A Data-Intensive Computing Reading Group
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SIGOPS Annual Report 2012
SIGOPS Annual Report 2012 Fiscal Year July 2012-June 2013 Submitted by Jeanna Matthews, SIGOPS Chair Overview SIGOPS is a vibrant community of people with interests in “operatinG systems” in the broadest sense, includinG topics such as distributed computing, storaGe systems, security, concurrency, middleware, mobility, virtualization, networkinG, cloud computinG, datacenter software, and Internet services. We sponsor a number of top conferences, provide travel Grants to students, present yearly awards, disseminate information to members electronically, and collaborate with other SIGs on important programs for computing professionals. Officers It was the second year for officers: Jeanna Matthews (Clarkson University) as Chair, GeorGe Candea (EPFL) as Vice Chair, Dilma da Silva (Qualcomm) as Treasurer and Muli Ben-Yehuda (Technion) as Information Director. As has been typical, elected officers agreed to continue for a second and final two- year term beginning July 2013. Shan Lu (University of Wisconsin) will replace Muli Ben-Yehuda as Information Director as of AuGust 2013. Awards We have an excitinG new award to announce – the SIGOPS Dennis M. Ritchie Doctoral Dissertation Award. SIGOPS has lonG been lackinG a doctoral dissertation award, such as those offered by SIGCOMM, Eurosys, SIGPLAN, and SIGMOD. This new award fills this Gap and also honors the contributions to computer science that Dennis Ritchie made durinG his life. With this award, ACM SIGOPS will encouraGe the creativity that Ritchie embodied and provide a reminder of Ritchie's leGacy and what a difference a person can make in the field of software systems research. The award is funded by AT&T Research and Alcatel-Lucent Bell Labs, companies that both have a strong connection to AT&T Bell Laboratories where Dennis Ritchie did his seminal work. -

Shanlu › About › Cv › CV Shanlu.Pdf Shan Lu
Shan Lu University of Chicago, Dept. of Computer Science Phone: +1-773-702-3184 5730 S. Ellis Ave., Rm 343 E-mail: [email protected] Chicago, IL 60637 USA Homepage: http://people.cs.uchicago.edu/~shanlu RESEARCH INTERESTS Tool support for improving the correctness and efficiency of large scale software systems EMPLOYMENT 2019 – present Professor, Dept. of Computer Science, University of Chicago 2014 – 2019 Associate Professor, Dept. of Computer Sciences, University of Chicago 2009 – 2014 Assistant Professor, Dept. of Computer Sciences, University of Wisconsin – Madison EDUCATION 2008 University of Illinois at Urbana-Champaign, Urbana, IL Ph.D. in Computer Science Thesis: Understanding, Detecting, and Exposing Concurrency Bugs (Advisor: Prof. Yuanyuan Zhou) 2003 University of Science & Technology of China, Hefei, China B.S. in Computer Science HONORS AND AWARDS 2019 ACM Distinguished Member Among 62 members world-wide recognized for outstanding contributions to the computing field 2015 Google Faculty Research Award 2014 Alfred P. Sloan Research Fellow Among 126 “early-career scholars (who) represent the most promising scientific researchers working today” 2013 Distinguished Alumni Educator Award Among 3 awardees selected by Department of Computer Science, University of Illinois 2010 NSF Career Award 2021 Honorable Mention Award @ CHI for paper [C71] (CHI 2021) 2019 Best Paper Award @ SOSP for paper [C62] (SOSP 2019) 2019 ACM SIGSOFT Distinguished Paper Award @ ICSE for paper [C58] (ICSE 2019) 2017 Google Scholar Classic Paper Award for -

Pivot Tracing: Dynamic Causal Monitoring for Distributed Systems Pdfauthor=Jonathan Mace, Ryan Roelke, Rodrigo Fonseca
PivoT Tracing:Dynamic Causal MoniToring for DisTribuTed SysTems JonaThan Mace Ryan Roelke Rodrigo Fonseca Brown UniversiTy AbsTracT MoniToring and TroubleshooTing disTribuTed sysTems is noToriously diõcult; poTenTial prob- lems are complex, varied, and unpredicTable. _e moniToring and diagnosis Tools commonly used Today – logs, counTers, and meTrics – have Two imporTanT limiTaTions: whaT gets recorded is deûned a priori, and The informaTion is recorded in a componenT- or machine-cenTric way, making iT exTremely hard To correlaTe events ThaT cross These boundaries. _is paper presents PivoT Tracing, a moniToring framework for disTribuTed sysTems ThaT addresses boTh limiTaTions by combining dynamic insTrumenTaTion wiTh a novel relaTional operaTor: The happened-before join. PivoT Tracing gives users, aT runTime, The abiliTy To deûne arbiTrary meTrics aT one poinT of The sysTem, while being able To selecT, ûlTer, and group by events mean- ingful aT oTher parts of The sysTem, even when crossing componenT or machine boundaries. We have implemenTed a proToType of PivoT Tracing for Java-based sysTems and evaluaTe iT on a heTerogeneous Hadoop clusTer comprising HDFS, HBase, MapReduce, and YARN. We show ThaT PivoT Tracing can eòecTively idenTify a diverse range of rooT causes such as soware bugs, misconûguraTion, and limping hardware. We show ThaT PivoT Tracing is dynamic, exTensible, and enables cross-Tier analysis beTween inTer-operaTing applicaTions, wiTh low execuTion overhead. Ë. InTroducTion MoniToring and TroubleshooTing disTribuTed sysTems -
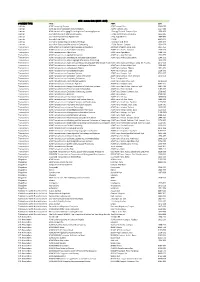
A ACM Transactions on Trans. 1553 TITLE ABBR ISSN ACM Computing Surveys ACM Comput. Surv. 0360‐0300 ACM Journal
ACM - zoznam titulov (2016 - 2019) CONTENT TYPE TITLE ABBR ISSN Journals ACM Computing Surveys ACM Comput. Surv. 0360‐0300 Journals ACM Journal of Computer Documentation ACM J. Comput. Doc. 1527‐6805 Journals ACM Journal on Emerging Technologies in Computing Systems J. Emerg. Technol. Comput. Syst. 1550‐4832 Journals Journal of Data and Information Quality J. Data and Information Quality 1936‐1955 Journals Journal of Experimental Algorithmics J. Exp. Algorithmics 1084‐6654 Journals Journal of the ACM J. ACM 0004‐5411 Journals Journal on Computing and Cultural Heritage J. Comput. Cult. Herit. 1556‐4673 Journals Journal on Educational Resources in Computing J. Educ. Resour. Comput. 1531‐4278 Transactions ACM Letters on Programming Languages and Systems ACM Lett. Program. Lang. Syst. 1057‐4514 Transactions ACM Transactions on Accessible Computing ACM Trans. Access. Comput. 1936‐7228 Transactions ACM Transactions on Algorithms ACM Trans. Algorithms 1549‐6325 Transactions ACM Transactions on Applied Perception ACM Trans. Appl. Percept. 1544‐3558 Transactions ACM Transactions on Architecture and Code Optimization ACM Trans. Archit. Code Optim. 1544‐3566 Transactions ACM Transactions on Asian Language Information Processing 1530‐0226 Transactions ACM Transactions on Asian and Low‐Resource Language Information Proce ACM Trans. Asian Low‐Resour. Lang. Inf. Process. 2375‐4699 Transactions ACM Transactions on Autonomous and Adaptive Systems ACM Trans. Auton. Adapt. Syst. 1556‐4665 Transactions ACM Transactions on Computation Theory ACM Trans. Comput. Theory 1942‐3454 Transactions ACM Transactions on Computational Logic ACM Trans. Comput. Logic 1529‐3785 Transactions ACM Transactions on Computer Systems ACM Trans. Comput. Syst. 0734‐2071 Transactions ACM Transactions on Computer‐Human Interaction ACM Trans. -

An Oral History of Computer Science Cornell University
An Oral History of Computer Science at Cornell University https://ecommons.cornell.edu/handle/1813/40569 Gates Hall, Cornell University Twelve senior faculty members share their personal journeys and their recollections of the early days of computer science at Cornell University and the leadership role in bringing a new field of study into existence. Birman, Ken Hopcroft, John E Cardie, Claire Kozen, Dexter Constable, Robert Nerode, Anil Conway, Richard W. Schneider, Fred B Gries, David Teitelbaum, Tim Hartmanis, Juris Van Loan, Charlie (Click on a name above to scroll to an abstract and a live link to the associated streaming video.) version: 16Jun16 1. KEN BIRMAN Ken Birman, who joined CS in 1981, exemplifies the successful synergy of research and entrepreneurial activities. His research in distributed systems led to his founding ISIS Distributed Systems, Inc., in 1988, which developed software used by the New York Stock Exchange (NYSE) and Swiss Exchange, the French Air Traffic Control sys- tem, the AEGIS warship, and others. He started two other companies, Reliable Network Solutions and Web Sci- ences LLC. This entrepreneurship has in turn generated new research ideas and has also led to Ken’s advising various organi- zations on distributed systems and cloud computing, including the French Civil Aviation Organization, the north- eastern electric power grid, NATO, the US Treasury, and the US Air Force. Ken has received several awards for his research, among them the IEEE Tsutomu Kanai Award for his work on trustworthy computing, the Cisco “Technology Visionary” award, and the ACM SIGOPS Hall of Fame Award. He also has written two successful texts. -
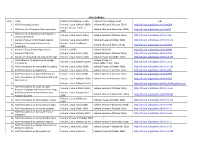
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1 (March 1969) Volume 49 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J204 Volume 24 Issue 1 (Feb. 1, 2. ACM Journal of Computer Documentation Volume 26 Issue 4 (November 2002) http://dl.acm.org/citation.cfm?id=J24 2000) ACM Journal on Emerging Technologies in 3. Volume 1 Issue 1 (April 2005) Volume 13 Issue 2 (October 2016) http://dl.acm.org/citation.cfm?id=J967 Computing Systems 4. Journal of Data and Information Quality Volume 1 Issue 1 (June 2009) Volume 8 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1191 Journal on Educational Resources in Volume 1 Issue 1es (March 5. Volume 16 Issue 2 (March 2016) http://dl.acm.org/citation.cfm?id=J814 Computing 2001) 6. Journal of Experimental Algorithmics Volume 1 (1996) Volume 21 (2016) http://dl.acm.org/citation.cfm?id=J430 7. Journal of the ACM Volume 1 Issue 1 (Jan. 1954) Volume 63 Issue 4 (October 2016) http://dl.acm.org/citation.cfm?id=J401 8. Journal on Computing and Cultural Heritage Volume 1 Issue 1 (June 2008) Volume 9 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J1157 ACM Letters on Programming Languages Volume 2 Issue 1-4 9. Volume 1 Issue 1 (March 1992) http://dl.acm.org/citation.cfm?id=J513 and Systems (March–Dec. 1993) 10. ACM Transactions on Accessible Computing Volume 1 Issue 1 (May 2008) Volume 9 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1156 11. -

Semperos: a Distributed Capability System
SemperOS: A Distributed Capability System Matthias Hille† Nils Asmussen† ∗ Pramod Bhatotia‡ Hermann Härtig† ∗ †Technische Universität Dresden ‡The University of Edinburgh ∗ Barkhausen Institut Abstract systems have received renewed attention recently to provide Capabilities provide an efficient and secure mechanism for an efficient and secure mechanism for resource management fine-grained resource management and protection. However, in modern hardware architectures [5, 24, 30, 36, 44, 64, 67]. as the modern hardware architectures continue to evolve Today the main improvements in compute capacity with large numbers of non-coherent and heterogeneous cores, are achieved by either adding more cores or integrating we focus on the following research question: can capability accelerators into the system. However, the increasing core systems scale to modern hardware architectures? counts exacerbate the hardware complexity required for global In this work, we present a scalable capability system to drive cache coherence. While on-chip cache coherence is likely to future systems with many non-coherent heterogeneous cores. remain a feature of future hardware architectures [45], we see More specifically, we have designed a distributed capability characteristics of distributed systems added to the hardware system based on a HW/SW co-designed capability system. by giving up on global cache coherence across a whole We analyzed the pitfalls of distributed capability operations machine [6, 28]. Additionally, various kinds of accelerators running concurrently and built the protocols in accordance are added like the Xeon Phi Processor, the Matrix-2000 accel- with the insights. We have incorporated these distributed erator, GPUs, FPGAs, or ASICs, which are used in numerous capability management protocols in a new microkernel-based application fields [4,21,32,34,43,60]. -

Robust Computer Algebra, Theorem Proving, and Oracle AI
Robust Computer Algebra, Theorem Proving, and Oracle AI Gopal P. Sarma∗ Nick J. Hayyz School of Medicine, Emory University, Atlanta, GA USA Vicarious FPC, San Francisco, CA USA Abstract In the context of superintelligent AI systems, the term “oracle” has two meanings. One refers to modular systems queried for domain-specific tasks. Another usage, referring to a class of systems which may be useful for addressing the value alignment and AI control problems, is a superintelligent AI system that only answers questions. The aim of this manuscript is to survey contemporary research problems related to oracles which align with long-term research goals of AI safety. We examine existing question answering systems and argue that their high degree of architectural heterogeneity makes them poor candidates for rigorous analysis as oracles. On the other hand, we identify computer algebra systems (CASs) as being primitive examples of domain-specific oracles for mathematics and argue that efforts to integrate computer algebra systems with theorem provers, systems which have largely been developed independent of one another, provide a concrete set of problems related to the notion of provable safety that has emerged in the AI safety community. We review approaches to interfacing CASs with theorem provers, describe well-defined architectural deficiencies that have been identified with CASs, and suggest possible lines of research and practical software projects for scientists interested in AI safety. I. Introduction other hand, issues of privacy and surveillance, access and inequality, or economics and policy are Recently, significant public attention has been also of utmost importance and are distinct from drawn to the consequences of achieving human- the specific technical challenges posed by most level artificial intelligence. -

List of Related Organizations and Conferences
List of Related Organizations and Conferences Organization/Event Name Sponsor Description # of days With approx. 80,000 members, ACM delivers resources that advance computing as a science and a profession. ACM provides the computing field's premier Digital ACM Library and serves its members and the computing profession with leading-edge publications, conferences, and career resources. With nearly 85,000 members, the IEEE Computer Society is the world’s leading organization of computing professionals. Founded in 1946, and the largest of the IEEE Computer Society 39 societies of the Institute of Electrical and Electronics Engineers (IEEE), the CS is dedicated to advancing the theory and application of computer and information- processing technology. ASPLOS is a multi-disciplinary conference for research that spans the boundaries of hardware, computer architecture, compilers, languages, operating systems, networking, and applications. ASPLOS provides a high quality forum for scientists and engineers to present their latest research findings in these rapidly changing ASPLOS XIII ACM SIGARCH, SIGPLAN, SIGOPS 3 days fields. It has captured some of the major computer systems innovations of the past two decades (e.g., RISC and VLIW processors, small and large-scale multiprocessors, clusters and networks-of-workstations, optimizing compilers, RAID, and network-storage system designs). BSDCan, a BSD conference held in Ottawa, Canada, has quickly established itself as the technical conference for people working on and with 4.4BSD based operating BSDCanada 4 days systems and related projects. The organizers have found a fantastic formula that appeals to a wide range of people from extreme novices to advanced The Federated Computer Research Conference (FCRC) assembles a spectrum of affiliated research conferences and workshops into a week long coordinated meeting 7 day mix of held at a common time in a common place. -

Title Publisher 3C ON-LINE ACM / Association for Computing Machinery 3DOR
Title Publisher 3C ON-LINE ACM / Association for Computing Machinery 3DOR: 3D Object Retrieval ACM / Association for Computing Machinery 3DVP: 3D Video Processing ACM / Association for Computing Machinery A2CWiC: Conference of Women in Computing in India ACM / Association for Computing Machinery AAA-IDEA : Advanced Architectures and Algorithms for Internet Delivery and ApplicationsACM / Association for Computing Machinery AADEBUG: Automated analysis-driven debugging ACM / Association for Computing Machinery AAMAS: Autonomous Agents and Multiagent Systems ACM / Association for Computing Machinery ACDC: Automated Control for Datacenters and Clouds ACM / Association for Computing Machinery AcessNets: Access Networks ACM / Association for Computing Machinery ACET: Advances in Computer Enterntainment Technology ACM / Association for Computing Machinery ACISNR: Applications of Computer and Information Sciences to Nature Research ACM / Association for Computing Machinery ACL2: ACL2 Theorem Prover and its Applications ACM / Association for Computing Machinery ACM Communications in Computer Algebra ACM / Association for Computing Machinery ACM Computing Surveys ACM / Association for Computing Machinery ACM DEV: Computing for Development ACM / Association for Computing Machinery ACM Inroads ACM / Association for Computing Machinery ACM Journal of Computer Documentation ACM / Association for Computing Machinery ACM Journal of Data and Information Quality (JDIQ) ACM / Association for Computing Machinery ACM journal on emerging technologies in computing -

Group Orientation: a Paradigm for Modern Distributed Systems Introduction
Group Orientation: a Paradigm for Mo dern Distributed Systems Paulo Verssimo Lus Ro drigues Werner Vogels [email protected] [email protected] [email protected] Tech. Univ. of Lisb oa Tech. Univ. of Lisb oa IST - INESC IST - INESC INESC Abstract of consistency, user-friendliness, p erformance and de- p endability. When lo oking at the several classes of distributed Increasing use of distributed systems, with the cor- activities that may take place in a distributed system, responding decentralisation, stimulates the need for the group concept app ears intuitively: when a group structuring activities around groups of participants, of participants co op erate in an activity (e.g. manage- for reasons of consistency, user-friend liness, perfor- ment of a fragmented database, distributed do cument mance and dependability. Although there is a signi - pro cessing or distributed pro cess control), comp ete in cant number of group communication protocolsinthe an activity (e.g. to share a given resource), or execute literature, they arepenetrating too slow ly in operating a replicated activity for p erformance or fault-tolerance systems technology. Two important reasons are: the reasons (e.g. replicated database server, replicated ac- literal interpretation general ly made of the end-to-end tuator). argument, and the lack of a layer mapping end-user needs (management of replication, competition, coop- Group-orientation, as a general rule, do es not imply eration and group membership) into what is general ly group-oriented programming for the end user. That providedbythecommunication layer: agreement and is, group to ols can help the programmer build appli- order properties. -

Appendix C SURPLUS/LOSS: $291.34 SIGCSE 0.00 Sigada 100.00 SIGAPP 0.00 SIGPLAN 0.00
Starts Ends Conference Actual SIGs and their % SIGACCESS 21-Oct-13 23-Oct-13 ASSETS '13: The 15th International ACM SIGACCESS ATTENDANCE: 155 SIGACCESS 100.00 Conference on Computers and Accessibility INCOME: $74,697.30 EXPENSE: $64,981.11 SURPLUS/LOSS: $9,716.19 SIGACT 12-Jan-14 14-Jan-14 ITCS'14 : Innovations in Theoretical Computer Science ATTENDANCE: 76 SIGACT 100.00 INCOME: $19,210.00 EXPENSE: $21,744.07 SURPLUS/LOSS: ($2,534.07) 22-Jul-13 24-Jul-13 PODC '13: ACM Symposium on Principles ATTENDANCE: 98 SIGOPS 50.00 of Distributed Computing INCOME: $62,310.50 SIGACT 50.00 EXPENSE: $56,139.24 SURPLUS/LOSS: $6,171.26 23-Jul-13 25-Jul-13 SPAA '13: 25th ACM Symposium on Parallelism in ATTENDANCE: 45 SIGACT 50.00 Algorithms and Architectures INCOME: $45,665.50 SIGARCH 50.00 EXPENSE: $39,586.18 SURPLUS/LOSS: $6,079.32 23-Jun-14 25-Jun-14 SPAA '14: 26th ACM Symposium on Parallelism in ATTENDANCE: 73 SIGARCH 50.00 Algorithms and Architectures INCOME: $36,107.35 SIGACT 50.00 EXPENSE: $22,536.04 SURPLUS/LOSS: $13,571.31 31-May-14 3-Jun-14 STOC '14: Symposium on Theory of Computing ATTENDANCE: SIGACT 100.00 INCOME: $0.00 EXPENSE: $0.00 SURPLUS/LOSS: $0.00 SIGAda 10-Nov-13 14-Nov-13 HILT 2013:High Integrity Language Technology ATTENDANCE: 60 SIGBED 0.00 ACM SIGAda Annual INCOME: $32,696.00 SIGCAS 0.00 EXPENSE: $32,404.66 SIGSOFT 0.00 Appendix C SURPLUS/LOSS: $291.34 SIGCSE 0.00 SIGAda 100.00 SIGAPP 0.00 SIGPLAN 0.00 SIGAI 11-Nov-13 15-Nov-13 ASE '13: ACM/IEEE International Conference on ATTENDANCE: 195 SIGAI 25.00 Automated Software Engineering