Integrating Big Data in the Belgian CPI
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

List of Participants
List of participants Conference of European Statisticians 69th Plenary Session, hybrid Wednesday, June 23 – Friday 25 June 2021 Registered participants Governments Albania Ms. Elsa DHULI Director General Institute of Statistics Ms. Vjollca SIMONI Head of International Cooperation and European Integration Sector Institute of Statistics Albania Argentina Sr. Joaquin MARCONI Advisor in International Relations, INDEC Mr. Nicolás PETRESKY International Relations Coordinator National Institute of Statistics and Censuses (INDEC) Elena HASAPOV ARAGONÉS National Institute of Statistics and Censuses (INDEC) Armenia Mr. Stepan MNATSAKANYAN President Statistical Committee of the Republic of Armenia Ms. Anahit SAFYAN Member of the State Council on Statistics Statistical Committee of RA Australia Mr. David GRUEN Australian Statistician Australian Bureau of Statistics 1 Ms. Teresa DICKINSON Deputy Australian Statistician Australian Bureau of Statistics Ms. Helen WILSON Deputy Australian Statistician Australian Bureau of Statistics Austria Mr. Tobias THOMAS Director General Statistics Austria Ms. Brigitte GRANDITS Head International Relation Statistics Austria Azerbaijan Mr. Farhad ALIYEV Deputy Head of Department State Statistical Committee Mr. Yusif YUSIFOV Deputy Chairman The State Statistical Committee Belarus Ms. Inna MEDVEDEVA Chairperson National Statistical Committee of the Republic of Belarus Ms. Irina MAZAISKAYA Head of International Cooperation and Statistical Information Dissemination Department National Statistical Committee of the Republic of Belarus Ms. Elena KUKHAREVICH First Deputy Chairperson National Statistical Committee of the Republic of Belarus Belgium Mr. Roeland BEERTEN Flanders Statistics Authority Mr. Olivier GODDEERIS Head of international Strategy and coordination Statistics Belgium 2 Bosnia and Herzegovina Ms. Vesna ĆUŽIĆ Director Agency for Statistics Brazil Mr. Eduardo RIOS NETO President Instituto Brasileiro de Geografia e Estatística - IBGE Sra. -

Celebrating the Establishment, Development and Evolution of Statistical Offices Worldwide: a Tribute to John Koren
Statistical Journal of the IAOS 33 (2017) 337–372 337 DOI 10.3233/SJI-161028 IOS Press Celebrating the establishment, development and evolution of statistical offices worldwide: A tribute to John Koren Catherine Michalopouloua,∗ and Angelos Mimisb aDepartment of Social Policy, Panteion University of Social and Political Sciences, Athens, Greece bDepartment of Economic and Regional Development, Panteion University of Social and Political Sciences, Athens, Greece Abstract. This paper describes the establishment, development and evolution of national statistical offices worldwide. It is written to commemorate John Koren and other writers who more than a century ago published national statistical histories. We distinguish four broad periods: the establishment of the first statistical offices (1800–1914); the development after World War I and including World War II (1918–1944); the development after World War II including the extraordinary work of the United Nations Statistical Commission (1945–1974); and, finally, the development since 1975. Also, we report on what has been called a “dark side of numbers”, i.e. “how data and data systems have been used to assist in planning and carrying out a wide range of serious human rights abuses throughout the world”. Keywords: National Statistical Offices, United Nations Statistical Commission, United Nations Statistics Division, organizational structure, human rights 1. Introduction limitations to this power. The limitations in question are not constitutional ones, but constraints that now Westergaard [57] labeled the period from 1830 to seemed to exist independently of any formal arrange- 1849 as the “era of enthusiasm” in statistics to indi- ments of government.... The ‘era of enthusiasm’ in cate the increasing scale of their collection. -

“Migration and Labor Market Integration in Europe”
Online Appendix to “Migration and Labor Market Integration in Europe” by David Dorn and Josef Zweimüller Appendix A: Appendix Figures Figure A1: Annual inflows of foreign citizens into the Netherlands 2 1.5 1 Number of inflows of inflows of Number .5 foreigners into Netherlands (in 100'000) (in Netherlands into foreigners 0 1950 1960 1970 1980 1990 2000 2010 2020 Year Contemporary EU EU-28 Total Note: “Contemporary EU” indicates inflows of foreign nationals who were citizens of a country that was a member of the EEC/EU in the indicated year. “EU-28” indicates inflows of foreigners who were citizens of one of the 28 countries that eventually joined the EU. Data sources: International Migration Institute (2015), Statistics Netherlands (2020a, 2020b). Figure A2: Net inflow of foreign citizens to western Europe from 2001 to 2018 2 2.5 10.5 IT SE 2 8.4 1.6 ES 1.5 6.3 1.2 AT* DE 1 .8 BE 4.2 IE DK DE NOAT DK NL .5 2.1 ES* .4 divided by total population in 2001 (%) 2001 in population total by divided (%) 2001 in population total by divided PT NO (%) 2001 in total population by divided BE BE Syria2001-2018 from citizens of inflow Net CH SECH Net inflow of citizens from Morocco 2001-2018 Morocco from citizens of Net inflow Net inflow of citizens from Romania 2001-2018 Romania from of citizens Net inflow FR IT FR NL FI FI GB SE CHDE NL FR 0 0 PTATGBFINO DK ESIT 0 PRT 0 .05 .1 .15 .2 .25 0 .21 .42 .63 .84 1.05 0 .04 .08 .12 .16 .2 Percentage of citizens from Romania among total population in 2001 Percentage of citizens from Morocco among total population -

ESS5 Appendix A4 Population Statistics Ed
APPENDIX A4 POPULATION STATISTICS, ESS5-2010 ed. 5.0 Austria ........................................................................................... 2 Belgium .......................................................................................... 5 Bulgaria ........................................................................................ 19 Croatia ......................................................................................... 25 Cyprus .......................................................................................... 27 Czech Republic .............................................................................. 63 Denmark ....................................................................................... 67 Estonia ......................................................................................... 83 Finland ......................................................................................... 84 France ........................................................................................ 124 Germany ..................................................................................... 130 Greece ....................................................................................... 145 Hungary ..................................................................................... 149 Ireland ....................................................................................... 155 Israel ......................................................................................... 162 Lithuania -

Sources and Data Description
OECD Regions and Cities at a Glance 2018 © OECD 2018 ANNEX B Sources and data description User guide: List of variables Variables used Page Chapter(s) Area 144 2 Business demography, births and deaths of enterprises 144 1 Employment at place of work and gross value added by industry 145 1 Foreign-born (migrants) 145 4 Gross domestic product (GDP) 146 1 Homicides 147 2 Household disposable income 148 2, 4 Households with broadband connection 149 2 Housing expenditures as a share of household disposable income 150 2 Income segregation in cities 151 4 Labour force, employment at place of residence by gender, unemployment 152 2 Labour force by educational attainment 152 2 Life expectancy at birth, total and by gender 153 2 Metropolitan population 154 4 Motor vehicle theft 155 2 Patents applications 155 1 PM2.5 particle concentration 155 2, 4 Population mobility among regions 156 3 Population, total, by age and gender 157 3 R&D expenditure and R&D personnel 158 1 Rooms per person (number of) 159 2 Subnational government expenditure, revenue, investment and debt 160 5 Voter turnout 160 2 Note on Israel: The statistical data for Israel are supplied by and under the responsibility of the relevant Israeli authorities. The use of such data by the OECD is without prejudice to the status of the Golan Heights, East Jerusalem and Israeli settlements in the West Bank under the terms of international law. 143 ANNEX B Area Country Source EU24 countries1 Eurostat: General and regional statistics, demographic statistics, population and area Australia Australian Bureau of Statistics (ABS), summing up SLAs Canada Statistics Canada http://www12.statcan.ca/english/census01/products/standard/popdwell/Table-CD-P. -

Sources and Data Description
ANNEX B ANNEX B Sources and data description User guide: List of variables Variables used Page Chapter(s) Area 147 2 Age-adjusted mortality rates based on mortality data 148 1 Death rates due to diseases of the respiratory system 148 1 Employment at place of work and gross value added by industry 149 2 Gini index of household disposable income 149 1 Gross domestic product (GDP) 150 2 Homicides 151 1 Hospital beds 152 4 Household disposable income 153 1 Households with broadband connection 154 4 Housing expenditures as a share of household disposable income 155 1 Individuals with unmet medical needs 155 1 Labour force, employment at place of residence by gender, unemployment, total and growth 156 1 and 2 Labour force by educational attainment 158 1 Life expectancy at birth, total and by gender 159 1 Life satisfaction 159 1 Local governments in metropolitan areas 160 2 Metropolitan population, total and by age 161 2 Motor vehicle theft 162 1 Municipal waste and recycled waste 163 4 Number of rooms per person 163 1 Part-time employment 164 4 Perception of corruption 164 1 PCT patent and co-patent applications, total and by sector 165 2 Physicians 165 4 PM2.5 particle concentration 166 1 Population, total, by age and gender 166 2 Population mobility among regions 167 4 R&D expenditure 169 2 R&D personnel 170 2 Social network support 170 1 Subnational government expenditure, revenue, investment and debt 171 3 Voter turnout 171 1 Young population neither in employment nor in education or training 172 4 Youth unemployment 173 4 The tables refer to the years and territorial levels used in this publication. -

The ESS Report 2015
Editorial Committee: Marjo Bruun, Director-General, Statistics Finland Mariana Kotzeva, Deputy Director- General, Eurostat Tjark Tjin-a-tsoi, Director-General, Statistics Netherlands Janusz Witkowski, President, Central Statistical Office Authors: Lukasz Augustyniak, Bettina Knauth, Morag Ottens, Eurostat Design: Claudia Daman, Publications Office Europe Direct is a service to help you find answers to your questions about the European Union. Freephone number (*): CONTENTS 00 800 6 7 8 9 10 11 (*) Certain mobile telephone operators do not allow access to 00 800 numbers or these calls may be billed. > Foreword ...........4 > What is the European Statistical System? ...........6 > A true ESS Perspective: A statistician’s best friends are statisticians in other countries ...........10 > The Instituto Nacional de Estadistica of Spain — an institution clothed in statistics ...........12 > The ESS in the year 2015 ...........14 > The role of the Presidency of the Council ...........18 > 2015 Council Presidencies in Statistics: Latvia and Luxembourg ...........20 Page 4: © European Union, 2016 Page 5: © Statistical Office of Slovenia > Second round of ESS peer reviews — importance and lessons learned ...........24 Page 8: © Statistics Portugal Page 10: © European Statistical Governance Advisory Board Page 12: © Instituto Nacional de Estadística, Spain Peer Review in Estonia ...........28 Page 19 — Latvia (top right to bottom right): © Euro Slice , © Nenyaki , © Dave Curtis , © Sandis Grandovskis (Luxembourg) Page 19 — Luxembourg (top left to bottom -

To Apply the PHI to the Metropolitan Areas It Was Deemed Important to Identify the Adequated Administrative Level to Provide Evidence on Urban Inequalities
Supplementary Material S1: Additional information on the Local Administrative Unit and delimitation of each metropolitan area. To apply the PHI to the metropolitan areas it was deemed important to identify the adequated administrative level to provide evidence on urban inequalities. For this study the definition of a municipality from the Encyclopædia Britannica was applied (http://www.britannica.com/topic/municipality): «A municipality is a political subdivision of a state within which a municipal corporation has been established to provide general local government for a specific population concentration in a defined area (…). The municipality is one of several basic types of local government, the others being counties, townships, school districts, and special districts».). However, European countries have a diversified system of local government in which several different categories exist. For instance, the term municipality may be applied in France to the commune, in Italy to comune and in Portugal to município. EUROSTAT has set up a hierarchical system of Nomenclature of Territorial Units for Statistics (NUTS) and Local Administrative Units (LAUs). NUTS are organized into four levels. NUTS 0 correspond to the 28 EU countries. NUTS 1 are the major socio-economic regions within a given country. NUTS 2 are basic regions for the application of regional policies and NUTS 3 are small regions for specific diagnoses. Below, the Local Administrative Units are also organized into two hierarchical levels: The upper LAU level (LAU level 1) and the lower LAU level (LAU level 2). For most European countries, LAU-2 corresponds to municipalities, except for Bulgaria and Hungary (Settlements), Ireland (Districts), Lithuania (Elderships), Malta (Councils), Denmark (Municipalities), Greece (Municipalities), Portugal (Parishes), and the United Kingdom (Wards) [47] (Table S1). -

Comparable Time Use Statistics—National Tables from 10 European
2005 EDITION Comparable time use statistics National tables from 10 European countries February 2005 THEME Population EUROPEAN and social COMMISSION conditions Europe Direct is a service to help you find answers to your questions about the European Union Freephone number (*): 00 800 6 7 8 9 10 11 (*) Certain mobile telephone operators do not allow access to 00 800 numbers or these calls may be billed. A great deal of additional information on the European Union is available on the Internet. It can be accessed through the Europa server (http://europa.eu.int). Luxembourg: Office for Official Publications of the European Communities, 2005 ISSN 1725-065X ISBN 92-894-8553-1 © European Communities, 2005 Comparable time use statistics National tables from 10 European countries February 2005 Acknowledgements Eurostat thanks Ilze LACE from the Central Statistical Bureau of Latvia for the elaboration of this working paper and the 10 participating countries for the production of the time use statistics. Preface In July 2004 Pocketbook on How Europeans spend their time! was published. This pocketbook is the first compendium of the Harn1onised European Time Use Surveys (HETUS). It aims to shed light on how women and men organise their everyday life in ten European countries. The Pocketbook was designed and produced by Statistics Finland. It has been funded by the fifth Community Action Programme to promote Gender Equality 2001-2005. The statistical source for the pocketbook is national Time Use Surveys that have been conducted in several European countries. Time Use Surveys fill a number of gaps in the statistical information available in the social domain. -

OECD Economic Surveys BELGIUM FEBRUARY 2015 OVERVIEW
OECD Economic Surveys BELGIUM FEBRUARY 2015 OVERVIEW OECD ECONOMIC SURVEYS: BELGIUM OECD 2015 1 This document and any map included herein are without prejudice to the status of or sovereignty over any territory, to the delimitation of international frontiers and boundaries and to the name of any territory, city or area. The statistical data for Israel are supplied by and under the responsibility of the relevant Israeli authorities. The use of such data by the OECD is without prejudice to the status of the Golan Heights, East Jerusalem and Israeli settlements in the West Bank under the terms of international law. OECD ECONOMIC SURVEYS: BELGIUM OECD 2015 2 Executive summary ● Main findings ● Key recommendations OECD ECONOMIC SURVEYS: BELGIUM OECD 2015 3 9 EXECUTIVE SUMMARY Main findings Belgium has returned to growth and halted the deterioration in external competitiveness, while continuing to score well on broader measures of well-being. The authorities have reduced budget deficits and substantially reformed fiscal federalism arrangements. However, the recovery is still fragile, long-term growth is held back by low employment rates and eroded cost competitiveness, and public debt remains uncomfortably high. For vulnerable groups, notably immigrants, labour market integration remains difficult and, for many, housing conditions have deteriorated. Securing fiscal sustainability while promoting employment and competitiveness. Public debt is set to hover around 100% of GDP if no further progress is made in fiscal consolidation. The absence of domestic multi-year expenditure ceilings makes spending-based consolidation and medium-term expenditure reforms more difficult. There is nonetheless considerable scope for these reforms, as public expenditure is high, reflecting public consumption and social transfers, particularly pensions. -

Sources and Data Description
ANNEX B ANNEX B Sources and data description User guide: List of variables Variables used Page Area 166 Carbon dioxide (CO2) emissions 166 Concentration of PM10 particles 166 Concentration of NO2 167 Employment and gross value added by industry 167 Employment at place of work 168 Gross domestic product (GDP) 169 Infant mortality 170 Labour force, employment at place of residency, unemployment; total and by gender 171 Labour force by educational attainment 172 Land cover and changes 172 Life expectancy, total and by gender 173 Local governments in metropolitan areas 174 Long-term unemployment 175 Mortality rates due to transport accidents 175 Motor vehicle theft 176 Municipal waste and recycled waste 177 Net ecosystem productivity (NEP) 177 Number of cars 178 Number of murders 179 Number of hospital beds 180 Number of physicians 181 Part-time employment 182 PCT patent applications, total and by sector; PCT co-patent applications 182 Population; total, by age and gender 183 Population in functional urban areas 184 Population mobility among regions 185 Primary and disposable income of households 186 R&D expenditure 187 R&D personnel 188 Scientific publications and citations 188 Subnational government expenditure, revenue and debt 189 Young population neither in employment nor in education or training 189 Youth unemployment 190 The tables refer to the years and territorial levels used in this publication. The statistical data for Israel are supplied by and under the responsibility of the relevant Israeli authorities. The use of such data by the OECD is without prejudice to the status of the Golan Heights, East Jerusalem and Israeli settlements in the West Bank under the terms of international law. -
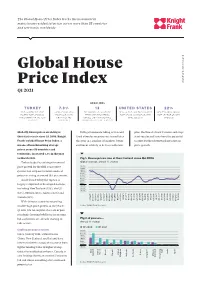
Global House Price Index Tracks the Movement in Mainstream Residential Prices Across More Than 55 Countries and Territories Worldwide
The Global House Price Index tracks the movement in mainstream residential prices across more than 55 countries and territories worldwide Global House Price Index knightfrank.com/research Q1 2021 HEADLINES TURKEY 7.3% 13 UNITED STATES 22% THE COUNTRY WITH THE AVERAGE CHANGE IN THE NUMBER OF COUNTRIES/ AT 13.2%, THE COUNTRY'S HIGHEST NEW ZEALAND'S ANNUAL HIGHEST RATE OF ANNUAL PRICES ACROSS 56 TERRITORIES REGISTERING RATE OF ANNUAL PRICE GROWTH RATE OF PRICE GROWTH PRICE GROWTH IN THE YEAR COUNTRIES AND DOUBLE-DIGIT ANNUAL PRICE SINCE DEC 2005 IN Q1 2021 TO Q1 2021 TERRITORIES GROWTH IN THE YEAR TO Q1 2021 Globally, house prices are rising at With governments taking action and plus, the threat of new variants and stop/ their fastest rate since Q4 2006. Knight fiscal stimulus measures set to end later start vaccine roll-outs have the potential Frank’s Global House Price Index, a this year in a number of markets, buyer to exert further downward pressure on means of benchmarking average sentiment is likely to be less exuberant, price growth. prices across 56 countries and territories, increased 7.3% in the year to March 2021. Fig 1. House prices rise at their fastest since Q4 2006 Turkey leads the rankings for annual Global average, annual % change price growth for the fifth consecutive 14.0% 12.0% quarter, but strip out inflation and real 10.0% 8.0% prices are rising at around 16% per annum. 6.0% 4.0% Aside from Turkey the top ten is 2.0% largely comprised of developed nations, 0.0% -2.0% including New Zealand (22%), the US -4.0% -6.0% (13%), Sweden (13%), Austria (12%) and Canada (11%).