Semantic Audio Analysis Utilities and Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Head-Order Techniques and Other Pragmatics of Lambda Calculus Graph Reduction
HEAD-ORDER TECHNIQUES AND OTHER PRAGMATICS OF LAMBDA CALCULUS GRAPH REDUCTION Nikos B. Troullinos DISSERTATION.COM Boca Raton Head-Order Techniques and Other Pragmatics of Lambda Calculus Graph Reduction Copyright © 1993 Nikos B. Troullinos All rights reserved. No part of this book may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording, or by any information storage and retrieval system, without written permission from the publisher. Dissertation.com Boca Raton, Florida USA • 2011 ISBN-10: 1-61233-757-0 ISBN-13: 978-1-61233-757-9 Cover image © Michael Travers/Cutcaster.com Abstract In this dissertation Lambda Calculus reduction is studied as a means of improving the support for declarative computing. We consider systems having reduction semantics; i.e., systems in which computations consist of equivalence-preserving transformations between expressions. The approach becomes possible by reducing expressions beyond weak normal form, allowing expression-level output values, and avoiding compilation-centered transformations. In particular, we develop reduction algorithms which, although not optimal, are highly efficient. A minimal linear notation for lambda expressions and for certain runtime structures is introduced for explaining operational features. This notation is related to recent theories which formalize the notion of substitution. Our main reduction technique is Berkling’s Head Order Reduction (HOR), a delayed substitution algorithm which emphasizes the extended left spine. HOR uses the de Bruijn representation for variables and a mechanism for artificially binding relatively free variables. HOR produces a lazy variant of the head normal form, the natural midway point of reduction. It is shown that beta reduction in the scope of relative free variables is not hard. -

Song List 2012
SONG LIST 2012 www.ultimamusic.com.au [email protected] (03) 9942 8391 / 1800 985 892 Ultima Music SONG LIST Contents Genre | Page 2012…………3-7 2011…………8-15 2010…………16-25 2000’s…………26-94 1990’s…………95-114 1980’s…………115-132 1970’s…………133-149 1960’s…………150-160 1950’s…………161-163 House, Dance & Electro…………164-172 Background Music…………173 2 Ultima Music Song List – 2012 Artist Title 360 ft. Gossling Boys Like You □ Adele Rolling In The Deep (Avicii Remix) □ Adele Rolling In The Deep (Dan Clare Club Mix) □ Afrojack Lionheart (Delicious Layzas Moombahton) □ Akon Angel □ Alyssa Reid ft. Jump Smokers Alone Again □ Avicii Levels (Skrillex Remix) □ Azealia Banks 212 □ Bassnectar Timestretch □ Beatgrinder feat. Udachi & Short Stories Stumble □ Benny Benassi & Pitbull ft. Alex Saidac Put It On Me (Original mix) □ Big Chocolate American Head □ Big Chocolate B--ches On My Money □ Big Chocolate Eye This Way (Electro) □ Big Chocolate Next Level Sh-- □ Big Chocolate Praise 2011 □ Big Chocolate Stuck Up F--k Up □ Big Chocolate This Is Friday □ Big Sean ft. Nicki Minaj Dance Ass (Remix) □ Bob Sinclair ft. Pitbull, Dragonfly & Fatman Scoop Rock the Boat □ Bruno Mars Count On Me □ Bruno Mars Our First Time □ Bruno Mars ft. Cee Lo Green & B.O.B The Other Side □ Bruno Mars Turn Around □ Calvin Harris ft. Ne-Yo Let's Go □ Carly Rae Jepsen Call Me Maybe □ Chasing Shadows Ill □ Chris Brown Turn Up The Music □ Clinton Sparks Sucks To Be You (Disco Fries Remix Dirty) □ Cody Simpson ft. Flo Rida iYiYi □ Cover Drive Twilight □ Datsik & Kill The Noise Lightspeed □ Datsik Feat. -

Biography Mark Ronson Is an Internationally Renowned DJ and Five-Time-Grammy-Award-Winning and Golden Globe-Winning Artist and P
Biography Mark Ronson is an internationally renowned DJ and five-time-Grammy-Award-winning and Golden Globe-winning artist and producer. Ronson spent the first eight years of his life growing up in London, England. Having played guitar and drums from an early age, it wasn't until moving to New York City following his parents’ divorce, that he discovered DJ culture. At age 16, and already a fan of artists like A Tribe Called Quest, Run DMC and the Beastie Boys, Ronson began listening to mixtapes released by various hip hop DJs. Inspired, Ronson confiscated his step-father's vinyl collection and tried his hand at mixing. It was the first step in a career highlighted by work on a multi Grammy-winning album by Amy Winehouse, as well as his own Grammy-winning, global smash hit with Bruno Mars, "Uptown Funk." In the late 1990s into the early 2000s, the New York club scene was percolating with booming hip-hop and glitzy R&B. Ronson quickly earned himself a reputation through stints on the decks in downtown clubs before becoming the DJ of choice for many noteworthy parties. Hip-hop mogul Sean "P. Diddy" Combs hired Ronson to DJ his fabled 29th birthday bash. These and other high-profile gigs boosted Ronson's profile and connected him with other artists, many of whom were interested in collaborating. His first production gig came from British soul singer Nikka Costa and he found that his experience of working a club crowd informed his production skills. Fusing his eclectic turntable skills with his knowledge of musical instruments and songwriting, Ronson soon embarked on his first solo record. -

Song of the Year
General Field Page 1 of 15 Category 3 - Song Of The Year 015. AMAZING 031. AYO TECHNOLOGY Category 3 Seal, songwriter (Seal) N. Hills, Curtis Jackson, Timothy Song Of The Year 016. AMBITIONS Mosley & Justin Timberlake, A Songwriter(s) Award. A song is eligible if it was Rudy Roopchan, songwriter songwriters (50 Cent Featuring Justin first released or if it first achieved prominence (Sunchasers) Timberlake & Timbaland) during the Eligibility Year. (Artist names appear in parentheses.) Singles or Tracks only. 017. AMERICAN ANTHEM 032. BABY Angie Stone & Charles Tatum, 001. THE ACTRESS Gene Scheer, songwriter (Norah Jones) songwriters; Curtis Mayfield & K. Tiffany Petrossi, songwriter (Tiffany 018. AMNESIA Norton, songwriters (Angie Stone Petrossi) Brian Lapin, Mozella & Shelly Peiken, Featuring Betty Wright) 002. AFTER HOURS songwriters (Mozella) Dennis Bell, Julia Garrison, Kim 019. AND THE RAIN 033. BACK IN JUNE José Promis, songwriter (José Promis) Outerbridge & Victor Sanchez, Buck Aaron Thomas & Gary Wayne songwriters (Infinite Embrace Zaiontz, songwriters (Jokers Wild 034. BACK IN YOUR HEAD Featuring Casey Benjamin) Band) Sara Quin & Tegan Quin, songwriters (Tegan And Sara) 003. AFTER YOU 020. ANDUHYAUN Dick Wagner, songwriter (Wensday) Jimmy Lee Young, songwriter (Jimmy 035. BARTENDER Akon Thiam & T-Pain, songwriters 004. AGAIN & AGAIN Lee Young) (T-Pain Featuring Akon) Inara George & Greg Kurstin, 021. ANGEL songwriters (The Bird And The Bee) Chris Cartier, songwriter (Chris 036. BE GOOD OR BE GONE Fionn Regan, songwriter (Fionn 005. AIN'T NO TIME Cartier) Regan) Grace Potter, songwriter (Grace Potter 022. ANGEL & The Nocturnals) Chaka Khan & James Q. Wright, 037. BE GOOD TO ME Kara DioGuardi, Niclas Molinder & 006. -

Analýza Nejposlouchanějších Skladeb Na Serveru Youtube.Com
Masarykova univerzita Pedagogická fakulta ANALÝZA NEJPOSLOUCHANĚJŠÍCH SKLADEB NA SERVERU YOUTUBE.COM Bakalářská práce Brno 2017 Autor: Vedoucí bakalářské práce: Jakub Šindelka doc. PhDr. Marek Sedláček, Ph.D. Anotace Název práce: Analýza nejposlouchanějších skladeb na serveru YouTube.com Title: The analysis of the most listened compositions on YouTube.com Tato práce se zabývá analýzou devatenácti nejposlouchanějších hudebních skladeb na serveru YouTube.com, které byly uploadovány v roce 2014 a později. Seznam je aktuální k datu 1. 7. 2016, práce se tedy zabývá skladbami, které byly nejpopulárnější na serveru YouTube od začátku roku 2014 do poloviny roku 2016. U skladeb je zkoumán jejich žánr, délka, tempo, harmonie, struktura a další charakteristiky, práce se zabývá rovněž interprety těchto skladeb a jejich životem, tvorbou a uměleckou kariérou. Závěrečná část práce je věnována vyhodnocení toho, jaké znaky jsou u skladeb nejčastější a nejtypičtější. Okrajově se práce zabývá rovněž historií a principem fungování serveru YouTube. This thesis is focused on the analysis of the nineteen most listened music compositions on YouTube.com, which were uploaded in 2014 or later. The list is relevant to 1. 7. 2016, therefore the point of interest of the thesis are composions, which were the most popular in the period since the beginning of 2014 to the half of 2016. The aspects of compositions which are analyzed are their genre, lenght, tempo, harmony, structure and other characteristics, thesis also tries to comprehend the life, artworks and carrier of interprets of the compositions. The goal of the final part of this thesis is to evaluate which characteristics of the compositions are the most frequent and the most typical ones. -

The Ithacan, 1977-10-27
Ithaca College Digital Commons @ IC The thI acan, 1977-78 The thI acan: 1970/71 to 1979/80 10-27-1977 The thI acan, 1977-10-27 The thI acan Follow this and additional works at: http://digitalcommons.ithaca.edu/ithacan_1977-78 Recommended Citation The thI acan, "The thI acan, 1977-10-27" (1977). The Ithacan, 1977-78. 10. http://digitalcommons.ithaca.edu/ithacan_1977-78/10 This Newspaper is brought to you for free and open access by the The thI acan: 1970/71 to 1979/80 at Digital Commons @ IC. It has been accepted for inclusion in The thI acan, 1977-78 by an authorized administrator of Digital Commons @ IC. October 27, 1977 Vol. 51/No. 10 Ithaca College published 1nd~pendent1v-bv the students of ltt-)aca College Ithaca, New York Board of Trustees Senior Class BylaWs;TO Be Altered Funds Discussed ~ . ' . The Ithaca College Board of by Nina Jorgensen Wells, James Heston of the New Trµstees bylaws are soon to be York Times, and Barbara Jor altered. Presently, the board The allocation of funds to don, a democratic representative includes two student trustees, wards a nationally renown of Alabama. All of these two· "faculty trustees, and two speaker for graduation and for speakers are quire expensive, staff trustees. At the next senior week were the main topics but the administration will match trustee election the bylaws read of discussion at the student the amount of money used by the that a nember '· of student, Congress meeting on Tuesday Senior class. However, there is a faculty, and staff trustees will b~- night. -

Aynsley Dunbar Retaliation
AYNSLEY DUNBAR RETALIATION Of the numerous British blues-rock bands to spring up in the late '60s, the Aynsley Dunbar Retaliation was one of the better known, though solid reception on tours did not translate into heavy record sales. Musically, the group recalled John Mayall's Bluesbreakers during the 1966-1967 era that had produced that group's A Hard Road album, though with a somewhat more downbeat tone. The similarities were hardly coincidental, as the band's founder and leader, drummer Aynsley Dunbar, had been in the Bluesbreakers lineup that recorded the A Hard Road LP. Too, bassist Alex Dmochowski would go on to play with Mayall in the 1970s, and guitarist Jon Morshead was friendly with fellow axeman Peter Green (also in the Bluesbreakers' A Hard Road lineup), whom he had replaced in Shotgun Express. Though he was only 21 when he formed the Aynsley Dunbar Retaliation, the drummer had already played with several bands of note in both his native Liverpool and London. Stints in several Merseybeat groups had culminated in his joining the Mojos, and Dunbar played on a couple of singles by the group, though these were cut after their British chart hits. Shortly after leaving the Mojos, he did his stint with the Bluesbreakers, after which he played for a few months in the Jeff Beck Group, also appearing on their 1967 single "Tallyman"/"Rock My Plimsoul." Wanting to lead his own band, in mid-1967 he formed the Aynsley Dunbar Retaliation, joined by Morshead, who'd previously been in the Moments (with a pre-Small Faces Steve Marriott), Shotgun Express, and Johnny Kidd & the Pirates; singer/guitarist/keyboardist Victor Brox, who worked for a while with British blues godfather Alexis Korner; and bassist Keith Tillman. -

The Yellow Cloud
THE YELLOW CLOUD A Doc Savage Adventure By Kenneth Robeson THE YELLOW CLOUD Table of Contents THE YELLOW CLOUD....................................................................................................................................1 A Doc Savage Adventure By Kenneth Robeson.....................................................................................1 Chapter I. THE IMPOSSIBLE YELLOW THING................................................................................1 Chapter II. PROOF OF IMPOSSIBLE....................................................................................................8 Chapter III. STRANGE LADYBIRD....................................................................................................12 Chapter IV. MEN AFTER FILM...........................................................................................................20 Chapter V. TELEVISION MIX−UP.....................................................................................................29 Chapter VI. BIG EARS..........................................................................................................................35 Chapter VII. GIRL TRAIL....................................................................................................................42 Chapter VIII. SCHOOLHOUSE LESSON............................................................................................48 Chapter IX. MONK, THE BEAUTIFUL..............................................................................................57 -

IBN February 2005
International Bear News Quarterly Newsletter of the International Association for Bear Research and Management (IBA) and the IUCN/SSC Bear Specialist Group February 2005 vol. 14, no. 1 © Andrés E. Bracho S. Vieu at Parke Tropikal (see page 34). IBA website: www.bearbiology.org/www.bearbiology.com Table of Contents Council News 3 From the President 5 Research & Conservation Grants Program — Editor’s Thank Yous — Newsletter Online 6 Part II: Ways to Donate Money to Bears 8 In Memory: Ralph Flowers 1928-2004 Bear Specialist Group 9 Sri Lanka Sloth Bear Expert Team 2004 Update 11 Bear Specialist Group Coordinating Committee Eurasia 12 Workshop on the Recent Black Bear-human Conflicts in Japan 13 Tibetan Black Bear on Verge of Extinction in China 14 Do Giant Panda Nature Reserves Serve the Needs of Asiatic Black Bears? 16 Bear Trees in North Taiga Landscapes of the Ilich Basin 18 Fatal Bear Attacks on Humans in Romania Website: Slovakia Bear Facts, Myths & Media 19 Bulgaria Bear Management 21 Greece: Monitoring Project Update on the Egnatia Highway Construction 22 Monitoring the Brown Bear in the Italian Alps Through Non-invasive Genetic Sampling Last Female Pyrenean Brown Bear Shot Americas 23 Sierra de Portuguesa Andean Bear Pilot Study 24 The Life History of an Extraordinary Female Barren-ground Grizzly Bear 25 Barren-ground Grizzly Bear Shot in Yellowknife, NWT 26 Central Canada: Ontario Polar/Black Bear Projects, Manitoba Black Bear-human Conflicts Southwest USA: Revising Management Strategies in Arizona, New Mexico Tidbits 27 American -

Exclusive Behind the Scenes Video of Martin Cohen’S 76Th
Exclusive Behind The Scenes Video Of Martin Cohen’s 76th Birthday Party 2015 Definitely one of the best parties anywhere, every year, I’m always honored to attend and sometimes perform with the band. Here’s some exclusive video. Sadly, I had to leave early, to perform with The Mambo Legends Orch and Tito Nieves at West Gate, which is fortunate for me. Check out the videos as I give a little tour and talk to some special people in attendance including the birthday boy. By Pete Nater Harvey Averne, Producer, Musician and Living Legend Harvey Averne is an American record producer, and the founder of CoCo Records, as well as its many subsidiaries. Established in 1972, CoCo was a label specializing in Afro-Cuban and Latin American Popular music, with special emphasis on the “New York Sound”, commonly referred to as “Salsa”. Averne’s gift for identifying and bringing together new and established musical talent, along with the careful management of his artists’ public image, initially made CoCo Records a major label nationally, and subsequently an international success. Over the next decade, he signed internationally known artists and was instrumental in bringing Latin American music into the American cultural mainstream. Averne personally ran the label from 1972 until 1979. His only rival was Fania Records, the leading Latin music label at the time and for whom Averne had previously been employed. He incorporated his new company (in partnership with Sam Goff, previously of Scepter/Wand Records) and quickly became one of the leading record producers in the Latin music field. -
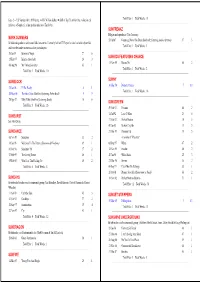
Mark Summers Sunblock Sunburst Sundance
Key - $ = US Number One (1959-date), ✮ UK Million Seller, ➜ Still in Top 75 at this time. A line in red Total Hits : 1 Total Weeks : 11 indicates a Number 1, a line in blue indicate a Top 10 hit. SUNFREAKZ Belgian male producer (Tim Janssens) MARK SUMMERS 28 Jul 07 Counting Down The Days (Sunfreakz featuring Andrea Britton) 37 3 British male producer and record label executive. Formerly half of JT Playaz, he also had a hit a Souvlaki and recorded under numerous other pseudonyms Total Hits : 1 Total Weeks : 3 26 Jan 91 Summers Magic 27 6 SUNKIDS FEATURING CHANCE 15 Feb 97 Inferno (Souvlaki) 24 3 13 Nov 99 Rescue Me 50 2 08 Aug 98 My Time (Souvlaki) 63 1 Total Hits : 1 Total Weeks : 2 Total Hits : 3 Total Weeks : 10 SUNNY SUNBLOCK 30 Mar 74 Doctor's Orders 7 10 21 Jan 06 I'll Be Ready 4 11 Total Hits : 1 Total Weeks : 10 20 May 06 The First Time (Sunblock featuring Robin Beck) 9 9 28 Apr 07 Baby Baby (Sunblock featuring Sandy) 16 6 SUNSCREEM Total Hits : 3 Total Weeks : 26 29 Feb 92 Pressure 60 2 18 Jul 92 Love U More 23 6 SUNBURST See Matt Darey 17 Oct 92 Perfect Motion 18 5 09 Jan 93 Broken English 13 5 SUNDANCE 27 Mar 93 Pressure US 19 5 08 Nov 97 Sundance 33 2 A remake of "Pressure" 10 Jan 98 Welcome To The Future (Shimmon & Woolfson) 69 1 02 Sep 95 When 47 2 03 Oct 98 Sundance '98 37 2 18 Nov 95 Exodus 40 2 27 Feb 99 The Living Dream 56 1 20 Jan 96 White Skies 25 3 05 Feb 00 Won't Let This Feeling Go 40 2 23 Mar 96 Secrets 36 2 Total Hits : 5 Total Weeks : 8 06 Sep 97 Catch Me (I'm Falling) 55 1 20 Oct 01 Pleaase Save Me (Sunscreem -

The Stranglers IV (Rattus Norvegicus) Mp3, Flac, Wma
The Stranglers IV (Rattus Norvegicus) mp3, flac, wma DOWNLOAD LINKS (Clickable) Genre: Rock Album: IV (Rattus Norvegicus) Country: Poland Released: 1991 Style: New Wave, Punk MP3 version RAR size: 1319 mb FLAC version RAR size: 1175 mb WMA version RAR size: 1945 mb Rating: 4.8 Votes: 899 Other Formats: RA DXD MIDI MP1 ADX AUD VQF Tracklist A1 Sometimes 4:54 A2 Goodbye Toulouse 3:16 A3 London Lady 2:31 A4 Princess Of The Streets 4:35 A5 Hanging Around 4:25 B1 Peaches 4:05 B2 (Get A) Grip (On Yourself) 4:01 B3 Ugly 4:06 B4 Down In The Sewer 7:54 B4.1 Falling 1:48 B4.2 Down In The Sewer 1:40 B4.3 Trying To Get Out Again 1:53 B4.4 Rats Rally 1:33 Other versions Category Artist Title (Format) Label Category Country Year Stranglers IV United Artists (Rattus UAG 30045, The Records, UAG 30045, Norvegicus) (LP, UK 1977 FREE 3 Stranglers United Artists FREE 3 Album + 7", Records Single + Ltd) Rattus Parlophone, 7243 5 34406 The 7243 5 34406 Norvegicus (CD, Warner Music Europe Unknown 2 6 Stranglers 2 6 Album, RP) Group Stranglers IV The (Rattus United Artists D-57537 D-57537 Spain 1978 Stranglers Norvegicus) Records (Cass, Album) IV Rattus 1A The 1A Norvegicus (LP, Fame, Liberty Europe Unknown 038-1575301 Stranglers 038-1575301 Album, RE) Stranglers IV Fame, Liberty, FA 3001, UAG The (Rattus FA 3001, UAG United Artists UK Unknown 30045 Stranglers Norvegicus) (LP, 30045 Records Album, RE) Related Music albums to IV (Rattus Norvegicus) by The Stranglers The Stranglers - Something Better Change / Straighten Out The Stranglers - Black And White The Stranglers - Stranglers IV (Rattus Norvegicus) The Stranglers - Grip / London Lady The Stranglers - Peaches / Go Buddy Go The Stranglers - Nice 'n' Sleazy The Stranglers - Duchess The Stranglers - Duchess = Duquesa The Stranglers - Who Wants The World / Bear Cage The Stranglers - IV / Rattus Norvegicus The Stranglers - Choosey Susie The Stranglers -.