Optimal Scheduling of Exoplanet Observations Via Bayesian Adaptive Exploration
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Astronomical Garden of Venus and Mars-NG915: the Pivotal Role Of
The astronomical garden of Venus and Mars - NG915 : the pivotal role of Astronomy in dating and deciphering Botticelli’s masterpiece Mariateresa Crosta Istituto Nazionale di Astrofisica (INAF- OATo), Via Osservatorio 20, Pino Torinese -10025, TO, Italy e-mail: [email protected] Abstract This essay demonstrates the key role of Astronomy in the Botticelli Venus and Mars-NG915 painting, to date only very partially understood. Worthwhile coin- cidences among the principles of the Ficinian philosophy, the historical characters involved and the compositional elements of the painting, show how the astronomi- cal knowledge of that time strongly influenced this masterpiece. First, Astronomy provides its precise dating since the artist used the astronomical ephemerides of his time, albeit preserving a mythological meaning, and a clue for Botticelli’s signature. Second, it allows the correlation among Botticelli’s creative intention, the historical facts and the astronomical phenomena such as the heliacal rising of the planet Venus in conjunction with the Aquarius constellation dating back to the earliest represen- tations of Venus in Mesopotamian culture. This work not only bears a significant value for the history of science and art, but, in the current era of three-dimensional mapping of billion stars about to be delivered by Gaia, states the role of astro- nomical heritage in Western culture. Finally, following the same method, a precise astronomical dating for the famous Primavera painting is suggested. Keywords: History of Astronomy, Science and Philosophy, Renaissance Art, Educa- tion. Introduction Since its acquisition by London’s National Gallery on June 1874, the painting Venus and Mars by Botticelli, cataloged as NG915, has remained a mystery to be interpreted [1]1. -

Lurking in the Shadows: Wide-Separation Gas Giants As Tracers of Planet Formation
Lurking in the Shadows: Wide-Separation Gas Giants as Tracers of Planet Formation Thesis by Marta Levesque Bryan In Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy CALIFORNIA INSTITUTE OF TECHNOLOGY Pasadena, California 2018 Defended May 1, 2018 ii © 2018 Marta Levesque Bryan ORCID: [0000-0002-6076-5967] All rights reserved iii ACKNOWLEDGEMENTS First and foremost I would like to thank Heather Knutson, who I had the great privilege of working with as my thesis advisor. Her encouragement, guidance, and perspective helped me navigate many a challenging problem, and my conversations with her were a consistent source of positivity and learning throughout my time at Caltech. I leave graduate school a better scientist and person for having her as a role model. Heather fostered a wonderfully positive and supportive environment for her students, giving us the space to explore and grow - I could not have asked for a better advisor or research experience. I would also like to thank Konstantin Batygin for enthusiastic and illuminating discussions that always left me more excited to explore the result at hand. Thank you as well to Dimitri Mawet for providing both expertise and contagious optimism for some of my latest direct imaging endeavors. Thank you to the rest of my thesis committee, namely Geoff Blake, Evan Kirby, and Chuck Steidel for their support, helpful conversations, and insightful questions. I am grateful to have had the opportunity to collaborate with Brendan Bowler. His talk at Caltech my second year of graduate school introduced me to an unexpected population of massive wide-separation planetary-mass companions, and lead to a long-running collaboration from which several of my thesis projects were born. -

Naming the Extrasolar Planets
Naming the extrasolar planets W. Lyra Max Planck Institute for Astronomy, K¨onigstuhl 17, 69177, Heidelberg, Germany [email protected] Abstract and OGLE-TR-182 b, which does not help educators convey the message that these planets are quite similar to Jupiter. Extrasolar planets are not named and are referred to only In stark contrast, the sentence“planet Apollo is a gas giant by their assigned scientific designation. The reason given like Jupiter” is heavily - yet invisibly - coated with Coper- by the IAU to not name the planets is that it is consid- nicanism. ered impractical as planets are expected to be common. I One reason given by the IAU for not considering naming advance some reasons as to why this logic is flawed, and sug- the extrasolar planets is that it is a task deemed impractical. gest names for the 403 extrasolar planet candidates known One source is quoted as having said “if planets are found to as of Oct 2009. The names follow a scheme of association occur very frequently in the Universe, a system of individual with the constellation that the host star pertains to, and names for planets might well rapidly be found equally im- therefore are mostly drawn from Roman-Greek mythology. practicable as it is for stars, as planet discoveries progress.” Other mythologies may also be used given that a suitable 1. This leads to a second argument. It is indeed impractical association is established. to name all stars. But some stars are named nonetheless. In fact, all other classes of astronomical bodies are named. -

Download This Article in PDF Format
A&A 562, A92 (2014) Astronomy DOI: 10.1051/0004-6361/201321493 & c ESO 2014 Astrophysics Li depletion in solar analogues with exoplanets Extending the sample, E. Delgado Mena1,G.Israelian2,3, J. I. González Hernández2,3,S.G.Sousa1,2,4, A. Mortier1,4,N.C.Santos1,4, V. Zh. Adibekyan1, J. Fernandes5, R. Rebolo2,3,6,S.Udry7, and M. Mayor7 1 Centro de Astrofísica, Universidade do Porto, Rua das Estrelas, 4150-762 Porto, Portugal e-mail: [email protected] 2 Instituto de Astrofísica de Canarias, C/ Via Lactea s/n, 38200 La Laguna, Tenerife, Spain 3 Departamento de Astrofísica, Universidad de La Laguna, 38205 La Laguna, Tenerife, Spain 4 Departamento de Física e Astronomia, Faculdade de Ciências, Universidade do Porto, 4169-007 Porto, Portugal 5 CGUC, Department of Mathematics and Astronomical Observatory, University of Coimbra, 3049 Coimbra, Portugal 6 Consejo Superior de Investigaciones Científicas, CSIC, Spain 7 Observatoire de Genève, Université de Genève, 51 ch. des Maillettes, 1290 Sauverny, Switzerland Received 18 March 2013 / Accepted 25 November 2013 ABSTRACT Aims. We want to study the effects of the formation of planets and planetary systems on the atmospheric Li abundance of planet host stars. Methods. In this work we present new determinations of lithium abundances for 326 main sequence stars with and without planets in the Teff range 5600–5900 K. The 277 stars come from the HARPS sample, the remaining targets were observed with a variety of high-resolution spectrographs. Results. We confirm significant differences in the Li distribution of solar twins (Teff = T ± 80 K, log g = log g ± 0.2and[Fe/H] = [Fe/H] ±0.2): the full sample of planet host stars (22) shows Li average values lower than “single” stars with no detected planets (60). -
![Arxiv:2105.11583V2 [Astro-Ph.EP] 2 Jul 2021 Keck-HIRES, APF-Levy, and Lick-Hamilton Spectrographs](https://docslib.b-cdn.net/cover/4203/arxiv-2105-11583v2-astro-ph-ep-2-jul-2021-keck-hires-apf-levy-and-lick-hamilton-spectrographs-364203.webp)
Arxiv:2105.11583V2 [Astro-Ph.EP] 2 Jul 2021 Keck-HIRES, APF-Levy, and Lick-Hamilton Spectrographs
Draft version July 6, 2021 Typeset using LATEX twocolumn style in AASTeX63 The California Legacy Survey I. A Catalog of 178 Planets from Precision Radial Velocity Monitoring of 719 Nearby Stars over Three Decades Lee J. Rosenthal,1 Benjamin J. Fulton,1, 2 Lea A. Hirsch,3 Howard T. Isaacson,4 Andrew W. Howard,1 Cayla M. Dedrick,5, 6 Ilya A. Sherstyuk,1 Sarah C. Blunt,1, 7 Erik A. Petigura,8 Heather A. Knutson,9 Aida Behmard,9, 7 Ashley Chontos,10, 7 Justin R. Crepp,11 Ian J. M. Crossfield,12 Paul A. Dalba,13, 14 Debra A. Fischer,15 Gregory W. Henry,16 Stephen R. Kane,13 Molly Kosiarek,17, 7 Geoffrey W. Marcy,1, 7 Ryan A. Rubenzahl,1, 7 Lauren M. Weiss,10 and Jason T. Wright18, 19, 20 1Cahill Center for Astronomy & Astrophysics, California Institute of Technology, Pasadena, CA 91125, USA 2IPAC-NASA Exoplanet Science Institute, Pasadena, CA 91125, USA 3Kavli Institute for Particle Astrophysics and Cosmology, Stanford University, Stanford, CA 94305, USA 4Department of Astronomy, University of California Berkeley, Berkeley, CA 94720, USA 5Cahill Center for Astronomy & Astrophysics, California Institute of Technology, Pasadena, CA 91125, USA 6Department of Astronomy & Astrophysics, The Pennsylvania State University, 525 Davey Lab, University Park, PA 16802, USA 7NSF Graduate Research Fellow 8Department of Physics & Astronomy, University of California Los Angeles, Los Angeles, CA 90095, USA 9Division of Geological and Planetary Sciences, California Institute of Technology, Pasadena, CA 91125, USA 10Institute for Astronomy, University of Hawai`i, -
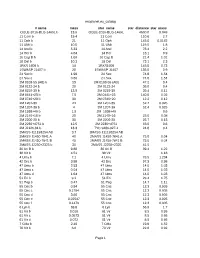
Exoplanet.Eu Catalog Page 1 # Name Mass Star Name
exoplanet.eu_catalog # name mass star_name star_distance star_mass OGLE-2016-BLG-1469L b 13.6 OGLE-2016-BLG-1469L 4500.0 0.048 11 Com b 19.4 11 Com 110.6 2.7 11 Oph b 21 11 Oph 145.0 0.0162 11 UMi b 10.5 11 UMi 119.5 1.8 14 And b 5.33 14 And 76.4 2.2 14 Her b 4.64 14 Her 18.1 0.9 16 Cyg B b 1.68 16 Cyg B 21.4 1.01 18 Del b 10.3 18 Del 73.1 2.3 1RXS 1609 b 14 1RXS1609 145.0 0.73 1SWASP J1407 b 20 1SWASP J1407 133.0 0.9 24 Sex b 1.99 24 Sex 74.8 1.54 24 Sex c 0.86 24 Sex 74.8 1.54 2M 0103-55 (AB) b 13 2M 0103-55 (AB) 47.2 0.4 2M 0122-24 b 20 2M 0122-24 36.0 0.4 2M 0219-39 b 13.9 2M 0219-39 39.4 0.11 2M 0441+23 b 7.5 2M 0441+23 140.0 0.02 2M 0746+20 b 30 2M 0746+20 12.2 0.12 2M 1207-39 24 2M 1207-39 52.4 0.025 2M 1207-39 b 4 2M 1207-39 52.4 0.025 2M 1938+46 b 1.9 2M 1938+46 0.6 2M 2140+16 b 20 2M 2140+16 25.0 0.08 2M 2206-20 b 30 2M 2206-20 26.7 0.13 2M 2236+4751 b 12.5 2M 2236+4751 63.0 0.6 2M J2126-81 b 13.3 TYC 9486-927-1 24.8 0.4 2MASS J11193254 AB 3.7 2MASS J11193254 AB 2MASS J1450-7841 A 40 2MASS J1450-7841 A 75.0 0.04 2MASS J1450-7841 B 40 2MASS J1450-7841 B 75.0 0.04 2MASS J2250+2325 b 30 2MASS J2250+2325 41.5 30 Ari B b 9.88 30 Ari B 39.4 1.22 38 Vir b 4.51 38 Vir 1.18 4 Uma b 7.1 4 Uma 78.5 1.234 42 Dra b 3.88 42 Dra 97.3 0.98 47 Uma b 2.53 47 Uma 14.0 1.03 47 Uma c 0.54 47 Uma 14.0 1.03 47 Uma d 1.64 47 Uma 14.0 1.03 51 Eri b 9.1 51 Eri 29.4 1.75 51 Peg b 0.47 51 Peg 14.7 1.11 55 Cnc b 0.84 55 Cnc 12.3 0.905 55 Cnc c 0.1784 55 Cnc 12.3 0.905 55 Cnc d 3.86 55 Cnc 12.3 0.905 55 Cnc e 0.02547 55 Cnc 12.3 0.905 55 Cnc f 0.1479 55 -

Milan Dimitrijevic Avgust.Qxd
1. M. Platiša, M. Popović, M. Dimitrijević, N. Konjević: 1975, Z. Fur Natur- forsch. 30a, 212 [A 1].* 1. Griem, H. R.: 1975, Stark Broadening, Adv. Atom. Molec. Phys. 11, 331. 2. Platiša, M., Popović, M. V., Konjević, N.: 1975, Stark broadening of O II and O III lines, Astron. Astrophys. 45, 325. 3. Konjević, N., Wiese, W. L.: 1976, Experimental Stark widths and shifts for non-hydrogenic spectral lines of ionized atoms, J. Phys. Chem. Ref. Data 5, 259. 4. Hey, J. D.: 1977, On the Stark broadening of isolated lines of F (II) and Cl (III) by plasmas, JQSRT 18, 649. 5. Hey, J. D.: 1977, Estimates of Stark broadening of some Ar III and Ar IV lines, JQSRT 17, 729. 6. Hey, J. D.: Breger, P.: 1980, Stark broadening of isolated lines emitted by singly - ionized tin, JQSRT 23, 311. 7. Hey, J. D.: Breger, P.: 1981, Stark broadening of isolated ion lines by plas- mas: Application of theory, in Spectral Line Shapes I, ed. B. Wende, W. de Gruyter, 201. 8. Сыркин, М. И.: 1981, Расчеты электронного уширения спектральных линий в теории оптических свойств плазмы, Опт. Спектроск. 51, 778. 9. Wiese, W. L., Konjević, N.: 1982, Regularities and similarities in plasma broadened spectral line widths (Stark widths), JQSRT 28, 185. 10. Konjević, N., Pittman, T. P.: 1986, Stark broadening of spectral lines of ho- mologous, doubly ionized inert gases, JQSRT 35, 473. 11. Konjević, N., Pittman, T. P.: 1987, Stark broadening of spectral lines of ho- mologous, doubly - ionized inert gases, JQSRT 37, 311. 12. Бабин, С. -

Stars and Their Spectra: an Introduction to the Spectral Sequence Second Edition James B
Cambridge University Press 978-0-521-89954-3 - Stars and Their Spectra: An Introduction to the Spectral Sequence Second Edition James B. Kaler Index More information Star index Stars are arranged by the Latin genitive of their constellation of residence, with other star names interspersed alphabetically. Within a constellation, Bayer Greek letters are given first, followed by Roman letters, Flamsteed numbers, variable stars arranged in traditional order (see Section 1.11), and then other names that take on genitive form. Stellar spectra are indicated by an asterisk. The best-known proper names have priority over their Greek-letter names. Spectra of the Sun and of nebulae are included as well. Abell 21 nucleus, see a Aurigae, see Capella Abell 78 nucleus, 327* ε Aurigae, 178, 186 Achernar, 9, 243, 264, 274 z Aurigae, 177, 186 Acrux, see Alpha Crucis Z Aurigae, 186, 269* Adhara, see Epsilon Canis Majoris AB Aurigae, 255 Albireo, 26 Alcor, 26, 177, 241, 243, 272* Barnard’s Star, 129–130, 131 Aldebaran, 9, 27, 80*, 163, 165 Betelgeuse, 2, 9, 16, 18, 20, 73, 74*, 79, Algol, 20, 26, 176–177, 271*, 333, 366 80*, 88, 104–105, 106*, 110*, 113, Altair, 9, 236, 241, 250 115, 118, 122, 187, 216, 264 a Andromedae, 273, 273* image of, 114 b Andromedae, 164 BDþ284211, 285* g Andromedae, 26 Bl 253* u Andromedae A, 218* a Boo¨tis, see Arcturus u Andromedae B, 109* g Boo¨tis, 243 Z Andromedae, 337 Z Boo¨tis, 185 Antares, 10, 73, 104–105, 113, 115, 118, l Boo¨tis, 254, 280, 314 122, 174* s Boo¨tis, 218* 53 Aquarii A, 195 53 Aquarii B, 195 T Camelopardalis, -

Lunar Occultations of Stars with Exoplanet Candidates
A&A 397, 1123–1127 (2003) Astronomy DOI: 10.1051/0004-6361:20021585 & c ESO 2003 Astrophysics Lunar occultations of stars with exoplanet candidates A. Richichi? European Southern Observatory, Karl-Schwarzschildstr. 2, 85748 Garching bei M¨unchen, Germany Received 3 September 2002 / Accepted 29 October 2002 Abstract. We investigate the potential of lunar occultations for the detection of very faint companions, and in particular for the possibility of detecting extrasolar planets. We review the basic concepts of the method, and discuss the quantities which are relevant for this particular application. The near-infrared range, and in particular the K and L bands (2.2 and 3.6 µm), offer the best dynamic range. We present results of detailed simulations based on previous experience with lunar occultation events, and taking into account a realistic noise model which includes the effects of detector, lunar background, scintillation. We conclude that lunar occultations at a large telescope (8–10 m class) can detect companions 5to 11 mag fainter than the primary, at ≈ ≈ distances of order 000: 01. The detection is highly asymmetric, with scintillation and photon noise from the central star being the limiting factor in one half-plane of the sky. Although this performance is not strictly sufficient for the direct detection of hot Jupiters, the method can nevertheless provide a valuable check with a relatively simple effort. We provide a list of lunar occultation events of candidate exoplanets visibile from the major observatories in the period 2003–2008. The method would be particularly attractive with large telescopes in the 30 to 100 m class. -

Planets and Exoplanets
NASE Publications Planets and exoplanets Planets and exoplanets Rosa M. Ros, Hans Deeg International Astronomical Union, Technical University of Catalonia (Spain), Instituto de Astrofísica de Canarias and University of La Laguna (Spain) Summary This workshop provides a series of activities to compare the many observed properties (such as size, distances, orbital speeds and escape velocities) of the planets in our Solar System. Each section provides context to various planetary data tables by providing demonstrations or calculations to contrast the properties of the planets, giving the students a concrete sense for what the data mean. At present, several methods are used to find exoplanets, more or less indirectly. It has been possible to detect nearly 4000 planets, and about 500 systems with multiple planets. Objetives - Understand what the numerical values in the Solar Sytem summary data table mean. - Understand the main characteristics of extrasolar planetary systems by comparing their properties to the orbital system of Jupiter and its Galilean satellites. The Solar System By creating scale models of the Solar System, the students will compare the different planetary parameters. To perform these activities, we will use the data in Table 1. Planets Diameter (km) Distance to Sun (km) Sun 1 392 000 Mercury 4 878 57.9 106 Venus 12 180 108.3 106 Earth 12 756 149.7 106 Marte 6 760 228.1 106 Jupiter 142 800 778.7 106 Saturn 120 000 1 430.1 106 Uranus 50 000 2 876.5 106 Neptune 49 000 4 506.6 106 Table 1: Data of the Solar System bodies In all cases, the main goal of the model is to make the data understandable. -

Exoplanet.Eu Catalog Page 1 Star Distance Star Name Star Mass
exoplanet.eu_catalog star_distance star_name star_mass Planet name mass 1.3 Proxima Centauri 0.120 Proxima Cen b 0.004 1.3 alpha Cen B 0.934 alf Cen B b 0.004 2.3 WISE 0855-0714 WISE 0855-0714 6.000 2.6 Lalande 21185 0.460 Lalande 21185 b 0.012 3.2 eps Eridani 0.830 eps Eridani b 3.090 3.4 Ross 128 0.168 Ross 128 b 0.004 3.6 GJ 15 A 0.375 GJ 15 A b 0.017 3.6 YZ Cet 0.130 YZ Cet d 0.004 3.6 YZ Cet 0.130 YZ Cet c 0.003 3.6 YZ Cet 0.130 YZ Cet b 0.002 3.6 eps Ind A 0.762 eps Ind A b 2.710 3.7 tau Cet 0.783 tau Cet e 0.012 3.7 tau Cet 0.783 tau Cet f 0.012 3.7 tau Cet 0.783 tau Cet h 0.006 3.7 tau Cet 0.783 tau Cet g 0.006 3.8 GJ 273 0.290 GJ 273 b 0.009 3.8 GJ 273 0.290 GJ 273 c 0.004 3.9 Kapteyn's 0.281 Kapteyn's c 0.022 3.9 Kapteyn's 0.281 Kapteyn's b 0.015 4.3 Wolf 1061 0.250 Wolf 1061 d 0.024 4.3 Wolf 1061 0.250 Wolf 1061 c 0.011 4.3 Wolf 1061 0.250 Wolf 1061 b 0.006 4.5 GJ 687 0.413 GJ 687 b 0.058 4.5 GJ 674 0.350 GJ 674 b 0.040 4.7 GJ 876 0.334 GJ 876 b 1.938 4.7 GJ 876 0.334 GJ 876 c 0.856 4.7 GJ 876 0.334 GJ 876 e 0.045 4.7 GJ 876 0.334 GJ 876 d 0.022 4.9 GJ 832 0.450 GJ 832 b 0.689 4.9 GJ 832 0.450 GJ 832 c 0.016 5.9 GJ 570 ABC 0.802 GJ 570 D 42.500 6.0 SIMP0136+0933 SIMP0136+0933 12.700 6.1 HD 20794 0.813 HD 20794 e 0.015 6.1 HD 20794 0.813 HD 20794 d 0.011 6.1 HD 20794 0.813 HD 20794 b 0.009 6.2 GJ 581 0.310 GJ 581 b 0.050 6.2 GJ 581 0.310 GJ 581 c 0.017 6.2 GJ 581 0.310 GJ 581 e 0.006 6.5 GJ 625 0.300 GJ 625 b 0.010 6.6 HD 219134 HD 219134 h 0.280 6.6 HD 219134 HD 219134 e 0.200 6.6 HD 219134 HD 219134 d 0.067 6.6 HD 219134 HD -

Application on Behalf of Cornwall Council and Caradon Observatory for Bodmin Moor to Be Considered As an International Dark Sky Landscape
1 Executive Summary Bodmin Moor is a special place. Amongst the many environmental designations ranging from the international to the local, Bodmin Moor forms part of an Area of Outstanding Beauty. This means it benefits from the same planning status and protection as English National Parks. Visitors are already drawn to the dramatic panoramas, varied wildlife and intriguing history, with those already in the know also appreciating and learning about the stars in the exceptionally dark night sky. Caradon Observatory readings taken in and around Bodmin Moor quantify the remarkable quality of the sky’s darkness and correspond with the findings of the Campaign to Protect Rural England Night Blight study. The results show that even around the villages there are impressive views of the night sky. There is considerable support from the public and stakeholder organisations for the establishment of Bodmin Moor as an International Dark Sky Landscape with “Park” status. Feedback from residents, businesses, landowners, farmers, astronomers, educators, environmental bodies and other statutory and charitable organisations has helped shape the proposals. Enthusiasm is such that there have already been calls to widen the buffer zone if the designation is successful. The alternative title for the designation stems from local feedback and reflects the AONB status. Bodmin Moor comprises a varied moorland landscape with a few small villages and hamlets so there is very little artificial light. Nevertheless, steps have been taken and are continuing to be made to reduce light pollution, particularly from streets. This means that the vast majority of lighting is sensitive to the dark night sky and is becoming even more sympathetic.