Transcriptomic Analysis of Prostate Cancer Progression
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Structural, Biochemical, and Cell Biological Characterization of Rab7 Mutants That Cause Peripheral Neuropathy
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations Spring 2010 Structural, Biochemical, and Cell Biological Characterization of Rab7 Mutants That Cause Peripheral Neuropathy Brett A. McCray University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/edissertations Part of the Molecular and Cellular Neuroscience Commons Recommended Citation McCray, Brett A., "Structural, Biochemical, and Cell Biological Characterization of Rab7 Mutants That Cause Peripheral Neuropathy" (2010). Publicly Accessible Penn Dissertations. 145. https://repository.upenn.edu/edissertations/145 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/edissertations/145 For more information, please contact [email protected]. Structural, Biochemical, and Cell Biological Characterization of Rab7 Mutants That Cause Peripheral Neuropathy Abstract Coordinated trafficking of intracellular vesicles is of critical importance for the maintenance of cellular health and homeostasis. Members of the Rab GTPase family serve as master regulators of vesicular trafficking, maturation, and fusion by reversibly associating with distinct target membranes and recruiting specific effector proteins. Rabs act as molecular switches by cycling between an active, GTP-bound form and an inactive, GDP-bound form. The activity cycle is coupled to GTP hydrolysis and is tightly controlled by regulatory proteins such as guanine nucleotide exchange factors and GTPase activating proteins. Rab7 specifically regulates the trafficking and maturation of vesicle populations that are involved in protein degradation including late endosomes, lysosomes, and autophagic vacuoles. Missense mutations of Rab7 cause a dominantly-inherited axonal degeneration known as Charcot-Marie-Tooth type 2B (CMT2B) through an unknown mechanism. Patients with CMT2B present with length-dependent degeneration of peripheral sensory and motor neurons that leads to weakness and profound sensory loss. -

A Rab Escort Protein Regulates the MAPK Pathway That
bioRxiv preprint doi: https://doi.org/10.1101/2020.06.02.130690; this version posted June 2, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Genome-Wide Screen for MAPK Regulatory Proteins Jamalzadeh and Cullen 1 A Rab Escort Protein Regulates the MAPK Pathway That 2 Controls Filamentous Growth in Yeast 3 4 Sheida Jamalzadeh 1 and Paul J. Cullen 2 † 5 1. Department of Chemical and Biological Engineering, University at Buffalo, State University 6 of New York, Buffalo New York 7 2. Department of Biological Sciences, University at Buffalo, State University of New York, 8 Buffalo New York 9 10 † Corresponding author: Paul J. Cullen 11 Address: Department of Biological Sciences 12 532 Cooke Hall 13 State University of New York at Buffalo 14 Buffalo, NY 14260-1300 15 Phone: (716)-645-4923 16 FAX: (716)-645-2975 17 E-mail: [email protected] 18 19 20 Keywords: Rab Escort Protein, MAP kinase, Cdc42, Protein Trafficking, Cell Polarity, 21 Genomics 22 23 Running title: Genome-Wide Screen for MAPK Regulatory Proteins 24 25 The authors have no competing interests in the study. 26 27 SJ designed and performed experiments, analyzed the data, and wrote the paper. PJC designed 28 experiments and wrote the paper. 29 30 The manuscript contains 32 pages, 6 Figures, 2 Tables, 3 Supplemental Tables, and 2 31 Supplemental Figures 32 33 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.06.02.130690; this version posted June 2, 2020. -

Horizon Scanning Status Report, Volume 2
PCORI Health Care Horizon Scanning System Volume 2, Issue 3 Horizon Scanning Status Report September 2020 Prepared for: Patient-Centered Outcomes Research Institute 1828 L St., NW, Suite 900 Washington, DC 20036 Contract No. MSA-HORIZSCAN-ECRI-ENG-2018.7.12 Prepared by: ECRI Institute 5200 Butler Pike Plymouth Meeting, PA 19462 Investigators: Randy Hulshizer, MA, MS Damian Carlson, MS Christian Cuevas, PhD Andrea Druga, PA-C Marcus Lynch, PhD, MBA Misha Mehta, MS Prital Patel, MPH Brian Wilkinson, MA Donna Beales, MLIS Jennifer De Lurio, MS Eloise DeHaan, BS Eileen Erinoff, MSLIS Cassia Hulshizer, AS Madison Kimball, MS Maria Middleton, MPH Diane Robertson, BA Melinda Rossi, BA Kelley Tipton, MPH Rosemary Walker, MLIS Andrew Furman, MD, MMM, FACEP Statement of Funding and Purpose This report incorporates data collected during implementation of the Patient-Centered Outcomes Research Institute (PCORI) Health Care Horizon Scanning System, operated by ECRI under contract to PCORI, Washington, DC (Contract No. MSA-HORIZSCAN-ECRI-ENG-2018.7.12). The findings and conclusions in this document are those of the authors, who are responsible for its content. No statement in this report should be construed as an official position of PCORI. An intervention that potentially meets inclusion criteria might not appear in this report simply because the Horizon Scanning System has not yet detected it or it does not yet meet inclusion criteria outlined in the PCORI Health Care Horizon Scanning System: Horizon Scanning Protocol and Operations Manual. Inclusion or absence of interventions in the horizon scanning reports will change over time as new information is collected; therefore, inclusion or absence should not be construed as either an endorsement or rejection of specific interventions. -

Expression of Rab Prenylation Pathway Genes and Relation to Disease Progression in Choroideremia
Article Expression of Rab Prenylation Pathway Genes and Relation to Disease Progression in Choroideremia Lewis E. Fry1,2, Maria I. Patrício1,2, Jasleen K. Jolly1,2,KanminXue1,2,and Robert E. MacLaren1,2 1 Nuffield Laboratory of Ophthalmology, Nuffield Department of Clinical Neurosciences, University of Oxford, Oxford,UK 2 Oxford Eye Hospital, Oxford University Hospitals NHS Foundation Trust, Oxford, UK Correspondence: Lewis E. Fry, Purpose: Choroideremia results from the deficiency of Rab Escort Protein 1 (REP1), Nuffield Department of Clinical encoded by CHM, involved in the prenylation of Rab GTPases. Here, we investigate Neuroscience, Level 6, West Wing, whether the transcription and expression of other genes involved in the prenylation John Radcliffe Hospital, Oxford, OX3 of Rab proteins correlates with disease progression in a cohort of patients with choroi- 9DU, UK. deremia. e-mail: [email protected]. Methods: Rates of retinal pigment epithelial area loss in 41 patients with choroideremia Received: February 9, 2021 were measured using fundus autofluorescence imaging for up to 4 years. From lysates of Accepted: May 9, 2021 cultured skin fibroblasts donated by patients (n = 15) and controls (n = 14), CHM, CHML, Published: July 13, 2021 RABGGTB and RAB27A mRNA expression, and REP1 and REP2 protein expression were Keywords: choroideremia; rab compared. escort protein 1 (REP1); inherited Results: The central autofluorescent island area loss in patients with choroideremia retinal degeneration; prenylation; occurred with a mean half-life of 5.89 years (95% confidence interval [CI] = 5.09–6.70), fundus autofluorescence with some patients demonstrating relatively fast or slow rates of progression (range = Citation: Fry LE, Patrício MI, Jolly JK, 3.3–14.1 years). -

Public Summary of Opinion on Orphan Designation of Adeno-Associated
1 June 2015 EMA/COMP/223562/2014 Rev.1 Committee for Orphan Medicinal Products Public summary of opinion on orphan designation Adeno-associated viral vector serotype 2 containing the human CHM gene encoding human Rab escort protein 1 for the treatment of choroideremia First publication 2 July 2014 Rev.1: administrative update 1 June 2015 Disclaimer Please note that revisions to the Public Summary of Opinion are purely administrative updates. Therefore, the scientific content of the document reflects the outcome of the Committee for Orphan Medicinal Products (COMP) at the time of designation and is not updated after first publication. On 4 June 2014, orphan designation (EU/03/14/1278) was granted by the European Commission to Alan Boyd Consultants Ltd, United Kingdom, for adeno-associated viral vector serotype 2 containing the human CHM gene encoding human Rab escort protein 1 for the treatment of choroideremia. What is choroideremia? Choroideremia is a hereditary disease of the eye that leads to progressive loss of sight. The disease mostly affects males. In patients with choroideremia, cells in the retina (the light-sensitive surface at the back of the eye), the retinal pigment epithelium (the cell layer just outside the retina that nourishes retinal cells) and the choroid (a network of blood vessels located between the retina and the sclera, the “white of the eye”) become damaged and eventually die. Chodoideraemia is a long-term debilitating disease because it causes the patient’s sight to worsen, eventually leading to blindness. What is the estimated number of patients affected by the condition? At the time of designation, choroideremia affected less than 0.2 people in 10,000 per year in the European Union (EU). -

Rab Gtpases As Regulators of Endocytosis, Targets of Disease and Therapeutic Opportunities
CORE Metadata, citation and similar papers at core.ac.uk Provided by PubMed Central Clin Genet 2011: 80: 305–318 © 2011 John Wiley & Sons A/S Printed in Singapore. All rights reserved CLINICAL GENETICS doi: 10.1111/j.1399-0004.2011.01724.x Review Rab GTPases as regulators of endocytosis, targets of disease and therapeutic opportunities Agola JO, Jim PA, Ward HH, BasuRay S, Wandinger-Ness A. Rab JO Agolaa,b, PA Jima,b, GTPases as regulators of endocytosis, targets of disease and therapeutic HH Warda,b,SBasuRaya,b opportunities. and A Wandinger-Nessa,b © Clin Genet 2011: 80: 305–318. John Wiley & Sons A/S, 2011 aDepartment of Pathology and bCancer Rab GTPases are well-recognized targets in human disease, although are Center, University of New Mexico School of Medicine, Albuquerque, NM underexplored therapeutically. Elucidation of how mutant or dysregulated 87131, USA Rab GTPases and accessory proteins contribute to organ specific and systemic disease remains an area of intensive study and an essential foundation for effective drug targeting. Mutation of Rab GTPases or associated regulatory proteins causes numerous human genetic diseases. Cancer, neurodegeneration and diabetes represent examples of acquired human diseases resulting from the up- or downregulation or aberrant function of Rab GTPases. The broad range of physiologic processes and organ systems affected by altered Rab GTPase activity is based on pivotal roles in responding to cell signaling and metabolic demand through the coordinated regulation of membrane trafficking. The Rab-regulated processes of cargo sorting, cytoskeletal translocation of vesicles and appropriate fusion with the target membranes control cell metabolism, Key words: cancer – viability, growth and differentiation. -

1 SUPPLEMENTAL DATA Figure S1. Poly I:C Induces IFN-Β Expression
SUPPLEMENTAL DATA Figure S1. Poly I:C induces IFN-β expression and signaling. Fibroblasts were incubated in media with or without Poly I:C for 24 h. RNA was isolated and processed for microarray analysis. Genes showing >2-fold up- or down-regulation compared to control fibroblasts were analyzed using Ingenuity Pathway Analysis Software (Red color, up-regulation; Green color, down-regulation). The transcripts with known gene identifiers (HUGO gene symbols) were entered into the Ingenuity Pathways Knowledge Base IPA 4.0. Each gene identifier mapped in the Ingenuity Pathways Knowledge Base was termed as a focus gene, which was overlaid into a global molecular network established from the information in the Ingenuity Pathways Knowledge Base. Each network contained a maximum of 35 focus genes. 1 Figure S2. The overlap of genes regulated by Poly I:C and by IFN. Bioinformatics analysis was conducted to generate a list of 2003 genes showing >2 fold up or down- regulation in fibroblasts treated with Poly I:C for 24 h. The overlap of this gene set with the 117 skin gene IFN Core Signature comprised of datasets of skin cells stimulated by IFN (Wong et al, 2012) was generated using Microsoft Excel. 2 Symbol Description polyIC 24h IFN 24h CXCL10 chemokine (C-X-C motif) ligand 10 129 7.14 CCL5 chemokine (C-C motif) ligand 5 118 1.12 CCL5 chemokine (C-C motif) ligand 5 115 1.01 OASL 2'-5'-oligoadenylate synthetase-like 83.3 9.52 CCL8 chemokine (C-C motif) ligand 8 78.5 3.25 IDO1 indoleamine 2,3-dioxygenase 1 76.3 3.5 IFI27 interferon, alpha-inducible -

Clinical and Functional Findings in Choroideremia Due to Complete Deletion of the CHM Gene
OPHTHALMIC MOLECULAR GENETICS Clinical and Functional Findings in Choroideremia Due to Complete Deletion of the CHM Gene Marco Mura, MD; Christina Sereda, BS; Monica M. Jablonski, PhD; Ian M. MacDonald, MD; Alessandro Iannaccone, MD, MS Objective: To report the clinical, functional, and in vivo illaris atrophy. The carrier mother had diffuse elevation microanatomic characteristics of a family with choroi- of 650-nm dark-adapted thresholds. deremia with a deletion of the entire gene that encodes for the Rab escort protein 1 (CHM). Conclusions: Deletion of the CHM gene causes severe choroideremia. Results of serial ERGs and fundus ex- Methods: We performed clinical examination, flash elec- aminations documented progression first of rod and then troretinography (ERG), light- and dark-adapted perim- of cone disease. Fundus appearance deteriorated rap- etry, and optical coherence tomography; reviewed medi- idly, in excess of the severity of the ERG decline. Opti- cal records; and obtained the medical history of the cal coherence tomography findings explained this ob- proband and 3 other family members. servation, at least in part. Results: At 4 years of age, the proband had a hypopig- Clinical Relevance: To our knowledge, this is the ear- mented fundus and retinal pigment epithelium mot- liest clinical, microanatomic, and ERG longitudinal tling, and dark-adapted ERGs were reduced. Severe reti- phenotypic documentation in molecularly character- nal pigment epithelium and choriocapillaris atrophy ized choroideremia and the first documentation of im- developed by 6 years of age, paralleled by a lesser ERG decline. Optical coherence tomography findings showed paired dark-adapted cone function in carriers. The pres- normal neural retinas overlying mild changes in the reti- ervation of the neural retina has mechanistic, prognostic, nal pigment epithelium and thinned neural retina with and therapeutic implications. -

Research Article Complex and Multidimensional Lipid Raft Alterations in a Murine Model of Alzheimer’S Disease
SAGE-Hindawi Access to Research International Journal of Alzheimer’s Disease Volume 2010, Article ID 604792, 56 pages doi:10.4061/2010/604792 Research Article Complex and Multidimensional Lipid Raft Alterations in a Murine Model of Alzheimer’s Disease Wayne Chadwick, 1 Randall Brenneman,1, 2 Bronwen Martin,3 and Stuart Maudsley1 1 Receptor Pharmacology Unit, National Institute on Aging, National Institutes of Health, 251 Bayview Boulevard, Suite 100, Baltimore, MD 21224, USA 2 Miller School of Medicine, University of Miami, Miami, FL 33124, USA 3 Metabolism Unit, National Institute on Aging, National Institutes of Health, 251 Bayview Boulevard, Suite 100, Baltimore, MD 21224, USA Correspondence should be addressed to Stuart Maudsley, [email protected] Received 17 May 2010; Accepted 27 July 2010 Academic Editor: Gemma Casadesus Copyright © 2010 Wayne Chadwick et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Various animal models of Alzheimer’s disease (AD) have been created to assist our appreciation of AD pathophysiology, as well as aid development of novel therapeutic strategies. Despite the discovery of mutated proteins that predict the development of AD, there are likely to be many other proteins also involved in this disorder. Complex physiological processes are mediated by coherent interactions of clusters of functionally related proteins. Synaptic dysfunction is one of the hallmarks of AD. Synaptic proteins are organized into multiprotein complexes in high-density membrane structures, known as lipid rafts. These microdomains enable coherent clustering of synergistic signaling proteins. -

Major Actors in the Mechanism of Protein-Trafficking Disorders
Eur J Pediatr (2008) 167:723–729 DOI 10.1007/s00431-008-0740-z REVIEW Rab proteins and Rab-associated proteins: major actors in the mechanism of protein-trafficking disorders Lucien Corbeel & Kathleen Freson Received: 31 March 2008 /Accepted: 8 April 2008 /Published online: 8 May 2008 # The Author(s) 2008 Abstract Ras-associated binding (Rab) proteins and Rab- only be bound to GTP, but they need also to be associated proteins are key regulators of vesicle transport, ‘prenylated’—i.e. bound to the cell membranes by isoprenes, which is essential for the delivery of proteins to specific which are intermediaries in the synthesis of cholesterol (e.g. intracellular locations. More than 60 human Rab proteins geranyl geranyl or farnesyl compounds). This means that have been identified, and their function has been shown to isoprenylation can be influenced by drugs such as statins, depend on their interaction with different Rab-associated which inhibit isoprenylation, or biphosphonates, which inhibit proteins regulating Rab activation, post-translational modifi- that farnesyl pyrophosphate synthase necessary for Rab cation and intracellular localization. The number of known GTPase activity. Conclusion: Although protein-trafficking inherited disorders of vesicle trafficking due to Rab cycle disorders are clinically heterogeneous and represented in defects has increased substantially during the past decade. almost every subspeciality of pediatrics, the identification of This review describes the important role played by Rab common pathogenic mechanisms may provide a better proteins in a number of rare monogenic diseases as well as diagnosis and management of patients with still unknown common multifactorial human ones. Although the clinical Rab cycle defects and stimulate the development of thera- phenotype in these monogenic inherited diseases is highly peutic agents. -
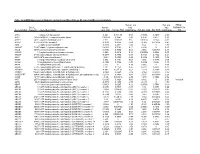
Mrna Expression in Human Leiomyoma and Eker Rats As Measured by Microarray Analysis
Table 3S: mRNA Expression in Human Leiomyoma and Eker Rats as Measured by Microarray Analysis Human_avg Rat_avg_ PENG_ Entrez. Human_ log2_ log2_ RAPAMYCIN Gene.Symbol Gene.ID Gene Description avg_tstat Human_FDR foldChange Rat_avg_tstat Rat_FDR foldChange _DN A1BG 1 alpha-1-B glycoprotein 4.982 9.52E-05 0.68 -0.8346 0.4639 -0.38 A1CF 29974 APOBEC1 complementation factor -0.08024 0.9541 -0.02 0.9141 0.421 0.10 A2BP1 54715 ataxin 2-binding protein 1 2.811 0.01093 0.65 0.07114 0.954 -0.01 A2LD1 87769 AIG2-like domain 1 -0.3033 0.8056 -0.09 -3.365 0.005704 -0.42 A2M 2 alpha-2-macroglobulin -0.8113 0.4691 -0.03 6.02 0 1.75 A4GALT 53947 alpha 1,4-galactosyltransferase 0.4383 0.7128 0.11 6.304 0 2.30 AACS 65985 acetoacetyl-CoA synthetase 0.3595 0.7664 0.03 3.534 0.00388 0.38 AADAC 13 arylacetamide deacetylase (esterase) 0.569 0.6216 0.16 0.005588 0.9968 0.00 AADAT 51166 aminoadipate aminotransferase -0.9577 0.3876 -0.11 0.8123 0.4752 0.24 AAK1 22848 AP2 associated kinase 1 -1.261 0.2505 -0.25 0.8232 0.4689 0.12 AAMP 14 angio-associated, migratory cell protein 0.873 0.4351 0.07 1.656 0.1476 0.06 AANAT 15 arylalkylamine N-acetyltransferase -0.3998 0.7394 -0.08 0.8486 0.456 0.18 AARS 16 alanyl-tRNA synthetase 5.517 0 0.34 8.616 0 0.69 AARS2 57505 alanyl-tRNA synthetase 2, mitochondrial (putative) 1.701 0.1158 0.35 0.5011 0.6622 0.07 AARSD1 80755 alanyl-tRNA synthetase domain containing 1 4.403 9.52E-05 0.52 1.279 0.2609 0.13 AASDH 132949 aminoadipate-semialdehyde dehydrogenase -0.8921 0.4247 -0.12 -2.564 0.02993 -0.32 AASDHPPT 60496 aminoadipate-semialdehyde -

Horizon Scanning Status Report June 2020 Prepared For: Patient-Centered Outcomes Research Institute 1828 L St., NW, Suite 900 Washington, DC 20036
PCORI Health Care Horizon Scanning System Volume 2 Issue 2 Horizon Scanning Status Report June 2020 Prepared for: Patient-Centered Outcomes Research Institute 1828 L St., NW, Suite 900 Washington, DC 20036 Contract No. MSA-HORIZSCAN-ECRI-ENG-2018.7.12 Prepared by: ECRI Institute 5200 Butler Pike Plymouth Meeting, PA 19462 Investigators: Randy Hulshizer, MA, MS Damian Carlson, MS Christian Cuevas, PhD Andrea Druga, PA-C Marcus Lynch, PhD Misha Mehta, MS Brian Wilkinson, MA Donna Beales, MLIS Jennifer De Lurio, MS Eloise DeHaan, BS Eileen Erinoff, MSLIS Madison Kimball, MS Maria Middleton, MPH Diane Robertson, BA Kelley Tipton, MPH Rosemary Walker, MLIS Karen Schoelles, MD, SM Statement of Funding and Purpose This report incorporates data collected during implementation of the Patient-Centered Outcomes Research Institute (PCORI) Health Care Horizon Scanning System, operated by ECRI Institute under contract to PCORI, Washington, DC (Contract No. MSA-HORIZSCAN-ECRI-ENG- 2018.7.12). The findings and conclusions in this document are those of the authors, who are responsible for its content. No statement in this report should be construed as an official position of PCORI. An intervention that potentially meets inclusion criteria might not appear in this report simply because the Horizon Scanning System has not yet detected it or it does not yet meet inclusion criteria outlined in the PCORI Health Care Horizon Scanning System: Horizon Scanning Protocol and Operations Manual. Inclusion or absence of interventions in the horizon scanning reports will change over time as new information is collected; therefore, inclusion or absence should not be construed as either an endorsement or rejection of specific interventions.