A Novel Application of Fuzzy Set Theory and Topic Model in Sentence Extraction for Vietnamese Text
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
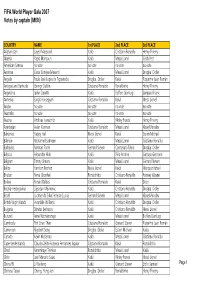
Final MEN by Coach and Captain
FIFA World Player Gala 2007 Votes by captain (MEN) COUNTRY NAME 1st PLACE 2nd PLACE 3rd PLACE Afghanistan Sayed Maqsood Kaká Cristiano Ronaldo Henry Thierry Algeria Yazid Mansouri Kaká Messi Lionel Cech Petr American Samoa no vote no vote no vote no vote Andorra Óscar Sonejee Masand Kaká Messi Lionel Drogba Didier Angola Paulo José Lopes de Figueiredo Drogba Didier Kaká Riquelme Juan Román Antigua and Barbuda George Dublin Cristiano Ronaldo Ronaldinho Henry Thierry Argentina Javier Zanetti Kaká Buffon Gianluigi Lampard Frank Armenia Sargis Hovsepyan Cristiano Ronaldo Kaká Messi Lionel Aruba no vote no vote no vote no vote Australia no vote no vote no vote no vote Austria Andreas Ivanschitz Kaká Ribéry Franck Henry Thierry Azerbaijan Aslan Karimov Cristiano Ronaldo Messi Lionel Klose Miroslav Bahamas Happy Hall Messi Lionel Kaká Essien Michael Bahrain Mohamed Salmeen Kaká Messi Lionel Cristiano Ronaldo Barbados Norman Forde Gerrard Steven Cannavaro Fabio Drogba Didier Belarus Alexander Hleb Kaká Pirlo Andrea Gattuso Gennaro Belgium Timmy Simons Kaká Messi Lionel Gerrard Steven Belize Harrison Rochez Messi Lionel Kaká Márquez Rafael Bhutan Pema Chophel Ronaldinho Cristiano Ronaldo Rooney Wayne Bolivia Ronald Baldes Cristiano Ronaldo Kaká Deco Bosnia-Herzegovina Zvjezdan Misimovic Kaká Cristiano Ronaldo Drogba Didier Brazil Lucimar da Silva Ferreira (Lucio) Gerrard Steven Messi Lionel Klose Miroslav British Virgin Islands Avondale Williams Kaká Cristiano Ronaldo Drogba Didier Bulgaria Dimitar Berbatov Kaká Cristiano Ronaldo Messi Lionel Burundi -

P19 Layout 1
THURSDAY, MARCH 19, 2015 SPORTS Leverkusen nerves prove costly again SPAIN: Bayer Leverkusen failed once more goal, hopes of finally ending their losing to hold their nerve in a crucial game, going run in the round of 16 were ignited. out on penalties against Atletico Madrid in Roger Schmidt’s team have been play- the Champions League last 16. ing a good season in the Bundesliga, sitting Leverkusen, nicknamed ‘Neverkusen’ for in fourth place with their exciting brand of narrowly missing out on silverware over quick, counter-attacking football with the the years, last reached the quarter-finals of addition of Calhanoglu and Karim Bellarabi the competition in 2002 when they went all this season. the way to the final before losing to Real The Spanish champions, losing finalists Madrid. last season, were in no way spectacular in Not many favored Leverkusen to the first leg and were on the backfoot again advance but after their first leg 1-0 win in on Tuesday until they scored following Germany courtesy of Hakan Calhanoglu’s some sloppy defending midway through the first half. But Leverkusen failed to make posses- sion count and then missed three penalties Matches on TV in the shootout after the game ended 1-0 after extra time. (Local Timings) Their opponents were equally bad from the spot, missing two penalties themselves UEFA Europa League before striker Stefan Kiessling sent a wild effort over the crossbar with the Bundesliga side’s fifth penalty to send Dinamo v SSC Napoli 20:00 Atletico through. beIN SPORTS 1 HD “We were not courageous enough,” said beIN SPORTS 11 HD Leverkusen defender Gonzalo Castro. -

Madam Pele: Novel and Essay
Edith Cowan University Research Online Theses: Doctorates and Masters Theses 2006 Madam Pele: Novel and essay Jud L. House Edith Cowan University Follow this and additional works at: https://ro.ecu.edu.au/theses Part of the Creative Writing Commons Recommended Citation House, J. L. (2006). Madam Pele: Novel and essay. https://ro.ecu.edu.au/theses/37 This Thesis is posted at Research Online. https://ro.ecu.edu.au/theses/37 Edith Cowan University Copyright Warning You may print or download ONE copy of this document for the purpose of your own research or study. The University does not authorize you to copy, communicate or otherwise make available electronically to any other person any copyright material contained on this site. You are reminded of the following: Copyright owners are entitled to take legal action against persons who infringe their copyright. A reproduction of material that is protected by copyright may be a copyright infringement. Where the reproduction of such material is done without attribution of authorship, with false attribution of authorship or the authorship is treated in a derogatory manner, this may be a breach of the author’s moral rights contained in Part IX of the Copyright Act 1968 (Cth). Courts have the power to impose a wide range of civil and criminal sanctions for infringement of copyright, infringement of moral rights and other offences under the Copyright Act 1968 (Cth). Higher penalties may apply, and higher damages may be awarded, for offences and infringements involving the conversion of material into digital or electronic form. USE OF THESIS The Use of Thesis statement is not included in this version of the thesis. -

Uefa Champions League
UEFA CHAMPIONS LEAGUE - 2017/18 SEASON MATCH PRESS KITS (First leg: 1-1) Camp Nou - Barcelona Wednesday 14 March 2018 FC Barcelona 20.45CET (20.45 local time) Chelsea FC Round of 16, Second leg UEFA CHAMPIONS LEAGUE OFFICIAL SPONSORS Previous meetings 2 Match background 10 Squad list 14 Head coach 16 Match officials 17 Fixtures and results 20 Match-by-match lineups 24 Competition facts 26 Team facts 28 Legend 31 1 FC Barcelona - Chelsea FC Wednesday 14 March 2018 - 20.45CET (20.45 local time) Match press kit Camp Nou, Barcelona Previous meetings Head to Head UEFA Champions League Date Stage Match Result Venue Goalscorers 20/02/2018 R16 Chelsea FC - FC Barcelona 1-1 London Willian 62; Messi 75 UEFA Champions League Date Stage Match Result Venue Goalscorers Sergio Busquets 35, 2-2 24/04/2012 SF FC Barcelona - Chelsea FC Barcelona Iniesta 43; Ramires agg: 2-3 45+1, Torres 90+2 18/04/2012 SF Chelsea FC - FC Barcelona 1-0 London Drogba 45+2 UEFA Champions League Date Stage Match Result Venue Goalscorers 1-1 06/05/2009 SF Chelsea FC - FC Barcelona London Essien 9; Iniesta 90+3 agg: 1-1 ag 28/04/2009 SF FC Barcelona - Chelsea FC 0-0 Barcelona UEFA Champions League Date Stage Match Result Venue Goalscorers Deco 3, Gudjohnsen 31/10/2006 GS FC Barcelona - Chelsea FC 2-2 Barcelona 58; Lampard 52, Drogba 90+3 18/10/2006 GS Chelsea FC - FC Barcelona 1-0 London Drogba 47 UEFA Champions League Date Stage Match Result Venue Goalscorers 1-1 Ronaldinho 78; 07/03/2006 R16 FC Barcelona - Chelsea FC Barcelona agg: 3-2 Lampard 90+2 (P) Thiago Motta 59 (og); -

Larsson Vs. Ljungberg
2006-05-15 15:29 CEST Larsson vs. Ljungberg På onsdag är det dags för årets hittills viktigaste fotbollsmatch på Stade de France, finalen i Champions League. En av våra svenska superstjärnor kommer att leda sitt klubblag till den tyngsta av titlar i europeisk klubbfotboll. Ladbrokes erbjuder hela 18 spel på Champions League-finalen och har Barcelona som favorit till 2,00 gånger pengarna mot Arsenals 3,20 gånger pengarna. Gör Henrik Larsson mål betalar Ladbrokes tillbaka 3,50 och Fredrik Ljungberg ger 5,50. Barcelona har massor av självförtroende och efter vinsten i La Liga med en Ronaldinho i form tyder det mesta på att Barcelona vinner säger Nicklas Kulti, Ladbrokes Sverigechef, som fortsätter, men Arsenal kan spela avslappnat som outsider med en säkrad Champions League-plats efter slutspurten i Premier League och är ur ett spelperspektiv högintressant. Ladbrokes odds i urval Europeisk - Champions League - (1 - X - 2 (90 min) Barcelona Arsenal 2.00 3.20 3.20 Europeisk - Champions League - (Antal mål i matchen) Inget mål 7.00 1mål 4.00 2 mål 3.40 3 mål 4.00 4 mål 6.00 5 mål 11.00 6 mål 23.00 7 mål 34.00 Europeisk - Champions League - (Spelare som gör mål (90 min) Thierry Henry 2.50 Samuel Eto'o 2.75 Ronaldinho 2.75 Henke Larsson 3.50 Ludovic Giuly 3.75 Maxi Lopez 4.00 Dennis Bergkamp 4.00 Robin van Persie 4.00 Deco 5.00 Santiago Ezquerro 5.00 Freddie Ljungberg 5.50 Jose Antonio Reyes 5.50 Mark van Bommel 5.50 Robert Pires 5.50 Theo Walcott 6.00 Thiago Motta 8.00 Francesc Fabregas 8.00 Alexsandr Hleb 8.00 Alexandre Song 9.00 Xavi 10.00 -

Chicago Art Deco Society Havana Magazine
March 2013 Special Issue A Meeting in Havana: A Preview of the 12th World Congress on Art Deco Havana Art Deco Bacardi Building Buenos Aires Art Deco Puerto Rican Art Deco Aracaju, Brazil Art Deco Art Deco Graphics Coolidge Corner-Deco Theatre CADS Board of Directors Joe Loundy/President President´s message Conrad Miczko/Vice President Robert Blanford/Secretary The Chicago Art Deco Society is pleased to collaborate with Habana Deco to bring you this Mary Miller/Treasurer Ruth Dearborn special World Congress supplement of the Chicago Art Deco Society Magazine. The articles Amy Keller highlight many of the Art Deco treasures in Havana and other parts of Cuba included on the Susan Levand Kevin Palmer itinerary for the 12th World Congress on Art Deco. CADS greatly appreciates Habana Deco’s Glenn Rogers Bill Sandstrom commitment to the organization of what promises to be a unique and outstanding conference. CADS Advisory Board Joseph Loundy / President, Chicago Art Deco Society. Richard Goisman Katherine Hamilton-Smith Seymour Persky INDEX Steve Starr A gift to my country 3 Social, a Pioneer 43 in Cuban Graphic Arts CADS Magazine Special World Congress Issue A Meeting in Havana: 4 Chief Editor: Geo Darder A Preview of the 12th World Eusebio Leal: 44 General Editorial Coordinator: Past, Present, and Future Mónica Palenque Congress on Art Deco Editor: Kathleen Murphy Skolnik Copy Editor: Linda Levendusky Art Deco in Havana: 6 The Coolidge Corner Theatre 45 Graphic Designer: Luis Alonso Brookline, Massachusetts Translations: Vivian Figueredo, -

Uefa.Com Team of the Year 2006
Media Release Date: 06/12/2006 Communiqué aux médias No. 139 Medien-Mitteilung uefa.com Team of the Year 2006 Fans can vote online until 4 January 2007 Voting opens today for the uefa.com users’ Team of the Year 2006. The poll, now in its sixth year, gives the users of uefa.com, Europe’s football website, the chance to select a team of players who made their mark in European football over the last 12 months. Sixty players and managers have been nominated for 12 positions, including coach, and the final team will be announced on 19 January 2007 on uefa.com and in the January issue of Champions magazine. The nominees were chosen by uefa.com staff writers on the basis of their coverage of football throughout Europe on a daily basis. The players were selected for their overall performances either for a European club or national team, or in a UEFA club competition in 2006. The uefa.com Team of the Year is not intended as a rival to more established awards, and does not bear the official UEFA imprimatur. Nevertheless, it has already proved hugely popular with fans, and over eight million votes have been cast in previous polls. European champions FC Barcelona have the most nominees with eleven, while UEFA Champions League runners-up Arsenal have seven. English champions Chelsea FC have received six nominations and French champions Olympique Lyonnais and UEFA Cup holders Sevilla FC have five apiece. In total, 19 clubs have players nominated. Eight members of Italy’s FIFA World Cup-winning squad plus coach Marcello Lippi have been nominated. -

AC MILAN V FC BARCELONA
Matchday Three Milan 20 October 2004 AC MILAN – FC BARCELONA STADIO GIUSEPPE MEAZZA, MILAN WEDNESDAY 20 OCTOBER 2004 at 20.45 UEFA CHAMPIONS LEAGUE GROUP F, MATCHDAY 3 AC MILAN v FC BARCELONA After the thrilling game against Celtic FC, resolved in AC Milan’s favour by two late goals, UEFA Champions League football returns to San Siro with an exciting clash between two former champions of Europe and the two teams who met in the 1994 final in Athens. Both are among the seven clubs who have opened their campaign with maximum points from two matches and the Group F table might suggest that they hold a comfortable advantage over their adversaries. However, while the two former champions are trying to take points from each other, the other Group F participants will be trying to make up ground and mount a serious challenge to the favourites. The fans are promised two epic confrontations between two of Europe’s most experienced campaigners and this match will be a special occasion for Frank Rijkaard, who after a successful playing career with AC Milan, returns to the Stadio Giuseppe Meazza as the head coach of FC Barcelona. Bearing in mind that the two clubs have jointly played 635 European matches and 301 in the continent’s premier competition, it’s surprising that they’ve met only four times and that they had a spell of 30 years from 1959 to 1989 without crossing paths. In the UEFA Champions League, this is only the second time that they have met on a home-and-away basis apart from the 1994 final in Athens, when Fabio Capello’s AC Milan beat Johan Cruyff’s FC Barcelona 4-0. -

Portugal Dio Un Baño a España, Que Sólo Reaccionó Tras El 0-1 Y Se Topó Dos Veces Con Los Palos
4 MUNDO DEPORTIVO Lunes 21 de junio de 2004 GRUPO A Portugal-Grecia-España-Rusia ESPAÑA-PORTUGAL 0-1 LA CRÓNICA Javier Gascón (Lisboa) A casa y sin excusas Portugal dio un baño a España, que sólo reaccionó tras el 0-1 y se topó dos veces con los palos España, 0 ñoles que acudieron al José Alva- Casillas (3); Puyol (2), Iván Helguera (2), Juanito (2), Raúl Bravo lade intentaban reanimar a la se- (1); Albelda (1), Xabi Alonso (1); Joaquín (2), Raúl (1), Vicente lección, pero el entusiasmo de los (2); Fernando Torres (3) 34.000 restantes empujaba a Portu- Sustituciones Baraja (1) por Albelda (min. 66); Luque (1) por Joaquín (min. gal. Sólo Fernando Torres, con ca- 72); Morientes (1) por Juanito (min. 80) balgadas en solitario, inquietaba Entrenador a la zaga lusa. Fue el único de los Iñaki Sáez jóvenes que no acusó la presión. Portugal, 1 Un entrenador más valiente hu- Ricardo (3); Miguel (3), Jorge Andrade (3). Ricardo Carvalho (4), biese hecho un cambio en el minu- Nuno Valente (2); Maniche (3), Costinha (3); Figo (3), Deco (4), Cristiano Ronaldo (4); Pauleta (1) to 30, Pero Iñaki Sáez debió pensar Sustituciones que si el marcador reflejaba un Nuno Gomes (3) por Pauleta (min. 46); Petit (2) por Figo (min. empate y Torres había rozado el 78); Fernando Couto (s.c.) por Cristiano Ronaldo (min. 85) gol con un cabezazo tras un saque Entrenador Luiz Felipe Scolari de esquina es que no había tanta Gol superioridad portuguesa. Grave 0-1, Nuno Gomes (min. 57) error. -

Uefa Euro 2016
UEFA EURO 2016 MATCH PRESS KITS Stade de France - Saint-Denis Sunday 10 July 2016 - 21.00CET Matchday 7 - Final Portugal #PORFRA France Last updated 10/07/2016 01:06CET UEFA EURO 2016 OFFICIAL SPONSORS Previous meetings 2 Match background 3 Squad list 5 Head coach 7 Match officials 8 Competition facts 10 Match-by-match lineups 14 Team facts 17 Legend 20 1 Portugal - France Sunday 10 July 2016 - 21.00CET (21.00 local time) Match press kit Stade de France, Saint-Denis Previous meetings Head to Head FIFA World Cup Date Stage Match Result Venue Goalscorers 05/07/2006 SF Portugal - France 0-1 Munich Zidane 33 UEFA EURO 2000 Date Stage Match Result Venue Goalscorers Henry 51, Zidane 117 2-1 28/06/2000 SF France - Portugal Brussels ET (P); Nuno Gomes (aet) 19 1984 UEFA European Championship Date Stage Match Result Venue Goalscorers Domergue 24, 114 3-2 23/06/1984 SF France - Portugal Marseille ET, Platini 119 ET; (aet) Rui Jordão 74, 98 ET Final Qualifying Total tournament Home Away Pld W D L Pld W D L Pld W D L Pld W D L GF GA EURO Portugal - - - - - - - - 2 0 0 2 2 0 0 2 3 5 France - - - - - - - - 2 2 0 0 2 2 0 0 5 3 FIFA* Portugal - - - - - - - - 1 0 0 1 1 0 0 1 0 1 France - - - - - - - - 1 1 0 0 1 1 0 0 1 0 Friendlies Portugal - - - - - - - - - - - - 21 5 1 15 25 43 France - - - - - - - - - - - - 21 15 1 5 43 25 Total Portugal - - - - - - - - 3 0 0 3 24 5 1 18 28 49 France - - - - - - - - 3 3 0 0 24 18 1 5 49 28 * FIFA World Cup/FIFA Confederations Cup 2 Portugal - France Sunday 10 July 2016 - 21.00CET (21.00 local time) Match press kit Stade de France, Saint-Denis Match background Portugal can lay the ghost of their UEFA EURO 2004 final defeat in Saint-Denis, but the UEFA EURO 2016 hosts have not lost a game against their Stade de France opponents since almost ten years before Cristiano Ronaldo was born. -

Full Time Report FC BARCELONA LIVERPOOL FC
Full Time Report First Knock-out Round 1st leg - Wednesday 21 February 2007 Camp Nou - Barcelona FC BARCELONA LIVERPOOL FC 120:45 2 (1) (1) half time half time 20 DECO 14' 1 VALDÉS Víctor 25 REINA Pepe 2 BELLETTI Juliano 23' 5 Daniel AGGER 2 ARBELOA Álvaro 3 MOTTA Thiago 3 FINNAN Steve 4 MÁRQUEZ Rafael 5 AGGER Daniel 5 PUYOL Carles 6 RIISE John Arne 6 XAVI HERNÁNDEZ 8 GERRARD Steven 10 RONALDINHO 14 ALONSO Xabi 11 ZAMBROTTA Gianluca 35' 18 Dirk KUYT 17 BELLAMY Craig 19 MESSI Lionel 18 KUYT Dirk 20 DECO 22 SISSOKO Mohamed 22 SAVIOLA Javier 2 Juliano BELLETTI 38' 23 CARRAGHER Jamie 43' 17 Craig BELLAMY 25 JORQUERA Albert 1 DUDEK Jerzy 7 GUDJOHNSEN Eidur 4 HYYPIÄ Sami 8 GIULY Ludovic 11 GONZALEZ Mark 12 VAN BRONCKHORST Giovanni 45' 15 CROUCH Peter 21 THURAM Lilian 1'01" 16 PENNANT Jermaine 23 OLEGUER 20 MASCHERANO Javier 24 INIESTA Andrés 32 ZENDEN Boudewijn Coach: Coach: RIJKAARD Frank BENÍTEZ Rafael Half Full 24 Andrés INIESTA in Half Full out 54' Total shots 8 14 3 Thiago MOTTA Total shots 2 7 On goal 2 4 On goal 1 5 Wide 4 8 61' 22 Mohamed SISSOKO Wide 1 2 Blocked 2 2 Blocked 0 0 Free kicks to goal 0 2 Free kicks to goal 0 2 in Saves 0 3 8 Ludovic GIULY Saves 1 2 6 XAVI HERNÁNDEZ out 65' Corners 4 6 Corners 0 2 Fouls committed 8 17 Fouls committed 14 29 Fouls suffered 13 28 Fouls suffered 8 16 Offside 3 5 74' 6 John Arne RIISE Offside 3 6 Possession 63% 62% Possession 37% 38% Ball in play 17' 33' 77' 17 Craig BELLAMY Ball in play 10' 20' Total ball in play 27' 53' in 16 Jermaine PENNANT Total ball in play 27' 53' 80' out 17 Craig BELLAMY in Referee: 7 Eidur GUDJOHNSEN out 82' VASSARAS Kyros (GRE) 22 Javier SAVIOLA in 32 Boudewijn ZENDEN Assistant referees: 84' out 22 Mohamed SISSOKO BOZATZIDIS Dimitrios (GRE) SARAIDARIS Dimitrios (GRE) Fourth official: TSACHILIDIS Ioannis (GRE) 90' UEFA delegate: in 15 Peter CROUCH LAURINEC František (SVK) 11 Gianluca ZAMBROTTA 4'34" out 18 Dirk KUYT 22:38:05 CET Goal Booked Sent off Substitution Penalty Owngoal Captain Goalkeeper Misses next match if booked 21 Feb 2007 UEFA Media Information. -

068: Referee Appointed for UEFA Champions League Final
Media Release Date: 19/05/2008 Communiqué aux médias No. 068 Medien-Mitteilung Referee appointed for UEFA Champions League final The UEFA Referees Committee today announced the referee for the final of the 2007/08 UEFA Champions League between Manchester United FC and Chelsea FC to be played at the Luzhniki Stadium in Moscow on Wednesday 21 May, kicking-off at 20.45 CET (22.45 local time in Moscow). The match will be handled by Slovakian referee Lubos Michel, who celebrated his 40th birthday last Friday. Born in Stropkov, he made his refereeing debut at a 6th-category match between FK Duplin and FK Strocin in 1987. By 1993, he had graduated to the top division and, in the November of that year, made his international debut at a match involving England – a European Under-21 Championship fixture against San Marino. Lubos Michel was at the Sydney Olympics in 2000 and handled the Brazil v Argentina final of the 2005 FIFA Confederations Cup (Carlos Tévez was 72nd-minute sub). He had become the first referee from the independent Slovakia to officiate at a FIFA World Cup match (the Paraguay v South Africa fixture in 2002). At the 2006 finals he refereed the Portugal v Mexico game (Paulo Ferreira and Ricardo Carvalho played; Cristiano Ronaldo was on the bench), plus the Brazil v Ghana match (Michael Essien unused) and the Argentina v Germany game that featured Michael Ballack and Carlos Tévez. Lubos Michel was referee of the 2003 UEFA Cup final in Seville between FC Porto and Celtic FC. At EURO 2004, he handled the Greece v Spain, Switzerland v France and Sweden v Netherlands games.