Instruction Set Architecture (ISA) 1 the SPIM Simu
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

6.004 Computation Structures Spring 2009
MIT OpenCourseWare http://ocw.mit.edu 6.004 Computation Structures Spring 2009 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms. M A S S A C H U S E T T S I N S T I T U T E O F T E C H N O L O G Y DEPARTMENT OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE 6.004 Computation Structures β Documentation 1. Introduction This handout is a reference guide for the β, the RISC processor design for 6.004. This is intended to be a complete and thorough specification of the programmer-visible state and instruction set. 2. Machine Model The β is a general-purpose 32-bit architecture: all registers are 32 bits wide and when loaded with an address can point to any location in the byte-addressed memory. When read, register 31 is always 0; when written, the new value is discarded. Program Counter Main Memory PC always a multiple of 4 0x00000000: 3 2 1 0 0x00000004: 32 bits … Registers SUB(R3,R4,R5) 232 bytes R0 ST(R5,1000) R1 … … R30 0xFFFFFFF8: R31 always 0 0xFFFFFFFC: 32 bits 32 bits 3. Instruction Encoding Each β instruction is 32 bits long. All integer manipulation is between registers, with up to two source operands (one may be a sign-extended 16-bit literal), and one destination register. Memory is referenced through load and store instructions that perform no other computation. Conditional branch instructions are separated from comparison instructions: branch instructions test the value of a register that can be the result of a previous compare instruction. -

ARM Instruction Set
4 ARM Instruction Set This chapter describes the ARM instruction set. 4.1 Instruction Set Summary 4-2 4.2 The Condition Field 4-5 4.3 Branch and Exchange (BX) 4-6 4.4 Branch and Branch with Link (B, BL) 4-8 4.5 Data Processing 4-10 4.6 PSR Transfer (MRS, MSR) 4-17 4.7 Multiply and Multiply-Accumulate (MUL, MLA) 4-22 4.8 Multiply Long and Multiply-Accumulate Long (MULL,MLAL) 4-24 4.9 Single Data Transfer (LDR, STR) 4-26 4.10 Halfword and Signed Data Transfer 4-32 4.11 Block Data Transfer (LDM, STM) 4-37 4.12 Single Data Swap (SWP) 4-43 4.13 Software Interrupt (SWI) 4-45 4.14 Coprocessor Data Operations (CDP) 4-47 4.15 Coprocessor Data Transfers (LDC, STC) 4-49 4.16 Coprocessor Register Transfers (MRC, MCR) 4-53 4.17 Undefined Instruction 4-55 4.18 Instruction Set Examples 4-56 ARM7TDMI-S Data Sheet 4-1 ARM DDI 0084D Final - Open Access ARM Instruction Set 4.1 Instruction Set Summary 4.1.1 Format summary The ARM instruction set formats are shown below. 3 3 2 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 9876543210 1 0 9 8 7 6 5 4 3 2 1 0 9 8 7 6 5 4 3 2 1 0 Cond 0 0 I Opcode S Rn Rd Operand 2 Data Processing / PSR Transfer Cond 0 0 0 0 0 0 A S Rd Rn Rs 1 0 0 1 Rm Multiply Cond 0 0 0 0 1 U A S RdHi RdLo Rn 1 0 0 1 Rm Multiply Long Cond 0 0 0 1 0 B 0 0 Rn Rd 0 0 0 0 1 0 0 1 Rm Single Data Swap Cond 0 0 0 1 0 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1 Rn Branch and Exchange Cond 0 0 0 P U 0 W L Rn Rd 0 0 0 0 1 S H 1 Rm Halfword Data Transfer: register offset Cond 0 0 0 P U 1 W L Rn Rd Offset 1 S H 1 Offset Halfword Data Transfer: immediate offset Cond 0 -

Assembly Language
Assembly Language University of Texas at Austin CS310H - Computer Organization Spring 2010 Don Fussell Human-Readable Machine Language Computers like ones and zeros… 0001110010000110 Humans like symbols… ADD R6,R2,R6 ; increment index reg. Assembler is a program that turns symbols into machine instructions. ISA-specific: close correspondence between symbols and instruction set mnemonics for opcodes labels for memory locations additional operations for allocating storage and initializing data University of Texas at Austin CS310H - Computer Organization Spring 2010 Don Fussell 2 An Assembly Language Program ; ; Program to multiply a number by the constant 6 ; .ORIG x3050 LD R1, SIX LD R2, NUMBER AND R3, R3, #0 ; Clear R3. It will ; contain the product. ; The inner loop ; AGAIN ADD R3, R3, R2 ADD R1, R1, #-1 ; R1 keeps track of BRp AGAIN ; the iteration. ; HALT ; NUMBER .BLKW 1 SIX .FILL x0006 ; .END University of Texas at Austin CS310H - Computer Organization Spring 2010 Don Fussell 3 LC-3 Assembly Language Syntax Each line of a program is one of the following: an instruction an assember directive (or pseudo-op) a comment Whitespace (between symbols) and case are ignored. Comments (beginning with “;”) are also ignored. An instruction has the following format: LABEL OPCODE OPERANDS ; COMMENTS optional mandatory University of Texas at Austin CS310H - Computer Organization Spring 2010 Don Fussell 4 Opcodes and Operands Opcodes reserved symbols that correspond to LC-3 instructions listed in Appendix A ex: ADD, AND, LD, LDR, … Operands registers -

Basic Processor Implementation Jinyang Li What We’Ve Learnt So Far
Basic Processor Implementation Jinyang Li What we’ve learnt so far • Combinatorial logic • Truth table • ROM • ALU • Sequential logic • Clocks • Basic state elements (SR latch, D latch, flip-flop) Clocked Clocked unclocked (Level (edge triggered) triggered) Today’s lesson plan • Implement a basic CPU Our CPU will be based on RISC-V instead of x86 • 3 popular ISAs now ISA Key advantage Who builds the Where are the processors processors? used? x86 Fast Intel, AMD Server (Cloud), Desktop, CISC Laptop, Xbox console Complex Instruction Set ARM Low power (everybody can license the Samsung, NVIDIA, Phones, Tablets, Nintendo design from ARM Holdings for $$$) Qualcomm, Broadcom, console, Raspberry Pi RISC Huawei/HiSilicon Reduced RISC-V Open source, royalty-free Western digital, Alibaba Devices (e.g. SSD controllers) Instruction Set RISC-V at a high level RISC-V X86-64 # of registers 32 16 similarities Memory Byte-addressable, Byte-addressable, Little Endian Little Endian Why RISC-V is much simpler? Fewer instructions 50+ (200 manual pages) 1000+ (2306 manual pages) Simpler instruction encoding 4-byte Variable length Simpler instructions • Ld/st instructions • Instructions take either load/store memory to memory or register operands or from register • Complex memory addressing • Other instructions take modes D(B, I, S) only register operands • Prefixes modify instruction behavior Basic RISC-V instructions Registers: x0, x1, x2,…, x31 64-bit Data transfer load doubleword ld x5, 40(x6) x5=Memory[x6+40] store doubleword sd x5, 40(x6) Memory[x6+40]=x5 -

X86 Assembly Language Reference Manual
x86 Assembly Language Reference Manual Part No: 817–5477–11 March 2010 Copyright ©2010 Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related software documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are “commercial computer software” or “commercial technical data” pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, duplication, disclosure, modification, and adaptation shall be subject to the restrictions and license terms setforth in the applicable Government contract, and, to the extent applicable by the terms of the Government contract, the additional rights set forth in FAR 52.227-19, Commercial Computer Software License (December 2007). Oracle USA, Inc., 500 Oracle Parkway, Redwood City, CA 94065. -

Assembly Language
Assembly Language Readings: 2.1-2.7, 2.9-2.10, 2.14 Green reference card Assembly language Simple, regular instructions – building blocks of C, Java & other languages Typically one-to-one mapping to machine language Our goal Understand the basics of assembly language Help figure out what the processor needs to be able to do Not our goal to teach complete assembly/machine language programming Floating point Procedure calls Stacks & local variables 9 Aside: C/C++ Primer struct coord { int x, y; }; /* Declares a type */ struct coord start; /* Object with two slots, x and y */ start.x = 1; /* For objects “.” accesses a slot */ struct coord *myLoc; /* “*” is a pointer to objects */ myLoc = &start; /* “&” returns thing’s location */ myLoc->y = 2; /* “->” is “*” plus “.” */ x y int scores[8]; /* 8 ints, from 0..7 */ scores[1]=5; /* Access locations in array */ int *index = scores; /* Points to scores[0] */ index++; /* Next scores location */ (*index)++; /* “*” works in arays as well */ index = &(scores[3]); /* Points to scores[3] */ *index = 9; 10 0 1 2 3 4 5 6 7 ARM Assembly Language The basic instructions have four components: Operator name Destination 1st operand 2nd operand ADD <dst>, <src1>, <src2> // <dst> = <src1> + <src2> SUB <dst>, <src1>, <src2> // <dst> = <src1> - <src2> Simple format: easy to implement in hardware More complex: A = B + C + D – E 11 Operands & Storage For speed, CPU has 32 general-purpose registers for storing most operands For capacity, computer has large memory (multi-GB) Computer Processor Memory Devices Control -
Opcode Tables
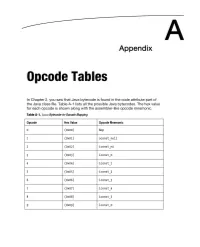
A Appendix Opcode Tables In Chapter 2, you saw that Java bytecode is found in the code attribute part of the Java class file. Table A-1 lists all the possible Java bytecodes. The hex value for each opcode is shown along with the assembler-like opcode mnemonic. Table A-1. Java Bytecode-to-Opcode Mapping Opcode Hex Value Opcode Mnemonic 0 (OXOo) Nop 1 (OX01) aconst null 2 (OX02) iconst ml 3 (OX03) iconst 0 4 (OX04) iconst 1 5 (OXOS) iconst 2 6 (Ox06) iconst_3 7 (OX07) iconst_4 8 (ox08) iconst_5 9 (OX09) lconst 0 256 APPENDIX A: Opcode Tables Opcode Hex Value Opcode Mnemonic 10 (oxoa) Ieonst 1 11 (oxOb) feonst 0 12 (oxoe) feonst 1 13 (oxOd) feonst 2 14 (oxoe) deonst 0 15 (oxof) deonst 1 16 (OX10) bipush 17 (OXll) sipush 18 (OX12) Ide 19 (OX13) Ide w 20 (OX14) Ide2 w 21 (OX1S) iload 22 (OX16) Hoad 23 (OX17) Hoad 24 (OX18) dload 25 (OX19) aload 26 (oxla) iload 0 27 (oxlb) iload 1 28 (oxle) iload 2 29 (oxld) iload_3 30 (oxle) Hoad 0 APPENDIX A: Opcode Tables 257 31 (Ox1f) Hoad 1 32 (OX20) Hoad 2 33 (OX21) Hoad_3 34 (OX22) Hoad 0 35 (OX23) Hoad 1 36 (OX24) Hoad 2 37 (OX25) Hoad_3 38 (OX26) dload 0 39 (OX27) dload 1 40 (OX28) dload 2 41 (OX29) dload_3 42 (Ox2a) aload 0 43 (Ox2b) aload 1 44 (OX2C) aload 2 45 (OX2d) aload_3 46 (Ox2e) iaload 47 (ox2f) laload 48 (OX30) faload 49 (OX31) daload 50 (OX32) aaload 51 (OX33) baload 52 (OX34) caload 258 APPENDIX A: Opcode Tables Opcode Hex Value Opcode Mnemonic 53 (OX35) saload 54 (OX36) istore 55 (OX37) lstore 56 (OX38) fstore 57 (OX39) dstore 58 (ox3a) astore 59 (OX3b) istore 0 60 (OX3C) istore 1 61 (OX3d) -

Computer Organization & Assembly Language Programming
Computer Organization & Assembly Language Programming CSE 2312 Lecture 6 ISA & Data Types & Instruction Formats 1 Multilevel Machines 2 ISA • Instruction Architecture Level – Lay between the microarchitecture level and operating system level • Significance – ISA is the interface between the software and the hardware. – It is not good to have the hardware directly execute programs written in C, C++, Java, or some other high-level language: 1) the performance advantage of compiling over interpreting would then be lost. 2) most computers have to be able to execute programs written in multiple languages, not just one. • One Design Principle – Let programs in various high-level languages to be translated to a common intermediate form—the ISA level – Build hardware to be able to execute ISA-level programs directly. • Theory vs. Reality – Theory: satisfy both complier writer and hardware engineer – Practice: backward compatible 3 ISA Level • Relationship – The ISA level define the interface between the compilers and the hardware. – It is the language that both of them have to understand. – The relationship among the compilers, the ISA level, and the hardware 4 What make a good ISA? • Implementation – a good ISA should define a set of instructions that can be implemented efficiently in current and future technologies, resulting in cost-effective designs over several generations. – A poor design is more difficult to implement and may require many more gates to implement a processor and more memory for executing programs. It also may run slower because the ISA obscures opportunities to overlap operations, requiring much more sophisticated designs to achieve equivalent performance. • Target for Compiler Code – A good ISA should provide a clean target for compiled code. -

High-Level Vs Assembly Language Programming
High-level vs. Assembly language Consider the following statements 1. a = x + y – z 2. if x > y then x:= x + y else x:= x - y How does a processor execute these? HLL (High Level Language) programs are machine independent. They are easy to learn, easy to use, and convenient for managing complex tasks. Assembly language programs are machine specific. It is the language that the processor directly understands. 1 Understanding Assembly Language Let us begin with data representation. How to represent • Signed integers • Fractions • Alphanumeric characters Review • Floating point numbers • Pictures? Memory 0 1 0 0 1 0 1 1 1 1 0 1 1 0 1 0 1 00 1 1 0 0 0 Can you read 0o00 the contents of these memory cells? 2 Visualizing instruction execution (The main concept is register-transfer operation. registers Memory 0 500 x r0 1 24 y r1 ALU -32 2 z r2 0 3 a r3 Address data processor A register is a fast storage within the CPU load x into r1 load y into r2 a = x + y - z load z into r0 r3 ¨ r1 + r2 r0 ¨ r3 – r0 store r0 into a 3 Assembly language instructions for a hypothetical machine (not MIPS) Load x, r1 Load y, r2 Load z, r0 Add r3, r1, r2 Sub r0, r3, r0 Store r0, a Each processor has a different set of registers, and different assembly language instructions. The assembly language instructions of Intel Pentium and MIPS are completely different. Motorola 68000 has 16 registers r0-r15 MIPS has 32 registers r0-r31 Pentium has 8 general purpose & 6 segment registers. -

Introduction to Intel X86-64 Assembly, Architecture, Applications, & Alliteration
Introduction to Intel x86-64 Assembly, Architecture, Applications, & Alliteration Xeno Kovah – 2014 xkovah at gmail All materials is licensed under a Creative Commons “Share Alike” license. • http://creativecommons.org/licenses/by-sa/3.0/ Attribution condition: You must indicate that derivative work "Is derived from Xeno Kovah's 'Intro x86-64’ class, available at http://OpenSecurityTraining.info/IntroX86-64.html” Attribution condition: You must indicate that derivative work "Is derived from Xeno Kovah's ‘Intro x86-64’ class, available at http://OpenSecurityTraining.info/IntroX86-64.html" Guess what? I have repeatedly misled you! • Simplification is misleading • Time to learn the fascinating truth… • Time to RTFM! Read The Fun Manuals • http://www.intel.com/products/processor/manuals/ • Vol.1 is a summary of life, the universe, and everything about x86 • Vol. 2a & 2b explains all the instructions • Vol. 3a & 3b are all the gory details for all the extra stuff they’ve added in over the years (MultiMedia eXtentions - MMX, Virtual Machine eXtentions - VMX, virtual memory, 16/64 bit modes, system management mode, etc) • Reminder, we’re using the pre-downloaded May 2012 version as the standardized reference throughout this class so we’re all looking at the same information • We’ll only be looking at Vol. 2a & 2b in this class Googling is fine to start with, but eventually you need to learn to read the manuals to get the details from the authoritative source Interpreting the Instruction Reference Pages • The correct way to interpret these pages -

Ubicom™ SX Cross Assembler User's Manual
www.ubicom.com Ubicom™ SX Cross Assembler User’s Manual Lit. No.: UM02-04 SASM Cross Assembler User’s Manual Rev. 1.3 © 2000 Ubicom, Inc. All rights reserved. Revision History www.ubicom.com Revision History REVISION RELEASE DATE SUMMARY OF CHANGES 1.0 July 14, 1999 Initial Release 1.1 May 15, 2000 Updated to reflect latest SX devices 1.2 August 30, 2000 Updated to support SASM vl. 45.5 and higher revisions 1.3 December, 2000 Updated to describe the improved macro lan- guage provided by SASM v1.46, including minor revisions 1.47 and 1.48. ©2000 Ubicom, Inc. All rights reserved. No warranty is provided and no liability is assumed by Ubicom with respect to the accuracy of this documentation or the merchantability or fitness of the product for a particular application. No license of any kind is conveyed by Ubicom with respect to its intellectual property or that of others. All information in this document is subject to change without notice. Ubicom products are not authorized for use in life support systems or under conditions where failure of the product would endanger the life or safety of the user, except when prior written approval is obtained from Ubicom. Ubicom™ and the Ubicom logo are trademarks of Ubicom, Inc. All other trademarks mentioned in this document are property of their respective companies. Ubicom, Inc., 1330 Charleston Road, Mountain View, CA 94043 USA Telephone: +1 650 210 1500, Web site: hhtp://www.ubicom.com SX Cross Assambler 1.3 2 ©2000 Ubicom, Inc. All rights reserved. -

V850e/Ms1 , V850e/Ms2
User’s Manual V850E/MS1TM, V850E/MS2TM 32-Bit Single-Chip Microcontrollers Architecture V850E/MS1: V850E/MS2: µPD703100 µPD703130 µPD703100A µPD703101 µPD703101A µPD703102 µPD703102A µPD70F3102 µPD70F3102A Document No. U12197EJ6V0UM00 (6th edition) Date Published November 2002 N CP(K) 1996 Printed in Japan [MEMO] 2 User’s Manual U12197EJ6V0UM NOTES FOR CMOS DEVICES 1 PRECAUTION AGAINST ESD FOR SEMICONDUCTORS Note: Strong electric field, when exposed to a MOS device, can cause destruction of the gate oxide and ultimately degrade the device operation. Steps must be taken to stop generation of static electricity as much as possible, and quickly dissipate it once, when it has occurred. Environmental control must be adequate. When it is dry, humidifier should be used. It is recommended to avoid using insulators that easily build static electricity. Semiconductor devices must be stored and transported in an anti-static container, static shielding bag or conductive material. All test and measurement tools including work bench and floor should be grounded. The operator should be grounded using wrist strap. Semiconductor devices must not be touched with bare hands. Similar precautions need to be taken for PW boards with semiconductor devices on it. 2 HANDLING OF UNUSED INPUT PINS FOR CMOS Note: No connection for CMOS device inputs can be cause of malfunction. If no connection is provided to the input pins, it is possible that an internal input level may be generated due to noise, etc., hence causing malfunction. CMOS devices behave differently than Bipolar or NMOS devices. Input levels of CMOS devices must be fixed high or low by using a pull-up or pull-down circuitry.