Pop Lyrics from Song Titles
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Alice What Dan This Will Hurt. I've Been with Anna. I'm in Love with Her
Alice What Dan This will hurt. I've been with Anna. I'm in love with her. We've been seeing each other for a year. It began at her opening. Alice walks away and gets her stuff Alice I'm going Dan I'm sorry Alice Irrelevant. What are you sorry for? Dan Everything Alice Why didn't you tell me before? Dan Cowardice Alice Is it because she is successful? Dan No it's because she doesn't need me. Alice Did you bring her here? Dan Yes Alice Didn't she get married? Dan She stopped seeing me Alice That's when we went to the country to celebrate our third anniversary. Did you phone her, beg her to come back when you went for your long lovely walks? Dan Yes Alice You're a piece of shit. Dan Deception is brutal. I'm not pretending otherwise. Alice How? How does it work. How do you do this to someone? Not good enough. Dan I fell in love with her Alice. Alice Oh as if you had no choice. There's a moment. There's always a moment. I can do this. I can give in to this. And I don't know when your moment was but I bet you there was one. I'm going. Dan It's not safe out there. Alice And it's safe in here? Dan What about your things? Alice I don't need things. Dan Where will you go? Alice I'll disappear. (beat) Can I still see you? Dan can I still see you? Answer me. -

Guest Host: Macklemore Show Date: Weekend of December 2-3, 2017 Hour One Opening Billboard: None Seg
Show Code: #17-49 INTERNATIONAL Guest Host: Macklemore Show Date: Weekend of December 2-3, 2017 Hour One Opening Billboard: None Seg. 1 Content: #40 “THAT'S WHAT I LIKE” – Bruno Mars #39 “LOVE'S JUST A FEELING” – Lindsey Stirling f/Rooty #38 “DESPACITO” – Luis Fonsi & Daddy Yankee f/Justin Bieber Outcue: JINGLE OUT Segment Time: 11:27 Local Break 2:00 Seg. 2 Content: #37 “WORST IN ME” – Julia Michaels Extra: “ANIMALS” – Maroon 5 #36 “SAY YOU WON'T LET GO” – James Arthur #35 “TOO MUCH TO ASK” – Niall Horan #34 “DON'T TAKE THE MONEY” – Bleachers Outcue: JINGLE OUT Segment Time: 18:51 Local Break 2:00 Seg. 3 Content: #33 “IT AIN’T ME” – Kygo X Selena Gomez Extra: “SET FIRE TO THE RAIN” – Adele #32 “RICH LOVE” – OneRepublic f/SeeB #31 “BODY LIKE A BACK ROAD” – Sam Hunt Outcue: JINGLE OUT Segment Time: 15:00 Local Break 1:00 Seg. 4 ***This is an optional cut - Stations can opt to drop song for local inventory*** Content: AT40 Extra: “THRIFT SHOP” – Macklemore & Ryan Lewis f/Wanz Outcue: “…big it got.” (sfx) Segment Time: 4:25 Hour 1 Total Time: 49:43 END OF HOUR ONE Show Code: #17-49 INTERNATIONAL Show Date: Weekend of December 2-3, 2017 Hour Two Opening Billboard: None Seg. 1 Content: #30 “1-800-273-8255” – Logic f/Alessia Cara & Khalid #29 “SHAPE OF YOU” – Ed Sheeran #28 “NO PROMISES” – Cheat Codes f/Demi Lovato On The Verge: “ONE MORE LIGHT” – Linkin Park Outcue: JINGLE OUT Segment Time: 17:53 Local Break 2:00 Seg. -

An N U Al R Ep O R T 2018 Annual Report
ANNUAL REPORT 2018 ANNUAL REPORT The Annual Report in English is a translation of the French Document de référence provided for information purposes. This translation is qualified in its entirety by reference to the Document de référence. The Annual Report is available on the Company’s website www.vivendi.com II –— VIVENDI –— ANNUAL REPORT 2018 –— –— VIVENDI –— ANNUAL REPORT 2018 –— 01 Content QUESTIONS FOR YANNICK BOLLORÉ AND ARNAUD DE PUYFONTAINE 02 PROFILE OF THE GROUP — STRATEGY AND VALUE CREATION — BUSINESSES, FINANCIAL COMMUNICATION, TAX POLICY AND REGULATORY ENVIRONMENT — NON-FINANCIAL PERFORMANCE 04 1. Profile of the Group 06 1 2. Strategy and Value Creation 12 3. Businesses – Financial Communication – Tax Policy and Regulatory Environment 24 4. Non-financial Performance 48 RISK FACTORS — INTERNAL CONTROL AND RISK MANAGEMENT — COMPLIANCE POLICY 96 1. Risk Factors 98 2. Internal Control and Risk Management 102 2 3. Compliance Policy 108 CORPORATE GOVERNANCE OF VIVENDI — COMPENSATION OF CORPORATE OFFICERS OF VIVENDI — GENERAL INFORMATION ABOUT THE COMPANY 112 1. Corporate Governance of Vivendi 114 2. Compensation of Corporate Officers of Vivendi 150 3 3. General Information about the Company 184 FINANCIAL REPORT — STATUTORY AUDITORS’ REPORT ON THE CONSOLIDATED FINANCIAL STATEMENTS — CONSOLIDATED FINANCIAL STATEMENTS — STATUTORY AUDITORS’ REPORT ON THE FINANCIAL STATEMENTS — STATUTORY FINANCIAL STATEMENTS 196 Key Consolidated Financial Data for the last five years 198 4 I – 2018 Financial Report 199 II – Appendix to the Financial Report 222 III – Audited Consolidated Financial Statements for the year ended December 31, 2018 223 IV – 2018 Statutory Financial Statements 319 RECENT EVENTS — OUTLOOK 358 1. Recent Events 360 5 2. Outlook 361 RESPONSIBILITY FOR AUDITING THE FINANCIAL STATEMENTS 362 1. -

Barbara Mandigo Kelly Peace Poetry Contest Winners
The Gathering by Ana Reisens Adult Category, First Place In the movie we sleep fearlessly on open planes because we cannot imagine any danger more tragic than those that have already passed. For weeks we have been arriving over the earth’s broken skin, over mountains and rivers, shaking the aching flagpoles from our shoulders. Now all the priests and imams and rabbis and shamans are gathered beside the others, teachers, brothers and kings and they’re sharing recipes and cooking sweet stories over fires. Suddenly we hear a voice calling from the sky or within – or is it a radio? – and it sings of quilts and white lilies as if wool and petals were engines. It’s a lullaby, a prayer we all understand, familiar like the scent of a lover’s skin. And as we listen we remember our grandmothers’ hands, the knitted strength of staying, how silence rises like warmth from a woven blanket. And slowly the lines begin to disappear from our skin and our memories spin until we’ve forgotten the I of our own histories and everyone is holy, everyone is laughing, weeping, singing, It’s over, come over, come in. And this is it, the story, an allegory, our movie – the ending and a beginning. The producer doesn’t want to take the risk. No one will watch it, he says, but we say, Just wait. All the while a familiar song plays on the radio and somewhere in a desert far away a soldier in a tank stops as if he’s forgotten the way. -
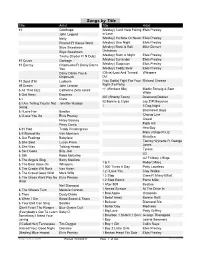
Songs by Title
Songs by Title Title Artist Title Artist #1 Goldfrapp (Medley) Can't Help Falling Elvis Presley John Legend In Love Nelly (Medley) It's Now Or Never Elvis Presley Pharrell Ft Kanye West (Medley) One Night Elvis Presley Skye Sweetnam (Medley) Rock & Roll Mike Denver Skye Sweetnam Christmas Tinchy Stryder Ft N Dubz (Medley) Such A Night Elvis Presley #1 Crush Garbage (Medley) Surrender Elvis Presley #1 Enemy Chipmunks Ft Daisy Dares (Medley) Suspicion Elvis Presley You (Medley) Teddy Bear Elvis Presley Daisy Dares You & (Olivia) Lost And Turned Whispers Chipmunk Out #1 Spot (TH) Ludacris (You Gotta) Fight For Your Richard Cheese #9 Dream John Lennon Right (To Party) & All That Jazz Catherine Zeta Jones +1 (Workout Mix) Martin Solveig & Sam White & Get Away Esquires 007 (Shanty Town) Desmond Dekker & I Ciara 03 Bonnie & Clyde Jay Z Ft Beyonce & I Am Telling You Im Not Jennifer Hudson Going 1 3 Dog Night & I Love Her Beatles Backstreet Boys & I Love You So Elvis Presley Chorus Line Hirley Bassey Creed Perry Como Faith Hill & If I Had Teddy Pendergrass HearSay & It Stoned Me Van Morrison Mary J Blige Ft U2 & Our Feelings Babyface Metallica & She Said Lucas Prata Tammy Wynette Ft George Jones & She Was Talking Heads Tyrese & So It Goes Billy Joel U2 & Still Reba McEntire U2 Ft Mary J Blige & The Angels Sing Barry Manilow 1 & 1 Robert Miles & The Beat Goes On Whispers 1 000 Times A Day Patty Loveless & The Cradle Will Rock Van Halen 1 2 I Love You Clay Walker & The Crowd Goes Wild Mark Wills 1 2 Step Ciara Ft Missy Elliott & The Grass Wont Pay -

Karaoke Songs by Title
Songs by Title Title Artist Title Artist #9 Dream Lennon, John 1985 Bowling For Soup (Day Oh) The Banana Belefonte, Harry 1994 Aldean, Jason Boat Song 1999 Prince (I Would Do) Anything Meat Loaf 19th Nervous Rolling Stones, The For Love Breakdown (Kissed You) Gloriana 2 Become 1 Jewel Goodnight 2 Become 1 Spice Girls (Meet) The Flintstones B52's, The 2 Become 1 Spice Girls, The (Reach Up For The) Duran Duran 2 Faced Louise Sunrise 2 For The Show Trooper (Sitting On The) Dock Redding, Otis 2 Hearts Minogue, Kylie Of The Bay 2 In The Morning New Kids On The (There's Gotta Be) Orrico, Stacie Block More To Life 2 Step Dj Unk (Your Love Has Lifted Shelton, Ricky Van Me) Higher And 20 Good Reasons Thirsty Merc Higher 2001 Space Odyssey Presley, Elvis 03 Bonnie & Clyde Jay-Z & Beyonce 21 Questions 50 Cent & Nate Dogg 03 Bonnie And Clyde Jay-Z & Beyonce 24 Jem (M-F Mix) 24 7 Edmonds, Kevon 1 Thing Amerie 24 Hours At A Time Tucker, Marshall, 1, 2, 3, 4 (I Love You) Plain White T's Band 1,000 Faces Montana, Randy 24's Richgirl & Bun B 10,000 Promises Backstreet Boys 25 Miles Starr, Edwin 100 Years Five For Fighting 25 Or 6 To 4 Chicago 100% Pure Love Crystal Waters 26 Cents Wilkinsons, The 10th Ave Freeze Out Springsteen, Bruce 26 Miles Four Preps, The 123 Estefan, Gloria 3 Spears, Britney 1-2-3 Berry, Len 3 Dressed Up As A 9 Trooper 1-2-3 Estefan, Gloria 3 Libras Perfect Circle, A 1234 Feist 300 Am Matchbox 20 1251 Strokes, The 37 Stitches Drowning Pool 13 Is Uninvited Morissette, Alanis 4 Minutes Avant 15 Minutes Atkins, Rodney 4 Minutes Madonna & Justin 15 Minutes Of Shame Cook, Kristy Lee Timberlake 16 @ War Karina 4 Minutes Madonna & Justin Timberlake & 16th Avenue Dalton, Lacy J. -

Motivation Portrayed in Demi Lovato's Third Album
MOTIVATION PORTRAYED IN DEMI LOVATO’S THIRD ALBUM ‘UNBROKEN’ A THESIS BY: EVY KARLINA P.SARI REG.NO. 110705020 DEPARTMENT OF ENGLISH FACULTY OF CULTURAL STUDIES UNIVERSITY OF SUMATERA UTARA MEDAN 2017 Universitas Sumatera Utara Universitas Sumatera Utara Approved By Department of English, Faculty of Cultural Studies University of Sumatera Utara (USU) Medan As a Thesis For The Sarjana Sastra Examination. Head, Secretary, Dr. Deliana, M.Hum Rahmadsyah Rangkuti,Ma.Ph.D NIP : 19571117 198303 2 002NIP: 19750209 200812 1 002 Universitas Sumatera Utara Accepted by the Board of Examiners in Partialfulfillment of Requirements for the Degree of Sarjana Sastra from the Department of English, Faculty of Cultural Studies University of Sumatera Utara, Medan. The Examination is Held in Department of English Faculty of Cultural Studies University of Sumatera Utara on …….. Dean of Faculty of Cultural Studies University of Sumatera Utara Dr. Budi Agustono, MS NIP. 19600805198703 1 001 Board of Examiners (signature) 1. Dr. H. Muhizar Muchtar, MS ..................................... 2. Rahmadsyah Rangkuti, MA. Ph.D. ..................................... 3. Dr. Siti Norma Nasution, M.Hum. ..................................... 4. Drs. Parlindungan Purba, M.Hum ..................................... Universitas Sumatera Utara AUTHOR’S DECLARATION I, EVY KARLINA PERMATASARI, DECLARE THAT I AM THE SOLE AUTHOR OF THIS THESIS EXCEPT WHERE REFERENCE IS MADE IN THE TEXT OF THIS THESIS. THIS THESIS CONTAINS NO MATERIAL PUBLISHED ELSEWHERE OR EXTRACTED IN WHOLE OR IN PART FROM A THESIS BY WHICH I HAVE QUALIFIED FOR OR AWARDED ANOTHER DEGREE. NO OTHER PERSON’S WORK HAS BEEN USED WITHOUT DUE ACKNOWLEDGMENTS IN THE MAIN TEXT OF THIS THESIS. THIS THESIS HAS NOT BEEN SUBMITTED FOR THE AWARD OF ANOTHER DEGREE IN ANY TERTIARY EDUCATION. -

Stories from the Heart of Australia, the Stories of Its People
O UR GIFT TO Y O U Stories from the PENNING THE P ANDEMIC EDIT ED B Y J OHANNA S K I NNE R & JANE C O NNO L LY Inner Cover picture – Liz Crispie Inner Cover design – Danielle Long Foreword – Johanna Skinner and Jane Connolly Self-Isolation – Margaret Clifford Foreword Late in 2019 news reports of a highly virulent virus were emerging from China. No one could imagine then what would follow. As a general practitioner working at a busy Brisbane surgery, I really did not think that it would affect us that much. How wrong I was. Within months, the World Health Organisation had named the virus COVID 19 and a pandemic was declared. Life as we knew it was changed, perhaps forever. I was fortunate to be part of a practice that had put protocols in place should the worst happen, but even so, I felt overwhelmed by the impact on the patients that I was in contact with daily. They poured their hearts out with stories of resilience, heartache and lives changed irrevocably. I contacted my friend Jane, an experienced editor and writer, about my idea to collect these tales into an anthology. In less than five minutes, she responded enthusiastically and became its senior editor, bringing her years of experience and sharp eye to detail to the anthology. Together, we spent many weekends over pots of tea and Jane’s warm scones reading the overwhelming number of stories and poems that the public entrusted to us. Our greatest regret was that we couldn’t accommodate every piece we received. -

Copy UPDATED KAREOKE 2013
Artist Song Title Disc # ? & THE MYSTERIANS 96 TEARS 6781 10 YEARS THROUGH THE IRIS 13637 WASTELAND 13417 10,000 MANIACS BECAUSE THE NIGHT 9703 CANDY EVERYBODY WANTS 1693 LIKE THE WEATHER 6903 MORE THAN THIS 50 TROUBLE ME 6958 100 PROOF AGED IN SOUL SOMEBODY'S BEEN SLEEPING 5612 10CC I'M NOT IN LOVE 1910 112 DANCE WITH ME 10268 PEACHES & CREAM 9282 RIGHT HERE FOR YOU 12650 112 & LUDACRIS HOT & WET 12569 1910 FRUITGUM CO. 1, 2, 3 RED LIGHT 10237 SIMON SAYS 7083 2 PAC CALIFORNIA LOVE 3847 CHANGES 11513 DEAR MAMA 1729 HOW DO YOU WANT IT 7163 THUGZ MANSION 11277 2 PAC & EMINEM ONE DAY AT A TIME 12686 2 UNLIMITED DO WHAT'S GOOD FOR ME 11184 20 FINGERS SHORT DICK MAN 7505 21 DEMANDS GIVE ME A MINUTE 14122 3 DOORS DOWN AWAY FROM THE SUN 12664 BE LIKE THAT 8899 BEHIND THOSE EYES 13174 DUCK & RUN 7913 HERE WITHOUT YOU 12784 KRYPTONITE 5441 LET ME GO 13044 LIVE FOR TODAY 13364 LOSER 7609 ROAD I'M ON, THE 11419 WHEN I'M GONE 10651 3 DOORS DOWN & BOB SEGER LANDING IN LONDON 13517 3 OF HEARTS ARIZONA RAIN 9135 30 SECONDS TO MARS KILL, THE 13625 311 ALL MIXED UP 6641 AMBER 10513 BEYOND THE GREY SKY 12594 FIRST STRAW 12855 I'LL BE HERE AWHILE 9456 YOU WOULDN'T BELIEVE 8907 38 SPECIAL HOLD ON LOOSELY 2815 SECOND CHANCE 8559 3LW I DO 10524 NO MORE (BABY I'MA DO RIGHT) 178 PLAYAS GON' PLAY 8862 3RD STRIKE NO LIGHT 10310 REDEMPTION 10573 3T ANYTHING 6643 4 NON BLONDES WHAT'S UP 1412 4 P.M. -

Jerry Garcia Song Book – Ver
JERRY GARCIA SONG BOOK – VER. 9 1. After Midnight 46. Chimes of Freedom 92. Freight Train 137. It Must Have Been The 2. Aiko-Aiko 47. blank page 93. Friend of the Devil Roses 3. Alabama Getaway 48. China Cat Sunflower 94. Georgia on My Mind 138. It Takes a lot to Laugh, It 4. All Along the 49. I Know You Rider 95. Get Back Takes a Train to Cry Watchtower 50. China Doll 96. Get Out of My Life 139. It's a Long, Long Way to 5. Alligator 51. Cold Rain and Snow 97. Gimme Some Lovin' the Top of the World 6. Althea 52. Comes A Time 98. Gloria 140. It's All Over Now 7. Amazing Grace 53. Corina 99. Goin' Down the Road 141. It's All Over Now Baby 8. And It Stoned Me 54. Cosmic Charlie Feelin' Bad Blue 9. Arkansas Traveler 55. Crazy Fingers 100. Golden Road 142. It's No Use 10. Around and Around 56. Crazy Love 101. Gomorrah 143. It's Too Late 11. Attics of My Life 57. Cumberland Blues 102. Gone Home 144. I've Been All Around This 12. Baba O’Riley --> 58. Dancing in the Streets 103. Good Lovin' World Tomorrow Never Knows 59. Dark Hollow 104. Good Morning Little 145. Jack-A-Roe 13. Ballad of a Thin Man 60. Dark Star Schoolgirl 146. Jack Straw 14. Beat it on Down The Line 61. Dawg’s Waltz 105. Good Time Blues 147. Jenny Jenkins 15. Believe It Or Not 62. Day Job 106. -

Give Your Heart a Break – Demi Lovato
iSing.pl - Każdy może śpiewać! Give Your Heart a Break – Demi Lovato The day I first met you You told me you'd never fall in love But now that I get you I know fear is what it really was Now here we are, so close Yet so far, haven't I passed the test? When will you realize Baby, I'm not like the rest Don't wanna break your heart I wanna give your heart a break I know you're scared it's wrong Like you might make a mistake There's just one life to live And there's no time to wait, to waste So let me give your heart a break Give your heart a break Let me give your heart a break Your heart a break Oh, yeah yeah On Sunday, you went home alone There were tears in your eyes I called your cell phone, my love But you did not reply The world is ours, if you want it We can take it, if you just take my hand There's no turning back now Baby, try to understand Don't wanna break your heart Wanna give your heart a break I know you're scared it's wrong Like you might make a mistake There's just one life to live And there's no time to wait, to waste So let me give your heart a break Give your heart a break Let me give your heart a break Your heart a break There's just so much you can take Give your heart a break Let me give your heart a break Your heart a break Oh, yeah yeah When your lips are on my lips And our hearts beat as one But you slip right out of my fingertips Every time you ruuuuuun, whoa Don't wanna break your heart Wanna give your heart a break I know you're scared it's wrong Like you might make a mistake There's just one life to live And -

Nostalgias in Modern Tunisia Dissertation
Images of the Past: Nostalgias in Modern Tunisia Dissertation Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By David M. Bond, M.A. Graduate Program in Near Eastern Languages and Cultures The Ohio State University 2017 Dissertation Committee: Sabra J. Webber, Advisor Johanna Sellman Philip Armstrong Copyrighted by David Bond 2017 Abstract The construction of stories about identity, origins, history and community is central in the process of national identity formation: to mould a national identity – a sense of unity with others belonging to the same nation – it is necessary to have an understanding of oneself as located in a temporally extended narrative which can be remembered and recalled. Amid the “memory boom” of recent decades, “memory” is used to cover a variety of social practices, sometimes at the expense of the nuance and texture of history and politics. The result can be an elision of the ways in which memories are constructed through acts of manipulation and the play of power. This dissertation examines practices and practitioners of nostalgia in a particular context, that of Tunisia and the Mediterranean region during the twentieth and early twenty-first centuries. Using a variety of historical and ethnographical sources I show how multifaceted nostalgia was a feature of the colonial situation in Tunisia notably in the period after the First World War. In the postcolonial period I explore continuities with the colonial period and the uses of nostalgia as a means of contestation when other possibilities are limited.