DR DRAM: Accelerating Memory-Read-Intensive Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ASIC Implementation of DDR SDRAM Memory Controller
© 2016 IJEDR | Volume 4, Issue 4 | ISSN: 2321-9939 ASIC Implementation of DDR SDRAM Memory Controller Ramagiri Ramya, Naganaik M.Tech Scholar, ASST.PROF, HOD of ECE BRIG-IC, Hyderabad ________________________________________________________________________________________________________ Abstract - A Dedicated Memory Controller is of prime importance in applications that do not contain microprocessors (high-end applications). The Memory Controller provides command signals for memory refresh, read and write operation and initialization of SDRAM. Our work will focus on ASIC Design methodology of Double Data Rate (DDR) SDRAM Controller that is located between the DDR SDRAM and Bus Master. The Controller simplifies the SDRAM command interface to standard system read/write interface and also optimizes the access time of read/write cycle. Keywords - DDR SDRAM Controller, Read/Write Data path, Cadence RTL Compiler. ________________________________________________________________________________________________________ I. INTRODUCTION Memory devices are almost found in all systems and nowadays high speed and high performance memories are in great demand. For better throughput and speed, the controllers are to be designed with clock frequency in the range of megahertz. As the clock speed of the controller is increasing, the design challenges are also becoming complex. Therefore the next generation memory devices require very high speed controllers like double data rate and quad data rate memory controllers. In this paper, the double data rate SDRAM Controller is implemented using ASIC methodology. Synchronous DRAM (SDRAM) is preferred in embedded system memory design because of its speed and pipelining capability. In high-end applications, like microprocessors there will be specific built in peripherals to provide the interface to the SDRAM. But for other applications, the system designer must design a specific memory controller to provide command signals for memory refresh, read and write operation and initialization of SDRAM. -
2GB DDR3 SDRAM 72Bit SO-DIMM
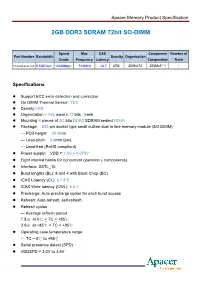
Apacer Memory Product Specification 2GB DDR3 SDRAM 72bit SO-DIMM Speed Max CAS Component Number of Part Number Bandwidth Density Organization Grade Frequency Latency Composition Rank 0C 78.A2GCB.AF10C 8.5GB/sec 1066Mbps 533MHz CL7 2GB 256Mx72 256Mx8 * 9 1 Specifications z Support ECC error detection and correction z On DIMM Thermal Sensor: YES z Density:2GB z Organization – 256 word x 72 bits, 1rank z Mounting 9 pieces of 2G bits DDR3 SDRAM sealed FBGA z Package: 204-pin socket type small outline dual in line memory module (SO-DIMM) --- PCB height: 30.0mm --- Lead pitch: 0.6mm (pin) --- Lead-free (RoHS compliant) z Power supply: VDD = 1.5V + 0.075V z Eight internal banks for concurrent operation ( components) z Interface: SSTL_15 z Burst lengths (BL): 8 and 4 with Burst Chop (BC) z /CAS Latency (CL): 6,7,8,9 z /CAS Write latency (CWL): 5,6,7 z Precharge: Auto precharge option for each burst access z Refresh: Auto-refresh, self-refresh z Refresh cycles --- Average refresh period 7.8㎲ at 0℃ < TC < +85℃ 3.9㎲ at +85℃ < TC < +95℃ z Operating case temperature range --- TC = 0℃ to +95℃ z Serial presence detect (SPD) z VDDSPD = 3.0V to 3.6V Apacer Memory Product Specification Features z Double-data-rate architecture; two data transfers per clock cycle. z The high-speed data transfer is realized by the 8 bits prefetch pipelined architecture. z Bi-directional differential data strobe (DQS and /DQS) is transmitted/received with data for capturing data at the receiver. z DQS is edge-aligned with data for READs; center aligned with data for WRITEs. -

Different Types of RAM RAM RAM Stands for Random Access Memory. It Is Place Where Computer Stores Its Operating System. Applicat
Different types of RAM RAM RAM stands for Random Access Memory. It is place where computer stores its Operating System. Application Program and current data. when you refer to computer memory they mostly it mean RAM. The two main forms of modern RAM are Static RAM (SRAM) and Dynamic RAM (DRAM). DRAM memories (Dynamic Random Access Module), which are inexpensive . They are used essentially for the computer's main memory SRAM memories(Static Random Access Module), which are fast and costly. SRAM memories are used in particular for the processer's cache memory. Early memories existed in the form of chips called DIP (Dual Inline Package). Nowaday's memories generally exist in the form of modules, which are cards that can be plugged into connectors for this purpose. They are generally three types of RAM module they are 1. DIP 2. SIMM 3. DIMM 4. SDRAM 1. DIP(Dual In Line Package) Older computer systems used DIP memory directely, either soldering it to the motherboard or placing it in sockets that had been soldered to the motherboard. Most memory chips are packaged into small plastic or ceramic packages called dual inline packages or DIPs . A DIP is a rectangular package with rows of pins running along its two longer edges. These are the small black boxes you see on SIMMs, DIMMs or other larger packaging styles. However , this arrangment caused many problems. Chips inserted into sockets suffered reliability problems as the chips would (over time) tend to work their way out of the sockets. 2. SIMM A SIMM, or single in-line memory module, is a type of memory module containing random access memory used in computers from the early 1980s to the late 1990s . -

Product Guide SAMSUNG ELECTRONICS RESERVES the RIGHT to CHANGE PRODUCTS, INFORMATION and SPECIFICATIONS WITHOUT NOTICE
May. 2018 DDR4 SDRAM Memory Product Guide SAMSUNG ELECTRONICS RESERVES THE RIGHT TO CHANGE PRODUCTS, INFORMATION AND SPECIFICATIONS WITHOUT NOTICE. Products and specifications discussed herein are for reference purposes only. All information discussed herein is provided on an "AS IS" basis, without warranties of any kind. This document and all information discussed herein remain the sole and exclusive property of Samsung Electronics. No license of any patent, copyright, mask work, trademark or any other intellectual property right is granted by one party to the other party under this document, by implication, estoppel or other- wise. Samsung products are not intended for use in life support, critical care, medical, safety equipment, or similar applications where product failure could result in loss of life or personal or physical harm, or any military or defense application, or any governmental procurement to which special terms or provisions may apply. For updates or additional information about Samsung products, contact your nearest Samsung office. All brand names, trademarks and registered trademarks belong to their respective owners. © 2018 Samsung Electronics Co., Ltd. All rights reserved. - 1 - May. 2018 Product Guide DDR4 SDRAM Memory 1. DDR4 SDRAM MEMORY ORDERING INFORMATION 1 2 3 4 5 6 7 8 9 10 11 K 4 A X X X X X X X - X X X X SAMSUNG Memory Speed DRAM Temp & Power DRAM Type Package Type Density Revision Bit Organization Interface (VDD, VDDQ) # of Internal Banks 1. SAMSUNG Memory : K 8. Revision M: 1st Gen. A: 2nd Gen. 2. DRAM : 4 B: 3rd Gen. C: 4th Gen. D: 5th Gen. -

Dual-DIMM DDR2 and DDR3 SDRAM Board Design Guidelines, External
5. Dual-DIMM DDR2 and DDR3 SDRAM Board Design Guidelines June 2012 EMI_DG_005-4.1 EMI_DG_005-4.1 This chapter describes guidelines for implementing dual unbuffered DIMM (UDIMM) DDR2 and DDR3 SDRAM interfaces. This chapter discusses the impact on signal integrity of the data signal with the following conditions in a dual-DIMM configuration: ■ Populating just one slot versus populating both slots ■ Populating slot 1 versus slot 2 when only one DIMM is used ■ On-die termination (ODT) setting of 75 Ω versus an ODT setting of 150 Ω f For detailed information about a single-DIMM DDR2 SDRAM interface, refer to the DDR2 and DDR3 SDRAM Board Design Guidelines chapter. DDR2 SDRAM This section describes guidelines for implementing a dual slot unbuffered DDR2 SDRAM interface, operating at up to 400-MHz and 800-Mbps data rates. Figure 5–1 shows a typical DQS, DQ, and DM signal topology for a dual-DIMM interface configuration using the ODT feature of the DDR2 SDRAM components. Figure 5–1. Dual-DIMM DDR2 SDRAM Interface Configuration (1) VTT Ω RT = 54 DDR2 SDRAM DIMMs (Receiver) Board Trace FPGA Slot 1 Slot 2 (Driver) Board Trace Board Trace Note to Figure 5–1: (1) The parallel termination resistor RT = 54 Ω to VTT at the FPGA end of the line is optional for devices that support dynamic on-chip termination (OCT). © 2012 Altera Corporation. All rights reserved. ALTERA, ARRIA, CYCLONE, HARDCOPY, MAX, MEGACORE, NIOS, QUARTUS and STRATIX words and logos are trademarks of Altera Corporation and registered in the U.S. Patent and Trademark Office and in other countries. -

A Modern Primer on Processing in Memory
A Modern Primer on Processing in Memory Onur Mutlua,b, Saugata Ghoseb,c, Juan Gomez-Luna´ a, Rachata Ausavarungnirund SAFARI Research Group aETH Z¨urich bCarnegie Mellon University cUniversity of Illinois at Urbana-Champaign dKing Mongkut’s University of Technology North Bangkok Abstract Modern computing systems are overwhelmingly designed to move data to computation. This design choice goes directly against at least three key trends in computing that cause performance, scalability and energy bottlenecks: (1) data access is a key bottleneck as many important applications are increasingly data-intensive, and memory bandwidth and energy do not scale well, (2) energy consumption is a key limiter in almost all computing platforms, especially server and mobile systems, (3) data movement, especially off-chip to on-chip, is very expensive in terms of bandwidth, energy and latency, much more so than computation. These trends are especially severely-felt in the data-intensive server and energy-constrained mobile systems of today. At the same time, conventional memory technology is facing many technology scaling challenges in terms of reliability, energy, and performance. As a result, memory system architects are open to organizing memory in different ways and making it more intelligent, at the expense of higher cost. The emergence of 3D-stacked memory plus logic, the adoption of error correcting codes inside the latest DRAM chips, proliferation of different main memory standards and chips, specialized for different purposes (e.g., graphics, low-power, high bandwidth, low latency), and the necessity of designing new solutions to serious reliability and security issues, such as the RowHammer phenomenon, are an evidence of this trend. -

DDR3 SODIMM Product Datasheet
DDR3 SODIMM Product Datasheet 廣 穎 電 通 股 份 有 限 公 司 Silicon Power Computer & Communications Inc. TEL: 886-2 8797-8833 FAX: 886-2 8751-6595 台北市114內湖區洲子街106號7樓 7F, No.106, ZHO-Z ST. NEIHU DIST, 114, TAIPEI, TAIWAN, R.O.C This document is a general product description and is subject to change without notice DDR3 SODIMM Product Datasheet Index Index...................................................................................................................................................................... 2 Revision History ................................................................................................................................................ 3 Description .......................................................................................................................................................... 4 Features ............................................................................................................................................................... 5 Pin Assignments................................................................................................................................................ 7 Pin Description................................................................................................................................................... 8 Environmental Requirements......................................................................................................................... 9 Absolute Maximum DC Ratings.................................................................................................................... -

DDR4 2400 R-DIMM / VLP R-DIMM / ECC U-DIMM / ECC SO-DIMM Features
DDR4 2400 R-DIMM / VLP R-DIMM / ECC U-DIMM / ECC SO-DIMM Available in densities ranging from 4GB to 16GB per module and clocked up to 2400MHz for a maximum 17GB/s bandwidth, ADATA DDR4 server memory modules are all certified Intel® Haswell-EP compatible to ensure superior performance. Products ship in four convenient form factors to accommodate diverse needs and applications: R-DIMM and ECC U-DIMM for servers and enterprises, VLP R-DIMM for high-end blade servers, and ECC SO-SIMM for micro servers. Running at a mere 1.2V, ADATA DDR4 memory modules use 20% less energy than conventional lower-performance DDR3 modules, in effect delivering more computational power for less energy draw. ADATA DDR4 server memory modules are an excellent choice for users looking to balance performance, environmental responsibility, and cost effectiveness. Features ECC U-DIMM High speed up to 2400MHz Transfer bandwidths up to 17GB/s Energy efficient: save up to 20% compared to DDR3 8-layer PCB provides improved signal transfer R-DIMM and system stability PCB gold plating: 30u and up Intel Haswell-EP compatible for extreme performance VLP R-DIMM ECC SO-DIMM Specifications Type ECC-DIMM R-DIMM VLP R-DIMM ECC SO-DIMM Standard Standard Very low profile Standard Form factor (1.18" height) (1.18" height) (0.7" height) (1.18" height) Enterprise servers / Enterprise servers / Suitable for Blade servers Micro servers data centers data centers Interface 288-pin 288-pin 288-pin 260-pin Capacity 4GB / 8GB / 16GB 4GB / 8GB / 16GB 4GB / 8GB /16GB 4GB / 8GB / 16GB Rank -

Datasheet DDR4 SDRAM Revision History
Rev. 1.1, Apr. 2018 M391A1K43BB1 M391A1K43BB2 M391A2K43BB1 288pin ECC Unbuffered DIMM based on 8Gb B-die 78FBGA with Lead-Free & Halogen-Free (RoHS compliant) datasheet SAMSUNG ELECTRONICS RESERVES THE RIGHT TO CHANGE PRODUCTS, INFORMATION AND SPECIFICATIONS WITHOUT NOTICE. Products and specifications discussed herein are for reference purposes only. All information discussed herein is provided on an "AS IS" basis, without warranties of any kind. This document and all information discussed herein remain the sole and exclusive property of Samsung Electronics. No license of any patent, copyright, mask work, trademark or any other intellectual property right is granted by one party to the other party under this document, by implication, estoppel or other- wise. Samsung products are not intended for use in life support, critical care, medical, safety equipment, or similar applications where product failure could result in loss of life or personal or physical harm, or any military or defense application, or any governmental procurement to which special terms or provisions may apply. For updates or additional information about Samsung products, contact your nearest Samsung office. All brand names, trademarks and registered trademarks belong to their respective owners. © 2018 Samsung Electronics Co., Ltd.GG All rights reserved. - 1 - Rev. 1.1 ECC Unbuffered DIMM datasheet DDR4 SDRAM Revision History Revision No. History Draft Date Remark Editor 0.5 - First SPEC release 15th Nov, 2017 Preliminary J.Y.Bae - Separate ECC and Non ECC datasheets. J.H.Han 1.0 - Final datasheet. 13th Dec, 2017 Final J.Y.Bae - Correct typo. J.H.Han - Correct speed bin table numbering. - Add DRAM Package Electrical Specifications (x4/x8) table. -

Dynamic Random Access Memory Topics
Dynamic Random Access Memory Topics Simple DRAM Fast Page Mode (FPM) DRAM Extended Data Out (EDO) DRAM Burst EDO (BEDO) DRAM Synchronous DRAM (SDRAM) Rambus DRAM (RDRAM) Double Data Rate (DDR) SDRAM One capacitor and transistor of power, the discharge y Leaks a smallcapacitor amount slowly Simplicit refresh Requires top sk de in ed Us le ti la o v General DRAM Formats • DRAM is produced as integrated circuits (ICs) bonded and mounted into plastic packages with metal pins for connection to control signals and buses • In early use individual DRAM ICs were usually either installed directly to the motherboard or on ISA expansion cards • later they were assembled into multi-chip plug-in modules (DIMMs, SIMMs, etc.) General DRAM formats • Some Standard Module Type: • DRAM chips (Integrated Circuit or IC) • Dual in-line Package (DIP) • DRAM (memory) modules • Single in-line in Package(SIPP) • Single In-line Memory Module (SIMM) • Dual In-line Memory Module (DIMM) • Rambus In-line Memory Module (RIMM) • Small outline DIMM (SO-DIMM) Dual in-line Package (DIP) • is an electronic component package with a rectangular housing and two parallel rows of electrical connecting pins • 14 pins Single in-line in Package (SIPP) • It consisted of a small printed circuit board upon which were mounted a number of memory chips. • It had 30 pins along one edge which mated with matching holes in the motherboard of the computer. Single In-line Memory Module (SIMM) SIMM can be a 30 pin memory module or a 72 pin Dual In-line Memory Module (DIMM) Two types of DIMMs: a 168-pin SDRAM module and a 184-pin DDR SDRAM module. -

Machxo2 LPDDR SDRAM Controller IP Core User's Guide
MachXO2™ LPDDR SDRAM Controller IP Core User’s Guide February 2014 IPUG92_01.3 Table of Contents Chapter 1. Introduction .......................................................................................................................... 4 Introduction ........................................................................................................................................................... 4 Quick Facts ........................................................................................................................................................... 4 Features ................................................................................................................................................................ 4 Chapter 2. Functional Description ........................................................................................................ 5 Overview ............................................................................................................................................................... 5 Initialization Block......................................................................................................................................... 5 Read Training Block..................................................................................................................................... 6 Data Control Block ....................................................................................................................................... 6 LPDDR I/Os ................................................................................................................................................ -

¡ Semiconductor MSM5718C50/Md5764802this Version: Feb
E2G1059-39-21 ¡ Semiconductor MSM5718C50/MD5764802This version: Feb. 1999 ¡ Semiconductor Previous version: Nov. 1998 MSM5718C50/MD5764802 18Mb (2M ´ 9) & 64Mb (8M ´ 8) Concurrent RDRAM DESCRIPTION The 18/64-Megabit Concurrent Rambus™ DRAMs (RDRAM®) are extremely high-speed CMOS DRAMs organized as 2M or 8M words by 8 or 9 bits. They are capable of bursting unlimited lengths of data at 1.67 ns per byte (13.3 ns per eight bytes). The use of Rambus Signaling Level (RSL) technology permits 600 MHz transfer rates while using conventional system and board design methodologies. Low effective latency is attained by operating the two or four 2KB sense amplifiers as high speed caches, and by using random access mode (page mode) to facilitate large block transfers. Concurrent (simultaneous) bank operations permit high effective bandwidth using interleaved transactions. RDRAMs are general purpose high-performance memory devices suitable for use in a broad range of applications including PC and consumer main memory, graphics, video, and any other application where high-performance at low cost is required. FEATURES • Compatible with Base RDRAMs • 600 MB/s peak transfer rate per RDRAM • Rambus Signaling Level (RSL) interface • Synchronous, concurrent protocol for block-oriented, interleaved (overlapped) transfers • 480 MB/s effective bandwidth for random 32 byte transfers from one RDRAM • 13 active signals require just 32 total pins on the controller interface (including power) • 3.3 V operation • Additional/multiple Rambus Channels each provide an additional 600 MB/s bandwidth • Two or four 2KByte sense amplifiers may be operated as caches for low latency access • Random access mode enables any burst order at full bandwidth within a page • Graphics features include write-per-bit and mask-per-bit operations • Available in horizontal surface mount plastic package (SHP32-P-1125-0.65-K) 1/45 ¡ Semiconductor MSM5718C50/MD5764802 PART NUMBERS The 18- and 64-Megabit RDRAMs are available in horizontal surface mount plastic package (SHP), with 533 and 600 MHz clock rate.