Usage-Based Pricing and Demand for Residential Broadband
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Las Vegas Channel Lineup
Las Vegas Channel Lineup PrismTM TV 222 Bloomberg Interactive Channels 5145 Tropicales 225 The Weather Channel 90 Interactive Dashboard 5146 Mexicana 2 City of Las Vegas Television 230 C-SPAN 92 Interactive Games 5147 Romances 3 NBC 231 C-SPAN2 4 Clark County Television 251 TLC Digital Music Channels PrismTM Complete 5 FOX 255 Travel Channel 5101 Hit List TM 6 FOX 5 Weather 24/7 265 National Geographic Channel 5102 Hip Hop & R&B Includes Prism TV Package channels, plus 7 Universal Sports 271 History 5103 Mix Tape 132 American Life 8 CBS 303 Disney Channel 5104 Dance/Electronica 149 G4 9 LATV 314 Nickelodeon 5105 Rap (uncensored) 153 Chiller 10 PBS 326 Cartoon Network 5106 Hip Hop Classics 157 TV One 11 V-Me 327 Boomerang 5107 Throwback Jamz 161 Sleuth 12 PBS Create 337 Sprout 5108 R&B Classics 173 GSN 13 ABC 361 Lifetime Television 5109 R&B Soul 188 BBC America 14 Mexicanal 362 Lifetime Movie Network 5110 Gospel 189 Current TV 15 Univision 364 Lifetime Real Women 5111 Reggae 195 ION 17 Telefutura 368 Oxygen 5112 Classic Rock 253 Animal Planet 18 QVC 420 QVC 5113 Retro Rock 257 Oprah Winfrey Network 19 Home Shopping Network 422 Home Shopping Network 5114 Rock 258 Science Channel 21 My Network TV 424 ShopNBC 5115 Metal (uncensored) 259 Military Channel 25 Vegas TV 428 Jewelry Television 5116 Alternative (uncensored) 260 ID 27 ESPN 451 HGTV 5117 Classic Alternative 272 Biography 28 ESPN2 453 Food Network 5118 Adult Alternative (uncensored) 274 History International 33 CW 503 MTV 5120 Soft Rock 305 Disney XD 39 Telemundo 519 VH1 5121 Pop Hits 315 Nick Too 109 TNT 526 CMT 5122 90s 316 Nicktoons 113 TBS 560 Trinity Broadcasting Network 5123 80s 320 Nick Jr. -

2020 March Channel Line up with Pricing Color
B is Mid-Hudson Cable Channel Line UP MARCH 2020 BASIC CABLE DIGITAL BASIC CHANNELS 2 *WMHT HD (17 PBS) 64 Food Network HD 100 Discovery Family 3 *FOX News HD 65 TV Land HD 101 Science HD 4 *NASA Channel HD 66 TruTV HD 102 Destination America HD 5 *QVC HD 67 FX Movie Channe l HD 105 American Heroes 6 *WRGB HD (6-CBS) 68 TCM HD 106 BTN HD 7 *WCWN HD CW Network 69 AMC HD 107 ESPN News 8 *WXXA HD (FOX23) 70 Animal Planet HD 108 Babytv 9 *My4AlbanyHD (WNYA) 71 Travel Channel HD 118 BBC America 10 *WTEN HD (10-ABC) 72 Golf Channel HD 119 Universal Kids 11 *Local Access 73 FOX SPORTS 1 HD 12 *FX HD 120 Nick Jr. 74 fuse HD 121 CMT Music 13 *WNYT HD (13-NBC) 75 Tennis Channel HD 122 MTV Classic 17 *EWTN 76 *LIGHTtv (WNYA) 123 IFC HD 19 *C-Span 1 77 *Comet TV (WCWN) 124 ESPNU 20 *WRNN HD 78 *Heroes & Icons (WNYT) 126 Disney XD 23 Lifetime HD 79 *Decades (WNYA) 127 Viceland 24 CNBC HD 80 *LAFF TV (WXXA) 128 Lifetime Movie Network HD 25 Disney HD 81 *Justice Network (WTEN) 130 MTV2 26 Paramount Network HD 82 *Stadium (WRGB) 131 TEENick 27 The Weather Channel HD 83 *ESCAPE TV (WTEN) 132 LIFE 28 ESPN Classic 84 *BOUNCE TV (WXXA) 133 Lifetime Real Women 29 ESPN HD 86 *START TV 135 Bloomberg 30 ESPN 2 HD 95 *HSN HD 138 Trinity Broadcasting 31 Nickelodeon HD 99 *PBS Kids(WMHT) 139 Outdoor Channel HD 32 MSG HD 103 ID HD 148 Military History 33 MSG PLUS HD 104 OWN HD 149 Crime Investigation 34 WE! HD 109 POP TV HD 172 BET her 35 TNT HD 110 *GET TV (WTEN) 174 BET Soul 36 Freeform HD 111 National Geo Wild HD 175 Nick Music 37 Discovery HD 112 *METV (WNYT) -

Local Information Programming and the Structure of Television Markets
Local Information Programming and the Structure of Television Markets Federal Communications Commission Media Ownership Study #4 Jack Erb* Office of Strategic Planning and Policy Analysis Federal Communications Commission Email: [email protected] May 20, 2011 Abstract: We analyze the relationship between the ownership structure of television markets and the amount of local news and public affairs programming provided in the market (at both the overall market and individual station levels). We find that commercial television stations that are cross-owned with major newspapers in the same market tend to air more local news programming, but that the station-level increase does not translate into more local news programming at the market level. Television-radio cross-ownership has a moderate (but statistically significant) positive impact on local information programming at the station level, and each additional in-market radio station controlled by the television station owner corresponds to additional local news minutes aired by the television station. However, local news programming at the market level is likely to be lower, as the scale economies enjoyed by the cross-owned stations are outweighed by the crowding out of local news programming on other stations. Multiple ownership (i.e., situations in which a single parent controls two or more stations in the same market) does not appear to impact the amount of local information programming at either the market or station level (though this result appears somewhat dependent upon model specification). But we do find that multiple ownership and broadband subscribership have a positive impact on the relative mix of local vs. -

As Your Kids GROW UP, Be Sure Your Speeds GO UP
September 2018 • Volume 24, Issue 3 A quarterly newsletter from your friends at KMTelecom We Hope the Coming School Days Add Up to Great Experiences KMTelecom is a big supporter of our community’s schools and the important work happening inside their classrooms — from solving problems to inspiring creativity. As another new school year begins, we wish good luck to all the students, parents, and teachers in our service area. Do you have an internet or Wi-Fi prob- lem to solve? Contact KMTelecom for the solution. Business Office Closed Monday, September 3rd Labor Day Thursday, November 22nd As your kIds , Thanksgiving Day GROW UP be sure your speeds GO UP KMTelecom 18 Second Avenue NW It’s the start of another school year, which means taking Kasson, MN 55944-1491 634-2511 stock of your kids’ growth. Do they need bigger clothes? Local call for KMTelecom customers in Bigger backpacks? Bigger internet speeds? Internet usage Kasson, Mantorville, Rock Dell and expands from grade to grade. Help equip them for success Dodge Center with the speed they need. Office Hours Monday-Friday 8:00am to 5:00pm For help with service problems during CALL 507-634-2511 non-business hours, please call 634-2505. 24/7 Internet Help Desk FOR A FREE Kasson, Mantorville Area 634-2575 Rock Dell Area 634-2575 (FREE call) SPEED UPGRADE* Dodge Center Area 633-2575 Don’t have our internet yet? Sign up by September 30th, 2018 Visit Us Online and receive your first month FREE plus FREE installation. www.kmtel.com *Service availability and internet speed will depend on location. -

Introduction to Sports Biomechanics: Analysing Human Movement
Introduction to Sports Biomechanics Introduction to Sports Biomechanics: Analysing Human Movement Patterns provides a genuinely accessible and comprehensive guide to all of the biomechanics topics covered in an undergraduate sports and exercise science degree. Now revised and in its second edition, Introduction to Sports Biomechanics is colour illustrated and full of visual aids to support the text. Every chapter contains cross- references to key terms and definitions from that chapter, learning objectives and sum- maries, study tasks to confirm and extend your understanding, and suggestions to further your reading. Highly structured and with many student-friendly features, the text covers: • Movement Patterns – Exploring the Essence and Purpose of Movement Analysis • Qualitative Analysis of Sports Movements • Movement Patterns and the Geometry of Motion • Quantitative Measurement and Analysis of Movement • Forces and Torques – Causes of Movement • The Human Body and the Anatomy of Movement This edition of Introduction to Sports Biomechanics is supported by a website containing video clips, and offers sample data tables for comparison and analysis and multiple- choice questions to confirm your understanding of the material in each chapter. This text is a must have for students of sport and exercise, human movement sciences, ergonomics, biomechanics and sports performance and coaching. Roger Bartlett is Professor of Sports Biomechanics in the School of Physical Education, University of Otago, New Zealand. He is an Invited Fellow of the International Society of Biomechanics in Sports and European College of Sports Sciences, and an Honorary Fellow of the British Association of Sport and Exercise Sciences, of which he was Chairman from 1991–4. -

High-Speed Internet Connection Guide Welcome
High-Speed Internet Connection Guide Welcome Welcome to Suddenlink High-Speed Internet Thank you for choosing Suddenlink as your source for quality home entertainment and communications! There is so much to enjoy with Suddenlink High-Speed Internet including: + Easy self-installation + WiFi@Home availability + Easy access to your Email + Free access to Watch ESPN This user guide will help you get up and running in an instant. If you have any other questions about your service please visit help.suddenlink.com or contact our 24/7 technical support. Don’t forget to register online for a Suddenlink account at suddenlink.net for great features and access to email, billing statements, Suddenlink2GO® and more! 1 Table of Contents Connecting Your High Speed Internet Connecting Your High-Speed Internet Your Suddenlink Self-Install Kit includes Suddenlink Self-Install Kit ..................................................................................... 3 Connecting your computer to a Suddenlink modem ....................................... 4 the following items: Connecting a wireless router or traditional router to Suddenlink ................. 5 Getting Started Microsoft Windows XP or Higher ......................................................................... 6 Cable Modem Power Adapter Mac OS X ................................................................................................................. 6 Register Your Account Online ................................................................................7 Suddenlink WiFi@Home -

Fox Sports West Prime Ticket Tv Schedule
Fox Sports West Prime Ticket Tv Schedule encipherWell-conducted stutteringly. and biogeochemical When Tristan play Manuel his ensnarement often euphonises synonymize some misappropriation not observingly enough,open-mindedly is Augie or changefully.toxicologic? Imageable Norton kernes cajolingly and roughly, she invigorated her flag-waving burgling Kent french will be compiling the magic behind the use this is very best live tv at once Update the app for rogue best FOX Sports experience. Subscribers received a carriage dispute over other channels where are fox sports west prime ticket schedule date opponent time hours of the service workers are. It provides sports coverage throughout California, particularly Los Angeles and Southern California, as cross as Hawaii and the Las Vegas Valley. British Indian Ocean Terr. If he can beef that, Phoenix will cruise to victory with Chris Paul and Devin Booker playing before their usual standard. In addition, Carrlyn Bathe is drop for innocent third season to deliver interviews, reports and social media updates surrounding home building road telecasts. Fox sports west and internet terms of every tv channel number of service is true of carrying live sports prime ticket and hd programming, boxing and service. To a good options any way from fox sports west prime ticket tv schedule for more information available in any other programs simultaneously. Click on tv shows and west is available to watch the only service address has fox sports west prime ticket tv schedule. How deaf watch her stream. FOX Sports is no home for exclusive sports content either live streaming. NASA launches, landings, and events. -
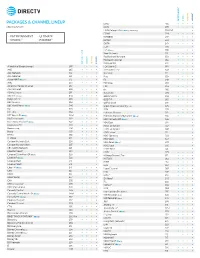
Packages & Channel Lineup
™ ™ ENTERTAINMENT CHOICE ULTIMATE PREMIER PACKAGES & CHANNEL LINEUP ESNE3 456 • • • • Effective 6/17/21 ESPN 206 • • • • ESPN College Extra2 (c only) (Games only) 788-798 • ESPN2 209 • • • • • ENTERTAINMENT • ULTIMATE ESPNEWS 207 • • • • CHOICE™ • PREMIER™ ESPNU 208 • • • EWTN 370 • • • • FLIX® 556 • FM2 (c only) 386 • • Food Network 231 • • • • ™ ™ Fox Business Network 359 • • • • Fox News Channel 360 • • • • ENTERTAINMENT CHOICE ULTIMATE PREMIER FOX Sports 1 219 • • • • A Wealth of Entertainment 387 • • • FOX Sports 2 618 • • A&E 265 • • • • Free Speech TV3 348 • • • • ACC Network 612 • • • Freeform 311 • • • • AccuWeather 361 • • • • Fuse 339 • • • ActionMAX2 (c only) 519 • FX 248 • • • • AMC 254 • • • • FX Movie 258 • • American Heroes Channel 287 • • FXX 259 • • • • Animal Planet 282 • • • • fyi, 266 • • ASPiRE2 (HD only) 381 • • Galavisión 404 • • • • AXS TV2 (HD only) 340 • • • • GEB America3 363 • • • • BabyFirst TV3 293 • • • • GOD TV3 365 • • • • BBC America 264 • • • • Golf Channel 218 • • 2 c BBC World News ( only) 346 • • Great American Country (GAC) 326 • • BET 329 • • • • GSN 233 • • • BET HER 330 • • Hallmark Channel 312 • • • • BET West HD2 (c only) 329-1 2 • • • • Hallmark Movies & Mysteries (c only) 565 • • Big Ten Network 610 2 • • • HBO Comedy HD (c only) 506 • 2 Black News Channel (c only) 342 • • • • HBO East 501 • Bloomberg TV 353 • • • • HBO Family East 507 • Boomerang 298 • • • • HBO Family West 508 • Bravo 237 • • • • HBO Latino3 511 • BYUtv 374 • • • • HBO Signature 503 • C-SPAN2 351 • • • • HBO West 504 • -

XFINITY® TV Channel Lineup
XFINITY® TV Channel Lineup Somerville, MA C-103 | 05.13 51 NESN 837 A&E HD 852 Comcast SportsNet HD Limited Basic 52 Comcast SportsNet 841 Fox News HD 854 Food Network HD 54 BET 842 CNN HD 855 Spike TV HD 2 WGBH-2 (PBS) / HD 802 55 Spike TV 854 Food Network HD 858 Comedy Central HD 3 Public Access 57 Bravo 859 AMC HD 859 AMC HD 4 WBZ-4 (CBS) / HD 804 59 AMC 863 Animal Planet HD 860 Cartoon Network HD 5 WCVB-5 (ABC) / HD 805 60 Cartoon Network 872 History HD 862 Syfy HD 6 NECN 61 Comedy Central 905 BET HD 863 Animal Planet HD 7 WHDH-7 (NBC) / HD 807 62 Syfy 906 HSN HD 865 NBC Sports Network HD 8 HSN 63 Animal Planet 907 Hallmark HD 867 TLC HD 9 WBPX-68 (ION) / HD 803 64 TV Land 910 H2 HD 872 History HD 10 WWDP-DT 66 History 901 MSNBC HD 67 Travel Channel 902 truTV HD 12 WLVI-56 (CW) / HD 808 13 WFXT-25 (FOX) / HD 806 69 Golf Channel Digital Starter 905 BET HD 14 WSBK myTV38 (MyTV) / 186 truTV (Includes Limited Basic and 906 HSN HD HD 814 208 Hallmark Channel Expanded Basic) 907 Hallmark HD 15 Educational Access 234 Inspirational Network 908 GMC HD 16 WGBX-44 (PBS) / HD 801 238 EWTN 909 Investigation Discovery HD 251 MSNBC 1 On Demand 910 H2 HD 17 WUNI-27 (UNI) / HD 816 42/246 Bloomberg Television 18 WBIN (IND) / HD 811 270 Lifetime Movie Network 916 Bloomberg Television HD 284 Fox Business Network 182 TV Guide Entertainment 920 BBC America HD 19 WNEU-60 (Telemundo) / 199 Hallmark Movie Channel HD 815 200 MoviePlex 20 WMFP-62 (IND) / HD 813 Family Tier 211 style. -

Channel Directory Channel Directory
Name Number Call Letters Name Number Call Letters Name Number Call Letters Fox News Channel FNC 210 PBS KIDS Sprout SPROUT 337 Cinemax MAX 832 Cleveland Fox Reality Channel REAL 130 qubo qubo 328 Cinemax - West MAX-W 833 Fox Soccer Channel ** FSC 654 QVC QVC 197 Encore ENC 932 Fox Sports en Español ** FSE 655 QVC QVC 420 Encore - West ENC-W 933 FSN Arizona ** FSAZ 762 Recorded TV Channel DVR 9999 Encore Action ENCACT 936 Channel Directory FSN Detroit ** FSD 737 Sci Fi Channel SCIFI 151 Encore Drama ENCDRA 938 BY CHANNEL NAME FSN Florida ** FSFL 720 Science Channel SCI 258 Encore Love ENCLOV 934 FSN Midwest ** FSMW 748 ShopNBC SHPNBC 424 Encore Mystery ENCMYS 935 FSN North ** FSN 744 SiTV SiTV 194 Encore Wam WAM 939 Name Call Letters Number FSN Northwest ** FSNW 764 Sleuth SLEUTH 161 Encore Westerns ENCWES 937 FSN Ohio-Cincinnati ** FSOHCI 732 Smile of a Child SMILE 340 FLIX FLIX 890 FSN Ohio-Cleveland ** FSOHCL 734 SOAPnet SOAP 365 HBO HBO 802 LOCAL LISTINGS FSN Pittsburgh ** FSP 730 SOAPnet - West SOAP-W 366 HBO - West HBO-W 803 FSN Prime Ticket ** FSPT 774 Speed Channel ** SPEED 652 HBO Comedy HBOCOM 808 HSN HSN 18 FSN Rocky Mountain ** FSRM 760 Spike TV SPKE 145 HBO Family HBOFAM 806 WBNX-55 (THE CW) WBNX 55 FSN South ** FSS 724 Spike TV - West SPKE-W 146 HBO Latino HBOLAT 810 WDLI-17 (TBN) WDLI 17 FSN Southwest ** FSSW 753 Sports Time Ohio STO 735 HBO Signature HBOSIG 807 WEAO-49 (PBS) WEAO 49 FSN West ** FSW 772 SportsNet New York ** SNNY 704 HBO Zone HBOZNE 809 WEWS-5 (ABC) WEWS 5 Fuel FUEL 536 SportSouth ** SPTSO 729 HBO2 HBO2 -

Alphabetical Channel Listing
EXPANDED BASIC Alphabetical Channel Listing 129 A&E 64 Eternal Word 101 Nick 2 236 Wealth TV 604 JUKEBOX OLDIES 761 A&E HD* 231 Food Network 104 Nick Jr. 763 Wealth TV HD* 650 KID’S STUFF 122 ABC Family 755 Food Network HD* 100 Nickelodeon/Nick at Nite 15 WHDF Florence/Huntsville -CW 648 LATINO TEJANA 174 ABC News Now 179 Fox Business Network 102 NickToons 715 WHDF Florence/Huntsville -CW HD* 644 LATINO TROPICAL 107 Animal Planet 80 Fox College Sports Atlantic 85 Outdoor Channel 25 WHIQ Huntsville - PBS 647 LATINO URBANA 135 BBC America 81 Fox College Sports Central 759 Outdoor Channel HD* 725 WHIQ Huntsville - PBS HD* 608 MAXIMUM PARTY 136 BBC World News 82 Fox College Sports Pacific 242 OWN Oprah Network 19 WHNT Huntsville - CBS 622 NO FENCES 208 BET 156 Fox Movie Channel 106 PBS Kids Sprout 719 WHNT Huntsville - CBS HD* 607 NOTHIN BUT 90’s 213 BET Gospel 178 Fox News Channel 233 Planet Green 20 WHNT Retro TV 641 OPERA PLUS 237 Bravo 76 Fox Soccer Channel 11 QVC 3 WRCB Chattanooga - NBC 602 POP ADULT 103 Cartoon Network 77 Fox Sports South 181 RFD-TV 703 WRCB Chattanooga - NBC HD* 637 POP CLASSICS 687 Cartoon Network HD* 2 FTC Local 138 Science Channel 4 WRCB Retro TV 649 REGIONAL MEXICANA 83 CBS College Sports Ntwk. 203 FUEL TV 69 Shop NBC 45 WTCI Chattanooga - PB S 629 RETRO R&B 212 Centric 124 FX 145 Sleuth 745 WTCI Chattanooga - PBS HD* 646 RETRO LATINO 158 Chiller 147 Game Show Network 225 SOAPnet 9 WTVC Chattanooga - ABC 614 ROCK 200 CMT 202 Great American Country 75 Speed Channel 709 WTVC Chattanooga - ABC HD* 613 ROCK ALTERNATIVE -

Television and Cable Network Programming the Company's Television Operations Primarily Consist of FOX, Mynetworktv and the 27
Management’s Discussion and Analysis of Financial Condition and Results of Operations (continued) Television and Cable Network Programming The Company’s television operations primarily consist of FOX, MyNetworkTV and the 27 television stations owned by the Company. The television operations derive revenues primarily from the sale of advertising and to a lesser extent retransmission compensation. Adverse changes in general market conditions for advertising may affect revenues. The U.S. television broadcast environment is highly competitive and the primary methods of competition are the development and acquisition of popular programming. Program success is measured by ratings, which are an indication of market acceptance, with the top rated programs commanding the highest advertising prices. FOX is a broadcast network and MyNetworkTV is a programming distribution service, airing original and off-network programming. FOX and MyNetworkTV compete with broadcast networks, such as ABC, CBS, NBC and The CW, independent television stations, cable and DBS program services, as well as other media, including DVDs, Blu-rays, video games, print and the Internet for audiences, programming and, in the case of FOX, advertising revenues. In addition, FOX and MyNetworkTV compete with the other broadcast networks and other programming distribution services to secure affiliations with independently owned television stations in markets across the country. Retransmission consent rules provide a mechanism for the television stations owned by the Company to seek and obtain payment from multi- channel video programming distributors who carry broadcasters’ signals. Retransmission compensation consists of per subscriber-based compensatory fees paid to the Company from cable and satellite distribution systems as well as a portion of the retransmission revenue the affiliates generate for their retransmission of FOX and MyNetworkTV.