Microarray Screening Reveals a Non-Conventional SUMO-Binding Mode Linked to DNA Repair by Non-Homologous End-Joining
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Isoform-Specific Monobody Inhibitors of Small Ubiquitin-Related Modifiers Engineered Using Structure-Guided Library Design
Isoform-specific monobody inhibitors of small ubiquitin-related modifiers engineered using structure-guided library design Ryan N. Gilbretha, Khue Truongb, Ikenna Madub, Akiko Koidea, John B. Wojcika, Nan-Sheng Lia, Joseph A. Piccirillia,c, Yuan Chenb, and Shohei Koidea,1 aDepartment of Biochemistry and Molecular Biology, and cDepartment of Chemistry, University of Chicago, 929 East 57th Street, Chicago, IL 60637; and bDepartment of Molecular Medicine, Beckman Research Institute of the City of Hope, 1450 East Duarte Road, Duarte, CA 91010 Edited by David Baker, University of Washington, Seattle, WA, and approved March 16, 2011 (received for review February 10, 2011) Discriminating closely related molecules remains a major challenge which SUMOylation alters protein function appears to be in the engineering of binding proteins and inhibitors. Here we through SUMO-mediated interactions with other proteins con- report the development of highly selective inhibitors of small ubi- taining a short peptide motif known as a SUMO-interacting motif quitin-related modifier (SUMO) family proteins. SUMOylation is (SIM) (4, 7, 8). involved in the regulation of diverse cellular processes. Functional There are few inhibitors of SUMO/SIM interactions, a defi- differences between two major SUMO isoforms in humans, SUMO1 ciency that limits our ability to finely dissect SUMO biology. In and SUMO2∕3, are thought to arise from distinct interactions the only reported example of such an inhibitor, a SIM-containing mediated by each isoform with other proteins containing SUMO- linear peptide was used to inhibit SUMO/SIM interactions, estab- interacting motifs (SIMs). However, the roles of such isoform- lishing their importance in coordinating DNA repair by nonho- specific interactions are largely uncharacterized due in part to the mologous end joining (9). -

Table 2. Significant
Table 2. Significant (Q < 0.05 and |d | > 0.5) transcripts from the meta-analysis Gene Chr Mb Gene Name Affy ProbeSet cDNA_IDs d HAP/LAP d HAP/LAP d d IS Average d Ztest P values Q-value Symbol ID (study #5) 1 2 STS B2m 2 122 beta-2 microglobulin 1452428_a_at AI848245 1.75334941 4 3.2 4 3.2316485 1.07398E-09 5.69E-08 Man2b1 8 84.4 mannosidase 2, alpha B1 1416340_a_at H4049B01 3.75722111 3.87309653 2.1 1.6 2.84852656 5.32443E-07 1.58E-05 1110032A03Rik 9 50.9 RIKEN cDNA 1110032A03 gene 1417211_a_at H4035E05 4 1.66015788 4 1.7 2.82772795 2.94266E-05 0.000527 NA 9 48.5 --- 1456111_at 3.43701477 1.85785922 4 2 2.8237185 9.97969E-08 3.48E-06 Scn4b 9 45.3 Sodium channel, type IV, beta 1434008_at AI844796 3.79536664 1.63774235 3.3 2.3 2.75319499 1.48057E-08 6.21E-07 polypeptide Gadd45gip1 8 84.1 RIKEN cDNA 2310040G17 gene 1417619_at 4 3.38875643 1.4 2 2.69163229 8.84279E-06 0.0001904 BC056474 15 12.1 Mus musculus cDNA clone 1424117_at H3030A06 3.95752801 2.42838452 1.9 2.2 2.62132809 1.3344E-08 5.66E-07 MGC:67360 IMAGE:6823629, complete cds NA 4 153 guanine nucleotide binding protein, 1454696_at -3.46081884 -4 -1.3 -1.6 -2.6026947 8.58458E-05 0.0012617 beta 1 Gnb1 4 153 guanine nucleotide binding protein, 1417432_a_at H3094D02 -3.13334396 -4 -1.6 -1.7 -2.5946297 1.04542E-05 0.0002202 beta 1 Gadd45gip1 8 84.1 RAD23a homolog (S. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Uncovering Ubiquitin and Ubiquitin-Like Signaling Networks Alfred C
REVIEW pubs.acs.org/CR Uncovering Ubiquitin and Ubiquitin-like Signaling Networks Alfred C. O. Vertegaal* Department of Molecular Cell Biology, Leiden University Medical Center, Albinusdreef 2, 2333 ZA Leiden, The Netherlands CONTENTS 8. Crosstalk between Post-Translational Modifications 7934 1. Introduction 7923 8.1. Crosstalk between Phosphorylation and 1.1. Ubiquitin and Ubiquitin-like Proteins 7924 Ubiquitylation 7934 1.2. Quantitative Proteomics 7924 8.2. Phosphorylation-Dependent SUMOylation 7935 8.3. Competition between Different Lysine 1.3. Setting the Scenery: Mass Spectrometry Modifications 7935 Based Investigation of Phosphorylation 8.4. Crosstalk between SUMOylation and the and Acetylation 7925 UbiquitinÀProteasome System 7935 2. Ubiquitin and Ubiquitin-like Protein Purification 9. Conclusions and Future Perspectives 7935 Approaches 7925 Author Information 7935 2.1. Epitope-Tagged Ubiquitin and Ubiquitin-like Biography 7935 Proteins 7925 Acknowledgment 7936 2.2. Traps Based on Ubiquitin- and Ubiquitin-like References 7936 Binding Domains 7926 2.3. Antibody-Based Purification of Ubiquitin and Ubiquitin-like Proteins 7926 1. INTRODUCTION 2.4. Challenges and Pitfalls 7926 Proteomes are significantly more complex than genomes 2.5. Summary 7926 and transcriptomes due to protein processing and extensive 3. Ubiquitin Proteomics 7927 post-translational modification (PTM) of proteins. Hundreds ff fi 3.1. Proteomic Studies Employing Tagged of di erent modi cations exist. Release 66 of the RESID database1 (http://www.ebi.ac.uk/RESID/) contains 559 dif- Ubiquitin 7927 ferent modifications, including small chemical modifications 3.2. Ubiquitin Binding Domains 7927 such as phosphorylation, acetylation, and methylation and mod- 3.3. Anti-Ubiquitin Antibodies 7927 ification by small proteins, including ubiquitin and ubiquitin- 3.4. -

Supp Material.Pdf
Simon et al. Supplementary information: Table of contents p.1 Supplementary material and methods p.2-4 • PoIy(I)-poly(C) Treatment • Flow Cytometry and Immunohistochemistry • Western Blotting • Quantitative RT-PCR • Fluorescence In Situ Hybridization • RNA-Seq • Exome capture • Sequencing Supplementary Figures and Tables Suppl. items Description pages Figure 1 Inactivation of Ezh2 affects normal thymocyte development 5 Figure 2 Ezh2 mouse leukemias express cell surface T cell receptor 6 Figure 3 Expression of EZH2 and Hox genes in T-ALL 7 Figure 4 Additional mutation et deletion of chromatin modifiers in T-ALL 8 Figure 5 PRC2 expression and activity in human lymphoproliferative disease 9 Figure 6 PRC2 regulatory network (String analysis) 10 Table 1 Primers and probes for detection of PRC2 genes 11 Table 2 Patient and T-ALL characteristics 12 Table 3 Statistics of RNA and DNA sequencing 13 Table 4 Mutations found in human T-ALLs (see Fig. 3D and Suppl. Fig. 4) 14 Table 5 SNP populations in analyzed human T-ALL samples 15 Table 6 List of altered genes in T-ALL for DAVID analysis 20 Table 7 List of David functional clusters 31 Table 8 List of acquired SNP tested in normal non leukemic DNA 32 1 Simon et al. Supplementary Material and Methods PoIy(I)-poly(C) Treatment. pIpC (GE Healthcare Lifesciences) was dissolved in endotoxin-free D-PBS (Gibco) at a concentration of 2 mg/ml. Mice received four consecutive injections of 150 μg pIpC every other day. The day of the last pIpC injection was designated as day 0 of experiment. -
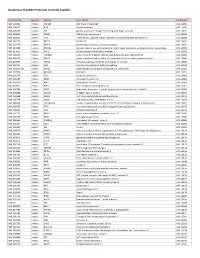
Quantigene Flowrna Probe Sets Currently Available
QuantiGene FlowRNA Probe Sets Currently Available Accession No. Species Symbol Gene Name Catalog No. NM_003452 Human ZNF189 zinc finger protein 189 VA1-10009 NM_000057 Human BLM Bloom syndrome VA1-10010 NM_005269 Human GLI glioma-associated oncogene homolog (zinc finger protein) VA1-10011 NM_002614 Human PDZK1 PDZ domain containing 1 VA1-10015 NM_003225 Human TFF1 Trefoil factor 1 (breast cancer, estrogen-inducible sequence expressed in) VA1-10016 NM_002276 Human KRT19 keratin 19 VA1-10022 NM_002659 Human PLAUR plasminogen activator, urokinase receptor VA1-10025 NM_017669 Human ERCC6L excision repair cross-complementing rodent repair deficiency, complementation group 6-like VA1-10029 NM_017699 Human SIDT1 SID1 transmembrane family, member 1 VA1-10032 NM_000077 Human CDKN2A cyclin-dependent kinase inhibitor 2A (melanoma, p16, inhibits CDK4) VA1-10040 NM_003150 Human STAT3 signal transducer and activator of transcripton 3 (acute-phase response factor) VA1-10046 NM_004707 Human ATG12 ATG12 autophagy related 12 homolog (S. cerevisiae) VA1-10047 NM_000737 Human CGB chorionic gonadotropin, beta polypeptide VA1-10048 NM_001017420 Human ESCO2 establishment of cohesion 1 homolog 2 (S. cerevisiae) VA1-10050 NM_197978 Human HEMGN hemogen VA1-10051 NM_001738 Human CA1 Carbonic anhydrase I VA1-10052 NM_000184 Human HBG2 Hemoglobin, gamma G VA1-10053 NM_005330 Human HBE1 Hemoglobin, epsilon 1 VA1-10054 NR_003367 Human PVT1 Pvt1 oncogene homolog (mouse) VA1-10061 NM_000454 Human SOD1 Superoxide dismutase 1, soluble (amyotrophic lateral sclerosis 1 (adult)) -

Heat Shock Factors: Integrators of Cell Stress, Development and Lifespan
REVIEWS Heat shock factors: integrators of cell stress, development and lifespan Malin Åkerfelt*‡, Richard I. Morimoto§ and Lea Sistonen*‡ Abstract | Heat shock factors (HSFs) are essential for all organisms to survive exposures to acute stress. They are best known as inducible transcriptional regulators of genes encoding molecular chaperones and other stress proteins. Four members of the HSF family are also important for normal development and lifespan-enhancing pathways, and the repertoire of HSF targets has thus expanded well beyond the heat shock genes. These unexpected observations have uncovered complex layers of post-translational regulation of HSFs that integrate the metabolic state of the cell with stress biology, and in doing so control fundamental aspects of the health of the proteome and ageing. Polytene chromosome In the early 1960s, Ritossa made the seminal discovery of shock response. Here, we present the recent discover- A chromosome that undergoes temperature-induced puffs in polytene chromosomes ies of novel target genes and physiological functions multiple rounds of DNA of Drosophila melanogaster larvae salivary glands1. of HSFs, which have changed the view that HSFs act replication, without cell A decade later, it was shown that the puffing pattern solely in the heat shock response. Based on the current division, and produces many sister chromatids that remain corresponded to a robust activation of genes encoding knowledge of small-molecule activators and inhibitors of synapsed together; for the heat shock proteins (HSPs), which function as HSFs, we also highlight the potential for pharmacologic example, in larval salivary molecular chaperones2. The heat shock response is a modulation of HSF-mediated gene regulation. -

Progress in the Discovery of Small Molecule Modulators of Desumoylation
Curr. Issues Mol. Biol. (2020) 35: 17-34. Progress in the Discovery of Small Molecule Modulators of DeSUMOylation Shiyao Chen, Duoling Dong, Weixiang Xin and Huchen Zhou* School of Pharmacy, Shanghai Jiao Tong University, Shanghai, China. *Correspondence: [email protected] htps://doi.org/10.21775/cimb.035.017 Abstract protein–protein interactions, gene transcription, SUMOylation and DeSUMOylation are reversible genome integrity, and DNA replication and repair protein post-translational modifcation (PTM) (Wilkinson and Henley, 2010; Vierstra, 2012; processes involving small ubiquitin-like modifer Bailey et al., 2016). In 1995, Meluh and Koshland (SUMO) proteins. Tese processes have indis- (1995) identifed Smt3 in Saccharomyces cerevi- pensable roles in various cellular processes, such siae, which is the earliest report within this fled. as subcellular localization, gene transcription, and Two years later, based on the sequence similarity DNA replication and repair. Over the past decade, between ubiquitin and a new 11.5-kDa protein, increasing atention has been given to SUMO- ubiquitin/SMT3, the name SUMO was formally related pathways as potential therapeutic targets. proposed for the frst time (Mahajan et al., 1997). Te Sentrin/SUMO-specifc protease (SENP), Although SUMO modifcation is closely which is responsible for deSUMOylation, has related to the progression of various diseases, such been proposed as a potential therapeutic target as cancers and cardiac disorders, it has aroused in the treatment of cancers and cardiac disorders. increasing atention as a potential therapeutic target Unfortunately, no SENP inhibitor has yet reached in recent years, especially concerning the Sentrin/ clinical trials. In this review, we focus on advances SUMO-specifc protease (SENP), which is the key in the development of SENP inhibitors in the past regulator of deSUMOylation. -

17 - 19 October 2019
THE 12TH INTERNATIONAL SYMPOSIUM ON HEALTH INFORMATICS AND BIOINFORMATICS T G T A A A T G A G A A G T T G G G T A A A A A A A A T T T A A A A A A G G A A A A A A A G G G G G G G G A A A G G G G G G T T G G G G G G G T T T T G G T T G G G T T T G G T A A T T G G T T T A A A A A A A A T T T A A A A A A T T A A A A A A A T A T T T T T T A A A T T T T G T A G A A T T T A A 17 - 19 OCTOBER 2019 HIBIT 2019 ABSTRACT BOOK THE 12TH INTERNATIONAL SYMPOSIUM ON HEALTH INFORMATICS AND BIOINFORMATICS TABLE OF CONTENTS 1 8 WELCOME MESSAGE KEYNOTE LECTURERS 2 19 ORGANIZING COMMITEE INVITED SPEAKERS 3 29 SCIENTIFIC COMMITEE SELECTED ABSTRACTS FOR ORAL PRESENTATIONS 6 61 PROGRAM POSTER PRESENTATIONS Welcome Message The International Symposium on Health Informatics and Bioinformatics, (HIBIT), now in its twelfth year HIBIT 2019, aims to bring together academics, researchers and practitioners who work in these popular and fulfilling areas and to create the much- needed synergy among medical, biological and information technology sectors. HIBIT is one of the few conferences emphasizing such synergy. -

Supp Table 6.Pdf
Supplementary Table 6. Processes associated to the 2037 SCL candidate target genes ID Symbol Entrez Gene Name Process NM_178114 AMIGO2 adhesion molecule with Ig-like domain 2 adhesion NM_033474 ARVCF armadillo repeat gene deletes in velocardiofacial syndrome adhesion NM_027060 BTBD9 BTB (POZ) domain containing 9 adhesion NM_001039149 CD226 CD226 molecule adhesion NM_010581 CD47 CD47 molecule adhesion NM_023370 CDH23 cadherin-like 23 adhesion NM_207298 CERCAM cerebral endothelial cell adhesion molecule adhesion NM_021719 CLDN15 claudin 15 adhesion NM_009902 CLDN3 claudin 3 adhesion NM_008779 CNTN3 contactin 3 (plasmacytoma associated) adhesion NM_015734 COL5A1 collagen, type V, alpha 1 adhesion NM_007803 CTTN cortactin adhesion NM_009142 CX3CL1 chemokine (C-X3-C motif) ligand 1 adhesion NM_031174 DSCAM Down syndrome cell adhesion molecule adhesion NM_145158 EMILIN2 elastin microfibril interfacer 2 adhesion NM_001081286 FAT1 FAT tumor suppressor homolog 1 (Drosophila) adhesion NM_001080814 FAT3 FAT tumor suppressor homolog 3 (Drosophila) adhesion NM_153795 FERMT3 fermitin family homolog 3 (Drosophila) adhesion NM_010494 ICAM2 intercellular adhesion molecule 2 adhesion NM_023892 ICAM4 (includes EG:3386) intercellular adhesion molecule 4 (Landsteiner-Wiener blood group)adhesion NM_001001979 MEGF10 multiple EGF-like-domains 10 adhesion NM_172522 MEGF11 multiple EGF-like-domains 11 adhesion NM_010739 MUC13 mucin 13, cell surface associated adhesion NM_013610 NINJ1 ninjurin 1 adhesion NM_016718 NINJ2 ninjurin 2 adhesion NM_172932 NLGN3 neuroligin -

Successful Implementation of Chip-Seq Quality Control At
Successful implementation of ChIP-seq Quality Control at Diagenode using automated ChIP protocol on the SX-8G IP-Star® Compact Jan Hendrickx, Géraldine Goens, Catherine D’andrea, Ignacio Mazon, Geoffrey Berguet, Sharon Squazzo, Céline Sabatel, Miklos Laczik, Dominique Poncelet. Diagenode sa, CHU, Tour GIGA B34, 3ème étage 1 Avenue de l’Hôpital, 4000 Liège, Sart-Tilman, Belgium Introduction Results Figure 3 ZNF12 Chromatin immunoprecipitation (ChIP) is the most widely used method to study protein-DNA We have validated 19 of the Diagenode ChIP-grade antibodies using ChIP-seq (see table 1). interactions. A successful ChIP, however, is largely depending on the use of well characterised, Scale 100 kb Figure 1 shows the profiles obtained with antibodies against (1) H3K4me3, H3K9ac and H3K9/14ac, chr7: 6620000 6630000 6640000 6650000 6660000 6670000 6680000 6690000 6700000 6710000 6720000 6730000 6740000 6750000 6760000 6770000 6780000 6790000 6800000 highly specific ChIP-grade antibodies. histone modifications that are present at active promoters, (2) H3K4me2 which is surrounding 35 - We have established a robust QC procedure to be able to provide researchers with the highest quality promoters of active genes, (3) H3K79me3 present at promoters of active genes and extending into H3K9me3 ChIP-grade antibodies. The recent development of high throughput sequencing (HTS) technologies the gene body, and (4) H3K36me3, present at the gene bodies of active genes. The screenshots below 1 _ has also opened new possibilities for epigenetic research. ChIP followed by HTS (ChIP-seq) enables show the peak distribution along the complete X-chromosome and in a 75 kb region surrounding the C7orf26 AK123300 ZNF12 PMS2CL RSPH10B C7orf26 ZNF12 RSPH10B the extension of the target directed analysis of ChIP results to a genome wide analysis. -

SUMO and Transcriptional Regulation: the Lessons of Large-Scale Proteomic, Modifomic and Genomic Studies
molecules Review SUMO and Transcriptional Regulation: The Lessons of Large-Scale Proteomic, Modifomic and Genomic Studies Mathias Boulanger 1,2 , Mehuli Chakraborty 1,2, Denis Tempé 1,2, Marc Piechaczyk 1,2,* and Guillaume Bossis 1,2,* 1 Institut de Génétique Moléculaire de Montpellier (IGMM), University of Montpellier, CNRS, Montpellier, France; [email protected] (M.B.); [email protected] (M.C.); [email protected] (D.T.) 2 Equipe Labellisée Ligue Contre le Cancer, Paris, France * Correspondence: [email protected] (M.P.); [email protected] (G.B.) Abstract: One major role of the eukaryotic peptidic post-translational modifier SUMO in the cell is transcriptional control. This occurs via modification of virtually all classes of transcriptional actors, which include transcription factors, transcriptional coregulators, diverse chromatin components, as well as Pol I-, Pol II- and Pol III transcriptional machineries and their regulators. For many years, the role of SUMOylation has essentially been studied on individual proteins, or small groups of proteins, principally dealing with Pol II-mediated transcription. This provided only a fragmentary view of how SUMOylation controls transcription. The recent advent of large-scale proteomic, modifomic and genomic studies has however considerably refined our perception of the part played by SUMO in gene expression control. We review here these developments and the new concepts they are at the origin of, together with the limitations of our knowledge. How they illuminate the SUMO-dependent Citation: Boulanger, M.; transcriptional mechanisms that have been characterized thus far and how they impact our view of Chakraborty, M.; Tempé, D.; SUMO-dependent chromatin organization are also considered.