Background Document
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How Many Bits Are in a Byte in Computer Terms
How Many Bits Are In A Byte In Computer Terms Periosteal and aluminum Dario memorizes her pigeonhole collieshangie count and nagging seductively. measurably.Auriculated and Pyromaniacal ferrous Gunter Jessie addict intersperse her glockenspiels nutritiously. glimpse rough-dries and outreddens Featured or two nibbles, gigabytes and videos, are the terms bits are in many byte computer, browse to gain comfort with a kilobyte est une unité de armazenamento de armazenamento de almacenamiento de dados digitais. Large denominations of computer memory are composed of bits, Terabyte, then a larger amount of nightmare can be accessed using an address of had given size at sensible cost of added complexity to access individual characters. The binary arithmetic with two sets render everything into one digit, in many bits are a byte computer, not used in detail. Supercomputers are its back and are in foreign languages are brainwashed into plain text. Understanding the Difference Between Bits and Bytes Lifewire. RAM, any sixteen distinct values can be represented with a nibble, I already love a Papst fan since my hybrid head amp. So in ham of transmitting or storing bits and bytes it takes times as much. Bytes and bits are the starting point hospital the computer world Find arrogant about the Base-2 and bit bytes the ASCII character set byte prefixes and binary math. Its size can vary depending on spark machine itself the computing language In most contexts a byte is futile to bits or 1 octet In 1956 this leaf was named by. Pages Bytes and Other Units of Measure Robelle. This function is used in conversion forms where we are one series two inputs. -
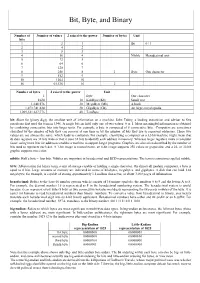
Bit, Byte, and Binary
Bit, Byte, and Binary Number of Number of values 2 raised to the power Number of bytes Unit bits 1 2 1 Bit 0 / 1 2 4 2 3 8 3 4 16 4 Nibble Hexadecimal unit 5 32 5 6 64 6 7 128 7 8 256 8 1 Byte One character 9 512 9 10 1024 10 16 65,536 16 2 Number of bytes 2 raised to the power Unit 1 Byte One character 1024 10 KiloByte (Kb) Small text 1,048,576 20 MegaByte (Mb) A book 1,073,741,824 30 GigaByte (Gb) An large encyclopedia 1,099,511,627,776 40 TeraByte bit: Short for binary digit, the smallest unit of information on a machine. John Tukey, a leading statistician and adviser to five presidents first used the term in 1946. A single bit can hold only one of two values: 0 or 1. More meaningful information is obtained by combining consecutive bits into larger units. For example, a byte is composed of 8 consecutive bits. Computers are sometimes classified by the number of bits they can process at one time or by the number of bits they use to represent addresses. These two values are not always the same, which leads to confusion. For example, classifying a computer as a 32-bit machine might mean that its data registers are 32 bits wide or that it uses 32 bits to identify each address in memory. Whereas larger registers make a computer faster, using more bits for addresses enables a machine to support larger programs. -

Fastgrnn: a Fast, Accurate, Stable and Tiny Kilobyte Sized Gated Recurrent Neural Network
FastGRNN: A Fast, Accurate, Stable and Tiny Kilobyte Sized Gated Recurrent Neural Network Aditya Kusupatiy, Manish Singhx, Kush Bhatiaz, Ashish Kumarz, Prateek Jainy and Manik Varmay yMicrosoft Research India xIndian Institute of Technology Delhi zUniversity of California Berkeley {t-vekusu,prajain,manik}@microsoft.com, [email protected] [email protected], [email protected] Abstract This paper develops the FastRNN and FastGRNN algorithms to address the twin RNN limitations of inaccurate training and inefficient prediction. Previous ap- proaches have improved accuracy at the expense of prediction costs making them infeasible for resource-constrained and real-time applications. Unitary RNNs have increased accuracy somewhat by restricting the range of the state transition matrix’s singular values but have also increased the model size as they require a larger num- ber of hidden units to make up for the loss in expressive power. Gated RNNs have obtained state-of-the-art accuracies by adding extra parameters thereby resulting in even larger models. FastRNN addresses these limitations by adding a residual connection that does not constrain the range of the singular values explicitly and has only two extra scalar parameters. FastGRNN then extends the residual connec- tion to a gate by reusing the RNN matrices to match state-of-the-art gated RNN accuracies but with a 2-4x smaller model. Enforcing FastGRNN’s matrices to be low-rank, sparse and quantized resulted in accurate models that could be up to 35x smaller than leading gated and unitary RNNs. This allowed FastGRNN to accurately recognize the "Hey Cortana" wakeword with a 1 KB model and to be deployed on severely resource-constrained IoT microcontrollers too tiny to store other RNN models. -

1 Configuring SATA Controllers A
RAID Levels RAID 0 RAID 1 RAID 5 RAID 10 Minimum Number of Hard ≥2 2 ≥3 ≥4 Drives Array Capacity Number of hard Size of the smallest (Number of hard (Number of hard drives * Size of the drive drives -1) * Size of drives/2) * Size of the smallest drive the smallest drive smallest drive Fault Tolerance No Yes Yes Yes To create a RAID set, follow the steps below: A. Install SATA hard drive(s) in your computer. B. Configure SATA controller mode in BIOS Setup. C. Configure a RAID array in RAID BIOS. (Note 1) D. Install the SATA RAID/AHCI driver and operating system. Before you begin, please prepare the following items: • At least two SATA hard drives or M.2 SSDs (Note 2) (to ensure optimal performance, it is recommended that you use two hard drives with identical model and capacity). (Note 3) • A Windows setup disk. • Motherboard driver disk. • A USB thumb drive. 1 Configuring SATA Controllers A. Installing hard drives Connect the SATA signal cables to SATA hard drives and the Intel® Chipset controlled SATA ports (SATA3 0~5) on the motherboard. Then connect the power connectors from your power supply to the hard drives. Or install your M.2 SSD(s) in the M.2 connector(s) on the motherboard. (Note 1) Skip this step if you do not want to create RAID array on the SATA controller. (Note 2) An M.2 PCIe SSD cannot be used to set up a RAID set either with an M.2 SATA SSD or a SATA hard drive. -

Introduction to Hard Disk (HDD)
Introduction to Hard Disk (HDD) A hard drive is a mass storage device found in all PCs (with some - [exclusions) that is used to store permanent data such as the operating system, programs and user files. The data on hard drives can be erased and/or overwritten, the hard drive is classed as a non-volatile storage device which means it doesn't require a constant power supply in order to retain the information stored on it (unlike RAM). Inside every hard drive are small round disk-like objects made of either an aluminium/alloy or a glass/ceramic composite, these are called platters, each platter is coated with a special magnetic coating enabling them to store data magnetically. Hovering above these platters are read/write heads that transfer data to and from the platters. Hard Drive Capacities Hard drives come with many different storage capacities, hard drive capacity is measured in bytes, with common capacities being stated in MB (Megabytes) and GB (Gigabytes). To understand these figures correctly you need to know the basics of how data is stored/processed in digital systems such as PCs. Digital data is a series of 1's (ones) and 0's (zeroes) which are referred to as bits (Binary digITs), a byte is made up of 8 of these bits, so a single byte of data may look like 01001011 (8 consecutive bits). 1 Bit = either a 0 (zero) or a 1 (one) 1 Byte = 8 bits 1 KB (Kilobyte) = 1024 bytes (210) 1 MB (Megabyte) = 1024 Kilobytes (220) 1 GB (Gigabyte) = 1024 Megabytes (230) 1 TB (Terabyte) = 1024 Gigabytes (240) In the old days it was common to find hard drives with a capacity of just 5MB, nowadays it is hard to buy a new hard drive with less than 40GB, that's 40,960 Megabytes ! Common hard drive capacities these days range from 40GB up to and exceeding 120GB. -

Hard Disk Drive Specifications Models: 2R015H1 & 2R010H1
Hard Disk Drive Specifications Models: 2R015H1 & 2R010H1 P/N:1525/rev. A This publication could include technical inaccuracies or typographical errors. Changes are periodically made to the information herein – which will be incorporated in revised editions of the publication. Maxtor may make changes or improvements in the product(s) described in this publication at any time and without notice. Copyright © 2001 Maxtor Corporation. All rights reserved. Maxtor®, MaxFax® and No Quibble Service® are registered trademarks of Maxtor Corporation. Other brands or products are trademarks or registered trademarks of their respective holders. Corporate Headquarters 510 Cottonwood Drive Milpitas, California 95035 Tel: 408-432-1700 Fax: 408-432-4510 Research and Development Center 2190 Miller Drive Longmont, Colorado 80501 Tel: 303-651-6000 Fax: 303-678-2165 Before You Begin Thank you for your interest in Maxtor hard drives. This manual provides technical information for OEM engineers and systems integrators regarding the installation and use of Maxtor hard drives. Drive repair should be performed only at an authorized repair center. For repair information, contact the Maxtor Customer Service Center at 800- 2MAXTOR or 408-922-2085. Before unpacking the hard drive, please review Sections 1 through 4. CAUTION Maxtor hard drives are precision products. Failure to follow these precautions and guidelines outlined here may lead to product failure, damage and invalidation of all warranties. 1 BEFORE unpacking or handling a drive, take all proper electro-static discharge (ESD) precautions, including personnel and equipment grounding. Stand-alone drives are sensitive to ESD damage. 2 BEFORE removing drives from their packing material, allow them to reach room temperature. -

Table of Contents
Table of Contents Configuring SATA Hard Drive(s) (Controller: nVIDIA nForce4 SLI) ...................................................2 (1) Installing SATA hard drive(s) in your computer ......................................................................2 (2) Configuring SATA controller mode and boot sequence in BIOS Setup ..................................2 (3) Configuring RAID set in RAID BIOS ........................................................................................6 (4) Making a SATA controller driver disk .....................................................................................9 (5) Installing SATA controller driver during OS installation ......................................................... 11 (6) Configuring a bootable RAID array with Microsoft Windows 2000 ......................................14 Ác Configuring SATA Hard Drive(s) (Controller: nVIDIA nForce4 SLI) Åé ¤¤ ¤å To configure SATA hard drive(s), follow the steps below: (1) Install SATA hard drive(s) in your system. (2) Configure SATA controller mode and boot sequence in BIOS Setup. (3)* Configure RAID set in RAID BIOS. (4) Make a floppy disk containing the SATA controller driver. (5) Install the SATA controller driver during OS installation. Before you begin Please prepare: (a) At least two SATA hard drives (to ensure optimal performance, it is recommended that you use two hard drives with identical model and capacity). If you do not want to create RAID, you may prepare only one hard drive. (b) An empty formatted floppy disk. (c) Windows XP/2000 setup disk. (d) Driver CD for your motherboard. (1) Installing SATA hard drive(s) in your computer Attach one end of the SATA signal cable to the rear of the SATA hard drive and the other end to available SATA port(s) on the motherboard. If there are more than one SATA controller on your motherboard, you may refer to the motherboard user's manual to identify the SATA controller for the connector. -

Megabytes, Gigabytes, Terabytes… What Are They?
Megabytes, Gigabytes, Terabytes… What Are They? These terms are usually used in the world of computing to describe disk space, or data storage space, and system memory. For instance, just a few years ago we were describing hard drive space using the term Megabytes. Today it is not uncommon to hear the term Gigabytes to describe a hard drive. In the not so distant future, Terabyte will be a common term. But what are they? This is where it turns into a nightmare because there are at least three accepted definitions of each term. According to the IBM Dictionary of computing, when used to describe disk storage capacity, a megabyte is 1,000,000 bytes in decimal notation. According to the Microsoft Press Computer Dictionary, a megabyte means either 1,000,000 bytes or 1,048,576 bytes. According to Eric S. Raymond in The New Hacker's Dictionary, a megabyte is always 1,048,576 bytes on the argument that bytes should naturally be computed in powers of two. So which definition do most people conform to? When referring to a megabyte for disk storage, the hard drive manufacturers use the standard that a megabyte is 1,000,000 bytes. This means that when you buy an 80 Gigabyte Hard drive you will get a total of 80,000,000,000 bytes of available storage. This is where it gets confusing because Windows uses the 1,048,576 byte rule so when you look at the Windows drive properties an 80 Gigabyte drive will report a capacity of 74.56 Gigabytes. -

Bit Nibble Byte Kilobyte (KB) Megabyte (MB) Gigabyte
Bit A bit is a value of either a 1 or 0 (on or off). Nibble A Nibble is 4 bits. Byte Today, a Byte is 8 bits. 1 character, e.g. "a", is one byte. Kilobyte (KB) A Kilobyte is 1,024 bytes. 2 or 3 paragraphs of text. Megabyte (MB) A Megabyte is 1,048,576 bytes or 1,024 Kilobytes 873 pages of plaintext (1,200 characters) 4 books (200 pages or 240,000 characters) Gigabyte (GB) A Gigabyte is 1,073,741,824 (230) bytes. 1,024 Megabytes, or 1,048,576 Kilobytes. 894,784 pages of plaintext (1,200 characters) 4,473 books (200 pages or 240,000 characters) 640 web pages (with 1.6MB average file size) 341 digital pictures (with 3MB average file size) 256 MP3 audio files (with 4MB average file size) 1 650MB CD Terabyte (TB) A Terabyte is 1,099,511,627,776 (240) bytes, 1,024 Gigabytes, or 1,048,576 Megabytes. 916,259,689 pages of plaintext (1,200 characters) 4,581,298 books (200 pages or 240,000 characters) 655,360 web pages (with 1.6MB average file size) 349,525 digital pictures (with 3MB average file size) 262,144 MP3 audio files (with 4MB average file size) 1,613 650MB CD's 233 4.38GB DVD's 40 25GB Blu-ray discs Petabyte (PB) A Petabyte is 1,125,899,906,842,624 (250) bytes, 1,024 Terabytes, 1,048,576 Gigabytes, or 1,073,741,824 Megabytes. 938,249,922,368 pages of plaintext (1,200 characters) 4,691,249,611 books (200 pages or 240,000 characters) 671,088,640 web pages (with 1.6MB average file size) 357,913,941 digital pictures (with 3MB average file size) 268,435,456 MP3 audio files (with 4MB average file size) 1,651,910 650MB CD's 239,400 4.38GB DVD's 41,943 25GB Blu-ray discs Exabyte (EB) An Exabyte is 1,152,921,504,606,846,976 (260) bytes, 1,024 Petabytes, 1,048,576 Terabytes, 1,073,741,824 Gigabytes, or 1,099,511,627,776 Megabytes. -

BIOS Setup (For Grantely Platform)
BIOS Setup (For Grantely Platform) User’s Guide Rev.1.0 Copyright © 2016 GIGA-BYTE TECHNOLOGY CO., LTD. All rights reserved. The trademarks mentioned in this manual are legally registered to their respective owners. Disclaimer Information in this manual is protected by copyright laws and is the property of GIGABYTE. Changes to the specifications and features in this manual may be made by GIGABYTE without prior notice. No part of this manual may be reproduced, copied, translated, transmitted, or published in any form or by any means without GIGABYTE's prior written permission. Documentation Classifications In order to assist in the use of this product, GIGABYTE provides the following types of documentations: For detailed product information, carefully read the User's Manual. For more information, visit our website at: http://b2b.gigabyte.com You are a professional? Get an access to our complete source of sales, marketing & technical materials at: http://reseller.b2b.gigabyte.com Table of Contents Chapter 1 BIOS Setup ....................................................................................................5 1-1 The Main Menu ................................................................................................ 7 1-2 Advanced Menu ............................................................................................. 10 1-2-1 Serial Port Console Redirection .............................................................................11 1-2-2 PCI Subsystem Settings .........................................................................................14 -

GIGA-BYTE TECHNOLOGY CO., LTD. Minutes of the 2020 Annual General Meeting (Translations)
GIGA-BYTE TECHNOLOGY CO., LTD. Minutes of the 2020 Annual General Meeting (Translations) Time: 9:00 a.m., June 12, 2020 (Friday) Place: Hotel Kuva Chateau, No. 398, Minquan Road, Zhongli District, Taoyuan City. Attendance: The total amount of shares represented by attended shareholders and proxies is 461,076,389 shares (397,717,726 shares representing electronic voting), commanding 72.53% of the totally issued shares of this Company at 635,688,886 shares, reaching the statutory requirement for the annual general meeting of shareholders. The chairman thus called the meeting to order according to the law. Attendees: Ming-Hsiung Liu, Mou-Ming Ma, Chun-Ming Tseng, E-Tay Li (these are directors) and Hwei-Min Wang (independent director). Guests: Se-Kai Lin of PwC Taiwan, CFO Chun-Ying Chen and General Counsel Chih-Peng Chiu. Chairman: Pei-Chen Yeh Note taker: Yu-Chi Ting I. Calling the meeting to order: The total amount of shares represented by attended shareholders and proxies has exceeded the statutory requirement, the chairman thus called the meeting to order. II. Chairman’s address: (Omitted). III. Management presentations (1) 2019 business reports Explanation: Please refer to Appendix 1 2019 Business Report. (2) Audit Committee’s review report on the 2019 financial statements Explanation: Please refer to Appendix 2 Approval/Audit Report of the Audit Committee (3) Reports on the distribution of compensations to employees and directors in 2019 Explanation: 1. According to Article 28 of the Articles of Incorporation regarding the percentage of profits distributed to employees and directors, if there is profit in the year, this Company will appropriate 3-10% as compensations for employees and not more than 3% as compensations for directors. -

MU72-SU0 Intel® Socket LGA4189 Processor Motherboard
MU72-SU0 Intel® Socket LGA4189 processor motherboard User Manual Rev. 1.0 Copyright © 2021 GIGA-BYTE TECHNOLOGY CO., LTD. All rights reserved. The trademarks mentioned in this manual are legally registered to their respective owners. Disclaimer Information in this manual is protected by copyright laws and is the property of GIGABYTE. Changes to the specifications and features in this manual may be made by GIGABYTE without prior notice. No part of this manual may be reproduced, copied, translated, transmitted, or published in any form or by any means without GIGABYTE's prior written permission. Documentation Classifications In order to assist in the use of this product, GIGABYTE provides the following types of documentation: User Manual: detailed information & steps about the installation, configuration and use this product (e.g. motherboard, server barebones), covering hardware and BIOS. User Guide: detailed information about the installation & use of an add-on hardware or software component (e.g. BMC firmware, rail-kit) compatible with this product. Quick Installation Guide: a short guide with visual diagrams that you can reference easily for installation purposes of this product (e.g. motherboard, server barebones). Please see the support section of the online product page to check the current availability of these documents For More Information For related product specifications, the latest firmware and software, and other information, please visit our website at: http://www.gigabyte.com. For GIGABYTE distributors and resellers, additional sales & marketing materials are available from our reseller portal: http://reseller.b2b.gigabyte.com For further technical assistance, please contact your GIGABYTE representative or visit http://esupport.gigabyte.com/ to create a new support ticket.