Arxiv:1912.11850V2 [Cs.CV] 10 Apr 2020 to Each of the Action-Words
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Social Tango
Social Tango Richard Powers Argentine tango has been popular around the world for over a century. Therefore it has evolved into several different forms. This doc describes social tango, sometimes called American tango. The world first saw tango when Argentine dancers brought it to Paris around 1910. It quickly became the biggest news in Paris—the 1912 Tangomania. Dancers around the world fell in love with tango and added it to their growing repertoire of social dances. When we compare 1912 European and North American tango descriptions to Argentine tango manuals from the same time, we see that the northern hemisphere dancers mostly got it right, dancing the same steps in the same style as the Argentines. Then as time went on, social dancers had no reason to change it. It wasn't broken, so why fix it? Today's social tango is essentially the continuation of the original 1912 Argentine tango. There have been a few evolutionary changes over time, like which foot to start on, but they're relatively minor compared to the greater changes that have been made to the other two forms of tango. Ironically, some people call this American Style tango. This is to differentiate it from International Style (British) tango, but it's nevertheless odd to call the nearly-unchanged original Argentine tango "American," unless one means South American. Many dancers in the world know social tango so this is worth learning. That doesn't mean it's "better" than the other forms of tango—that depends on one's personal preference. But social tango is a very useful kind of tango for dancing with friends at parties, weddings and ocean cruises. -

3671 Argentine Tango (Gold Dance Test)
3671 ARGENTINE TANGO (GOLD DANCE TEST) Music - Tango 4/4 Tempo - 24 measures of 4 beats per minute - 96 beats per minute Pattern - Set Duration - The time required to skate 2 sequences is 1:10 min. The Argentine Tango should be skated with strong edges and considerable “élan”. Good flow and fast travel over the ice are essential and must be achieved without obvious effort or pushing. The dance begins with partners in open hold for steps 1 to 10. The initial progressive, chassé and progressive sequences of steps 1 to 6 bring the partners on step 7 to a bold LFO edge facing down the ice surface. On step 8 both partners skate a right forward outside cross in front on count 1 held for one beat. On step 9, the couple crosses behind on count 2, with a change of edge on count 3 as their free legs are drawn past the skating legs and held for count 4 to be in position to start the next step, crossed behind for count 1. On step 10 the man turns a counter while the woman executes another cross behind then change of edge. This results in the partners being in closed hold as the woman directs her edge behind the man as he turns his counter. Step 11 is strongly curved towards the side of the ice surface. At the end of this step the woman momentarily steps onto the RFI on the “and” between counts 4 and 1 before skating step 12 that is first directed toward the side barrier. -

Samba, Rumba, Cha-Cha, Salsa, Merengue, Cumbia, Flamenco, Tango, Bolero
SAMBA, RUMBA, CHA-CHA, SALSA, MERENGUE, CUMBIA, FLAMENCO, TANGO, BOLERO PROMOTIONAL MATERIAL DAVID GIARDINA Guitarist / Manager 860.568.1172 [email protected] www.gozaband.com ABOUT GOZA We are pleased to present to you GOZA - an engaging Latin/Latin Jazz musical ensemble comprised of Connecticut’s most seasoned and versatile musicians. GOZA (Spanish for Joy) performs exciting music and dance rhythms from Latin America, Brazil and Spain with guitar, violin, horns, Latin percussion and beautiful, romantic vocals. Goza rhythms include: samba, rumba cha-cha, salsa, cumbia, flamenco, tango, and bolero and num- bers by Jobim, Tito Puente, Gipsy Kings, Buena Vista, Rollins and Dizzy. We also have many originals and arrangements of Beatles, Santana, Stevie Wonder, Van Morrison, Guns & Roses and Rodrigo y Gabriela. Click here for repertoire. Goza has performed multiple times at the Mohegan Sun Wolfden, Hartford Wadsworth Atheneum, Elizabeth Park in West Hartford, River Camelot Cruises, festivals, colleges, libraries and clubs throughout New England. They are listed with many top agencies including James Daniels, Soloman, East West, Landerman, Pyramid, Cutting Edge and have played hundreds of weddings and similar functions. Regular performances in the Hartford area include venues such as: Casona, Chango Rosa, La Tavola Ristorante, Arthur Murray Dance Studio and Elizabeth Park. For more information about GOZA and for our performance schedule, please visit our website at www.gozaband.com or call David Giardina at 860.568-1172. We look forward -
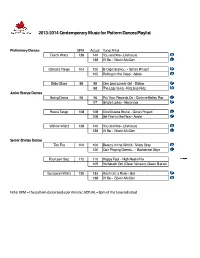
2013-2014 Contemporary Music for Pattern Dances Playlist
2013-2014 Contemporary Music for Pattern Dances Playlist Preliminary Dances BPM Act ual Tune/ Ar t ist Dut ch Walt z 138 140 You and Me - Lifehouse 138 I'll Be - Edwin McCain Can ast a Tan go 104 100 El Capitalismo... - Gotan Project 105 Rolling in the Deep - Adele Baby Bl ues 88 88 One Less Lonely Girl - Bieber 88 The Lazy Song - Kidz bop Kidz Ju n i o r Br o n z e D a n ce s Sw i n g Da n c e 96 96 Put Your Records On - Corinne Bailey Rae 97 Single Ladies - Beyoncee Fi est a Tango 108 108 Una Musica Brutal - Gotan Project 108 Set Fire to the Rain - Adele Willow Waltz 138 140 You and Me - Lifehouse 138 I'll Be - Edwin McCain Se ni or Br onze Da nce s Ten Fox 100 100 Beauty in the World - Macy Gray 100 Quit Playing Games... - Backstreet Boys Fo ur t een St ep 112 110 Happy Feet - High Heels Mix 109 Hollaback Girl (Clean Version)-Gwen Stefani Eu r o p ean Wal t z 135 133 Kiss from a Rose - Seal 138 I'll Be - Edwin McCain Note: BPM = the pattern dance beats per minute; ACTUAL = bpm of the tune indicated _____________________________________________________________________________________ 2013-2014 Contemporary Music for Pattern Dances Playlist pg2 Junior Silver Dances BPM Act ual Tune/ Ar t ist Keat s Foxt r ot 100 100 Beauty in the World - Macy Gray 100 Quit Playing Games... - Backstreet Boys Ro ck er Fo xt r o t 104 104 Black Horse & the Cherry Tree - KT Tunstall 104 Never See Your Face Again- Maroon 5 Harris Tango 108 108 Set Fire to the Rain - Adele 111 Gotan Project - Queremos Paz American Walt z 198 193 Fal l i n - Al i ci a Keys -

Amateur Mul Dance & Scholarship Entry Form
Form Leader: Age: DOB: mm/dd/yy: NDCA#: Studio: F Follower: Age: Teacher: Amateur Mul� Dance & Scholarship Entry Form DOB: mm/dd/yy: NDCA#: Phone: Adult contact name: Email: Amateur Rhythm Amateur Int'l Ballroom $ Per Category Dances Couple Category Dances $ Per Couple Sun Day - Session 10 Sun Day - Session 10 40 Amateur Under 21 - American Rhythm Cha Cha, Rumba, Swing, Bolero Amateur Under 21 - Int'l Ballroom Waltz, Tango, V. Waltz, Foxtrot, Quickstep 40 Wed Eve - Session 3 Fri Day - Session 6 Pre-Novice - American Rhythm Cha Cha, Rumba 40 Pre-Novice - Int'l Ballroom Waltz, Tango 40 Novice - American Rhythm Cha Cha, Rumba, Swing 40 Pre-Novice - Int'l Ballroom Foxtrot, Quickstep 40 Pre-Championship - American Rhythm Cha Cha, Rumba, Swing, Bolero 50 Novice - Int'l Ballroom Waltz, Foxtrot, Quickstep 40 Senior Open - American Rhythm (35+) Cha Cha, Rumba, Swing, Bolero 50 Pre-Championship - Int'l Ballroom Waltz, Tango, Foxtrot, Quickstep 40 Open Am - Am Rhythm Scholarship Cha Cha, Rumba, Swing, Bolero, Mambo 55 Senior Open - Int'l Ballroom (35+) Waltz, Tango, V. Waltz, Foxtrot, Quickstep 50 $ Total Amateur Rhythm Dance Entries: Masters Open - Int'l Ballroom (51+) Waltz, Tango, V. Waltz, Foxtrot, Quickstep 50 Fri Eve - Session 7 55 Open Am - Int'l Ballroom Scholarship Waltz, Tango, V. Waltz, Foxtrot, Quickstep Amateur Smooth $ $ Per Total Amateur Int'l Ballroom Dance Entries: Category Dances Couple Sun Day - Session 10 Amateur Under 21 - American Smooth Waltz, Tango, Foxtrot, V. Waltz 40 Amateur Int'l La�n Thu Eve - Session 5 Category Dances $ Per Pre-Novice - American Smooth Waltz, Tango 40 Couple Sun Day - Session 10 Novice - American Smooth Waltz, Tango, Foxtrot 40 Amateur Under 21 - Int'l La�n Cha Cha, Samba, Rumba, Paso Doble, Jive 40 Pre-Championship - American Smooth Waltz, Tango, Foxtrot, V. -

UNIVERSITY of CALIFORNIA, IRVINE Analysis of the Crossover
UNIVERSITY OF CALIFORNIA, IRVINE Analysis of the Crossover Between Ballroom and Ballet in Choreographic Works THESIS submitted in partial satisfaction of the requirements for the degree of MASTER FINE ARTS in Dance by Chanel Kostich Thesis Committee: Professor Alan Terricciano, Chair Associate Professor Tong Wang Assistant Professor Vitor Luiz 2020 © 2020 Chanel Kostich TABLE OF CONTENTS ACKNOWLEDGMENTS iii ABSTRACT OF THE THESIS iv INTRODUCTION 1 CHAPTER 1: Dance Autobiography 3 CHAPTER 2: Synopsis & Timeline of the Three Works 7 NYC Ballet: “Vienna Waltzes” 7 Grupo Corpo: “Grande Waltz” 11 Tango Pasión: “Argentine Tango Duet” 16 CHAPTER 3: Contextualizing the Interview with Rodrigo Pedernerias 20 CHAPTER 4: Heat of the Night: A Choreographic Thesis Film 22 Reflection of Thesis Project 30 Appendix 1: MethodoLogy Movement 32 American Smooth Tango Argentine Tango Ballet in Tango Pasión Bolero, Ballet, and Argentine Tango Viennese Waltz Appendix 2: Interview with Rodrigo Pederneiras 39 Appendix 3: Collaborative Design, Copyright Information, Contents of the Music 50 Works Cited 54 ii ACKNOWLEDGEMENTS I want to start by expressing immense gratitude for my thesis chair, Alan Terricciano. Thank you for your encouragement to experiment and be creative within this research process and for your continued patience as we worked through those choices together. Our discussions were always meaningful and impactful to this work, as weLL as to me as a graduate student. I appreciate your kindness, advice, and enthusiasm towards my creative work as we coLLaborated throughout this research process. I would like to thank my thesis committee members Professor Tong Wang and Professor Vitor Luiz for your encouragement and guidance. -

The Modern Dances, How to Dance Them, by Caroline Walker
Library of Congress The modern dances, how to dance them, by Caroline Walker; complete instructions for the tango, the Castle walk, the walking Boston, the hesitation waltz, the dream waltz GV 1755 .W3 1914 The MODERN DANCES TANGO CASTLE WALK HESITATION WALTZ ONE STEP DREAM WALTZ By CAROLINE WALKER LIBRARY OF CONGRESS [???] 00004207129 Class GV 1755 Book W3 Copyright N o . 1914b COPYRIGHT DEPOSIT. THE MODERN DANCES First Edition, Jan. 27, 1914 Second Edition, Feb. 12, 1914 Third Edition, March 20, 1914 The modern dances, how to dance them, by Caroline Walker; complete instructions for the tango, the Castle walk, the walking Boston, the hesitation waltz, the dream waltz http://www.loc.gov/resource/musdi.161 Library of Congress Photographs by Archibald Studio Chicago THE Modern Dances How to Dance Them BY CAROLINE WALKER COMPLETE INSTRUCTIONS FOR LEARNING The Tango, or One Step The Castle Walk The Walking Boston The Hesitation Waltz The Dream Waltz The Argentine Tango LC PUBLISHED BY SAUL BROTHERS 626 FEDERAL ST., CHICAGO 1914 GV1755 .W3 1914b Copyright, 1914, by Saul Brothers LC $1.00 APR -6 1914 ©CI.A369669 no 1 The modern dances, how to dance them, by Caroline Walker; complete instructions for the tango, the Castle walk, the walking Boston, the hesitation waltz, the dream waltz http://www.loc.gov/resource/musdi.161 Library of Congress THIS book is dedicated to those who enjoy dancing, who wish to dance the new dances properly and gracefully, and who desire to learn such steps and figures as may be performed at any dancing party. 6 Table -

Elements of Argentine Tango a Resource Manual for Dancers
Elements of Argentine Tango A Resource Manual for Dancers http://abqtango.org 1 History of Argentine Tango by Mike Higgins When talking about the history of the Tango, the reader should consider that although there were many ‘influences’ in the creation and life of the Tango, it is very important not to assume that it was some form of linear development Whilst dances and music from around the world have had some influence, this rather detracts from the people who really created and evolved the Tango into its current form. These are the people of Buenos Aires, who in the bars, cafes and dance halls made the Tango, danced the Tango, lived, loved and occasionally died for the Tango. It is the voice of the streets of Buenos Aires. Any suggestion that they may be dancing some sort of second hand steps or regurgitating music taken from Europe or Africa must be rejected as some what insulting to all the great milongueros who have danced and innovated down though years. It is equally insulting to the great Tango maestros who have drawn on their own life experiences when composing music. Almost certainly, the most important factor in the evolution of the Tango was the influence brought in by the Habanera, created in Havana, Cuba, and also known as the Andalusian Tango. Unfortunately there is now insufficient information to assess exactly how this was originally danced. The Habanera was based on the concept of a ’walk’, the same as the Tango. At some point the Milonga and The Habanera were fused to form the embryonic version of the Tango. -

Tangoconnection
Tango connection Tangoconnection Marianka Swain talks tango movement and music with master Germán Cornejo. Photographs by Federico Paleo Galeassi. “We have the same values and the breath becoming increasingly about work, family and life, we intensive through the song.” know what we want, and we work Enhancing that purity is the use of hard to achieve our dreams.” music from the great Astor Piazzolla, The pair now run their own company. “portraying the contemporary, “I normally work more closely with melancholy and bohemian Buenos the creativity and musicality of our Aires after dark, with a live band of the pieces, while Gisela pays attention to best musicians and two of the finest cleaning the sequences or steps. She’s singers from Argentina”. Cornejo first an extraordinary dancer, highly skilled heard Piazzolla’s album Libertango aged and very disciplined, with the charisma 12. “I remember crying almost all the of a true artist. I love that, and dancing way through, because it touched me with her makes me feel complete. I so deeply. His compositions represent think the fact that both of us admire the Buenos Aires of today – that and respect each other as artists is the inspired me more than anything.” secret to our successful partnership.” Composer, arranger and bandoneon Crucially, their company’s shows Piazzolla revolutionised tango in the incorporate a live band and singers. middle of the 20th century, creating Tango Fire “showed tango’s evolution a nuevo tango sound by blending through the decades with the band’s traditional music with recognisable amazing music”, while Break the western forms such as jazz. -

SOLO DANCE Elimination Final Primary Double Cross Waltz Balanciaga Academy Blues American March
SOLO DANCE Elimination Final Primary Double Cross Waltz Balanciaga Academy Blues American March Juvenile A Siesta Tango Blue Danube Waltz Rhythm Blues Denver Shuffle Elementary A La Vista Cha Cha Bayou Polka Bounce Boogie Swing Dance Juv/Elem B Rhythm Blues Dutch Waltz Chasse Waltz Siesta Tango Juv/Elem C Glide Waltz Academy Blues Progressive Tango Skaters March _____________________________________________________________________________________________ Freshman A California Swing Delicado Border Blues Casino March Sophomore A Princeton Polka Viva Cha Cha Carroll Swing Keats Foxtrot _____________________________________________________________________________________________ Fr/Soph B Bounce Boogie Southland Swing Siesta Tango La Vista Cha Cha Fr/SophC City Blues Swing Waltz Denver Shuffle Balanciaga Bronze Swing Schottische Double Cross Waltz Div 1, 2, & 3 Canasta Tango City Blues Silver Tara Tango Luna Blues Div 1, 2, & 3 Carey Foxtrot Criss Cross March Gold 14 Step Chase Waltz Div 1 California Swing Joann Foxtrot Gold Zig ZagPolka Syncopated Swing Div 2 & 3 Milonga Tango Century Blues Classic Gold Carroll Swing Dench Blues Paso Doble Keats Foxtrot Junior American Rocker Foxtrot Willow Waltz Paso Doble Dench Blues Senior American Westminister Waltz (138) Killian (100, 2/4) Quickstep (100, 6/8) Argentine Tango (96) Tiny Tots – CoEd Progressive Tango Glide Waltz TEAM DANCE Juvenile Double Cross Waltz Skaters March Denver Shuffle Swing Waltz Elementary Chase Waltz Casino Tango Rhythm Blues Swing Dance Freshman/ 14 Step Border Blues Sophomore A Joann Foxtrot Mirror Waltz Fr/Soph B Blue Danube Waltz Chase Waltz Siesta Tango Bounce Boogie Fr Soph C City Blues Balanciaga Swing Waltz Denver Shuffle Bronze Double Cross Waltz Canasta Tango Div 1, 2, & 3 Swing Schottische City Blues Silver Tara Tango Golden Skater Waltz Div 1, 2, & 3 Pilgrim Waltz Criss Cross March Gold Southland Swing 14 Step Div 1 Joann Foxtrot California Swing Gold Zig Zag Polka Milonga Tango Div 2 & 3 Century Blues Pilgrim Waltz Classic Gold Dench Blues Keats Foxtrot Continental Waltz Paso Doble . -

Ballet Hispanico at the Joyce, Program B
http://www.edgenewyork.com/index.php?ch=entertainment&sc=theatre&sc2=reviews&sc3=&id =143258 Ballet Hispanico at the Joyce, Program B Saturday Apr 27, 2013 - By Steve Weinstein If my EDGE review of Ballet Hispanico’s Program A at the just-completed season at the Joyce was less than ecstatic, I had no such qualms when experiencing the sheer joy of "Ballet Hispanico: Program B." The three separate works showed how profoundly this American troupe has spanned the wide world of Latino dance and distilled it to its essence. Vanessa Valecillo and Jamal Rashann Callender in ’Tango Vitrola’ (Source:Paula Lobo) From the moment that a male soloist appeared on the stage, his arms clasped high over his head - - those defiant gestures that define flamenco -- I was prepared to enter the world of flamenco. Derived from several sources, over its long history, flamenco assimilated gypsy and folk dances, put it into the small neighborhood clubs of Andalusia and turned it into an art form. Normally, flamenco is accompanied by singer-shouters who rhythmically clap their hands in a quirky syncopation. The last all-flamenco program I saw put too much emphasis on the singing, with the dancing appearing and re-appearing at intervals. This might be more authentic, but makes less of a pure dance experience. Ballet Hispanico’s "Nube Blanco" dispensed with traditional dialect singing in favor of a more dance-oriented score by Maria Dolores Pradera, all to the good. The audience was able to experience pure flamenco moves uninterrupted by long periods of singing and clapping. -

Whether You Try Ballet, Tango, Or Just Freestyle with Your Friends, Dancing
Leisure Whether you try ballet, Tango, or just freestyle with Dancing gets a 10 your friends, dancing of any fro m Le n sort confers some hile not everyone may be as incredible as tap, jazz, contemporary, bedroom freestyle, or zumba. With an incredible health Michael Flatley, everybody and anybody open mind, you’ll be rocking it on the dance floor in no time! can benefit from giving dance a try. According to a recent survey by the Royal Academy of benefits Whether you try ballet, tango, or just Dance the older you get the less embarrassed you are Wfreestyle with your friends, dancing of any sort confers some to dance. incredible health benefits. Melanie Murphy, RAD’s Director of Marketing Improve learning and memory. Dancing and learning Communications & Membership, said: “The results of this dances activates the cognitive centre of the brain and survey reinforce how dance can help to build self-confidence encourages neural plasticity. This means that neurons are at any age. Our research team within the Faculty of Education healthier and more adaptable throughout life, meaning better have undertaken extensive research into the health and cognitive function as you age. Especially in later years, wellbeing benefits of dance under its Dance for Lifelong skills and neurons enhanced through dance are incredibly Wellbeing project, with one key audience being the 60 plus important in maintaining memory function. It is also one of market. In response to the research last year, we launched a the few forms of physical activity that effectively protects programme of Silver Swans™ classes to meet the demand against dementia.