Supplementary Table 1. HUGO Gene Nomenclature Committee (HGNC) Gene Symbols of Genes Included in the Targeted Next-Generation Sequencing Assay
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model
Downloaded from http://www.jimmunol.org/ by guest on September 25, 2021 T + is online at: average * The Journal of Immunology , 34 of which you can access for free at: 2016; 197:1477-1488; Prepublished online 1 July from submission to initial decision 4 weeks from acceptance to publication 2016; doi: 10.4049/jimmunol.1600589 http://www.jimmunol.org/content/197/4/1477 Molecular Profile of Tumor-Specific CD8 Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. Waugh, Sonia M. Leach, Brandon L. Moore, Tullia C. Bruno, Jonathan D. Buhrman and Jill E. Slansky J Immunol cites 95 articles Submit online. Every submission reviewed by practicing scientists ? is published twice each month by Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://jimmunol.org/subscription Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html http://www.jimmunol.org/content/suppl/2016/07/01/jimmunol.160058 9.DCSupplemental This article http://www.jimmunol.org/content/197/4/1477.full#ref-list-1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material References Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2016 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of September 25, 2021. The Journal of Immunology Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. -

Downregulation of Salivary Proteins, Protective Against Dental Caries, in Type 1 Diabetes
proteomes Article Downregulation of Salivary Proteins, Protective against Dental Caries, in Type 1 Diabetes Eftychia Pappa 1,* , Konstantinos Vougas 2, Jerome Zoidakis 2 , William Papaioannou 3, Christos Rahiotis 1 and Heleni Vastardis 4 1 Department of Operative Dentistry, School of Dentistry, National and Kapodistrian University of Athens, 11527 Athens, Greece; [email protected] 2 Proteomics Laboratory, Biomedical Research Foundation Academy of Athens, 11527 Athens, Greece; [email protected] (K.V.); [email protected] (J.Z.) 3 Department of Preventive and Community Dentistry, School of Dentistry, National and Kapodistrian University of Athens, 11527 Athens, Greece; [email protected] 4 Department of Orthodontics, School of Dentistry, National and Kapodistrian University of Athens, 11527 Athens, Greece; [email protected] * Correspondence: effi[email protected] Abstract: Saliva, an essential oral secretion involved in protecting the oral cavity’s hard and soft tissues, is readily available and straightforward to collect. Recent studies have analyzed the sali- vary proteome in children and adolescents with extensive carious lesions to identify diagnostic and prognostic biomarkers. The current study aimed to investigate saliva’s diagnostic ability through proteomics to detect the potential differential expression of proteins specific for the occurrence of carious lesions. For this study, we performed bioinformatics and functional analysis of proteomic datasets, previously examined by our group, from samples of adolescents with regulated and unreg- ulated type 1 diabetes, as they compare with healthy controls. Among the differentially expressed Citation: Pappa, E.; Vougas, K.; proteins relevant to caries pathology, alpha-amylase 2B, beta-defensin 4A, BPI fold containing family Zoidakis, J.; Papaioannou, W.; Rahiotis, C.; Vastardis, H. -

Genome Analysis and Knowledge
Dahary et al. BMC Medical Genomics (2019) 12:200 https://doi.org/10.1186/s12920-019-0647-8 SOFTWARE Open Access Genome analysis and knowledge-driven variant interpretation with TGex Dvir Dahary1*, Yaron Golan1, Yaron Mazor1, Ofer Zelig1, Ruth Barshir2, Michal Twik2, Tsippi Iny Stein2, Guy Rosner3,4, Revital Kariv3,4, Fei Chen5, Qiang Zhang5, Yiping Shen5,6,7, Marilyn Safran2, Doron Lancet2* and Simon Fishilevich2* Abstract Background: The clinical genetics revolution ushers in great opportunities, accompanied by significant challenges. The fundamental mission in clinical genetics is to analyze genomes, and to identify the most relevant genetic variations underlying a patient’s phenotypes and symptoms. The adoption of Whole Genome Sequencing requires novel capacities for interpretation of non-coding variants. Results: We present TGex, the Translational Genomics expert, a novel genome variation analysis and interpretation platform, with remarkable exome analysis capacities and a pioneering approach of non-coding variants interpretation. TGex’s main strength is combining state-of-the-art variant filtering with knowledge-driven analysis made possible by VarElect, our highly effective gene-phenotype interpretation tool. VarElect leverages the widely used GeneCards knowledgebase, which integrates information from > 150 automatically-mined data sources. Access to such a comprehensive data compendium also facilitates TGex’s broad variant annotation, supporting evidence exploration, and decision making. TGex has an interactive, user-friendly, and easy adaptive interface, ACMG compliance, and an automated reporting system. Beyond comprehensive whole exome sequence capabilities, TGex encompasses innovative non-coding variants interpretation, towards the goal of maximal exploitation of whole genome sequence analyses in the clinical genetics practice. This is enabled by GeneCards’ recently developed GeneHancer, a novel integrative and fully annotated database of human enhancers and promoters. -

Identification of BBX Proteins As Rate-Limiting Co-Factors of HY5
1 Identification of BBX proteins as rate-limiting co-factors of HY5. 2 Katharina Bursch1, Gabriela Toledo-Ortiz2, Marie Pireyre3, Miriam Lohr1, Cordula Braatz1, Henrik 3 Johansson1* 4 1. Institute of Biology/Applied Genetics, Dahlem Centre of Plant Sciences (DCPS), Freie Universität 5 Berlin, Albrecht-Thaer-Weg 6. D-14195 Berlin, Germany. 6 2. Lancaster Environment Centre, Lancaster University, Lancaster LA1 4YQ, UK 7 3. Department of Botany and Plant Biology, Section of Biology, Faculty of Sciences, University of 8 Geneva, 30 Quai E. Ansermet, 1211 Geneva 4, Switzerland 9 *E-mail [email protected] 10 Abstract 11 As a source of both energy and environmental information, monitoring the incoming light is crucial for 12 plants to optimize growth throughout development1. Concordantly, the light signalling pathways in 13 plants are highly integrated with numerous other regulatory pathways2,3. One of these signal 14 integrators is the bZIP transcription factor HY5 which holds a key role as a positive regulator of light 15 signalling in plants4,5. Although HY5 is thought to act as a DNA-binding transcriptional regulator6,7, the 16 lack of any apparent transactivation domain8 makes it unclear how HY5 is able to accomplish its many 17 functions. Here, we describe the identification of three B-box containing proteins (BBX20, 21 and 22) 18 as essential partners for HY5 dependent modulation of hypocotyl elongation, anthocyanin 19 accumulation and transcriptional regulation. The bbx202122 triple mutant mimics the phenotypes of 20 hy5 in the light and its ability to suppress the cop1 mutant phenotype in darkness. Furthermore, 84% 21 of genes that exhibit differential expression in bbx202122 are also HY5 regulated, and we provide 22 evidence that HY5 requires the B-box proteins for transcriptional regulation. -

Primary Driver Mutations in GTF2I Specific to the Development Of
cancers Article Primary Driver Mutations in GTF2I Specific to the Development of Thymomas Rumi Higuchi 1, Taichiro Goto 1,* , Yosuke Hirotsu 2 , Yujiro Yokoyama 1, Takahiro Nakagomi 1, Sotaro Otake 1, Kenji Amemiya 2,3, Toshio Oyama 3, Hitoshi Mochizuki 2 and Masao Omata 2,4 1 Lung Cancer and Respiratory Disease Center, Yamanashi Central Hospital, Yamanashi 400-8506, Japan; [email protected] (R.H.); [email protected] (Y.Y.); [email protected] (T.N.); [email protected] (S.O.) 2 Genome Analysis Center, Yamanashi Central Hospital, Yamanashi 400-8506, Japan; [email protected] (Y.H.); [email protected] (K.A.); [email protected] (H.M.); [email protected] (M.O.) 3 Department of Pathology, Yamanashi Central Hospital, Yamanashi 400-8506, Japan; [email protected] 4 Department of Gastroenterology, The University of Tokyo Hospital, Tokyo 113-8655, Japan * Correspondence: [email protected]; Tel.: +81-55-253-7111 Received: 16 June 2020; Accepted: 22 July 2020; Published: 24 July 2020 Abstract: Thymomas are rare mediastinal tumors that are difficult to treat and pose a major public health concern. Identifying mutations in target genes is vital for the development of novel therapeutic strategies. Type A thymomas possess a missense mutation in GTF2I (chromosome 7 c.74146970T>A) with high frequency. However, the molecular pathways underlying the tumorigenesis of other thymomas remain to be elucidated. We aimed to detect this missense mutation in GTF2I in other thymoma subtypes (types B). This study involved 22 patients who underwent surgery for thymomas between January 2014 and August 2019. -
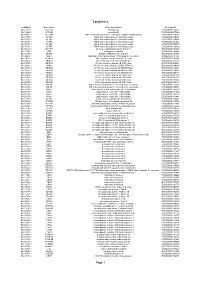
Epigenetics Page 1
Epigenetics esiRNA ID Gene Name Gene Description Ensembl ID HU-13237-1 ACTL6A actin-like 6A ENSG00000136518 HU-13925-1 ACTL6B actin-like 6B ENSG00000077080 HU-14457-1 ACTR1A ARP1 actin-related protein 1 homolog A, centractin alpha (yeast) ENSG00000138107 HU-10579-1 ACTR2 ARP2 actin-related protein 2 homolog (yeast) ENSG00000138071 HU-10837-1 ACTR3 ARP3 actin-related protein 3 homolog (yeast) ENSG00000115091 HU-09776-1 ACTR5 ARP5 actin-related protein 5 homolog (yeast) ENSG00000101442 HU-00773-1 ACTR6 ARP6 actin-related protein 6 homolog (yeast) ENSG00000075089 HU-07176-1 ACTR8 ARP8 actin-related protein 8 homolog (yeast) ENSG00000113812 HU-09411-1 AHCTF1 AT hook containing transcription factor 1 ENSG00000153207 HU-15150-1 AIRE autoimmune regulator ENSG00000160224 HU-12332-1 AKAP1 A kinase (PRKA) anchor protein 1 ENSG00000121057 HU-04065-1 ALG13 asparagine-linked glycosylation 13 homolog (S. cerevisiae) ENSG00000101901 HU-13552-1 ALKBH1 alkB, alkylation repair homolog 1 (E. coli) ENSG00000100601 HU-06662-1 ARID1A AT rich interactive domain 1A (SWI-like) ENSG00000117713 HU-12790-1 ARID1B AT rich interactive domain 1B (SWI1-like) ENSG00000049618 HU-09415-1 ARID2 AT rich interactive domain 2 (ARID, RFX-like) ENSG00000189079 HU-03890-1 ARID3A AT rich interactive domain 3A (BRIGHT-like) ENSG00000116017 HU-14677-1 ARID3B AT rich interactive domain 3B (BRIGHT-like) ENSG00000179361 HU-14203-1 ARID3C AT rich interactive domain 3C (BRIGHT-like) ENSG00000205143 HU-09104-1 ARID4A AT rich interactive domain 4A (RBP1-like) ENSG00000032219 HU-12512-1 ARID4B AT rich interactive domain 4B (RBP1-like) ENSG00000054267 HU-12520-1 ARID5A AT rich interactive domain 5A (MRF1-like) ENSG00000196843 HU-06595-1 ARID5B AT rich interactive domain 5B (MRF1-like) ENSG00000150347 HU-00556-1 ASF1A ASF1 anti-silencing function 1 homolog A (S. -

Supplementary Table 1: Adhesion Genes Data Set
Supplementary Table 1: Adhesion genes data set PROBE Entrez Gene ID Celera Gene ID Gene_Symbol Gene_Name 160832 1 hCG201364.3 A1BG alpha-1-B glycoprotein 223658 1 hCG201364.3 A1BG alpha-1-B glycoprotein 212988 102 hCG40040.3 ADAM10 ADAM metallopeptidase domain 10 133411 4185 hCG28232.2 ADAM11 ADAM metallopeptidase domain 11 110695 8038 hCG40937.4 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 195222 8038 hCG40937.4 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 165344 8751 hCG20021.3 ADAM15 ADAM metallopeptidase domain 15 (metargidin) 189065 6868 null ADAM17 ADAM metallopeptidase domain 17 (tumor necrosis factor, alpha, converting enzyme) 108119 8728 hCG15398.4 ADAM19 ADAM metallopeptidase domain 19 (meltrin beta) 117763 8748 hCG20675.3 ADAM20 ADAM metallopeptidase domain 20 126448 8747 hCG1785634.2 ADAM21 ADAM metallopeptidase domain 21 208981 8747 hCG1785634.2|hCG2042897 ADAM21 ADAM metallopeptidase domain 21 180903 53616 hCG17212.4 ADAM22 ADAM metallopeptidase domain 22 177272 8745 hCG1811623.1 ADAM23 ADAM metallopeptidase domain 23 102384 10863 hCG1818505.1 ADAM28 ADAM metallopeptidase domain 28 119968 11086 hCG1786734.2 ADAM29 ADAM metallopeptidase domain 29 205542 11085 hCG1997196.1 ADAM30 ADAM metallopeptidase domain 30 148417 80332 hCG39255.4 ADAM33 ADAM metallopeptidase domain 33 140492 8756 hCG1789002.2 ADAM7 ADAM metallopeptidase domain 7 122603 101 hCG1816947.1 ADAM8 ADAM metallopeptidase domain 8 183965 8754 hCG1996391 ADAM9 ADAM metallopeptidase domain 9 (meltrin gamma) 129974 27299 hCG15447.3 ADAMDEC1 ADAM-like, -

Cellular and Molecular Signatures in the Disease Tissue of Early
Cellular and Molecular Signatures in the Disease Tissue of Early Rheumatoid Arthritis Stratify Clinical Response to csDMARD-Therapy and Predict Radiographic Progression Frances Humby1,* Myles Lewis1,* Nandhini Ramamoorthi2, Jason Hackney3, Michael Barnes1, Michele Bombardieri1, Francesca Setiadi2, Stephen Kelly1, Fabiola Bene1, Maria di Cicco1, Sudeh Riahi1, Vidalba Rocher-Ros1, Nora Ng1, Ilias Lazorou1, Rebecca E. Hands1, Desiree van der Heijde4, Robert Landewé5, Annette van der Helm-van Mil4, Alberto Cauli6, Iain B. McInnes7, Christopher D. Buckley8, Ernest Choy9, Peter Taylor10, Michael J. Townsend2 & Costantino Pitzalis1 1Centre for Experimental Medicine and Rheumatology, William Harvey Research Institute, Barts and The London School of Medicine and Dentistry, Queen Mary University of London, Charterhouse Square, London EC1M 6BQ, UK. Departments of 2Biomarker Discovery OMNI, 3Bioinformatics and Computational Biology, Genentech Research and Early Development, South San Francisco, California 94080 USA 4Department of Rheumatology, Leiden University Medical Center, The Netherlands 5Department of Clinical Immunology & Rheumatology, Amsterdam Rheumatology & Immunology Center, Amsterdam, The Netherlands 6Rheumatology Unit, Department of Medical Sciences, Policlinico of the University of Cagliari, Cagliari, Italy 7Institute of Infection, Immunity and Inflammation, University of Glasgow, Glasgow G12 8TA, UK 8Rheumatology Research Group, Institute of Inflammation and Ageing (IIA), University of Birmingham, Birmingham B15 2WB, UK 9Institute of -

HMGB1 in Health and Disease R
Donald and Barbara Zucker School of Medicine Journal Articles Academic Works 2014 HMGB1 in health and disease R. Kang R. C. Chen Q. H. Zhang W. Hou S. Wu See next page for additional authors Follow this and additional works at: https://academicworks.medicine.hofstra.edu/articles Part of the Emergency Medicine Commons Recommended Citation Kang R, Chen R, Zhang Q, Hou W, Wu S, Fan X, Yan Z, Sun X, Wang H, Tang D, . HMGB1 in health and disease. 2014 Jan 01; 40():Article 533 [ p.]. Available from: https://academicworks.medicine.hofstra.edu/articles/533. Free full text article. This Article is brought to you for free and open access by Donald and Barbara Zucker School of Medicine Academic Works. It has been accepted for inclusion in Journal Articles by an authorized administrator of Donald and Barbara Zucker School of Medicine Academic Works. Authors R. Kang, R. C. Chen, Q. H. Zhang, W. Hou, S. Wu, X. G. Fan, Z. W. Yan, X. F. Sun, H. C. Wang, D. L. Tang, and +8 additional authors This article is available at Donald and Barbara Zucker School of Medicine Academic Works: https://academicworks.medicine.hofstra.edu/articles/533 NIH Public Access Author Manuscript Mol Aspects Med. Author manuscript; available in PMC 2015 December 01. NIH-PA Author ManuscriptPublished NIH-PA Author Manuscript in final edited NIH-PA Author Manuscript form as: Mol Aspects Med. 2014 December ; 0: 1–116. doi:10.1016/j.mam.2014.05.001. HMGB1 in Health and Disease Rui Kang1,*, Ruochan Chen1, Qiuhong Zhang1, Wen Hou1, Sha Wu1, Lizhi Cao2, Jin Huang3, Yan Yu2, Xue-gong Fan4, Zhengwen Yan1,5, Xiaofang Sun6, Haichao Wang7, Qingde Wang1, Allan Tsung1, Timothy R. -

Whole Genome Comparative Genomic Hybridization of Ewing Sarcoma Indicates Cytoskeleton, Migration and Protein Trafficking †
Proceedings Whole Genome Comparative Genomic Hybridization of Ewing Sarcoma Indicates Cytoskeleton, Migration and Protein Trafficking † Burçin Baran 1, Safiye Aktaş 1,*, Hülya Tosun 1,2, Gülden Diniz 1,2, Yasemin Çakır 1,2, Tekincan Çağrı Aktaş 1, Zekiye Altun 1 and Nur Olgun 1 1 Institute of Oncology, Dokuz Eylul University, Izmir 35340, Turkey; [email protected] (B.B.); [email protected] (H.T.); [email protected] (G.D.); [email protected] (Y.Ç.); [email protected] (T.Ç.A.); [email protected] (Z.A.); [email protected] (N.O.) 2 Dr.Behcet Uz Children’s Research Hospital, Izmir 35210, Turkey * Correspondence: [email protected] † Presented at the 2nd International Cell Death Research Congress, Izmir, Turkey, 1–4 November 2018. Published: 5 December 2018 Abstract: Ewing sarcoma is a bone and soft tissue tumor either neuroectodermal or mesenchymal originated and affecting children and adolescents. In the present study, we aimed to find out prognostic and predictive biomarkers for Ewing sarcoma. Hence, we examined the copy number alterations (and related possible genes) among ten Ewing sarcoma patient samples and possible associations with the clinical outcome. DNA extraction from formalin fixed paraffin embedded archive tissues was performed. Whole genome Comparative Genomic Hybridization (CGH) was performed by NimbleGen and recorded as single Panel Rainbow through chromosomes 1–22, X and Y. Data was interpreted by SignalMap software and genetic regions matching the deletion or amplification loci were recorded. The mean age of the patients was 8.6 years. Three of the cases were male, while seven were female. According to CGH analysis, the most common DNA copy number alterations were found in SLIT-ROBO Rho GTPase activating protein (srGAP2), RANBP2 like GRIP domain (RGPD5), nephrocystin 1 (NPHP1), GTF2I repeat domain containing 2 (GTF2IRD2), pyridoxal dependent decarboxylase domain containing 1 (PXDC1), which were found down- regulated among 7 of 10 patients. -

The Nuclear Localization Pattern and Interaction Partners of GTF2IRD1 Demonstrate a Role in Chromatin Regulation
Hum Genet DOI 10.1007/s00439-015-1591-0 ORIGINAL INVESTIGATION The nuclear localization pattern and interaction partners of GTF2IRD1 demonstrate a role in chromatin regulation Paulina Carmona‑Mora1 · Jocelyn Widagdo2 · Florence Tomasetig1 · Cesar P. Canales1 · Yeojoon Cha1 · Wei Lee1 · Abdullah Alshawaf3 · Mirella Dottori3 · Renee M. Whan4 · Edna C. Hardeman1 · Stephen J. Palmer1 Received: 11 February 2015 / Accepted: 4 August 2015 © Springer-Verlag Berlin Heidelberg 2015 Abstract GTF2IRD1 is one of the three members of the mostly involved in chromatin modification and transcrip- GTF2I gene family, clustered on chromosome 7 within a tional regulation, whilst others indicate an unexpected role 1.8 Mb region that is prone to duplications and deletions in connection with the primary cilium. Mapping of the sites in humans. Hemizygous deletions cause Williams–Beuren of protein interaction also indicates key features regarding syndrome (WBS) and duplications cause WBS duplica- the evolution of the GTF2IRD1 protein. These data provide tion syndrome. These copy number variations disturb a a visual and molecular basis for GTF2IRD1 nuclear func- variety of developmental systems and neurological func- tion that will lead to an understanding of its role in brain, tions. Human mapping data and analyses of knockout mice behaviour and human disease. show that GTF2IRD1 and GTF2I underpin the craniofacial abnormalities, mental retardation, visuospatial deficits and Abbreviations hypersociability of WBS. However, the cellular role of the hESC Human embryonic stem cells GTF2IRD1 protein is poorly understood due to its very PLA Proximity ligation assay low abundance and a paucity of reagents. Here, for the first STED Stimulated emission depletion time, we show that endogenous GTF2IRD1 has a punctate WBS Williams–Beuren syndrome pattern in the nuclei of cultured human cell lines and neu- Y2H Yeast two-hybrid rons. -

1A Multiple Sclerosis Treatment
The Pharmacogenomics Journal (2012) 12, 134–146 & 2012 Macmillan Publishers Limited. All rights reserved 1470-269X/12 www.nature.com/tpj ORIGINAL ARTICLE Network analysis of transcriptional regulation in response to intramuscular interferon-b-1a multiple sclerosis treatment M Hecker1,2, RH Goertsches2,3, Interferon-b (IFN-b) is one of the major drugs for multiple sclerosis (MS) 3 2 treatment. The purpose of this study was to characterize the transcriptional C Fatum , D Koczan , effects induced by intramuscular IFN-b-1a therapy in patients with relapsing– 2 1 H-J Thiesen , R Guthke remitting form of MS. By using Affymetrix DNA microarrays, we obtained and UK Zettl3 genome-wide expression profiles of peripheral blood mononuclear cells of 24 MS patients within the first 4 weeks of IFN-b administration. We identified 1Leibniz Institute for Natural Product Research 121 genes that were significantly up- or downregulated compared with and Infection Biology—Hans-Knoell-Institute, baseline, with stronger changed expression at 1 week after start of therapy. Jena, Germany; 2University of Rostock, Institute of Immunology, Rostock, Germany and Eleven transcription factor-binding sites (TFBS) are overrepresented in the 3University of Rostock, Department of Neurology, regulatory regions of these genes, including those of IFN regulatory factors Rostock, Germany and NF-kB. We then applied TFBS-integrating least angle regression, a novel integrative algorithm for deriving gene regulatory networks from gene Correspondence: M Hecker, Leibniz Institute for Natural Product expression data and TFBS information, to reconstruct the underlying network Research and Infection Biology—Hans-Knoell- of molecular interactions. An NF-kB-centered sub-network of genes was Institute, Beutenbergstr.