3 a Quantitative and Comparative Study of Network-Level Efficiency for Cloud Storage Services
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Uila Supported Apps
Uila Supported Applications and Protocols updated Oct 2020 Application/Protocol Name Full Description 01net.com 01net website, a French high-tech news site. 050 plus is a Japanese embedded smartphone application dedicated to 050 plus audio-conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also 10086.cn classifies the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese web portal operated by YLMF Computer Technology Co. Chinese cloud storing system of the 115 website. It is operated by YLMF 115.com Computer Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr Korean shopping website 11st. It is operated by SK Planet Co. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt Lithuanian news portal Chinese web portal 163. It is operated by NetEase, a company which 163.com pioneered the development of Internet in China. 17173.com Website distributing Chinese games. 17u.com Chinese online travel booking website. 20 minutes is a free, daily newspaper available in France, Spain and 20minutes Switzerland. This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Shared 2shared is an online space for sharing and storage. -
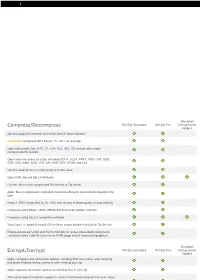
Compress/Decompress Encrypt/Decrypt
Windows Compress/Decompress WinZip Standard WinZip Pro Compressed Folders Zip and unzip files instantly with 64-bit, best-in-class software ENHANCED! Compress MP3 files by 15 - 20 % on average Open and extract Zipx, RAR, 7Z, LHA, BZ2, IMG, ISO and all other major compression file formats Open more files types as a Zip, including DOCX, XLSX, PPTX, XPS, ODT, ODS, ODP, ODG,WMZ, WSZ, YFS, XPI, XAP, CRX, EPUB, and C4Z Use the super picker to unzip locally or to the cloud Open CAB, Zip and Zip 2.0 Methods Convert other major compressed file formats to Zip format Apply 'Best Compression' method to maximize efficiency automatically based on file type Reduce JPEG image files by 20 - 25% with no loss of photo quality or data integrity Compress using BZip2, LZMA, PPMD and Enhanced Deflate methods Compress using Zip 2.0 compatible methods 'Auto Open' a zipped Microsoft Office file by simply double-clicking the Zip file icon Employ advanced 'Unzip and Try' functionality to review interrelated components contained within a Zip file (such as an HTML page and its associated graphics). Windows Encrypt/Decrypt WinZip Standard WinZip Pro Compressed Folders Apply encryption and conversion options, including PDF conversion, watermarking and photo resizing, before, during or after creating your zip Apply separate conversion options to individual files in your zip Take advantage of hardware support in certain Intel-based computers for even faster AES encryption Administrative lockdown of encryption methods and password policies Check 'Encrypt' to password protect your files using banking-level encryption and keep them completely secure Secure sensitive data with strong, FIPS-197 certified AES encryption (128- and 256- bit) Auto-wipe ('shred') temporarily extracted copies of encrypted files using the U.S. -

Lock-Free Collaboration Support for Cloud Storage Services With
Lock-Free Collaboration Support for Cloud Storage Services with Operation Inference and Transformation Jian Chen, Minghao Zhao, and Zhenhua Li, Tsinghua University; Ennan Zhai, Alibaba Group Inc.; Feng Qian, University of Minnesota - Twin Cities; Hongyi Chen, Tsinghua University; Yunhao Liu, Michigan State University & Tsinghua University; Tianyin Xu, University of Illinois Urbana-Champaign https://www.usenix.org/conference/fast20/presentation/chen This paper is included in the Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST ’20) February 25–27, 2020 • Santa Clara, CA, USA 978-1-939133-12-0 Open access to the Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST ’20) is sponsored by Lock-Free Collaboration Support for Cloud Storage Services with Operation Inference and Transformation ⇤ 1 1 1 2 Jian Chen ⇤, Minghao Zhao ⇤, Zhenhua Li , Ennan Zhai Feng Qian3, Hongyi Chen1, Yunhao Liu1,4, Tianyin Xu5 1Tsinghua University, 2Alibaba Group, 3University of Minnesota, 4Michigan State University, 5UIUC Abstract Pattern 1: Losing updates Alice is editing a file. Suddenly, her file is overwritten All studied This paper studies how today’s cloud storage services support by a new version from her collaborator, Bob. Sometimes, cloud storage collaborative file editing. As a tradeoff for transparency/user- Alice can even lose her edits on the older version. services friendliness, they do not ask collaborators to use version con- Pattern 2: Conflicts despite coordination trol systems but instead implement their own heuristics for Alice coordinates her edits with Bob through emails to All studied handling conflicts, which however often lead to unexpected avoid conflicts by enforcing a sequential order. -

Photos Copied" Box
Our photos have never been as scattered as they are now... Do you know where your photos are? Digital Photo Roundup Checklist www.theswedishorganizer.com Online Storage Edition Let's Play Digital Photo Roundup! Congrats on making the decision to start organizing your digital photos! I know the task can seem daunting, so hopefully this handy checklist will help get your moving in the right direction. LET'S ORGANIZE! To start organizing your digital photos, you must first gather them all into one place, so that you'll be able to sort and edit your collection. Use this checklist to document your family's online storage accounts (i.e. where you have photos saved online), and whether they are copied onto your Master hub (the place where you are saving EVERYTHING). It'll make the gathering process a whole lot easier if you keep a record of what you have already copied and what is still to be done. HERE'S HOW The services in this checklist are categorized, so that you only need to print out what applies to you. If you have an account with the service listed, simply check the "Have Account" box. When you have copied all the photos, check the "Photos Copied" box. Enter your login credentials under the line between the boxes for easy retrieval. If you don't see your favorite service on the list, just add it to one of the blank lines provided after each category. Once you are done, you should find yourself with all your digital images in ONE place, and when you do, check back on the blog for tools to help you with the next step in the organizing process. -

Chapter 14 This Presentation Covers
Basic Operating Systems Chapter 14 This presentation covers: > Staying Current >Basic Operating Systems Overview > Command Prompts Qualities of a Good Technician “Soft skills” as they are known across many industries are essential Staying Current Benefits of staying current include: >(1) understanding and troubleshooting the latest technologies > (2) recommending upgrades or solutions to customers > (3) saving time troubleshooting (and time is money) > (4) being someone considered for a promotion Staying Current A variety of methods to stay current include: >Subscribe to a magazine or an online magazine > Subscribe to a news list that gives you an update in your email > Join or attend association meetings >Register for and attend a seminar > Attend an online webinar > Take a class > Read books > Talk to your department peers and supervisor Basic Operating Systems Overview Basic Operating Systems > Computers require software to operate >An operating system (OS) is software that coordinates the interaction between hardware and any software applications and the interaction between a user and the computer >An operating system can be a graphical user interface (GUI) or a command line interface, or both > It is responsible for handling file and disk management Popular Operating Systems > Microsoft Windows >Apple macOS > Linux > Chrome OS > Android (mobile) > Apple iOS (mobile) 32- vs 64-bit Operating Systems Windows 7 Editions Windows 10 Editions End-of-Life Concerns > Serious consequences if an operating system or application has reached its -

Mobile Cloud Storage
Context Awareness MobileHCI 2014, Sept. 23–26, 2014, Toronto, ON, CA Mobile Cloud Storage: A Contextual Experience Karel Vandenbroucke Denzil Ferreira*, Jorge Goncalves*, Katrien De Moor iMinds-MICT-Ghent University Vassilis Kostakos* ITEM-NTNU Ghent, Belgium University of Oulu Trondheim, Norway [email protected] Oulu, Finland [email protected] {dteixeir;jgoncalv;vassilis}@ee.oulu.fi ABSTRACT anywhere, at any time and from any device. However, one In an increasingly connected world, users access personal unyielding disadvantage of these lightweight, mobile or shared data, stored “in the cloud” (e.g., Dropbox, devices is their limited storage capacity, which also limits Skydrive, iCloud) with multiple devices. Despite the their possible uses. It is also more common to find services popularity of cloud storage services, little work has focused and applications that work across different mobile devices on investigating cloud storage users’ Quality of Experience and platforms. As a result, the related user behavior and (QoE), in particular on mobile devices. Moreover, it is not usage patterns have become more complex and a range of clear how users’ context might affect QoE. We conducted problems has emerged. One recurring challenge is to an online survey with 349 cloud service users to gain connect multiple devices that have vastly different insight into their usage and affordances. In a 2-week characteristics and requirements and how to synchronize follow-up study, we monitored mobile cloud service usage the stored data across these devices in an effortless way. on tablets and smartphones, in real-time using a mobile- With recent improvements on network speed, reliability based Experience Sampling Method (ESM) questionnaire. -

Data Protection and Collaboration in Cloud Storage
Technical Report 1210 Charting a Security Landscape in the Clouds: Data Protection and Collaboration in Cloud Storage G. Itkis B.H. Kaiser J.E. Coll W.W. Smith R.K. Cunningham 7 July 2016 Lincoln Laboratory MASSACHUSETTS INSTITUTE OF TECHNOLOGY LEXINGTON, MASSACHUSETTS This material is based on work supported by the Department of Homeland Security under Air Force Contract No. FA8721-05-C-0002 and/or FA8702-15-D-0001. Approved for public release: distribution unlimited. This report is the result of studies performed at Lincoln Laboratory, a federally funded research and development center operated by Massachusetts Institute of Technology. This material is based on work supported by the Department of Homeland Security under Air Force Contract No. FA8721-05- C-0002 and/or FA8702-15-D-0001. Any opinions, findings and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of Department of Homeland Security. © 2016 MASSACHUSETTS INSTITUTE OF TECHNOLOGY Delivered to the U.S. Government with Unlimited Rights, as defined in DFARS Part 252.227-7013 or 7014 (Feb 2014). Notwithstanding any copyright notice, U.S. Government rights in this work are defined by DFARS 252.227-7013 or DFARS 252.227-7014 as detailed above. Use of this work other than as specifically authorized by the U.S. Government may violate any copyrights that exist in this work. Massachusetts Institute of Technology Lincoln Laboratory Charting a Security Landscape in the Clouds: Data Protection and Collaboration in Cloud Storage G. Itkis B. Kaiser J. Coll W. Smith R. -
A Survey on Cloud Storage
1764 JOURNAL OF COMPUTERS, VOL. 6, NO. 8, AUGUST 2011 A Survey on Cloud Storage Jiehui JU1,4 1.School of Information and Electronic Engineering, Zhejiang University of Science and Technology,Hangzhou,China Email: [email protected] Jiyi WU2,3, Jianqing FU3, Zhijie LIN1,3, Jianlin ZHANG2 2. Key Lab of E-Business and Information Security, Hangzhou Normal University, Hangzhou,China 3.School of Computer Science and Technology, Zhejiang University,Hangzhou,China 4.Key Lab of E-business Market Application Technology of Guangdong Province, Guangdong University of Business Studies, Guangzhou 510320, China Email: [email protected]; [email protected]; [email protected]; [email protected] Abstract— Cloud storage is a new concept come into being simultaneously with cloud computing, and can be divided into public cloud storage, private cloud storage and hybrid cloud storage. This article gives a quick introduction to cloud storage. It covers the key technologies in Cloud Computing and Cloud Storage. Google GFS massive data storage system and the popular open source Hadoop HDFS were detailed introduced to analyze the principle of Cloud Storage technology. As an important technology area and research direction, cloud storage is becoming a hot research for both academia and industry session. The future valuable research works were summarized at the end. Index Terms—Cloud Storage, Distributed File System, Research Status, survey I. INTRODUCTION As we all known disk storage is one of the largest expenditure in IT projects. ComputerWorld estimates that storage is responsible for almost 30% of capital expenditures as the average growth of data approaches Figure 1. -

On the Cost-Benefit Tradeoffs of Cloud Storage Services for End Users and Service Providers
ON THE COST-BENEFIT TRADEOFFS OF CLOUD STORAGE SERVICES FOR END USERS AND SERVICE PROVIDERS GLAUBER DIAS GONÇALVES ON THE COST-BENEFIT TRADEOFFS OF CLOUD STORAGE SERVICES FOR END USERS AND SERVICE PROVIDERS Tese apresentada ao Programa de Pós-Graduação em Ciência da Computação do Instituto de Ciências Exatas da Universidade Federal de Minas Gerais como requisito parcial para a obtenção do grau de Doutor em Ciência da Computação. Orientador: Jussara Marques de Almeida Coorientador: Alex Borges Vieira Belo Horizonte Dezembro de 2017 GLAUBER DIAS GONÇALVES ON THE COST-BENEFIT TRADEOFFS OF CLOUD STORAGE SERVICES FOR END USERS AND SERVICE PROVIDERS Thesis presented to the Graduate Program in Ciência da Computação of the Universidade Federal de Minas Gerais in partial fulfillment of the requirements for the degree of Doctor in Ciência da Computação. Advisor: Jussara Marques de Almeida Co-Advisor: Alex Borges Vieira Belo Horizonte December 2017 © 2017, Glauber Dias Gonçalves. Todos os direitos reservados Ficha catalográfica elaborada pela Biblioteca do ICEx - UFMG Gonçalves, Glauber Dias. G635o On the cost-benefit tradeoffs of cloud storage services for end users and service providers. / Glauber Dias Gonçalves. – Belo Horizonte, 2017. xiv, 139 f.: il.; 29 cm. Tese (doutorado) - Universidade Federal de Minas Gerais – Departamento de Ciência da Computação. Orientadora: Jussara Marques de Almeida Gonçalves Coorientador: Alex Borges Vieira 1. Computação - Teses. 2. Computação em nuvem. 3. Comportamento de usuário. 4. Custos e benefícios. 5. Cache. 6. Dropbox. I. Orientadora. II. Coorientador. III. Título. CDU 519.6*32(043) Abstract Cloud storage is a data-intensive Internet service that offers the means for end users to easily backup data and perform collaborative work, with files in user devices being automatically synchronized with the cloud. -

Deltacfs: Boosting Delta Sync for Cloud Storage Services by Learning from NFS
DeltaCFS: Boosting Delta Sync for Cloud Storage Services by Learning from NFS Quanlu Zhang∗, Zhenhua Liy, Zhi Yang∗, Shenglong Li∗, Shouyang Li∗, Yangze Guo∗, and Yafei Dai∗z ∗Peking University yTsinghua University zInstitute of Big Data Technologies Shenzhen Key Lab for Cloud Computing Technology & Applications fzql, yangzhi, lishenglong, lishouyang, guoyangze, [email protected], [email protected] Abstract—Cloud storage services, such as Dropbox, iCloud find a common root cause that undermines the effect of delta Drive, Google Drive, and Microsoft OneDrive, have greatly sync: these applications heavily rely on structured data which facilitated users’ synchronizing files across heterogeneous devices. are stored in tabular files (e.g., SQLite [12] files), rather than Among them, Dropbox-like services are particularly beneficial owing to the delta sync functionality that strives towards greater simple textual files (e.g., .txt, .tex, and .log files). For exam- network-level efficiency. However, when delta sync trades com- ple, today’s smartphones (like iPhone) regularly synchronize putation overhead for network-traffic saving, the tradeoff could local data to the cloud storage (like iCloud [13]), where a be highly unfavorable under some typical workloads. We refer considerable part of the synchronized is tabular data [14]. to this problem as the abuse of delta sync. Confronted with the abovementioned situation, delta sync To address this problem, we propose DeltaCFS, a novel file sync framework for cloud storage services by learning from the exhibits poor performance, because it often generates intoler- design of conventional NFS (Network File System). Specifically, ably high computation overhead when dealing with structured we combine delta sync with NFS-like file RPC in an adaptive data. -

Online File-Hosting Service
ISSN XXXX XXXX © 2017 IJESC Research Article Volume 7 Issue No.3 Online File-Hosting Service Khaja Viqar Uddin1, MD Daniyal Raza2, Faheem Uddin3, Abdul Rais4 B.Tech Students 1,2,3, Assistant Professor4 Department of Computer Science Engineering Lords Institute of Engineering and Technology,Hyderabad, India Abstract: It is a type of file hosting application. Which is used for storing multimedia files in a Database or a server which can be a ccessed from any remote location by the user if he or she has the hardware and software requirements. In this we are trying to improve or counter the drawbacks of the existing system and possibly add few new features.It creates a special folder on user’s device. The content of which are then synchronized to the application server and to other devices that has installed the application. This application uses a freemium business model, users are offered a free account with a set storage size. Keywords:Multimedia, Synchronized, Remote Location.Freemium Business Model. I.INTRODUCTION: II.EXPLANATION A file hosting service, cloud storage service, online file Personal file storage storage provider, or cyberlocker is an Internet hosting Personal file storage services are aimed at private individuals, service specifically designed to host user files. It allows users offering a sort of "network storage" for personal backup, file to upload files that could then be accessed over the internet access, or file distribution. Users can upload their files and from a different computer, tablet, s mart phone or other share them publicly or keep them password-protected. networked device, by the same user or possibly by other users, Document-sharing services allow users to share and after a password or other authentication is provided. -

Android Cell Phone Basics Table of Contents
Android Cell Phone Basics Table of Contents Google Accounts ............................................... 2 Secured vs Unsecured Wireless Networks ..... 18 The Device ........................................................ 2 Texting ............................................................ 18 Status Bar ......................................................... 2 Text Messages and Phone Data ...................... 18 Notifications ..................................................... 3 Text Messages ................................................. 19 Gestures ............................................................ 3 Alternatives to SMS Texting ........................... 20 Quick Settings ................................................... 3 Apps ................................................................ 20 Settings ............................................................. 4 Closing and Removing Apps .......................... 20 Accessibility ...................................................... 5 Google Play Store ............................................ 21 Font Size ........................................................... 5 Folders ............................................................ 23 Flash Alerts ....................................................... 6 Camera ............................................................ 25 Android Version vs Phone Model vs Carrier.... 6 Photos ............................................................. 26 Lock Screens and Security ................................