Forecasting Short Term Demand in Heterogeneous Customer Oriented Demand Management Processes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

GAIN Report Global Agriculture Information Network
Foreign Agricultural Service GAIN Report Global Agriculture Information Network Required Report - public distribution Date: 11/19/2001 GAIN Report #ID1031 Indonesia Retail Food Sector Report 2001 Approved by: Dennis Voboril U.S. ATO Jakarta Prepared by: Kussusilowati & Fahwani Y.R. Report Highlights: The modern retail food business in Indonesia continues to grow rapidly despite the ongoing economic crisis and political uncertainty. Since the onset of the current crisis in 1997, there has been a 41% increase in the number of supermarkets and a 66% increase in minimarkets. Best market prospects for U.S. suppliers include fresh fruit, canned food, frozen french fries, potato chips, sauces & seasonings, salad dressing, snack food, beans, and pastas. Niche markets exist for frozen pizzas, frozen meat & poultry, delicatessen items, breakfast cereals, non-alcoholic beverages, tomato paste, cream cheese, confectionary, and biscuits. Includes PSD changes: No Includes Trade Matrix: No Unscheduled Report Jakarta ATO [ID2], ID GAIN Report #ID1031 Page 1 of 13 RETAIL FOOD SECTOR REPORT: INDONESIA SECTION I. MARKET SUMMARY Retail System The traditional sector still dominates the retail food business in Indonesia, but the data shown below indicates a growing trend towards the supermarket and other modern retail outlets. In 2001, an A.C. Nielsen study indicates that there were 1,903,602 retail food outlets in Indonesia. Of these outlets, 814 were supermarkets (up 41 percent since Retail Outlet Share of Market 1997), 3,051 were mini-markets (up 99 percent) 59,055 were large provision shops (no change), Warung 599,489 were small provision shops (up 66 (65.2%) Traditional Small percent), and 1,241,193 were warung provision Traditional Large shops (up 18 percent).1 Other (Supermkt & Minimkt) (0.2%) (3.1%) It is currently estimated by trade sources that 25 percent of retail food sales in Jakarta take place in supermarkets and other modern retail outlets. -

PDF-Xchange 4.0 Examples
WorldReginfo - f65a79fa-dec3-4614-8df6-74077a403cfa - WorldReginfo Annual Review 2015 Nestlé – Annual Review 2015 Our business Nestlé has grown from a company founded 150 years ago to a global leader in Nutrition, Health and Wellness. Wherever you are in What we sell (in CHF billion) the world we have safe, nutritious products to Powdered and Nutrition and Milk products Prepared dishes Liquid Beverages Health Science and Ice cream and cooking aids help you care for yourself and your family. Our product portfolio has seven categories, offering you 19.2 14.9 14.6 12.6 healthier and tastier choices at every stage of your life, at every time of the day. PetCare Confectionery Water 11.5 8.9 7.1 Our growth has enabled Where we sell (in CHF billion) us to help improve the lives of millions of people through the products EMENA and services we provide, 27.5 and through employment, our supplier networks and the contribution we make to economies around the world. AMS AOA 39.1 22.2 Number of employees Number of countries we sell in 335 000 189 Total group salaries and social Corporate taxes paid in 2015 welfare expenses (in CHF) (in CHF) 16 billion 3.3 billion WorldReginfo - f65a79fa-dec3-4614-8df6-74077a403cfa Our commitments Our 39 commitments in the Nestlé in society report guide all of us at Nestlé in our collective efforts to meet specific objectives. For a company to prosper Nutrition, health and wellness over the long term and create value for shareholders, it 192 billion 8041 must create value for society at the same time. -

Recall Retail List 030-2020
United States Food Safety Department of and Inspection Agriculture Service RETAIL CONSIGNEES FOR FSIS RECALL 030-2020 FSIS has reason to believe that the following retail location(s) received LEAN CUISINE Baked Chicken meal products that have been recalled by Nestlé Prepared Foods. This list may not include all retail locations that have received the recalled productor may include retail locations that did not actually receive the recalled product. Therefore, it is important that you use the product-specific identification information, available at https://www.fsis.usda.gov/wps/portal/fsis/topics/recalls-and-public- health-alerts/recall-case-archive/archive/2020/recall-030-2020-release, in addition to this list of retail stores, to check meat or poultry products in your possession to see if they have been recalled. Store list begins on next page United States Food Safety USDA Department of And Inspection - Agl'iculture Service Retail List for Recall Number: 030-2020 chicken meal product List Current As Of: 26-Jan-21 Nationwide, State-Wide, or Area-Wide Distribution Retailer Name Location 1 Albertsons AZ, CA, LA, NV, OR, TX, WA 2 Bashas AZ 3 Big Y CT 4 City Market CO 5 Dillons KS 6 Food Lion GA, SC, TN, VA 7 Fred Meyer OR, WA 8 Fry's Food And Drug AZ 9 Fry's Marketplace AZ 10 Gelson's Market CA 11 Giant MD, PA, VA 12 Giant Eagle Supermarket OH, PA 13 Heinen's OH 14 Hy-Vee IL, IA, KS, MN, MO, NE, SD 15 Ingles Markets GA, NC, SC, TN 16 Jay C IN 17 JewelOsco IL 18 King Soopers CO AR, GA, IL, IN, KY, MI, MS, OH, SC, TN, TX, VA, 19 Kroger WV 20 Lowes NC 21 Marianos IL 22 Meijers IL, IN, MI 23 Pavilions CA 24 Pick n Save WI 25 Piggly Wiggly WI 26 Publix FL, GA Page 1 of 85 Nationwide, State-Wide, or Area-Wide Distribution Retailer Name Location 27 Quality Food Center WA 28 Ralphs CA 29 Ralphs Fresh Fare CA 30 Randalls TX 31 Safeway AZ, CA, HI, OR, WA 32 Shaw's MA, NH 33 Smart & Final CA 34 Smith's NV, NM, UT 35 Stater Bros. -

Retail Industry
Productivity in the Service Sector: Retail Industry Recent Trends and Prospects for APO Member Countries 1 Chief Expert Toshiyuki Matsuura 2 Keio Economic Observatory, Keio University 1 We would like to thank Prof. Jonathan Haskel for helpful comments and suggestions. 2 e-Mail: [email protected] Asian Productivity Organization 0 Contributors Chief Expert Japan Prof. Toshiyuki Matsuura Assistant Professor, Keio Economic Observatory Keio University 2-15-45 Mita, Minato-ku Tokyo 108-8345 Telephone/Fax: 81-3-5427-1479 e-Mail: [email protected] National Experts India Prof. Uniyal Dwarika Prasad Dean, Chitkara Business School Chitkara University Barotiwala, Hiamchal e-Mail: [email protected] Indonesia Dr. Handito Hadi Joewono Chairman of Permanent Committee on Education, Training and Apprenticeship of Indonesia Chamber of Commerce and Industry and Chief Strategy Consultant of ARRBEY Menara Kadin Indonesia, Jl. HR. Rasuna Said X-5 Kav 2-3 Jakarta 12950 Telephone: 62-21-5274485 Fax: 62-21-53664869 e-Mail: [email protected] Republic of Korea Dr. Keun Hee Rhee Senior Researcher Korea Productivity Center 122-1 Jeokseon-dong, Jongro-ku Seoul 110-751 Telephone: 82-2-7241054 Fax: 82-2-7241050 e-Mail: [email protected] Malaysia Mr. Ramli Idris Associate Consultant Quest Consulting Group 9-5 Jalan 8/146, Bandar Tasik Selatan, Sg. Besi, 57000 Kuala Lumpur e-Mail: [email protected] Thailand Ms. Suchira Simma Decision Support System Assistant Department Manager CP. Seven Eleven Public Co., Ltd. Sibunruang 1 Bldg., 6th Floor, 283 Silom Road, Bangrak Bangkok 10500 Telephone: 66-2-6771305 Fax: 66-2-6311446 Asian Productivity Organization 1 e-Mail: [email protected] Mr. -

Dumex Thailand Thailand
DumexDumex Thailand Thailand INTRODUCTION September 12, 2003 by Gerard Geraets Managing Director, Dumex Ltd. IndexIndex Who are we ? Milestones and Highlights Market and Competition Critical Factors Growth Opportunities Critical Success Factors Recall and Recovery Outlook 2 WhoWho areare wewe ?? OrganizationOrganization ChartChart Gerard Geraets Managing Director Wanna Swuddigul Steve Donnelly Morten S. Knudsen Likhit Somboon Regional Financial Marketing Director Operations Manager HR Director Controller Wisanti Lomtakul Pisit Pittayanurak Deputy Financial Controller Sales Director Production/Technical Modern Trade Finance Marketing QA & QC/R&D HR General Trade Admin. Nutrition Supply Chain Training Trade Marketing IT Warehousing 4 GERARD GERAETS 59 years Dutch National Business Administration Nijenrode University, The Netherlands 18 years of Asian experience in Thailand, Taiwan, Singapore Extensive marketing and General Management experience with o.a. Heineken, Sara Lee and Friesland Dairy Foods Almost 7 years with Dumex as MD Dumex Ltd. Thailand 5 WANNA SWUDDIGUL 37 years Thai National Master of Business Administration, Western Illinois University, USA 9 years experience in Marketing with Consumer Products Company 2 years experience as General Manager at Fast Food business 2 years experience in Marketing with Telecommunication business 3 months with Dumex Ltd, Thailand as Marketing Director 6 STEVE DONNELLY 39 years New Zealand National Dairy Science and Technology, Massey University, New Zealand 10 years experience -

AU-Thesis-Fulltext-171148.PDF ( 4013.57 KB )
A S;fUDY OF EFFICACY OF SALES PROMOTIONS OF TOPS SUPERMARKET IN BANGKOK By PIMOLRAT KHUNVIROJPANICH I A Thesis submitted in partial fulfillment of the requirement for the degree of Master of Business Administration Examination Committee : 1. Dr. Ishwar C. Gupta (Advisor) 2. Dr. Thongdee Kijboonchoo (Member) ,{_~-..:..... 3. Dr. Sirion Chaipoopirutana (Member) "?";c"~'j 4. Dr. Jakarin Srimoon (Member) IJ ..(( 14 .. krrt?..0( 5. Assoc. Prof. Poonsak Sangsunt (MOE Representative) Examined on : 23 June 2004 Approved for Graduation on : Graduate School of Business Assumption University Bangkok, Thailand June 2004 ABSTRACT There is an intense competition in the retail business. Customers have many alternatives to select. They move away from tradition trade to modern trade such as supermarket. One of the several reasons is sales promotion tools which are used by supermarkets to attract the customers. Therefore, it is useful and interesting to study the relationship between sales promotion tools and consumers behavior response. Tops Supermarket is chosen for this study. The research problem for this study is "What is the relationship between sales promotion tools and consumer behavior". The objective of this research is to find out the relationship of four different sales promotion tools which are coupon, price discount, buy-one-get-one-free, and premium, with four different consumer behavior responses which are brand switching, brand loyalty, stockpiling, and purchase acceleration. The research instrument was administered 400 respondents, both male and female which were completed by the target population who have experienced in shopping at Tops Supermarket. After data were collected from respondents, the data were processed by SPSS program. -

Annual Report for 2016
NESTLÉ INDIA LIMITED (CIN: L15202DL1959PLC003786) Registered Office: M-5A, Connaught Circus, New Delhi - 110 001 Email: [email protected], Website: www.nestle.in Phone: 011-23418891, Fax: 011-23415130 NOTICE NOTICE IS HEREBY GIVEN THAT THE FIFTY EIGHTH ANNUAL GENERAL MEETING OF NESTLÉ INDIA LIMITED will be held at Air Force Auditorium, Subroto Park, New Delhi – 110 010 on Thursday, 11th May, 2017 at 10:00 a.m. to transact the following business: ORDINARY BUSINESS: 1. To receive, consider and adopt the Financial Statements of the Company for the year 2016 including audited Balance Sheet as at 31st December, 2016, the Statement of Profit and Loss and Cash Flow Statement for the year ended on that date and the Reports of the Board of Directors and Auditors thereon. 2. To confirm the payment of three Interim Dividends aggregating to` 40 per equity share and to declare a Final Dividend on Equity Shares for the financial year ended 31st December, 2016. 3. To appoint a Director in place of Mr. Shobinder Duggal (DIN 00039580), who retires by rotation and, being eligible, offers himself for re-appointment. 4. To consider and, if thought fit, to pass with or without modification(s), the following Resolution as an Ordinary Resolution: “RESOLVED THAT pursuant to the provisions of Sections 139, 142 and other applicable provisions, if any, of the Companies Act, 2013, and the Companies (Audit and Auditors) Rules, 2014 (including any statutory modification(s) or re-enactment thereof, for the time being in force), M/s. BSR & Co. LLP, Chartered Accountants (ICAI Registration No.: 101248W/ W-100022), be and is hereby appointed as the Statutory Auditors of the Company, in place of M/s. -
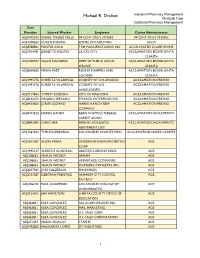
Additional Case Information
Michael R. Drobot Industrial Pharmacy Management MediLab Corp California Pharmacy Management Case Number Injured Worker Employer Claims Administrator ADJ7472102 ISMAEL TORRES VALLE 99 CENT ONLY STORES 99 CENT ONLY STORES ADJ1308567 CURTIS RIGGINS EMPIRE DISTRIBUTORS ACCA ADJ8768841 MARTIN AVILA TRM MANUFACTURING INC ACCELERATED CLAIMS IRVINE ADJ7014781 JEANETTE WILSON LA COUNTY ACCLAMATION 802108 SANTA CLARITA ADJ7200937 SUSAN NAVARRO DEPT OF PUBLIC SOCIAL ACCLAMATION 802108 SANTA SERVICE CLARITA ADJ8009655 MARIA PAEZ RUSKIN DAMPERS AND ACCLAMATION 802108 SANTA LOUVERS CLARITA ADJ1993776 ROBERTA VILLARREAL COUNTY OF LOS ANGELES ACCLAMATION FRESNO ADJ1993776 ROBERTA VILLARREAL COUNTY OF LOS ACCLAMATION FRESNO ANGELES/DPSS ADJ7117844 TOMMY ROBISON CITY OF MARICOPA ACCLAMATION FRESNO ADJ8162473 ONORIO SERRANO ESPARZA ENTERPRISES INC ACCLAMATION FRESNO ADJ8420600 JORGE LOZANO HARRIS RANCH BEEF ACCLAMATION FRESNO COMPANY ADJ8473212 DAREN HANDY KERN SCHOOLS FEDERAL ACCLAMATION SACRAMENTO CREDIT UNION ADJ8845092 CHAO HER FRESNO MOSQUITO ACCLAMATION SACRAMENTO ABATEMENT DIST ADJ1361532 THELMA JENNINGS LOS ANGELES COUNTY/DPSS ACCLAMATION SANTA CLARITA ADJ1611037 ALICIA MORA ANDERSON BARROWS METALS ACE CORP ADJ1995137 ALBERTO GUNDRAN ABLESTIK LABORATORIES ACE ADJ208633 SHAUN WIDNEY AMPAM ACE ADJ208633 SHAUN WIDNEY AMPAM RCR COMPANIES ACE ADJ208633 SHAUN WIDNEY PLUMBING CONCEPTS INC ACE ADJ2237965 JOSE CALDERON FMI EXPRESS ACE ADJ2353287 DEBORAH PRENTICE ANAHEIM CITY SCHOOL ACE DISTRICT ADJ246218 PAUL LIGAMMARI LOS ANGELES COLLEGE OF ACE CHIROPRACTIC -

Factors Affecting the Level of Trust and Commitment in Tops Supermarket Supply Chain Management, Bangkok
California State University, San Bernardino CSUSB ScholarWorks Theses Digitization Project John M. Pfau Library 2008 Factors affecting the level of trust and commitment in Tops Supermarket supply chain management, Bangkok Kamolchanok Saisomboon Follow this and additional works at: https://scholarworks.lib.csusb.edu/etd-project Part of the Business Administration, Management, and Operations Commons Recommended Citation Saisomboon, Kamolchanok, "Factors affecting the level of trust and commitment in Tops Supermarket supply chain management, Bangkok" (2008). Theses Digitization Project. 3356. https://scholarworks.lib.csusb.edu/etd-project/3356 This Project is brought to you for free and open access by the John M. Pfau Library at CSUSB ScholarWorks. It has been accepted for inclusion in Theses Digitization Project by an authorized administrator of CSUSB ScholarWorks. For more information, please contact [email protected]. FACTORS AFFECTING THE LEVEL OF TRUST AND COMMITMENT IN TOPS SUPERMARKET SUPPLY CHAIN MANAGEMENT, BANGKOK A Project Presented to the Faculty of California' State University, San Bernardino In Partial Fulfillment of the Requirements for the Degree Master of Business Administration by I Kamolchanok Saisomboon June 2008 FACTORS AFFECTING THE LEVEL OF TRUST AND COMMITMENT IN TOPS SUPERMARKET SUPPLY CHAIN MANAGEMENT, BANGKOK A Project Presented to the Faculty of California State University, San Bernardino by Kamolchanok Saisomboon . June 2008 Approved by: Decision Sciences Dr. Tapie Rohm __ Dr. Walter Stewart, Jr., Department Chair, Information and Decision Sciences ABSTRACT Trust is one of the most important aspects in successful supply chain relationship. It is the aspect that encourages commitment in the relationship. A supply chain relationship which lacks of trust and commitment may affect the performance of partners which in turn results in high-cost or even lost of current suppliers or customers. -

Transformational Challenge Nestlé 1990–2005
I wanted to stimulate your creative thinking and give Our goal is to earn consumers’ trust as their preferred you a more in-depth feeling of some of the resources Food, Beverage, Nutrition, Health and Wellness Company available in the Group, which are not always suffi ciently both for their own needs and those of their family mem- exploited. We have therefore again organised, not only bers, including their pets. We understand consumers’ the very much appreciated Product Exhibition, but also Nestlé 1990–2005 Challenge Transformational nutritional and emo- a visit to IMD, where we will be exposed to the latest tional needs/prefer- thinking on relevant business issues seen from the aca- TTransformational ransformational ences and provide demic point of view. A visit to our Research Centre at CChallenge hallenge them with innova- Lausanne, which, by the way, celebrates its 10th anni- tive branded prod- versary, will give you the opportunity to get a better idea NNestléestlé 11990–2005990–2005 ucts and services of how those 650 people can help you to achieve a AAlbertlbert PPfifi fffnerfner based on superior higher degree of competitiveness in the market place. HHans-Jörgans-Jörg RRenkenk science and technol- But before starting on the specifi c issues, let me make ogy. By serving our a preliminary remark: it is only fair that I should explain consumers and im- to you how most of our subjects for discussion fi t into proving their quality a broader framework, namely the development strategy of life, everywhere in of our Group. Over the past years, I have had more than the world, we ensure once the opportunity to refl ect on the shape of things profi table, sustain- to come, to use H.G. -

Consolidated Accounts of the Nestlé Group 137Th Annual Report Of
Consolidated accounts of the Nestlé Group 3 Consolidated income statement for the year ended 31st December 2003 4 Consolidated balance sheet as at 31st December 2003 6 Consolidated cash flow statement for the year ended 31st December 2003 8 Consolidated statement of changes in equity 11 Annex 11 Accounting policies 12 Financial risk management and commodity price risk management 13 Valuation methods and definitions 18 Changes in accounting policies and modification of the scope of consolidation 19 Notes 60Principal exchange rates 61 Report of the Group auditors 62 Financial information – five year review 64 Companies of the Nestlé Group 137th Annual report of Nestlé S.A. 86 Income statement for the year 2003 87 Balance sheet as at 31st December 2003 88 Annex to the annual accounts of Nestlé S.A. 88 Accounting policies 91 Notes to the annual accounts 99 Proposed appropriation of profit 100 Report of the statutory auditors 101 Agenda for the 137th Ordinary General Meeting of Nestlé S.A. 102 Important dates 2004 103 Shareholder information 1 Nestlé Consolidated accounts of the Nestlé Group Consolidated income statement for the year ended 31st December 2003 In millions of CHF Notes 2003 2002 Sales to customers 1 87 979 89 160 Cost of goods sold (37 583) (38 521) Distribution expenses (7 104) (7 112) Marketing and administration expenses (31 081) (31 379) Research and development costs (1 205) (1 208) EBITA (a) 1 11 006 10940 (a) Earnings Before Interest, Taxes and Amortisation Net other income (expenses) 2 (534) 1 686 of goodwill. Amortisation -

Thailand Summerfruit Market Overview OCTOBER 2009
Thailand Summerfruit Market Overview OCTOBER 2009 Author: Marissa Bailey Value Chain Development Officer Agribusiness Group Editor: Cynthia Mahoney Value Chain Development Leader Agribusiness Group Published by: Department of Primary Industries Farm Services Victoria Agribusiness Group Melbourne, Victoria, Australia December, 2009 © The State of Victoria, Department of Primary Industries, 2009 This publication is copyright. No part may be reproduced by any process except in accordance with the provisions of the Copyright Act 1968. Authorised by: The Victorian Government, GPO Box 4440, Melbourne, Victoria, 3000, Australia ISBN: 978-1-74217-906-3 (online) For more information about DPI visit the website at www.dpi.vic.gov.au or call the Customer Service Centre on 136 186. Also published on www.dpi.vic.gov.au/agribusiness Front Cover Image: Australian Summerfruit (DPI, 2009a) Acknowledgements: Data has been compiled by Strategic Market Analysis Team (DPI Agribusiness Group) Disclaimer This publication may be of assistance to you but the State of Victoria and its employees do not guarantee that the publication is without flaw of any kind or is wholly appropriate for your particular purposes and therefore disclaims all liability for any error, loss or other consequence which may arise from you relying on any information in this publication. i Executive Summary Key Thailand Market Facts Population 67.1 million Gross Domestic Product (GDP) AU$419.5 m Consumer expenditure AU$226,612 m Consumer expenditure on food AU$86,308 m Consumer expenditure on fruit US$3,288 m (2008) Source: Planet Retail (2009) Thailand is a rapidly developing economy. Thailand’s GDP is predicted to grow by seven percent per annum, on average, between 2002 and 2013.