Lecture 26: “Parallel Programming”
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Operating Guide
Operating Guide EPIA EN-Series Mini-ITX Mainboard January 18, 2012 Version 1.21 EPIA EN-Series Operating Guide Table of Contents Table of Contents ...................................................................................................................................................................................... i VIA EPIA EN-Series Overview.............................................................................................................................................................. 1 VIA EPIA EN-Series Layout .................................................................................................................................................................. 2 VIA EPIA EN-Series Specifications ...................................................................................................................................................... 3 VIA EPIA EN Processor SKUs .............................................................................................................................................................. 4 VIA CN700 Chipset Overview ............................................................................................................................................................... 5 VIA EPIA EN-Series I/O Back Panel Layout ...................................................................................................................................... 6 VIA EPIA EN-Series Layout Diagram & Mounting Holes .............................................................................................................. -

SIMD Extensions
SIMD Extensions PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 12 May 2012 17:14:46 UTC Contents Articles SIMD 1 MMX (instruction set) 6 3DNow! 8 Streaming SIMD Extensions 12 SSE2 16 SSE3 18 SSSE3 20 SSE4 22 SSE5 26 Advanced Vector Extensions 28 CVT16 instruction set 31 XOP instruction set 31 References Article Sources and Contributors 33 Image Sources, Licenses and Contributors 34 Article Licenses License 35 SIMD 1 SIMD Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD Single instruction, multiple data (SIMD), is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously. Thus, such machines exploit data level parallelism. History The first use of SIMD instructions was in vector supercomputers of the early 1970s such as the CDC Star-100 and the Texas Instruments ASC, which could operate on a vector of data with a single instruction. Vector processing was especially popularized by Cray in the 1970s and 1980s. Vector-processing architectures are now considered separate from SIMD machines, based on the fact that vector machines processed the vectors one word at a time through pipelined processors (though still based on a single instruction), whereas modern SIMD machines process all elements of the vector simultaneously.[1] The first era of modern SIMD machines was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2. These machines had many limited-functionality processors that would work in parallel. -

Intel® Architecture and Tools
Klaus-Dieter Oertel Intel-SSG-Developer Products Division FZ Jülich, 22-05-2017 The “Free Lunch” is over, really Processor clock rate growth halted around 2005 Source: © 2014, James Reinders, Intel, used with permission Software must be parallelized to realize all the potential performance 4 Optimization Notice Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Changing Hardware Impacts Software More cores More Threads Wider vectors Intel® Intel® Xeon® Intel® Xeon® Intel® Xeon® Intel® Xeon® Intel® Future Intel® Xeon Intel® Xeon Phi™ Future Intel® Xeon® Processor Processor Processor Processor Xeon® Intel® Xeon® Phi™ x100 x200 Processor Xeon Phi™ Processor 5100 series 5500 series 5600 series E5-2600 v2 Processor Processor1 Coprocessor & Coprocessor (KNH) 64-bit series E5-2600 (KNC) (KNL) v3 series v4 series Up to Core(s) 1 2 4 6 12 18-22 TBD 61 72 TBD Up to Threads 2 2 8 12 24 36-44 TBD 244 288 TBD SIMD Width 128 128 128 128 256 256 512 512 512 TBD Intel® Intel® Intel® Intel® Intel® Intel® Intel® Intel® Vector ISA IMCI 512 TBD SSE3 SSE3 SSE4- 4.1 SSE 4.2 AVX AVX2 AVX-512 AVX-512 Optimization Notice Product specification for launched and shipped products available on ark.intel.com. 1. Not launched or in planning. Copyright © 2016, Intel Corporation. All rights reserved. 9 *Other names and brands may be claimed as the property of others. Changing Hardware Impacts Software More cores More Threads Wider vectors Intel® Intel® Xeon® Intel® Xeon® Intel® Xeon® Intel® Xeon® Intel® Future Intel® Xeon Intel® Xeon Phi™ Future Intel® Xeon® Processor Processor Processor Processor Xeon® Intel® Xeon® Phi™ x100 x200 Processor Xeon Phi™ Processor 5100 series 5500 series 5600 series E5-2600 v2 Processor Processor1 Coprocessor & Coprocessor (KNH) 64-bit series E5-2600 (KNC) (KNL) v3 series v4 series Up to Core(s) 1 2 4 6 12 18-22 TBD 61 72 TBD Up to Threads 2 High2 performance8 12 24software36-44 mustTBD be 244both: 288 TBD SIMD Width 128 . -

Intel® Software Guard Extensions (Intel® SGX)
Intel® Software Guard Extensions (Intel® SGX) Developer Guide Intel(R) Software Guard Extensions Developer Guide Legal Information No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. Intel disclaims all express and implied warranties, including without limitation, the implied war- ranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice. Contact your Intel rep- resentative to obtain the latest forecast, schedule, specifications and roadmaps. The products and services described may contain defects or errors known as errata which may cause deviations from published specifications. Current characterized errata are available on request. Intel technologies features and benefits depend on system configuration and may require enabled hardware, software or service activation. Learn more at Intel.com, or from the OEM or retailer. Copies of documents which have an order number and are referenced in this document may be obtained by calling 1-800-548-4725 or by visiting www.intel.com/design/literature.htm. Intel, the Intel logo, Xeon, and Xeon Phi are trademarks of Intel Corporation in the U.S. and/or other countries. Optimization Notice Intel's compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. -

AMD Ryzen 5 1600 Specifications
AMD Ryzen 5 1600 specifications General information Type CPU / Microprocessor Market segment Desktop Family AMD Ryzen 5 Model number 1600 CPU part numbers YD1600BBM6IAE is an OEM/tray microprocessor YD1600BBAEBOX is a boxed microprocessor with fan and heatsink Frequency 3200 MHz Turbo frequency 3600 MHz Package 1331-pin lidded micro-PGA package Socket Socket AM4 Introduction date March 15, 2017 (announcement) April 11, 2017 (launch) Price at introduction $219 Architecture / Microarchitecture Microarchitecture Zen Processor core Summit Ridge Core stepping B1 Manufacturing process 0.014 micron FinFET process 4.8 billion transistors Data width 64 bit The number of CPU cores 6 The number of threads 12 Floating Point Unit Integrated Level 1 cache size 6 x 64 KB 4-way set associative instruction caches 6 x 32 KB 8-way set associative data caches Level 2 cache size 6 x 512 KB inclusive 8-way set associative unified caches Level 3 cache size 2 x 8 MB exclusive 16-way set associative shared caches Multiprocessing Uniprocessor Features MMX instructions Extensions to MMX SSE / Streaming SIMD Extensions SSE2 / Streaming SIMD Extensions 2 SSE3 / Streaming SIMD Extensions 3 SSSE3 / Supplemental Streaming SIMD Extensions 3 SSE4 / SSE4.1 + SSE4.2 / Streaming SIMD Extensions 4 SSE4a AES / Advanced Encryption Standard instructions AVX / Advanced Vector Extensions AVX2 / Advanced Vector Extensions 2.0 BMI / BMI1 + BMI2 / Bit Manipulation instructions SHA / Secure Hash Algorithm extensions F16C / 16-bit Floating-Point conversion instructions -

X86 Intrinsics Cheat Sheet Jan Finis [email protected]
x86 Intrinsics Cheat Sheet Jan Finis [email protected] Bit Operations Conversions Boolean Logic Bit Shifting & Rotation Packed Conversions Convert all elements in a packed SSE register Reinterpet Casts Rounding Arithmetic Logic Shift Convert Float See also: Conversion to int Rotate Left/ Pack With S/D/I32 performs rounding implicitly Bool XOR Bool AND Bool NOT AND Bool OR Right Sign Extend Zero Extend 128bit Cast Shift Right Left/Right ≤64 16bit ↔ 32bit Saturation Conversion 128 SSE SSE SSE SSE Round up SSE2 xor SSE2 and SSE2 andnot SSE2 or SSE2 sra[i] SSE2 sl/rl[i] x86 _[l]rot[w]l/r CVT16 cvtX_Y SSE4.1 cvtX_Y SSE4.1 cvtX_Y SSE2 castX_Y si128,ps[SSE],pd si128,ps[SSE],pd si128,ps[SSE],pd si128,ps[SSE],pd epi16-64 epi16-64 (u16-64) ph ↔ ps SSE2 pack[u]s epi8-32 epu8-32 → epi8-32 SSE2 cvt[t]X_Y si128,ps/d (ceiling) mi xor_si128(mi a,mi b) mi and_si128(mi a,mi b) mi andnot_si128(mi a,mi b) mi or_si128(mi a,mi b) NOTE: Shifts elements right NOTE: Shifts elements left/ NOTE: Rotates bits in a left/ NOTE: Converts between 4x epi16,epi32 NOTE: Sign extends each NOTE: Zero extends each epi32,ps/d NOTE: Reinterpret casts !a & b while shifting in sign bits. right while shifting in zeros. right by a number of bits 16 bit floats and 4x 32 bit element from X to Y. Y must element from X to Y. Y must from X to Y. No operation is SSE4.1 ceil NOTE: Packs ints from two NOTE: Converts packed generated. -
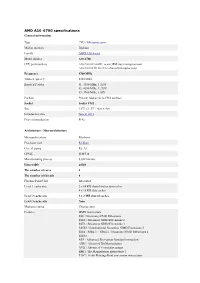
AMD A10-6700 Specifications General Information
AMD A10-6700 specifications General information Type CPU / Microprocessor Market segment Desktop Family AMD A10-Series Model number A10-6700 CPU part numbers AD6700OKA44HL is an OEM/tray microprocessor AD6700OKHLBOX is a boxed microprocessor Frequency 3700 MHz Turbo frequency 4300 MHz Boosted P states #1: 4300 MHz, 1.325V #2: 4200 MHz, 1.275V #3: 3900 MHz, 1.05V Package 904-pin lidded micro-PGA package Socket Socket FM2 Size 1.57" x 1.57" / 4cm x 4cm Introduction date June 4, 2013 Price at introduction $142 Architecture / Microarchitecture Microarchitecture Piledriver Processor core Richland Core stepping RL-A1 CPUID 610F31h Manufacturing process 0.032 micron Data width 64 bit The number of cores 4 The number of threads 4 Floating Point Unit Integrated Level 1 cache size 2 x 64 KB shared instruction caches 4 x 16 KB data caches Level 2 cache size 2 x 2 MB shared caches Level 3 cache size None Multiprocessing Uniprocessor Features MMX instructions SSE / Streaming SIMD Extensions SSE2 / Streaming SIMD Extensions 2 SSE3 / Streaming SIMD Extensions 3 SSSE3 / Supplemental Streaming SIMD Extensions 3 SSE4 / SSE4.1 + SSE4.2 / Streaming SIMD Extensions 4 SSE4a AES / Advanced Encryption Standard instructions ABM / Advanced Bit Manipulation AVX / Advanced Vector Extensions BMI1 / Bit Manipulation instructions 1 F16C / 16-bit Floating-Point conversion instructions FMA3 / 3-operand Fused Multiply-Add instructions FMA4 / 4-operand Fused Multiply-Add instructions TBM / Trailing Bit Manipulation instructions XOP / eXtended Operations instructions AMD64 -

PC-Doctor Service Center 12 Data Sheet
PC-Doctor Service Center TM Data Sheet PC-Doctor Service Center is the diagnostic toolkit used by repair organizations, IT professionals, system builders and others to troubleshoot and isolate hardware issues, and to verify system integrity on servers, desktops, notebooks and mobile devices. The Service Center Kit includes diagnostics for Windows, DOS, Android, and Bootable Diagnostics that includes support for PCs and Intel-based Macs. Each kit contains a bootable USB key, CD and DVD test media, loopback adapters for serial, parallel, audio, and RJ45 ports, and a professional carrying case. In addition, the Service Center Premier Kit includes a power supply tester and PCI and miniPCI POST cards with remote display. What’s New? • Drive Erase – Certified NIST compliant! • Organize by customer, system or other desired parameters o Sanitization improvements for NVMe and ATA drives • Store test results from multiple test environments in one place as organized by your choice of sessions o Cloud storage for reports • Android version 8.x Oreo and 9.x Pie support My Links • Support for NVDIMM testing Create shortcuts to the most used utilities, test scripts, • DirectX 12 testing or websites: The first five links are added to the main • Storage testing improvements application screen for easy access. o Improved SAS drive coverage o Improved Intel Optane support System Snapshots o Expanded NVMe testing Snapshots provide a one-click solution to save a • Improved processor support detailed system inventory on PCs and Macs: o AMD Ryzen Mobile CPUs • All hardware devices o Skylake-W Xeon processors • (Windows) OS, virus protection, web browser, o AVX2 for AMD CPUs Windows startup programs and device drivers • Windows Server 2016 support Compare two system snapshots to visually display all • Updated Video Interactive testing hardware and driver changes—great for auditing and building customer confidence. -

Intel® Architecture Instruction Set Extensions and Future Features Programming Reference
Intel® Architecture Instruction Set Extensions and Future Features Programming Reference 319433-030 OCTOBER 2017 Intel technologies features and benefits depend on system configuration and may require enabled hardware, software, or service activation. Learn more at intel.com, or from the OEM or retailer. No computer system can be absolutely secure. Intel does not assume any liability for lost or stolen data or systems or any damages resulting from such losses. You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to grant Intel a non-exclusive, royalty-free license to any patent claim thereafter drafted which includes subject matter disclosed herein. No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifica- tions. Current characterized errata are available on request. This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice. Intel does not guarantee the availability of these interfaces in any future product. Contact your Intel representative to obtain the latest Intel product specifications and roadmaps. Copies of documents which have an order number and are referenced in this document, or other Intel literature, may be obtained by calling 1- 800-548-4725, or by visiting http://www.intel.com/design/literature.htm. Intel, the Intel logo, Intel Atom, Intel Core, Intel SpeedStep, MMX, Pentium, VTune, and Xeon are trademarks of Intel Corporation in the U.S. -

Introduction to Intel Scalable Architectures
Introduction to Intel scalable architectures Fabio Affinito (SCAI - Cineca) Available options... Right here, right now… two kind of solutions are available on the market: ● IBM+ nVIDIA (Coral-like) ● Intel-based (Xeon/Xeon Phi) IBM+NVIDIA Each node will be based on a Power CPU + 4/6/8 nVIDIA TESLA GPUs connected using an nVIDIA NVlink interconnect Intel Xeon and Xeon Phi Intel will keep on with the production of server processors on the Xeon line, together with the introduction of the Xeon Phi many-core chips Intel Xeon Phi will not be a co-processor anymore, but a self-standing CPU with a very high number of cores Such systems are integrated by several vendors in many different configurations (Cray, HP, Lenovo, E4..) MARCONI FERMI, the IBM BlueGene/Q deployed in Cineca ended its lifecycle in 2016 We needed a new HPC machine that could - increase the computational power - respect the agreements with PRACE - satisfy the needs of the italian computing community MARCONI MARCONI NeXtScale architecture nx360M5 nodes: Supporting Intel HSW & BDW Able to host both IB network Mellanox EDR & Intel Omni-Path Twelve nodes are grouped into a Chassis (6 chassis per rack) The compute node is made of: 2 x Intel Broadwell (Xeon processor E5-2697 v4) 18 cores, 2,3 HGz 8 x 16GB DIMM memory (RAM DDR4 2400 MHz), 128 GB total 1 x 129 GB SATA MLC S3500 Enterprise Value SSD Further details 1 x link OPA 100GBs 2*18*2,3*16 = 1.325 GFs peak 24 rack in total: 21 rack compute 1 rack service nodes 2 racks core switch MARCONI - Network MARCONI - Network MARCONI - Storage -

Intel® Architecture Instruction Set Extensions and Future Features
Intel® Architecture Instruction Set Extensions and Future Features Programming Reference May 2021 319433-044 Intel technologies may require enabled hardware, software or service activation. No product or component can be absolutely secure. Your costs and results may vary. You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to grant Intel a non-exclusive, royalty-free license to any patent claim thereafter drafted which includes subject matter disclosed herein. No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. All product plans and roadmaps are subject to change without notice. The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. Code names are used by Intel to identify products, technologies, or services that are in development and not publicly available. These are not “commercial” names and not intended to function as trademarks. Copies of documents which have an order number and are referenced in this document, or other Intel literature, may be ob- tained by calling 1-800-548-4725, or by visiting http://www.intel.com/design/literature.htm. Copyright © 2021, Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. -

Streaming SIMD Extension (SSE) SIMD Architectures
Streaming SIMD Extension (SSE) SIMD architectures • A data parallel architecture • Applying the same instruction to many data – Save control logic – A related architecture is the vector architecture – SIMD and vector architectures offer hhhigh performance for vector operations. Vector operations ⎛ x ⎞ ⎛ y ⎞ ⎛ x + y ⎞ • Vector addition Z = X + Y ⎜ 1 ⎟ ⎜ 1 ⎟ ⎜ 1 1 ⎟ ⎜ x2 ⎟ ⎜ y2 ⎟ ⎜ x2 + y2 ⎟ + = ⎜ ... ⎟ ⎜ ... ⎟ ⎜ ...... ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ for (i=0; i<n; i++) z[i] = x[i] + y[i]; ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎝ xn ⎠ ⎝ yn ⎠ ⎝ xn + yn ⎠ ⎛ x ⎞ ⎛ a* x ⎞ • Vector scaling Y = a * X ⎜ 1 ⎟ ⎜ 1 ⎟ ⎜ x2 ⎟ ⎜a* x2 ⎟ a* = ⎜ ... ⎟ ⎜ ...... ⎟ for(i=0; i<n; i++) y[i] = a*x[i]; ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎝ xn ⎠ ⎝a* xn ⎠ ⎛ x ⎞ ⎛ y ⎞ • Dot product ⎜ 1 ⎟ ⎜ 1 ⎟ ⎜ x2 ⎟ ⎜ y2 ⎟ • = x * y + x * y +......+ x * y ⎜ ... ⎟ ⎜ ... ⎟ 1 1 2 2 n n for(i=0; i<n; i++) r += x[i]*y[i]; ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎝ xn ⎠ ⎝ yn ⎠ SISD and SIMD vector operations • C = A + B – For (i=0;i<n; i++) c[][i] = a[][i] + b[i ] C A 909.0 808.0 707.0 606.0 505.0 404.0 303.0 202.0 101.0 SISD 10 9.0 8.0 7.0 6.0 5.0 4.0 3.0 2.0 + B 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 A 7.0 5.0 3.0 1.0 808.0 606.0 404.0 202.0 SIMD 8.0 6.0 4.0 2.0 + C 9.0 7.0 5.0 3.0 1.0 1.0 1.0 1.0 + B 1.0 1.0 1.0 1.0 x86 architecture SIMD support • Both current AMD and Intel’s x86 processors have ISA and microarchitecture support SIMD operations.