Model Comparison with Sharpe Ratios
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Fact Sheet 2021
Q2 2021 GCI Select Equity TM Globescan Capital was Returns (Average Annual) Morningstar Rating (as of 3/31/21) © 2021 Morningstar founded on the principle Return Return that investing in GCI Select S&P +/- Percentile Quartile Overall Funds in high-quality companies at Equity 500TR Rank Rank Rating Category attractive prices is the best strategy to achieve long-run Year to Date 18.12 15.25 2.87 Q1 2021 Top 30% 2nd 582 risk-adjusted performance. 1-year 43.88 40.79 3.08 1 year Top 19% 1st 582 As such, our portfolio is 3-year 22.94 18.67 4.27 3 year Top 3% 1st 582 concentrated and focused solely on the long-term, Since Inception 20.94 17.82 3.12 moat-protected future free (01/01/17) cash flows of the companies we invest in. TOP 10 HOLDINGS PORTFOLIO CHARACTERISTICS Morningstar Performance MPT (6/30/2021) (6/30/2021) © 2021 Morningstar Core Principles Facebook Inc A 6.76% Number of Holdings 22 Return 3 yr 19.49 Microsoft Corp 6.10% Total Net Assets $44.22M Standard Deviation 3 yr 18.57 American Tower Corp 5.68% Total Firm Assets $119.32M Alpha 3 yr 3.63 EV/EBITDA (ex fincls/reits) 17.06x Upside Capture 3yr 105.46 Crown Castle International Corp 5.56% P/E FY1 (ex fincls/reits) 29.0x Downside Capture 3 yr 91.53 Charles Schwab Corp 5.53% Invest in businesses, EPS Growth (ex fincls/reits) 25.4% Sharpe Ratio 3 yr 1.04 don't trade stocks United Parcel Service Inc Class B 5.44% ROIC (ex fincls/reits) 14.1% Air Products & Chemicals Inc 5.34% Standard Deviation (3-year) 18.9% Booking Holding Inc 5.04% % of assets in top 5 holdings 29.6% Mastercard Inc A 4.74% % of assets in top 10 holdings 54.7% First American Financial Corp 4.50% Dividend Yield 0.70% Think long term, don't try to time markets Performance vs S&P 500 (Average Annual Returns) Be concentrated, 43.88 GCI Select Equity don't overdiversify 40.79 S&P 500 TR 22.94 20.94 18.12 18.67 17.82 15.25 Use the market, don't rely on it YTD 1 YR 3 YR Inception (01/01/2017) Disclosures Globescan Capital Inc., d/b/a GCI-Investors, is an investment advisor registered with the SEC. -

Lapis Global Top 50 Dividend Yield Index Ratios
Lapis Global Top 50 Dividend Yield Index Ratios MARKET RATIOS 2012 2013 2014 2015 2016 2017 2018 2019 2020 P/E Lapis Global Top 50 DY Index 14,45 16,07 16,71 17,83 21,06 22,51 14,81 16,96 19,08 MSCI ACWI Index (Benchmark) 15,42 16,78 17,22 19,45 20,91 20,48 14,98 19,75 31,97 P/E Estimated Lapis Global Top 50 DY Index 12,75 15,01 16,34 16,29 16,50 17,48 13,18 14,88 14,72 MSCI ACWI Index (Benchmark) 12,19 14,20 14,94 15,16 15,62 16,23 13,01 16,33 19,85 P/B Lapis Global Top 50 DY Index 2,52 2,85 2,76 2,52 2,59 2,92 2,28 2,74 2,43 MSCI ACWI Index (Benchmark) 1,74 2,02 2,08 2,05 2,06 2,35 2,02 2,43 2,80 P/S Lapis Global Top 50 DY Index 1,49 1,70 1,72 1,65 1,71 1,93 1,44 1,65 1,60 MSCI ACWI Index (Benchmark) 1,08 1,31 1,35 1,43 1,49 1,71 1,41 1,72 2,14 EV/EBITDA Lapis Global Top 50 DY Index 9,52 10,45 10,77 11,19 13,07 13,01 9,92 11,82 12,83 MSCI ACWI Index (Benchmark) 8,93 9,80 10,10 11,18 11,84 11,80 9,99 12,22 16,24 FINANCIAL RATIOS 2012 2013 2014 2015 2016 2017 2018 2019 2020 Debt/Equity Lapis Global Top 50 DY Index 89,71 93,46 91,08 95,51 96,68 100,66 97,56 112,24 127,34 MSCI ACWI Index (Benchmark) 155,55 137,23 133,62 131,08 134,68 130,33 125,65 129,79 140,13 PERFORMANCE MEASURES 2012 2013 2014 2015 2016 2017 2018 2019 2020 Sharpe Ratio Lapis Global Top 50 DY Index 1,48 2,26 1,05 -0,11 0,84 3,49 -1,19 2,35 -0,15 MSCI ACWI Index (Benchmark) 1,23 2,22 0,53 -0,15 0,62 3,78 -0,93 2,27 0,56 Jensen Alpha Lapis Global Top 50 DY Index 3,2 % 2,2 % 4,3 % 0,3 % 2,9 % 2,3 % -3,9 % 2,4 % -18,6 % Information Ratio Lapis Global Top 50 DY Index -0,24 -

Arbitrage Pricing Theory: Theory and Applications to Financial Data Analysis Basic Investment Equation
Risk and Portfolio Management Spring 2010 Arbitrage Pricing Theory: Theory and Applications To Financial Data Analysis Basic investment equation = Et equity in a trading account at time t (liquidation value) = + Δ Rit return on stock i from time t to time t t (includes dividend income) = Qit dollars invested in stock i at time t r = interest rate N N = + Δ + − ⎛ ⎞ Δ ()+ Δ Et+Δt Et Et r t ∑Qit Rit ⎜∑Qit ⎟r t before rebalancing, at time t t i=1 ⎝ i=1 ⎠ N N N = + Δ + − ⎛ ⎞ Δ + ε ()+ Δ Et+Δt Et Et r t ∑Qit Rit ⎜∑Qit ⎟r t ∑| Qi(t+Δt) - Qit | after rebalancing, at time t t i=1 ⎝ i=1 ⎠ i=1 ε = transaction cost (as percentage of stock price) Leverage N N = + Δ + − ⎛ ⎞ Δ Et+Δt Et Et r t ∑Qit Rit ⎜∑Qit ⎟r t i=1 ⎝ i=1 ⎠ N ∑ Qit Ratio of (gross) investments i=1 Leverage = to equity Et ≥ Qit 0 ``Long - only position'' N ≥ = = Qit 0, ∑Qit Et Leverage 1, long only position i=1 Reg - T : Leverage ≤ 2 ()margin accounts for retail investors Day traders : Leverage ≤ 4 Professionals & institutions : Risk - based leverage Portfolio Theory Introduce dimensionless quantities and view returns as random variables Q N θ = i Leverage = θ Dimensionless ``portfolio i ∑ i weights’’ Ei i=1 ΔΠ E − E − E rΔt ΔE = t+Δt t t = − rΔt Π Et E ~ All investments financed = − Δ Ri Ri r t (at known IR) ΔΠ N ~ = θ Ri Π ∑ i i=1 ΔΠ N ~ ΔΠ N ~ ~ N ⎛ ⎞ ⎛ ⎞ 2 ⎛ ⎞ ⎛ ⎞ E = θ E Ri ; σ = θ θ Cov Ri , R j = θ θ σ σ ρ ⎜ Π ⎟ ∑ i ⎜ ⎟ ⎜ Π ⎟ ∑ i j ⎜ ⎟ ∑ i j i j ij ⎝ ⎠ i=1 ⎝ ⎠ ⎝ ⎠ ij=1 ⎝ ⎠ ij=1 Sharpe Ratio ⎛ ΔΠ ⎞ N ⎛ ~ ⎞ E θ E R ⎜ Π ⎟ ∑ i ⎜ i ⎟ s = s()θ ,...,θ = ⎝ ⎠ = i=1 ⎝ ⎠ 1 N ⎛ ΔΠ ⎞ N σ ⎜ ⎟ θ θ σ σ ρ Π ∑ i j i j ij ⎝ ⎠ i=1 Sharpe ratio is homogeneous of degree zero in the portfolio weights. -
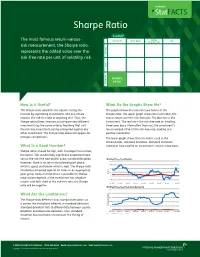
Sharpe Ratio
StatFACTS Sharpe Ratio StatMAP CAPITAL The most famous return-versus- voLATILITY BENCHMARK TAIL PRESERVATION risk measurement, the Sharpe ratio, RN TU E represents the added value over the R risk-free rate per unit of volatility risk. K S I R FF O - E SHARPE AD R RATIO T How Is it Useful? What Do the Graphs Show Me? The Sharpe ratio simplifies the options facing the The graphs below illustrate the two halves of the investor by separating investments into one of two Sharpe ratio. The upper graph shows the numerator, the choices, the risk-free rate or anything else. Thus, the excess return over the risk-free rate. The blue line is the Sharpe ratio allows investors to compare very different investment. The red line is the risk-free rate on a rolling, investments by the same criteria. Anything that isn’t three-year basis. More often than not, the investment’s the risk-free investment can be compared against any return exceeds that of the risk-free rate, leading to a other investment. The Sharpe ratio allows for apples-to- positive numerator. oranges comparisons. The lower graph shows the risk metric used in the denominator, standard deviation. Standard deviation What Is a Good Number? measures how volatile an investment’s returns have been. Sharpe ratios should be high, with the larger the number, the better. This would imply significant outperformance versus the risk-free rate and/or a low standard deviation. Rolling Three Year Return However, there is no set-in-stone breakpoint above, 40% 30% which is good, and below, which is bad. -

A Sharper Ratio: a General Measure for Correctly Ranking Non-Normal Investment Risks
A Sharper Ratio: A General Measure for Correctly Ranking Non-Normal Investment Risks † Kent Smetters ∗ Xingtan Zhang This Version: February 3, 2014 Abstract While the Sharpe ratio is still the dominant measure for ranking risky investments, much effort has been made over the past three decades to find more robust measures that accommodate non- Normal risks (e.g., “fat tails”). But these measures have failed to map to the actual investor problem except under strong restrictions; numerous ad-hoc measures have arisen to fill the void. We derive a generalized ranking measure that correctly ranks risks relative to the original investor problem for a broad utility-and-probability space. Like the Sharpe ratio, the generalized measure maintains wealth separation for the broad HARA utility class. The generalized measure can also correctly rank risks following different probability distributions, making it a foundation for multi-asset class optimization. This paper also explores the theoretical foundations of risk ranking, including proving a key impossibility theorem: any ranking measure that is valid for non-Normal distributions cannot generically be free from investor preferences. Finally, we show that approximation measures, which have sometimes been used in the past, fail to closely approximate the generalized ratio, even if those approximations are extended to an infinite number of higher moments. Keywords: Sharpe Ratio, portfolio ranking, infinitely divisible distributions, generalized rank- ing measure, Maclaurin expansions JEL Code: G11 ∗Kent Smetters: Professor, The Wharton School at The University of Pennsylvania, Faculty Research Associate at the NBER, and affiliated faculty member of the Penn Graduate Group in Applied Mathematics and Computational Science. -

In-Sample and Out-Of-Sample Sharpe Ratios of Multi-Factor Asset Pricing Models
In-sample and Out-of-sample Sharpe Ratios of Multi-factor Asset Pricing Models RAYMOND KAN, XIAOLU WANG, and XINGHUA ZHENG∗ This version: November 2020 ∗Kan is from the University of Toronto, Wang is from Iowa State University, and Zheng is from Hong Kong University of Science and Technology. We thank Svetlana Bryzgalova, Peter Christoffersen, Victor DeMiguel, Andrew Detzel, Junbo Wang, Guofu Zhou, seminar participants at Chinese University of Hong Kong, London Business School, Louisiana State University, Uni- versity of Toronto, and conference participants at 2019 CFIRM Conference for helpful comments. Corresponding author: Raymond Kan, Joseph L. Rotman School of Management, University of Toronto, 105 St. George Street, Toronto, Ontario, Canada M5S 3E6; Tel: (416) 978-4291; Fax: (416) 978-5433; Email: [email protected]. In-sample and Out-of-sample Sharpe Ratios of Multi-factor Asset Pricing Models Abstract For many multi-factor asset pricing models proposed in the recent literature, their implied tangency portfolios have substantially higher sample Sharpe ratios than that of the value- weighted market portfolio. In contrast, such high sample Sharpe ratio is rarely delivered by professional fund managers. This makes it difficult for us to justify using these asset pricing models for performance evaluation. In this paper, we explore if estimation risk can explain why the high sample Sharpe ratios of asset pricing models are difficult to realize in reality. In particular, we provide finite sample and asymptotic analyses of the joint distribution of in-sample and out-of-sample Sharpe ratios of a multi-factor asset pricing model. For an investor who does not know the mean and covariance matrix of the factors in a model, the out-of-sample Sharpe ratio of an asset pricing model is substantially worse than its in-sample Sharpe ratio. -

Picking the Right Risk-Adjusted Performance Metric
WORKING PAPER: Picking the Right Risk-Adjusted Performance Metric HIGH LEVEL ANALYSIS QUANTIK.org Investors often rely on Risk-adjusted performance measures such as the Sharpe ratio to choose appropriate investments and understand past performances. The purpose of this paper is getting through a selection of indicators (i.e. Calmar ratio, Sortino ratio, Omega ratio, etc.) while stressing out the main weaknesses and strengths of those measures. 1. Introduction ............................................................................................................................................. 1 2. The Volatility-Based Metrics ..................................................................................................................... 2 2.1. Absolute-Risk Adjusted Metrics .................................................................................................................. 2 2.1.1. The Sharpe Ratio ............................................................................................................................................................. 2 2.1. Relative-Risk Adjusted Metrics ................................................................................................................... 2 2.1.1. The Modigliani-Modigliani Measure (“M2”) ........................................................................................................ 2 2.1.2. The Treynor Ratio ......................................................................................................................................................... -

Investment Performance Performance Versus Benchmark: Return and Sharpe Ratio
Release date 07-31-2018 Page 1 of 20 Investment Performance Performance versus Benchmark: Return and Sharpe Ratio 5-Yr Summary Statistics as of 07-31-2018 Name Total Rtn Sharpe Ratio TearLab Corp(TEAR) -75.30 -2.80 AmerisourceBergen Corp(ABC) 8.62 -2.80 S&P 500 TR USD 13.12 1.27 Definitions Return Sharpe Ratio The gain or loss of a security in a particular period. The return consists of the The Sharpe Ratio is calculated using standard deviation and excess return to income and the capital gains relative to an investment. It is usually quoted as a determine reward per unit of risk. The higher the SharpeRatio, the better the percentage. portfolio’s historical risk-adjusted performance. Performance Disclosure The performance data quoted represents past performances and does not guarantee future results. The investment return and principal value of an investment will fluctuate; thus an investor's shares, when sold or redeemed, may be worth more or less than their original cost. Current performance may be lower or higher than return data quoted herein. Please see the Disclosure Statements for Standardized Performance. ©2018 Morningstar. All Rights Reserved. Unless otherwise provided in a separate agreement, you may use this report only in the country in which its original distributor is based. The information, data, analyses and ® opinions contained herein (1) include the confidential and proprietary information of Morningstar, (2) may include, or be derived from, account information provided by your financial advisor which cannot be verified by Morningstar, (3) may not be copied or redistributed, (4) do not constitute investment advice offered by Morningstar, (5) are provided solely for informational purposes and therefore are not an offer to buy or sell a security, ß and (6) are not warranted to be correct, complete or accurate. -

Chapter 4 Sharpe Ratio, CAPM, Jensen's Alpha, Treynor Measure
Excerpt from Prof. C. Droussiotis Text Book: An Analytical Approach to Investments, Finance and Credit Chapter 4 Sharpe Ratio, CAPM, Jensen’s Alpha, Treynor Measure & M Squared This chapter will continue to emphasize the risk and return relationship. In the previous chapters, the risk and return characteristics of a given portfolio were measured at first versus other asset classes and then second, measured to market benchmarks. This chapter will re-emphasize these comparisons by introducing other ways to compare via performance measurements ratios such the Share Ratio, Jensen’s Alpha, M Squared, Treynor Measure and other ratios that are used extensively on wall street. Learning Objectives After reading this chapter, students will be able to: Calculate various methods for evaluating investment performance Determine which performance ratios measure is appropriate in a variety of investment situations Apply various analytical tools to set up portfolio strategy and measure expectation. Understand to differentiate the between the dependent and independent variables in a linear regression to set return expectation Determine how to allocate various assets classes within the portfolio to achieve portfolio optimization. [Insert boxed text here AUTHOR’S NOTES: In the spring of 2006, just 2 years before the worse financial crisis the U.S. has ever faced since the 1930’s, I visited few European countries to promote a new investment opportunity for these managers who only invested in stocks, bonds and real estate. The new investment opportunity, already established in the U.S., was to invest equity in various U.S. Collateral Loan Obligations (CLO). The most difficult task for me is to convince these managers to accept an average 10-12% return when their portfolio consists of stocks, bonds and real estate holdings enjoyed returns in excess of 30% per year for the last 3-4 years. -

Fixed-Income Insights
Fixed-Income Insights Reassessing Risk—and Opportunity—in Short-Duration Fixed Income Investors seeking attractive income in a yield-starved world—with lower risk—may wish to take a fresh look at short-maturity credit. December 27, 2016 by Timothy Paulson, Investment Strategist, Fixed Income IN BRIEF n The low investment yields available over the past few years have created difficult tradeoffs for investors. But are there opportunities in established asset categories that might improve a portfolio’s return profile without increasing overall risk? n One option to consider is short-maturity credit, which historically has featured attractive yields and low price volatility. n In this report, we will examine in detail five key attributes of short credit, and their influence on factors such as price volatility, return, credit ratings, and credit risk, across key short-maturity categories such as corporate debt, asset backed securities, and commercial mortgage-backed securities. n The key takeaway: At a time when many investors are struggling to be adequately compensated for risks, short term credit may provide some real solutions. Investors have been for some time now grappling This paper will focus on five key attributes of with historically low expected returns across all asset short-maturity paper and their implications for classes. As central bank actions have left the global investors: financial system awash in liquidity, yield-starved inves- tors have squeezed value out of many traditional asset classes. While price appreciation of many assets has 1) The “pull to par” mitigates price volatility for short-term bonds. helped in recent years, investors have been left with a difficult trade-off: accepting lower returns or changing 2) Credit spreads over-compensate investors for their traditional asset mix. -

Seeing Beyond the Complexity: an Introduction to Collateralized Loan Obligations
September 2019 Seeing Beyond the Complexity: An Introduction to Collateralized Loan Obligations Collateralized loan obligations are robust, opportunity-rich debt instruments that offer the potential for above- average returns versus other fixed income strategies. Here, we explore how these instruments work, as well as the benefits and risks investors should consider when allocating to this asset class. Collateralized loan obligations (CLOs) are robust, opportunity-rich debt instruments Authors: that have been around for about 30 years. And while they’re well established, they’re also complex enough that even sophisticated investors may hesitate to dig into the Steven Oh, CFA details – and end up avoiding them instead. Global Head of Credit CLOs have been gaining wider prominence in markets in recent years, and it’s no and Fixed Income surprise why. They offer a compelling combination of above-average yield and potential appreciation. But for many investors, the basics of how they work, the benefits they can provide, and the risks they pose are wrapped in complication. And they’re also often Laila Kollmorgen, CFA misconstrued by the financial media and some market participants. CLO Tranche Portfolio In spite of this, we believe CLOs are attractive investments and well worth the time and Manager effort required to understand them. What is a CLO? Put simply, a CLO is a portfolio of leveraged loans that is securitized and managed as a fund. Each CLO is structured as a series of tranches that are interest-paying bonds, along with a small portion of equity. CLOs originated in the late 1980s, similar to other types of securitizations, as a way for banks to package leveraged loans together to provide investors with an investment vehicle with varied degrees of risk and return to best suit their investment objectives. -

Securitization & Hedge Funds: Creating a More Efficient
SECURITIZATION & HEDGE FUNDS: COLLATERALIZED FUND OBLIGATIONS SECURITIZATION & HEDGE FUNDS: CREATING A MORE EFFICIENT MARKET BY CLARK CHENG, CFA Intangis Funds AUGUST 6, 2002 INTANGIS PAGE 1 SECURITIZATION & HEDGE FUNDS: COLLATERALIZED FUND OBLIGATIONS TABLE OF CONTENTS INTRODUCTION........................................................................................................................................ 3 PROBLEM.................................................................................................................................................... 4 SOLUTION................................................................................................................................................... 5 SECURITIZATION..................................................................................................................................... 5 CASH-FLOW TRANSACTIONS............................................................................................................... 6 MARKET VALUE TRANSACTIONS.......................................................................................................8 ARBITRAGE................................................................................................................................................ 8 FINANCIAL ENGINEERING.................................................................................................................... 8 TRANSPARENCY......................................................................................................................................