Graphical Model for Baskeball Match Simulation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

O Klahoma City
MEDIA GUIDE O M A A H C L I K T Y O T R H U N D E 2 0 1 4 2 0 1 5 THUNDER.NBA.COM TABLE OF CONTENTS GENERAL INFORMATION ALL-TIME RECORDS General Information .....................................................................................4 Year-By-Year Record ..............................................................................116 All-Time Coaching Records .....................................................................117 THUNDER OWNERSHIP GROUP Opening Night ..........................................................................................118 Clayton I. Bennett ........................................................................................6 All-Time Opening-Night Starting Lineups ................................................119 2014-2015 OKLAHOMA CITY THUNDER SEASON SCHEDULE Board of Directors ........................................................................................7 High-Low Scoring Games/Win-Loss Streaks ..........................................120 All-Time Winning-Losing Streaks/Win-Loss Margins ...............................121 All times Central and subject to change. All home games at Chesapeake Energy Arena. PLAYERS Overtime Results .....................................................................................122 Photo Roster ..............................................................................................10 Team Records .........................................................................................124 Roster ........................................................................................................11 -

P18 3.E$S 4 Layout 1
THURSDAY, MAY 11, 2017 SPORTS India can be the next China for NBA: Top official NEW DELHI: While China is the National said on Tuesday. “With the availability of down to the D-League where he now games on their platform. We have an why they picked the Asian neighbors, Basketball Association’s biggest market these games and these competitions represents Texas Legends. India website now with localized con- also the world’s two most populous outside the United States, NBA Deputy from around the world, I think more and “There is a strong culture and history tent and we have extensive grassroots nations, Tatum said: “We have 113 play- Commissioner Mark Tatum has told more the sporting culture is starting to of playing the game of basketball in development programs which has ers from 41 different countries and terri- Reuters that India is ripe to grow the change. “Now is the time for a sport like China. What we are doing now is we’re reached six million kids and trained tories and not one from China, not one game as its changing sporting culture the NBA, a league like the NBA to contin- establishing that here in India. We really 5,000 coaches.” from India. It’s not that passion for the begins to offer its 1.3 billion people ue to grow our business here.” do believe that India will be the next All India needs now is its own Yao game is not there. In China 300 million alternatives to cricket. Speaking in an Basketball goes back 100 years in China for the NBA,” Tatum said. -

National Basketball Association
NATIONAL BASKETBALL ASSOCIATION OFFICIAL SCORER'S REPORT FINAL BOX Wednesday, October 25, 2017 AmericanAirlines Arena, Miami, FL Officials: #13 Monty McCutchen, #3 Nick Buchert, #68 Jacyn Goble Game Duration: 2:15 Attendance: 19600 (Sellout) VISITOR: San Antonio Spurs (4-0) POS MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS +/- PTS 1 Kyle Anderson F 27:16 4 8 0 0 4 6 1 9 10 2 1 1 0 0 5 12 12 LaMarcus Aldridge F 38:09 12 20 1 1 6 7 1 6 7 1 4 2 2 1 16 31 16 Pau Gasol C 19:00 5 8 0 1 3 4 1 8 9 0 2 1 3 1 1 13 14 Danny Green G 34:40 6 7 3 4 0 0 1 6 7 3 3 0 1 1 20 15 5 Dejounte Murray G 24:19 0 6 0 0 0 0 1 2 3 3 3 0 1 0 9 0 22 Rudy Gay 26:29 6 8 1 2 9 11 2 1 3 4 0 2 3 0 16 22 8 Patty Mills 25:55 1 4 1 2 0 0 0 1 1 4 1 0 3 0 3 3 20 Manu Ginobili 21:48 6 12 2 5 0 0 0 3 3 1 2 0 0 0 9 14 11 Bryn Forbes 03:06 0 0 0 0 0 0 0 0 0 0 1 0 0 0 -6 0 3 Brandon Paul 19:18 2 3 2 2 1 2 1 0 1 0 3 0 0 0 12 7 42 Davis Bertans DNP - Coach's decision 77 Joffrey Lauvergne NWT - Injury/Illness - Sprained Right Ankle 4 Derrick White DNP - Coach's decision 240:00 42 76 10 17 23 30 8 36 44 18 20 6 13 3 17 117 55.3% 58.8% 76.7% TM REB: 7 TOT TO: 13 (17 PTS) HOME: MIAMI HEAT (2-2) POS MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS +/- PTS 0 Josh Richardson F 33:00 1 8 0 4 4 4 2 3 5 3 6 3 3 0 -12 6 16 James Johnson F 36:01 8 14 1 3 4 4 0 9 9 4 4 1 4 0 -20 21 13 Bam Adebayo C 19:35 2 6 0 0 0 0 1 7 8 0 3 0 0 1 -12 4 11 Dion Waiters G 39:38 6 15 2 7 3 4 0 2 2 5 1 0 0 0 -10 17 7 Goran Dragic G 37:23 9 16 2 4 0 0 1 3 4 1 2 1 1 0 -12 20 8 Tyler Johnson 33:16 7 13 3 6 6 6 0 0 0 3 2 1 0 1 -7 23 9 Kelly Olynyk 12:07 2 3 1 1 0 0 0 2 2 1 2 0 1 0 2 5 20 Justise Winslow 22:24 2 5 0 1 0 0 0 1 1 1 3 0 0 0 -11 4 2 Wayne Ellington 06:18 0 0 0 0 0 0 0 1 1 1 2 0 0 0 -1 0 15 Okaro White 00:18 0 0 0 0 0 0 0 0 0 0 0 0 0 0 -2 0 40 Udonis Haslem DNP - Coach's decision 25 Jordan Mickey DNP - Coach's decision 12 Matt Williams Jr. -

Nfap Policy Brief » J U N E 2 0 1 4
NATIONALN A T I O N A L FOUNDATION FOR AMERICAN POLICY NFAP POLICY BRIEF » J U N E 2 0 1 4 IMMIGRANT CONTRIBUTIONS IN THE NBA AND MAJOR LEAGUE BASEBALL EXECUTIVE SUMMARY The 2014 NBA champion San Antonio Spurs are an example of how successful American enterprises today combine native-born and foreign-born talent to compete at the highest level. With 7 foreign-born players, the Spurs led the NBA with the most foreign-born players on their roster. Tony Parker (France), Boris Diaw (France) and Manu Ginobili (Argentina) played alongside Tim Duncan (U.S. Virgin Islands) and Kawhi Leonard (U.S.) to bring the team its 5th NBA championship since 1999. The San Antonio Spurs are part of a larger trend of globalization in the NBA. In the 2013-14 season, the National Basketball Association (NBA) set a record with 90 international players, representing 20 percent of the players on the opening-night NBA rosters, compared to 21 international players (and 5 percent of rosters) in 1992. Professional baseball started blending foreign-born players with native-born talent earlier than the NBA. On the 2014 Major League Baseball (MLB) opening-day roster there were 213 foreign-born players, representing 25 percent of the total, an increase of 2 percentage points from an NFAP analysis of MLB rosters performed in 2006. Leading foreign-born baseball players include 2013 American League MVP Miguel Cabrera, 2013 World Series MVP David Ortiz and Texas Rangers pitcher Yu Darvish. San Antonio Spurs Coach Gregg Popovich (l) with Tony Parker (c) and Manu Ginobili (r). -

PDF Numbers and Names
CeLoMiManca Checklist NBA 2018/2019 - Sticker & Card Collection 1 Oct. 28, 2017 - 17 - Jersey Away Jefferson 70 Jeremy Lamb Russell Westbrook 18 - 36 Kyrie Irving 54 Spencer Dinwiddie 71 Frank Kaminsky 2 Dec. 18, 2017 - Kobe 19 - 37 Jaylen Brown 55 Caris LeVert 72 James Borrego (head Bryant 20 - 38 Al Horford 56 Rondae Hollis- coach) 3 Lauri Markkanen Jefferson 21 - 39 Team Logo 73 Nicolas Batum 4 Jan. 30, 2018 - James 57 Shabazz Napier 22 a - Jersey Home / b - 40 Jason Tatum 74 a - Jersey Home / b - Harden Jersey Away 41 Gordon Hayward 58 Allen Crabbe Jersey Away 5 Feb. 15, 2018 - Nikola 23 Kent Bazemore 42 Marcus Morris 59 Kenny Atkinson 75 Robin Lopez Jokic (head coach) 24 Jeremy Lin 43 Jason Tatum 76 Bobby Portis 6 Feb. 28, 2018 - Dirk 60 D'Angelo Russell 77 Justin Holiday Nowitzki 25 Dewayne Dedmon 44 Terry Rozier 61 a - Jersey Home / b - 26 Team Logo 45 Marcus Smart 78 Team Logo 7 - Jersey Away 27 Taurean Prince 46 Brad Stevens (head 79 Lauri Markkanen 8 - 62 Nicolas Batum 28 De Andrè Bembry coach) 80 Kris Dunn 9 - 63 Tony Parker 29 John Collins 47 Kyrie Irving 81 Denzel Valentine 10 - 64 Cody Zeller 30 Kent Bazemore 48 a - Jersey Home / b - 82 Lauri Markkanen 11 - 65 Team Logo Jersey Away 83 Zach LaVine 12 - 31 Miles Plumlee 49 Jarrett Allen 66 Marvin Williams 32 Tyler Dorsey 84 Jabari Parker 13 - 67 Michael Kidd- 50 DeMarre Carroll 85 Fred Hoiberg (head 14 - 33 Lloyd Pierce (head Gilchrist coach) 51 D'Angelo Russell coach) 15 - 68 Kemba Walker 34 John Collins 52 Team Logo 86 Zach LaVine 16 - 69 Kemba Walker 35 a - Jersey Home -

Administration of Barack Obama, 2015 Remarks Honoring the 2014
Administration of Barack Obama, 2015 Remarks Honoring the 2014 National Basketball Association Champion San Antonio Spurs January 12, 2015 The President. Well, hello, everybody! Welcome to the White House. Everybody, please have a seat. In case you didn't know, these are the NBA Champion San Antonio Spurs. I was considering having the Vice President cover these remarks so I could stay fresh for the State of the Union. [Laughter] Taking an example off Pop, who sits his stars sometimes—[laughter]— but I decided I actually wanted to meet them. So I know we've got a lot of Spurs fans in the house—no doubt—including a guy I stole from San Antonio, our Secretary of Housing and Urban Development, former Mayor Julián Castro. [Applause] Hey! And of course we want to welcome General Manager R.C. Buford and, of course, Coach Popovich. I want the coach to know that he is not contractually obligated to take questions after the first quarter of my remarks. [Laughter] Now, look, I admit it, I'm a Bulls fan. It's never easy celebrating a non-Bulls team in the White House. [Laughter] That's all I've been able to do—[laughter]—so far. But even I have to admit that the Spurs are hard to dislike. First of all, they're old. [Laughter] And for an old guy, it makes me feel good to see—where's Tim? [Laughter] Tim's got some gray. There's a few others with a little sprinkles around here. There's a reason why the uniform is black and silver. -

Rosters Set for 2014-15 Nba Regular Season
ROSTERS SET FOR 2014-15 NBA REGULAR SEASON NEW YORK, Oct. 27, 2014 – Following are the opening day rosters for Kia NBA Tip-Off ‘14. The season begins Tuesday with three games: ATLANTA BOSTON BROOKLYN CHARLOTTE CHICAGO Pero Antic Brandon Bass Alan Anderson Bismack Biyombo Cameron Bairstow Kent Bazemore Avery Bradley Bojan Bogdanovic PJ Hairston Aaron Brooks DeMarre Carroll Jeff Green Kevin Garnett Gerald Henderson Mike Dunleavy Al Horford Kelly Olynyk Jorge Gutierrez Al Jefferson Pau Gasol John Jenkins Phil Pressey Jarrett Jack Michael Kidd-Gilchrist Taj Gibson Shelvin Mack Rajon Rondo Joe Johnson Jason Maxiell Kirk Hinrich Paul Millsap Marcus Smart Jerome Jordan Gary Neal Doug McDermott Mike Muscala Jared Sullinger Sergey Karasev Jannero Pargo Nikola Mirotic Adreian Payne Marcus Thornton Andrei Kirilenko Brian Roberts Nazr Mohammed Dennis Schroder Evan Turner Brook Lopez Lance Stephenson E'Twaun Moore Mike Scott Gerald Wallace Mason Plumlee Kemba Walker Joakim Noah Thabo Sefolosha James Young Mirza Teletovic Marvin Williams Derrick Rose Jeff Teague Tyler Zeller Deron Williams Cody Zeller Tony Snell INACTIVE LIST Elton Brand Vitor Faverani Markel Brown Jeffery Taylor Jimmy Butler Kyle Korver Dwight Powell Cory Jefferson Noah Vonleh CLEVELAND DALLAS DENVER DETROIT GOLDEN STATE Matthew Dellavedova Al-Farouq Aminu Arron Afflalo Joel Anthony Leandro Barbosa Joe Harris Tyson Chandler Darrell Arthur D.J. Augustin Harrison Barnes Brendan Haywood Jae Crowder Wilson Chandler Caron Butler Andrew Bogut Kentavious Caldwell- Kyrie Irving Monta Ellis -
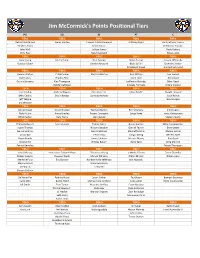
Jim Mccormick's Points Positional Tiers
Jim McCormick's Points Positional Tiers PG SG SF PF C TIER 1 TIER 1 TIER 1 TIER 1 TIER 1 Russell Westbrook James Harden Giannis Antetokounmpo Anthony Davis Karl-Anthony Towns Stephen Curry Kevin Durant DeMarcus Cousins John Wall LeBron James Rudy Gobert Chris Paul Kawhi Leonard Nikola Jokic TIER 2 TIER 2 TIER 2 TIER 2 TIER 2 Kyrie Irving Jimmy Butler Paul George Myles Turner Hassan Whiteside Damian Lillard Gordon Hayward Blake Griffin DeAndre Jordan Draymond Green Andre Drummond TIER 3 TIER 3 TIER 3 TIER 3 TIER 3 Kemba Walker CJ McCollum Khris Middleton Paul Millsap Joel Embiid Kyle Lowry Bradley Beal Kevin Love Al Horford Dennis Schroder Klay Thompson LaMarcus Aldridge Marc Gasol DeMar DeRozan Kirstaps Porzingis Nikola Vucevic TIER 4 TIER 4 TIER 4 TIER 4 TIER 4 Jrue Holiday Andrew Wiggins Otto Porter Jr. Julius Randle Dwight Howard Mike Conley Devin Booker Carmelo Anthony Jusuf Nurkic Jeff Teague Brook Lopez Eric Bledsoe TIER 5 TIER 5 TIER 5 TIER 5 TIER 5 Goran Dragic Victor Oladipo Harrison Barnes Ben Simmons Clint Capela Ricky Rubio Avery Bradley Robert Covington Serge Ibaka Jonas Valanciunas Elfrid Payton Gary Harris Jae Crowder Steven Adams TIER 6 TIER 6 TIER 6 TIER 6 TIER 6 D'Angelo Russell Evan Fournier Tobias Harris Aaron Gordon Willy Hernangomez Isaiah Thomas Wilson Chandler Derrick Favors Enes Kanter Dennis Smith Jr. Danilo Gallinari Markieff Morris Marcin Gortat Lonzo Ball Trevor Ariza Gorgui Dieng Nerlens Noel Rajon Rondo James Johnson Marcus Morris Pau Gasol George Hill Nicolas Batum Dario Saric Greg Monroe Patrick Beverley -

Annual Report 2009/2010
BASKETBALL AUSTRALIA ANNUAL REPORT 2009/2010 Basketball Australia Annual Report 2009/2010 WWW.BASKETBALL.NET.AU I BASKETBALL AUSTRALIA ANNUAL REPORT 2009/2010 Message from the Australian Sports Commission It is an honour to serve as the new Chair of the Australian Sports Commission (ASC) Board at this challenging and exciting period for our national sporting system. The ASC and national sporting organisations This is the first time key sport partners, such (NSOs) have long spoken of a shared ambition as state and territory institutes and academies to strengthen relationships between all system of sport and state and territory departments partners involved in Australian sport. of sport and recreation, have collaborated on a Commonwealth funding decision in the Aligned with this ambition, the Australian interests of Australia’s sporting future. Government is now encouraging a whole-of- sport reform agenda, aimed at establishing a This is an exciting time for all of us involved in more collaborative, efficient and integrated Australian sport. With significant new funding sports system. from the Australian Government, sports will be better positioned than ever before to lead the Through new direction for sport ‘Australian drive for higher participation levels and strong Sport: the Pathway to Success’, the ASC will success on the sporting field by promoting the work closely with sport to achieve its main unique nature of their sport, creating a legacy objectives; boost sports participation and and a lasting impression for communities strengthen -

Top-Ranked Hastings Falls in NAIA D-II Tournament SIOUX CITY, Iowa — It May Have Taken Shawnee State (Ohio) Saturday at 1 P.M
www.yankton.net Yankton Daily Press & Dakotan ■ Saturday, March 13, 2010 PAGE 9A Top-Ranked Hastings Falls In NAIA D-II Tournament SIOUX CITY, Iowa — It may have taken Shawnee State (Ohio) Saturday at 1 p.m. National Championship. In the loss for the Mustangs (21-12), Tanaeya Pueblo rallied from an 11 point second half deficit to seven years, but Grand View (Iowa) was Hastings’ season ends with a record of The Red Raiders, now 28-6 on the season, advance Worden finish with 26. Leslie Foral recorded 13 points shock the second-seeded Wildcats 59-48 Friday after- to the quarterfinals for the third straight year and will and Bobbi McManaman chipped in 11. noon in the first round of the NCAA Division II Central able to get revenge against Hastings 31-4. square off against Iowa Wesleyan Saturday at 3 p.m. IND. WESLEYAN 58, BLACK HILLS STATE 50: Regional Women’s Basketball Tournament in Durango, (Neb.) with a 69-61 second-round victory For Grand View, Jennifer Jorgensen Sterling's 14th national championship appearance ends SIOUX CITY, Iowa — The ability to knock down free Colo. Friday at the NAIA Division II Women's finished the game with 21 points and 13 in the second round and the Warriors exit at 27-5. throws with time winding down was a key factor in The ThunderWolves advance to Saturday’s semifi- Basketball National Championship on rebounds. Play down low was also all Northwestern with 51 Indiana Wesleyan’s 58-50 second-round win over Black nals with a 21-10 record while ending Wayne State’s Friday afternoon. -

This Day in Hornets History
THIS DAY IN HORNETS HISTORY January 1, 2005 – Emeka Okafor records his 19th straight double-double, the longest double-double streak by a rookie since 12-time NBA All-Star Elvin Hayes registered 60 straight during the 1968-69 season. January 2, 1998 – Glen Rice scores 42 points, including a franchise-record-tying 28 in the second half, in a 99-88 overtime win over Miami. January 3, 1992 – Larry Johnson becomes the first Hornets player to be named NBA Rookie of the Month, winning the award for the month of December. January 3, 2002 – Baron Davis records his third career triple-double in a 114-102 win over Golden State. January 3, 2005 – For the second time in as many months, Emeka Okafor earns the Eastern Conference Rookie of the Month award for the month of December 2004. January 6, 1997 – After being named NBA Player of the Week earlier in the day, Glen Rice scores 39 points to lead the Hornets to a 109-101 win at Golden State. January 7, 1995 – Alonzo Mourning tallies 33 points and 13 rebounds to lead the Hornets to the 200th win in franchise history, a 106-98 triumph over the Boston Celtics at the Hive. January 7, 1998 – David Wesley steals the ball and hits a jumper with 2.2 seconds left to lift the Hornets to a 91-89 win over Portland. January 7, 2002 – P.J. Brown grabs a career-high 22 rebounds in a 94-80 win over Denver. January 8, 1994 – The Hornets beat the Knicks for the second time in six days, erasing a 20-2 first quarter deficit en route to a 102-99 win. -

NBA's REVIVAL IS PURE MAGIC by Michael Wilbon
NEWSLETTER #23 - 2005-06 NBA'S REVIVAL IS PURE MAGIC By Michael Wilbon Don't get me wrong, the NBA has had great teams since Michael Jordan retired from the Chicago Bulls after the 1997-98 season. The San Antonio Spurs teams, particularly the ones with Tim Duncan and David Robinson, could hold their own in any era. The Lakers of Phil Jackson, Shaquille O'Neal and Kobe Bryant were, at times, dominating and entertaining. And although great team play usually is enough to maximize interest in pro football and Major League Baseball, that simply isn't the case with professional basketball. The NBA has been, is now, and probably always will be a league driven by and dependent on its star power. It's been that way from Mikan and Cousy to Russell and Chamberlain to Oscar and West to Kareem and Julius to Bird and Magic to Sir Charles and M.J. to Shaq and Kobe. The greatest team in NBA history -- the 1992 Dream Team -- never even played a single league contest or a game of consequence on U.S. soil but was the most star-studded team ever put together anywhere. So there's a very easy answer to the questions of why these NBA playoffs have been so compelling, why TV ratings have been up and why there's a buzz about the NBA Finals in a way there hasn't been since Jordan's second retirement. After seven seasons of trying to convince fans that certain players were stars, the league has enjoyed a postseason where its most recognizable players led teams into the playoffs, then played the way stars historically have in the NBA.