₃ R₂ S || Talam: Rupakam Composer: Tyagaraja Version: Peri Sriramamurthy Lyrics & Meanings Courtesy: Tyagaraja Vaibhavam http://thyagaraja- vaibhavam.blogspot.com/2008/04/thyagaraja-kriti-narada-gana-raga.html Youtube Class / Lesson: https://www.youtube.com/watch?v=BGLXdVK7uPM MP3 Class / Lesson: http://www.shivkumar.org/music/naradaganalola -class.mp3 Pallavi: nArada gAna lOla nata jana paripAla Anupallavi: nIrada sama nIla nirupama guNa SIla (nArada) caraNam: nIvu lEka(y)E tanuvulu niratamugA naDucunu nIvu lEka(y)E taruvulu nikkamugA molucunu nIvu lEka(y)E vAnalu nityamugA kuriyunu nIvu lEka tyAgarAju nI guNamulan(e)Tu pADunu (nArada) Meaning Courtesy: Thyagaraja Vaibhavam: http://thyagaraja- vaibhavam.blogspot.com/2008/04/thyagaraja-kriti-narada-gana-raga.html P: O Lord who enjoys (lOla) the songs (gAna) of sage nArada! O Nourisher (paripAla) of those (jana) who supplicate (nata)! A: O Dark-blue-hued (nIla) like (sama) the rain cloud (nIrada)! O Lord with peerless (nirupama) virtuous (guNa) disposition (SIla)! O Lord who enjoys the songs of sage nArada! O Nourisher of those who supplicate! C: Without (lEka) You (nIvu) which (E) (lEkayE) body (tanuvulu) (literally bodies) would ever (niratamugA) move about (naDucunu) (literally walk)? Without (lEka) You (nIvu) which (E) (lEkayE) tree (taruvulu) (literally trees) would ever grow (molucunu) so resolutely (nikkamugA)? Without (lEka) You -

Raga (Melodic Mode) Raga This Article Is About Melodic Modes in Indian Music
FREE SAMPLES FREE VST RESOURCES EFFECTS BLOG VIRTUAL INSTRUMENTS Raga (Melodic Mode) Raga This article is about melodic modes in Indian music. For subgenre of reggae music, see Ragga. For similar terms, see Ragini (actress), Raga (disambiguation), and Ragam (disambiguation). A Raga performance at Collège des Bernardins, France Indian classical music Carnatic music · Hindustani music · Concepts Shruti · Svara · Alankara · Raga · Rasa · Tala · A Raga (IAST: rāga), Raag or Ragam, literally means "coloring, tingeing, dyeing".[1][2] The term also refers to a concept close to melodic mode in Indian classical music.[3] Raga is a remarkable and central feature of classical Indian music tradition, but has no direct translation to concepts in the classical European music tradition.[4][5] Each raga is an array of melodic structures with musical motifs, considered in the Indian tradition to have the ability to "color the mind" and affect the emotions of the audience.[1][2][5] A raga consists of at least five notes, and each raga provides the musician with a musical framework.[3][6][7] The specific notes within a raga can be reordered and improvised by the musician, but a specific raga is either ascending or descending. Each raga has an emotional significance and symbolic associations such as with season, time and mood.[3] The raga is considered a means in Indian musical tradition to evoke certain feelings in an audience. Hundreds of raga are recognized in the classical Indian tradition, of which about 30 are common.[3][7] Each raga, state Dorothea -

2017 SRUTI Board of Directors………………………………………
Table of Contents From the Publications & Outreach Committee……………………... Balaji Raghothaman ....................... 1 From the President’s Desk…………………………………………….Nari Narayanan .......................... 2 About the Cover………………………………………………………… ............................................... 4 2017 SRUTI Board of Directors……………………………………….. ................................................ 5 The Role of Sahityam in Sangeetam…………………………………..T. Sarada ................................... 6 Wonderful Kalyani at Thyagaraja Aradhana………………………….Dinakar Subramanian ................. 10 Vocal Concert by Amritha Murali……………………………………..Revathi Subramony ...................... 11 Enriching Outreach Experiences……………………………………..Arathi Prasad Narayan ................ 13 Towards the Modern Carnatic Instrument……………………………Balaji Raghothaman .................... 14 Not Missing a Beat - Vibrations Concert Review…………………….Pitchumani Sivakumar ................. 18 Fitting a Square Peg in a Round Hole?...............................................Sanjana Narayanan..................... 19 A pleasing musical garden – Padma Sugavanam in Concert………..Balaji Raghothaman ..................... 20 Shijith and Parvathy……………………………………………………Sunanda Gandham ...................... 22 Sruti Bharatanatyam Performance……………………………………. Eesha Ampani .......................... 23 What is in a raga – vadi or vivadi?........................................................ Dr. P. Swaminathan .................. 24 Down (USB) Memory lane…………………………………………….Dinakar Subramanian ................. 26 -

The Journal of the Music Academy Devoted to the Advancement of the Science and Art of Music
ISSN. 0970 -3101 THE JOURNAL OF THE MUSIC ACADEMY DEVOTED TO THE ADVANCEMENT OF THE SCIENCE AND ART OF MUSIC Vol. LXVI 1995 »T5CtCT w qrafor w fagffa w * II "/ dwell not in Vaikuntha, nor in the hearts o f Yogins nor in the Sun; (but) where my bhaktas sing, there be I, NaradaV' Edited by T.S. PARTHASARATHY The Music Academy, Madras 306, T.T.K. Road, Madras - 600 014. Annual Subscript sign $ 3-00 THE JOURNAL OF THE MUSIC ACADEMY DEVOTED TO THE ADVANCEMENT OF THE SCIENCE AND ART OF MUSIC Vol. LXVI 1995 t TOTfiT 1 V f t I *nr nurfer w ftgrfir h r * n "I dwell not in Vaikuntha, nor in the hearts o f Yogins nor in the Sun; (but) where my bhaktas sing, there be I, Narada!" Edited by T.S. PARTHASARATHY The Music Academy, Madras 306, T.T.K. Road, Madras - 600 014. Annual Subscription - Inland oreign $ 3-00 r OURSELVES This Journal is published as an Annual. All correspondence relating to the Journal should be sent to The Editor Journal of the Music Academy, 306, T.T.K. Road, Madras - 600 014. Articles on music and dance are accepted for publication on the understanding that they are contributed solely to the Journal of the Music Academy. Manuscripts should be legibly written or, preferably, typewritten (double -spaced and on one side of the paper only) and should be signed by the writer (giving his or her address in full). The Editor of the Journal is not responsible for the views expressed by contributors in their articles. -

Shri Mahaganapatim Bhajeham Ragam: Atana (29Th Mela
shrI mahAgaNapatim bhajEham Ragam: Atana (29th Mela Shankarabharanam Janyam): http://en.wikipedia.org/wiki/Atana ARO: S R2 M1 P N2 S || AVA: S N3 D2 , N2 P M1 P G2 , R2 S || Talam: Adi Composer: HH Jayachamaraja Wodeyar Version: Radha & Jayalakshmi (Soolamangalam Sisters) Lyrics Courtesy: Meena Pallavi: shrI mahAgaNapatim bhajEham shivAtmajam SaNmukhAgrajam Anupallavi : shrta gaNasEvitam vighna nAshakam shIgra vara prasAda dAyakam (madhyamakAlam): sadayam kapila muni varadAyakam guru sEva shaktam hErambam Charanam 1: jnAna mudrAlankrtam mUlAdhAra nivAsinam Charanam 2: gajAraNya vAsinam jyOtirmayam upaniSad sAram panca bhUtAtmakam sindhUra priyam pancamAtanga mukham Charanam 3: kAmEsha nayanA hlAdakam nAgalinga vara putram shrI vidyA cit-prabhAnanda rAja yOgIndram sannutam (or vanditam) ciTTasvara: S, Snpdnpmp g,-mrs |r,, s rs, r, -m, -p, -n || SnSR, -MRS nRSn, S-d, |nS,, -R nS d,, pmp-g,-mpn || Meaning: (Approximate): P: I pray (“bhajEham”) to shri mahAgaNapatim, who is the son (“Atmajam”) of Shiva, and the elder brother (“Agrajam”) of Shanmugha. A: He is worshipped (“sEvitam” by all beings (“shrta gaNa”). He destroys (“nAshakam”) obstacles (“vighna”) in our lives. He gives (“dAyakam”) boons (“vara”) and blessings (“prasAda”) very quickly (“shIgra”). C1: He is adorned (“Alankrtam”) by the symbol (“mudrA”) called Knowledge (“jnAna”). He resides in (“nivAsinam”) the mUlAdhAra chakra ( http://en.wikipedia.org/wiki/Muladhara ) kshetra in the body. C2: He lives (“vAsinam”) in the forest (“AraNya”) full of elephants (“gaja-AraNya”). He is full (“mayam”) of brightness (“jyOtir-mayam”). He is the essence (“sAram”) of the Upanishads. He is the soul (“Atmakam”) of the pancha bhutas {Akasha (Spirit/Essence), Vayu (Air), Agni (Fire), Ap (Water), and Prithvi (Earth)}.