An Analysis of the Size and Impact of Digital Footprints Whitney Nielsen Maxwell Brigham Young University
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tracking My Digital Footprint a Guide to Digital Footprint Discovery and Management
Tracking my Digital Footprint A guide to digital footprint discovery and management © CROWN COPYRIGHT 2015 | TRACKING MY DIGITAL FOOTPRINT: A GUIDE TO DIGITAL FOOTPRINT DISCOVERY AND MANAGEMENT © Crown Copyright 2015 Disclaimer Reference to any specific commercial product, process or service by trade name, trademark, manufacturer, or otherwise, does not constitute or imply its endorsement, recommendation or favour by CPNI. The views and opinions of authors expressed within this document shall not be used for advertising or product endorsement purposes. To the fullest extent permitted by law, CPNI accepts no liability for any loss or damage (whether direct, indirect or consequential, and including but not limited to, loss of profits or anticipated profits, loss of data, business or goodwill) incurred by any person and howsoever caused arising from or connected with any error or omission in this document or from any person acting, omitting to act or refraining from acting upon, or otherwise using the information contained in this document or its references. You should make your own judgment as regards use of this document and seek independent professional advice on your particular circumstances. 1 © CROWN COPYRIGHT 2015 | TRACKING MY DIGITAL FOOTPRINT: A GUIDE TO DIGITAL FOOTPRINT DISCOVERY AND MANAGEMENT “Every day most of us contribute to an evolving public presentation of who we are that anyone can see and that we cannot erase. We might think we are at home on our laptops, cell phones or iPads communicating with just a few people on -

What's Your Digital Footprint?
What’s your digital footprint? Teacher’s guide and handouts Introduction: This lesson plan introduces students to the concepts of privacy and professionalism online. Students will search for their “digital footprint,” or publicly available information tied to them on the web, on popular social media sites like Facebook, Instagram, Twitter and LinkedIn. Students discuss what it means to be professional and then change their privacy settings on their social networks to reflect their wishes. Learning Objectives: ● Students are aware of what information about themselves is publicly available ● Students can name at least two ways to protect their personal information and identity on social networks ● Students know how to alter security settings on common social networks, including Facebook, Twitter and Instagram ● Students can describe characteristics that differ between a “professional” and “unprofessional” digital footprint for an entry level internship Estimated Duration: 30-60 minutes (depends on length of discussion) Ages: 13+ (may need to be adjusted for younger students) -- see important notes section below Materials: ● Pencil or pen ● Worksheet (provided) ● Computers, tablets or smart phones ● Internet access to social media sites ● Ground Rules set by the class Important Notes: ● Social media searches may bring up compromising information or images on some of your students that they may not wish to share with others. ● Anticipate that some students may find information they find upsetting when searching themselves, such as cyberbullying. ● Consider allowing students to opt out, or modifying the in-class activity to focus on a profile you have already vetted, such as yourself, a fake profile, a celebrity or colleague. Scenario: Tell the student he/she is about to apply for a position as a social media intern at a local radio station. -

Your Digital Footprint
Intel® Learn Easy Steps Activity Card Digital Footprint Your Digital Footprint Are you wondering what happens to the information you share online? Are you worried about posting details about yourself on the Internet? Would you like to know how to better share your personal information? Making sure you understand how your data is stored, shared, and found online is an important part of protecting yourself online. Your digital footprint, or the trail of data left behind by users on digital devices, and how it is maintained is an important aspect of your online safety. This trail of data not only builds an online reputation, but will follow you into the future and even into your offline life. How to Understand Your Digital Footprint A. While browsing the web (Passive User Footprint) Cookies and Browsing History 1. Browsing History: You can clear your browser’s History or manage settings to customize when or how long your browser retains your History. 2. Cookies: Cookies are small files, consisting of letters and numbers, placed on your computer, tablet, phone, or similar device, when you use that device to visit a web site. Cookies are widely used by web site owners to make their web sites operate, work more efficiently, and provide analytic information (Intel). You can turn Cookies off in your browser’s Preferences. B. While adding content to the web (Active User Footprint) 1. Community Member: As members of any community, we should be conscious of how we present ourselves in public arenas, including the Internet. Even though it is possible to delete content from online profiles, or cancel an account altogether, the data was shared and could be saved by other users or by the entity or service being accessed. -

Online Reputation Checklist Your Digital Footprint Is the Mark That You Leave Behind When Using the Internet and Can Shape Your Online Reputation
Online Reputation Checklist Your digital footprint is the mark that you leave behind when using the internet and can shape your online reputation. Your digital footprints can be positive or negative and shape how people see you now or in the future. Use our simple checklist to help manage and maintain your online reputation. Search yourself online: do you know what is online about you? Do a simple web search of your name and see what you can fi nd. If you fi nd something you aren’t happy with, take the necessary steps to get that content removed. Remember, if your Facebook or Twitter pages appear you can change this by adjusting your privacy settings. Check privacy settings: make sure you know what information you are sharing on the websites you use, in particular on social networking sites. Most social networking sites have privacy settings to help you manage the content you share and who you share it with; you can decide if you want your posts to be shared with your online friends and followers only or with the public. Keep in mind that your friend’s content and their settings can also affect your digital footprint. Think before you post: before you post that funny picture of your friend, or make that joke about someone on Twitter, ask yourself do you want everyone to see it; friends, family, grandparents, future employers? Would you be happy for others to post that type of content about you? You should be proud of everything you post online, remember once it is online it could potentially be there forever! Deactivate and delete: when you stop using a social networking profi le or website, it’s a good idea to deactivate or delete your account. -

Digital Footprints: Your Unique Identity Juanita Blue ● Joan Condell ● Tom Lunney
Digital Footprints: Your Unique Identity Juanita Blue ● Joan Condell ● Tom Lunney Digital Footprints: Your Unique Identity Juanita Blue Joan Condell Tom Lunney University of Ulster University of Ulster University of Ulster Derry, Northern Ireland, UK Derry, Northern Ireland, UK Derry, Northern Ireland, UK [email protected] [email protected] [email protected] In the digital age where Human Computer Interaction is creating large and entirely unique digital footprints, online accounts and activities can prove to be a valuable source of information that may contribute to verification that an asserted identity is genuine. Online social contextual data – or ‘Digital identities’ -- pertaining to real people are built over time and bolstered by associated accounts, relationships and attributes. This data is difficult to fake and therefore may have the capacity to provide proof of a ‘real’ identity. This paper outlines the design and initial development of a solution that utilizes data sourced from an individual’s digital footprint to assess the likelihood that it pertains to a ‘real’ identity. This is achieved through application of machine learning and Bayesian probabilistic modelling techniques. Identity; Authentication; Digital Footprint, Privacy; Security 1. INTRODUCTION As individuals spend increasing amounts of time 2010). In a cyber context, this social identity is interacting online, the line between their physical lives demonstrated via an individual’s digital footprint. and their digital lives is becoming increasingly blurred. Therefore, it may be surmised that the same Digital footprints map and record the activities that behaviours possess the potential to aid authentication substantiate each individual’s online life. -
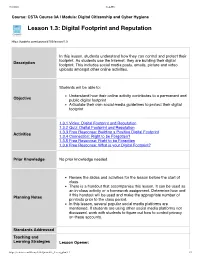
Lesson 1.3: Digital Footprint and Reputation
7/2/2020 CodeHS Course: CSTA Course 3A | Module: Digital Citizenship and Cyber Hygiene Lesson 1.3: Digital Footprint and Reputation https://codehs.com/course/6103/lesson/1.3 In this lesson, students understand how they can control and protect their footprint. As students use the Internet, they are building their digital Description footprint. This includes social media posts, emails, picture and video uploads amongst other online activities. Students will be able to: Understand how their online activity contributes to a permanent and Objective public digital footprint Articulate their own social media guidelines to protect their digital footprint 1.3.1 Video: Digital Footprint and Reputation 1.3.2 Quiz: Digital Footprint and Reputation 1.3.3 Free Response: Building a Positive Digital Footprint Activities 1.3.4 Connection: Right to be Forgotten? 1.3.5 Free Response: Right to be Forgotten 1.3.6 Free Response: What is your Digital Footprint? Prior Knowledge No prior knowledge needed. Review the slides and activities for the lesson before the start of class. There is a handout that accompanies this lesson. It can be used as an in-class activity or a homework assignment. Determine how and if this handout will be used and make the appropriate number of Planning Notes printouts prior to the class period. In this lesson, several popular social media platforms are mentioned. If students are using other social media platforms not discussed, work with students to figure out how to control privacy on these accounts. Standards Addressed Teaching and Learning Strategies Lesson Opener: https://codehs.com/library/6103/printable_lesson_plan/1.3 1/3 7/2/2020 CodeHS Have your students create an identity word cloud. -

Our Digital Footprint: Protecting the Next Generation of Field Personnel
Karen Ann Tremper | 187 Our Digital Footprint: Protecting the Next Generation of Field Personnel Karen Ann Tremper DOI: 10.7252/Paper. 000055 About the Author Karen Ann Tremper is a Professor and Director of Global Life at Life Pacifc College. Served with Wyclife Bible Translators and YWAM and is an ordained minister in the Foursquare Church. 188 | Our Digital Footprint: Abstract We live in a global community that continues to become exceedingly smaller. As universities and colleges face the challenges of preparing students to “go to the ends of the earth” it has become evident that providing outstanding curriculum is not the only aspect of preparation they must consider. Te specifc language used to promote their programs must be adjusted since their audience has expanded well beyond their perspective or current students. Internet access has allowed the global community to visit universities and their program oferings online. As degree programs seek to neutralize their language a further element that must be addressed is the extracurricular programs that supplement student learning. Te issue more precisely is the digital footprint that is left by the university and students themselves through social media, not limited to the university’s website. Tis digital footprint, if not properly neutralized, can have ramifcations in the future for a student whose heart is for the mission feld. Tis paper seeks to address the need to consider changes in the language used to describe extracurricular programs as well as the use of social media and its potentially damaging digital footprint on the future of the next generation of feld personnel. -

Digital Footprint & Reputation
Digital Footprint & Reputation In order to build a positive self-image and identity online, it is important to remember that the nature of the Internet is very public and permanent; nothing on the Internet is private, even if you added a password. Information you choose to share with others can easily be broadcast without permission. Anything shared online might resurface in the future so it is crucial to make a conscious effort to manage your own privacy and respect the privacy of others. Self-reflect before you self-reveal! What is Digital Footprint? Choose a video to show your students as an introduction to Digital Footprint: Primary: https://www.commonsensemedia.org/videos/follow-the-digital-trail Intermediate: https://www.commonsensemedia.org/videos/digital-footprint Alternate: Amazing Mind Reader Reveals his ‘Gift’ - https://youtu.be/F7pYHN9iC9I Reflection Questions Reflect on what your current Digital Footprint. What does your typical daily online activity entail? What kind of personal information have you shared about yourself and your friends? What does it say about you as a person? How can you show respect to others’ privacy when tagging, posting, or sharing information? o Poster: “I Took a Photo of my Friend that I Want to Share. Now What?” https://www.commonsensemedia.org/educators/middlehigh_poster What are possible harmful effects of over-sharing? How can you build and maintain a positive online presence? Reputation – Building a Positive Online Identity Who are you? What do you want others to know about you? Using the footprint frame, students can do one of the following: Draw and label images of things you feel are safe to share about yourself. -

Guide to Self- Defence Tools
Considering that we are living in what ten create these services simply as bait and implementation, they sketch a map Mark Zuckerberg has called the age for getting hold of data (“the product is of what could be the future of electron- when privacy is over, there are a sur- you”). The table that we reproduce be- ic self-defence: a world in which the cli- prising number of alternatives devel- low, that does not aim to be exhaustive ent-product is affirmed as a citizen and oping in the most common systems and nor definitive, but illustrative, includes demands control over the data he or she solutions for sharing data online. From some of the alternatives with the great- generates and the information deriving Guidethe social networks to email, to and pass- est impactSelf- in spheres still controlled to- from them. ing through search engines, services in day by those large corporations, as well the cloud or voice over Internet, in re- as solutions that help to raise awareness cent years we are witnessing the emer- of how personal data are (mis)managed gence of alternatives to the standards in the digital world. With different levels developed by large companies, which of- of user-friendliness, privacy protection, 15 Defence Tools - 14 Category Description/Conventional products Alternatives Audio/ The spread of the use of alternatives to conventional telephone services through Jitsi Free and open-source multiplatform voice (VoIP), videoconferencing and IM Video/ Voice over IP (VoIP) services is not related with the revelations made by Edward application for Windows, Linux and Mac OS X with LPG license. -

Reducing Your Digital Footprint
COUNTERINTELLIGENCE TIPS REDUCING YOUR DIGITAL FOOTPRINT Every time you connect to the Internet, or use your mobile phone, tablet, laptop, or other digital device, a trail follows. Intentionally shared personal data—such as social media postings—represent your active digital footprint. Online data collected unknowingly about you is your passive digital footprint. Comments on social media, online shopping, e-mail, cell and Skype calls, and media applications all contribute to your digital footprint. In addition, a cell phone can store geographical locations that pinpoint your route, home, and hotel, among others. It’s important to be aware of the trail you are creating, its possible consequences, and ways to limit digital traces that may expose you and your association with the government. TAKE STEPS TO UNDERSTAND AND MINIMIZE YOUR PASSIVE FOOTPRINT When Traveling Outside of the United States: • Leave personal devices at home. • Buy a throw away or pay-as-you-go phone. • Use a Wi-Fi only tablet and create a new e-mail and Skype address for communicating. Do not log into any other existing, identifying personal accounts such as Facebook or Twitter. Disable Location Services on Your Phones or Other Mobile Devices For Apple devices: • Navigate to Settings > Privacy > Location Services > Select “Off” • Navigate to Settings > Privacy > Diagnostics & Usage > Select “Don’t Send” For Android devices: • Open Settings > Personal > Location > Select “Off” • Open Settings > Google > Location > Google Location History > Select “Off” • Google Location History > Manage Activities > > Settings > Delete all Location History INTERNET RESOURCES OnGuardOnline.gov Operated by the Federal Trade Commission (FTC), this site provides tips and technical guidance on cybersecurity issues as well as a guide for talking to children about Internet use. -
How to Download Iso in Tails How to Create an Anonymous Bootable Tails USB
how to download iso in tails How to Create an Anonymous Bootable Tails USB. Tails isn’t the kind of operating system that you want to install on your hard drive. The Tails developers specifically configured it to forget everything that you’ve done when you reboot. While that doesn’t make it a good general purpose OS, it does mean that running off of a USB that you can load up whenever you want to use a computer privately and anonymously is an excellent option. What You’ll Need. Before you get started making your Tails USB, you’ll need a couple of things. First, you’ll need two USBs. Only Tails can install a full version of Tails. You’ll have to install an intermediary version of Tails on one USB first. Then, you can install Tails from that one. Next, you’ll need a computer running either Windows or Linux. That computer will download Tails and create the first USB. Finally, you’re going to want to open this article on your phone. This way you can follow along, even after you have to restart your computer. Download and Verify Tails. There are a couple of ways to do this. By far, the easiest is to use the Firefox add-on that the Tails project set up. Go to the Tails download page using Firefox. You’ll see a couple of steps listed. The first will be highlighted purple, and it will prompt you to install the Firefox add-on. The next button will light up purple, after the add-on installs. -

Big Data and Passive Digital Footprints
An Authentic Self: Big Data and Passive Digital Footprints L. Y. Williams, D. M. Pennington Faculty, MSIT, MSCM, School of Business and Information Technology Purdue Global University Lecturer, Department of Computer and Information Sciences The University of Strathclyde Glasgow, United Kingdom email: [email protected], [email protected] Abstract The ability to allow users to create online communities of interest and to share a variety of personal information, collectively referred to as social media, is gradually being built into an expanding range of applications. Some of these applications, such as computer operating systems, were not originally intended to collect information from the user. Thus, users may not be aware that their digital information is being collected. Devices such as smart televisions, smart cars, and even smart grids, are now collecting massive quantities of user data without the user’s knowledge. Users of social media, and the internet in general, leave fragments of their activities and intentions behind them across an increasing range of technologies. These fragments collectively and passively create a hidden identity built up from metadata of which the user is mostly unaware. Given that the user builds this hidden identity during the normal course of their day, without editing elements that the user may not wish to share with others, might the passive digital footprint more accurately reveal the individual's genuine or authentic self than the individual realises? We propose that an aggregated, passively collected digital portrait of a user's unconscious but connected activities may reveal a more genuine view of that person's self than would be deduced from sources over which the user has conscious control.