Structural and Biophysical Characterization of Protocadherin Extracellular Regions Holly N. Wolcott Submitted in Partial Fulfill
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Genome-Wide Analysis of DNA Methylation In
Villalba‑Benito et al. Clin Epigenet (2021) 13:51 https://doi.org/10.1186/s13148‑021‑01040‑6 RESEARCH Open Access Genome‑wide analysis of DNA methylation in Hirschsprung enteric precursor cells: unraveling the epigenetic landscape of enteric nervous system development Leticia Villalba‑Benito1,2, Daniel López‑López3,4, Ana Torroglosa1,2, Carlos S. Casimiro‑Soriguer3,4, Berta Luzón‑Toro1,2, Raquel María Fernández1,2, María José Moya‑Jiménez5, Guillermo Antiñolo1,2, Joaquín Dopazo2,3,4 and Salud Borrego1,2* Abstract Background: Hirschsprung disease (HSCR, OMIM 142623) is a rare congenital disorder that results from a failure to fully colonize the gut by enteric precursor cells (EPCs) derived from the neural crest. Such incomplete gut coloniza‑ tion is due to alterations in EPCs proliferation, survival, migration and/or diferentiation during enteric nervous system (ENS) development. This complex process is regulated by a network of signaling pathways that is orchestrated by genetic and epigenetic factors, and therefore alterations at these levels can lead to the onset of neurocristopathies such as HSCR. The goal of this study is to broaden our knowledge of the role of epigenetic mechanisms in the disease context, specifcally in DNA methylation. Therefore, with this aim, a Whole‑Genome Bisulfte Sequencing assay has been performed using EPCs from HSCR patients and human controls. Results: This is the frst study to present a whole genome DNA methylation profle in HSCR and reveal a decrease of global DNA methylation in CpG context in HSCR patients compared with controls, which correlates with a greater hypomethylation of the diferentially methylated regions (DMRs) identifed. -

Functional Parsing of Driver Mutations in the Colorectal Cancer Genome Reveals Numerous Suppressors of Anchorage-Independent
Supplementary information Functional parsing of driver mutations in the colorectal cancer genome reveals numerous suppressors of anchorage-independent growth Ugur Eskiocak1, Sang Bum Kim1, Peter Ly1, Andres I. Roig1, Sebastian Biglione1, Kakajan Komurov2, Crystal Cornelius1, Woodring E. Wright1, Michael A. White1, and Jerry W. Shay1. 1Department of Cell Biology, University of Texas Southwestern Medical Center, 5323 Harry Hines Boulevard, Dallas, TX 75390-9039. 2Department of Systems Biology, University of Texas M.D. Anderson Cancer Center, Houston, TX 77054. Supplementary Figure S1. K-rasV12 expressing cells are resistant to p53 induced apoptosis. Whole-cell extracts from immortalized K-rasV12 or p53 down regulated HCECs were immunoblotted with p53 and its down-stream effectors after 10 Gy gamma-radiation. ! Supplementary Figure S2. Quantitative validation of selected shRNAs for their ability to enhance soft-agar growth of immortalized shTP53 expressing HCECs. Each bar represents 8 data points (quadruplicates from two separate experiments). Arrows denote shRNAs that failed to enhance anchorage-independent growth in a statistically significant manner. Enhancement for all other shRNAs were significant (two tailed Studentʼs t-test, compared to none, mean ± s.e.m., P<0.05)." ! Supplementary Figure S3. Ability of shRNAs to knockdown expression was demonstrated by A, immunoblotting for K-ras or B-E, Quantitative RT-PCR for ERICH1, PTPRU, SLC22A15 and SLC44A4 48 hours after transfection into 293FT cells. Two out of 23 tested shRNAs did not provide any knockdown. " ! Supplementary Figure S4. shRNAs against A, PTEN and B, NF1 do not enhance soft agar growth in HCECs without oncogenic manipulations (Student!s t-test, compared to none, mean ± s.e.m., ns= non-significant). -

Supplementary Table 1: Adhesion Genes Data Set
Supplementary Table 1: Adhesion genes data set PROBE Entrez Gene ID Celera Gene ID Gene_Symbol Gene_Name 160832 1 hCG201364.3 A1BG alpha-1-B glycoprotein 223658 1 hCG201364.3 A1BG alpha-1-B glycoprotein 212988 102 hCG40040.3 ADAM10 ADAM metallopeptidase domain 10 133411 4185 hCG28232.2 ADAM11 ADAM metallopeptidase domain 11 110695 8038 hCG40937.4 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 195222 8038 hCG40937.4 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 165344 8751 hCG20021.3 ADAM15 ADAM metallopeptidase domain 15 (metargidin) 189065 6868 null ADAM17 ADAM metallopeptidase domain 17 (tumor necrosis factor, alpha, converting enzyme) 108119 8728 hCG15398.4 ADAM19 ADAM metallopeptidase domain 19 (meltrin beta) 117763 8748 hCG20675.3 ADAM20 ADAM metallopeptidase domain 20 126448 8747 hCG1785634.2 ADAM21 ADAM metallopeptidase domain 21 208981 8747 hCG1785634.2|hCG2042897 ADAM21 ADAM metallopeptidase domain 21 180903 53616 hCG17212.4 ADAM22 ADAM metallopeptidase domain 22 177272 8745 hCG1811623.1 ADAM23 ADAM metallopeptidase domain 23 102384 10863 hCG1818505.1 ADAM28 ADAM metallopeptidase domain 28 119968 11086 hCG1786734.2 ADAM29 ADAM metallopeptidase domain 29 205542 11085 hCG1997196.1 ADAM30 ADAM metallopeptidase domain 30 148417 80332 hCG39255.4 ADAM33 ADAM metallopeptidase domain 33 140492 8756 hCG1789002.2 ADAM7 ADAM metallopeptidase domain 7 122603 101 hCG1816947.1 ADAM8 ADAM metallopeptidase domain 8 183965 8754 hCG1996391 ADAM9 ADAM metallopeptidase domain 9 (meltrin gamma) 129974 27299 hCG15447.3 ADAMDEC1 ADAM-like, -

Structural Variant Calling by Assembly in Whole Human Genomes: Applications in Hypoplastic Left Heart Syndrome by Matthew Kendzi
STRUCTURAL VARIANT CALLING BY ASSEMBLY IN WHOLE HUMAN GENOMES: APPLICATIONS IN HYPOPLASTIC LEFT HEART SYNDROME BY MATTHEW KENDZIOR THESIS Submitted in partial FulFillment oF tHe requirements for the degree of Master of Science in BioinFormatics witH a concentration in Crop Sciences in the Graduate College of the University oF Illinois at Urbana-Champaign, 2019 Urbana, Illinois Master’s Committee: ProFessor MattHew Hudson, CHair ResearcH Assistant ProFessor Liudmila Mainzer ProFessor SaurabH SinHa ABSTRACT Variant discovery in medical researcH typically involves alignment oF sHort sequencing reads to the human reference genome. SNPs and small indels (variants less than 50 nucleotides) are the most common types oF variants detected From alignments. Structural variation can be more diFFicult to detect From short-read alignments, and thus many software applications aimed at detecting structural variants From short read alignments have been developed. However, these almost all detect the presence of variation in a sample using expected mate-pair distances From read data, making them unable to determine the precise sequence of the variant genome at the speciFied locus. Also, reads from a structural variant allele migHt not even map to the reference, and will thus be lost during variant discovery From read alignment. A variant calling by assembly approacH was used witH tHe soFtware Cortex-var for variant discovery in Hypoplastic Left Heart Syndrome (HLHS). THis method circumvents many of the limitations oF variants called From a reFerence alignment: unmapped reads will be included in a sample’s assembly, and variants up to thousands of nucleotides can be detected, with the Full sample variant allele sequence predicted. -
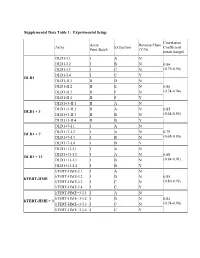
Table 3: Average Gene Expression Profiles by Chromosome
Supplemental Data Table 1: Experimental Setup Correlation Array Reverse Fluor Array Extraction Coefficient Print Batch (Y/N) mean (range) DLD1-I.1 I A N DLD1-I.2 I B N 0.86 DLD1-I.3 I C N (0.79-0.90) DLD1-I.4 I C Y DLD1 DLD1-II.1 II D N DLD1-II.2 II E N 0.86 DLD1-II.3 II F N (0.74-0.94) DLD1-II.4 II F Y DLD1+3-II.1 II A N DLD1+3-II.2 II A N 0.85 DLD1 + 3 DLD1+3-II.3 II B N (0.64-0.95) DLD1+3-II.4 II B Y DLD1+7-I.1 I A N DLD1+7-I.2 I A N 0.79 DLD1 + 7 DLD1+7-I.3 I B N (0.68-0.90) DLD1+7-I.4 I B Y DLD1+13-I.1 I A N DLD1+13-I.2 I A N 0.88 DLD1 + 13 DLD1+13-I.3 I B N (0.84-0.91) DLD1+13-I.4 I B Y hTERT-HME-I.1 I A N hTERT-HME-I.2 I B N 0.85 hTERT-HME hTERT-HME-I.3 I C N (0.80-0.92) hTERT-HME-I.4 I C Y hTERT-HME+3-I.1 I A N hTERT-HME+3-I.2 I B N 0.84 hTERT-HME + 3 hTERT-HME+3-I.3 I C N (0.74-0.90) hTERT-HME+3-I.4 I C Y Supplemental Data Table 2: Average gene expression profiles by chromosome arm DLD1 hTERT-HME Ratio.7 Ratio.1 Ratio.3 Ratio.3 Chrom. -

Nº Ref Uniprot Proteína Péptidos Identificados Por MS/MS 1 P01024
Document downloaded from http://www.elsevier.es, day 26/09/2021. This copy is for personal use. Any transmission of this document by any media or format is strictly prohibited. Nº Ref Uniprot Proteína Péptidos identificados 1 P01024 CO3_HUMAN Complement C3 OS=Homo sapiens GN=C3 PE=1 SV=2 por 162MS/MS 2 P02751 FINC_HUMAN Fibronectin OS=Homo sapiens GN=FN1 PE=1 SV=4 131 3 P01023 A2MG_HUMAN Alpha-2-macroglobulin OS=Homo sapiens GN=A2M PE=1 SV=3 128 4 P0C0L4 CO4A_HUMAN Complement C4-A OS=Homo sapiens GN=C4A PE=1 SV=1 95 5 P04275 VWF_HUMAN von Willebrand factor OS=Homo sapiens GN=VWF PE=1 SV=4 81 6 P02675 FIBB_HUMAN Fibrinogen beta chain OS=Homo sapiens GN=FGB PE=1 SV=2 78 7 P01031 CO5_HUMAN Complement C5 OS=Homo sapiens GN=C5 PE=1 SV=4 66 8 P02768 ALBU_HUMAN Serum albumin OS=Homo sapiens GN=ALB PE=1 SV=2 66 9 P00450 CERU_HUMAN Ceruloplasmin OS=Homo sapiens GN=CP PE=1 SV=1 64 10 P02671 FIBA_HUMAN Fibrinogen alpha chain OS=Homo sapiens GN=FGA PE=1 SV=2 58 11 P08603 CFAH_HUMAN Complement factor H OS=Homo sapiens GN=CFH PE=1 SV=4 56 12 P02787 TRFE_HUMAN Serotransferrin OS=Homo sapiens GN=TF PE=1 SV=3 54 13 P00747 PLMN_HUMAN Plasminogen OS=Homo sapiens GN=PLG PE=1 SV=2 48 14 P02679 FIBG_HUMAN Fibrinogen gamma chain OS=Homo sapiens GN=FGG PE=1 SV=3 47 15 P01871 IGHM_HUMAN Ig mu chain C region OS=Homo sapiens GN=IGHM PE=1 SV=3 41 16 P04003 C4BPA_HUMAN C4b-binding protein alpha chain OS=Homo sapiens GN=C4BPA PE=1 SV=2 37 17 Q9Y6R7 FCGBP_HUMAN IgGFc-binding protein OS=Homo sapiens GN=FCGBP PE=1 SV=3 30 18 O43866 CD5L_HUMAN CD5 antigen-like OS=Homo -

Supporting Information
Supporting Information Li et al. 10.1073/pnas.1617802113 SI Materials and Methods transfection. Cells were transfected with reporter constructs TOP- Plasmids. Mutant Tet3 (H950D and Y952A) was generated by or FOP-Flash using Lipofectamine 2000 (Invitrogen). Cell extracts PCR using Pfu polymerase, Dpn I treatment, and transformation were prepared 48 h after transfection. The luciferase activity was (Stratagene). The ORF of mouse Tet3, mutant Tet3 (H950D and evaluated by using the Dual-Luciferase Reporter Assay System ’ Y952A), Sfpr4, Pcdha4, and Pcdha7 were cloned into pPyCAGIP (Promega) according to the manufacturer s recommendations. vector (60). qRT-PCR. qRT-PCR was performed by using Universal SYBR Green Generation of Tet3 KO and Tet1/2/3 TKO mESCs. Tet3 KO and Tet1/2/3 Master Mix (Roche) and analyzed by a StepOne Plus real-time PCR ’ TKO mouse ESCs were generated from mice (C57BL/6 back- system (Applied Biosystems), according to the manufacturer sin- ground) bearing the individual floxed alleles (Fig. S1C) (14, 18), structions, and the data were normalized for Gapdh expression. followed by excision of the floxed exon by transient expression of The primers used for qRT-PCR are listed in Dataset S4. Cre recombinase. Immunohistochemistry. Immunohistochemistry was performed as mESC Culture and Differentiation. mESCs were maintained on mi- described (61) with the primary antibodies described below. For ∼ tomycin C-treated mouse embryonic fibroblasts (MEFs; feeders) in statistical analysis, 300 cells were examined for each experiment, standard medium (61). Neural differentiation in SFEB culture was which was repeated four times. Mouse embryos were fixed over- night in 4% (wt/vol) paraformaldehyde, saturated with 20% (wt/vol) performed as described (31) with a minor modification. -

Thousands of Cpgs Show DNA Methylation Differences in ACPA-Positive Individuals
G C A T T A C G G C A T genes Article Thousands of CpGs Show DNA Methylation Differences in ACPA-Positive Individuals Yixiao Zeng 1,2, Kaiqiong Zhao 2,3, Kathleen Oros Klein 2, Xiaojian Shao 4, Marvin J. Fritzler 5, Marie Hudson 2,6,7, Inés Colmegna 6,8, Tomi Pastinen 9,10, Sasha Bernatsky 6,8 and Celia M. T. Greenwood 1,2,3,9,11,* 1 PhD Program in Quantitative Life Sciences, Interfaculty Studies, McGill University, Montréal, QC H3A 1E3, Canada; [email protected] 2 Lady Davis Institute for Medical Research, Jewish General Hospital, Montréal, QC H3T 1E2, Canada; [email protected] (K.Z.); [email protected] (K.O.K.); [email protected] (M.H.) 3 Department of Epidemiology, Biostatistics and Occupational Health, McGill University, Montréal, QC H3A 1A2, Canada 4 Digital Technologies Research Centre, National Research Council Canada, Ottawa, ON K1A 0R6, Canada; [email protected] 5 Cumming School of Medicine, University of Calgary, Calgary, AB T2N 1N4, Canada; [email protected] 6 Department of Medicine, McGill University, Montréal, QC H4A 3J1, Canada; [email protected] (I.C.); [email protected] (S.B.) 7 Division of Rheumatology, Jewish General Hospital, Montréal, QC H3T 1E2, Canada 8 Division of Rheumatology, McGill University, Montréal, QC H3G 1A4, Canada 9 Department of Human Genetics, McGill University, Montréal, QC H3A 0C7, Canada; [email protected] 10 Center for Pediatric Genomic Medicine, Children’s Mercy, Kansas City, MO 64108, USA 11 Gerald Bronfman Department of Oncology, McGill University, Montréal, QC H4A 3T2, Canada * Correspondence: [email protected] Citation: Zeng, Y.; Zhao, K.; Oros Abstract: High levels of anti-citrullinated protein antibodies (ACPA) are often observed prior to Klein, K.; Shao, X.; Fritzler, M.J.; Hudson, M.; Colmegna, I.; Pastinen, a diagnosis of rheumatoid arthritis (RA). -

Mouse Pcdha9 Knockout Project (CRISPR/Cas9)
https://www.alphaknockout.com Mouse Pcdha9 Knockout Project (CRISPR/Cas9) Objective: To create a Pcdha9 knockout Mouse model (C57BL/6J) by CRISPR/Cas-mediated genome engineering. Strategy summary: The Pcdha9 gene (NCBI Reference Sequence: NM_138661 ; Ensembl: ENSMUSG00000103770 ) is located on Mouse chromosome 18. 4 exons are identified, with the ATG start codon in exon 1 and the TGA stop codon in exon 4 (Transcript: ENSMUST00000115659). Exon 1 will be selected as target site. Cas9 and gRNA will be co-injected into fertilized eggs for KO Mouse production. The pups will be genotyped by PCR followed by sequencing analysis. Note: Exon 1 starts from the coding region. Exon 1 covers 84.47% of the coding region. The size of effective KO region: ~2481 bp. The KO region does not have any other known gene. Page 1 of 9 https://www.alphaknockout.com Overview of the Targeting Strategy Wildtype allele 5' gRNA region gRNA region 3' 1 4 Legends Exon of mouse Pcdha9 Knockout region Page 2 of 9 https://www.alphaknockout.com Overview of the Dot Plot (up) Window size: 15 bp Forward Reverse Complement Sequence 12 Note: The 2000 bp section of Exon 1 is aligned with itself to determine if there are tandem repeats. No significant tandem repeat is found in the dot plot matrix. So this region is suitable for PCR screening or sequencing analysis. Overview of the Dot Plot (down) Window size: 15 bp Forward Reverse Complement Sequence 12 Note: The 2000 bp section of Exon 1 is aligned with itself to determine if there are tandem repeats. -

Species Functional Analysis Implicate LRP2 in Hypoplastic Left Heart
TOOLS AND RESOURCES Patient-specific genomics and cross- species functional analysis implicate LRP2 in hypoplastic left heart syndrome Jeanne L Theis1†, Georg Vogler2†, Maria A Missinato2†, Xing Li3, Tanja Nielsen2,4, Xin-Xin I Zeng2, Almudena Martinez-Fernandez5, Stanley M Walls2, Anaı¨s Kervadec2, James N Kezos2, Katja Birker2, Jared M Evans3, Megan M O’Byrne3, Zachary C Fogarty3, Andre´ Terzic5,6,7,8, Paul Grossfeld9,10, Karen Ocorr2, Timothy J Nelson6,7,8‡*, Timothy M Olson5,6,8‡*, Alexandre R Colas2‡, Rolf Bodmer2‡* 1Cardiovascular Genetics Research Laboratory, Rochester, United States; 2Development, Aging and Regeneration, Sanford Burnham Prebys Medical Discovery Institute, La Jolla, United States; 3Division of Biomedical Statistics and Informatics, Mayo Clinic, Rochester, United States; 4Doctoral Degrees and Habilitations, Department of Biology, Chemistry, and Pharmacy, Freie Universita¨ t Berlin, Berlin, Germany; 5Department of Cardiovascular Medicine, Mayo Clinic, Rochester, United States; 6Department of Molecular and Pharmacology and Experimental Therapeutics, Mayo Clinic, La Jolla, United States; 7Center for Regenerative Medicine, Mayo Clinic, Rochester, United States; 8Division of Pediatric Cardiology, Department of Pediatric and Adolescent Medicine, Mayo Clinic, *For correspondence: Rochester, United States; 9University of California San Diego, Rady’s Hospital, San [email protected] (TJN); 10 [email protected] (TMO); Diego, United States; Division of General Internal Medicine, Mayo Clinic, [email protected] (RB) Rochester, United States †These authors contributed equally to this work ‡These authors also contributed equally to this work Abstract Congenital heart diseases (CHDs), including hypoplastic left heart syndrome (HLHS), are genetically complex and poorly understood. Here, a multidisciplinary platform was established Competing interests: The to functionally evaluate novel CHD gene candidates, based on whole-genome and iPSC RNA authors declare that no sequencing of a HLHS family-trio. -

Remote Memory and Cortical Synaptic Plasticity Require Neuronal CCCTC-Binding Factor (CTCF)
5042 • The Journal of Neuroscience, May 30, 2018 • 38(22):5042–5052 Cellular/Molecular Remote Memory and Cortical Synaptic Plasticity Require Neuronal CCCTC-Binding Factor (CTCF) X Somi Kim,1* Nam-Kyung Yu,1* Kyu-Won Shim,2 XJi-il Kim,1 X Hyopil Kim,1 Dae Hee Han,1 XJa Eun Choi,1 X Seung-Woo Lee,1 X Dong Il Choi,1 Myung Won Kim,1 Dong-Sung Lee,3 Kyungmin Lee,4 Niels Galjart,5 X Yong-Seok Lee,6 XJae-Hyung Lee,7 and XBong-Kiun Kaang1 1Department of Biological Sciences, College of Natural Sciences, Seoul National University, Seoul 08826, South Korea, 2Interdisciplinary Program in Bioinformatics, Seoul National University, Seoul 08826, South Korea, 3Salk Institute for Biological Studies, La Jolla, California 92130, 4Department of Anatomy, Graduate School of Medicine, Kyungpook National University, Daegu 700-422, Korea, 5Department of Cell Biology and Genetics, 3000 CA Rotterdam, The Netherlands, 6Department of Physiology, Seoul National University College of Medicine, Seoul 03080, South Korea, and 7Department of Life and Nanopharmaceutical Sciences, Department of Maxillofacial Biomedical Engineering, School of Dentistry, Kyung Hee University, Seoul 02447, South Korea The molecular mechanism of long-term memory has been extensively studied in the context of the hippocampus-dependent recent memory examined within several days. However, months-old remote memory maintained in the cortex for long-term has not been investigated much at the molecular level yet. Various epigenetic mechanisms are known to be important for long-term memory, but how the 3D chromatin architecture and its regulator molecules contribute to neuronal plasticity and systems consolidation is still largely unknown. -

A CATH Domain Functional Family Based Approach to Identify
bioRxiv preprint doi: https://doi.org/10.1101/399014; this version posted August 25, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. 1 A CATH domain functional family based approach to identify putative cancer driver genes and driver mutations Paul Ashford1,+, Camilla S.M. Pang1,+, Aurelio A. Moya-García1,2, Tolulope Adeyelu1 & Christine A. Orengo1,* +These authors contributed equally to this work. 1University College London, Institute of Structural and Molecular Biology, London, UK. 2Laboratorio de Biología Molecular del Cáncer, Centro de Investigaciones Médico-Sanitarias (CIMES), Universidad de Málaga, Málaga, Spain Correspondence and requests for materials should be addressed to Christine Orengo (email: [email protected]). Tumour sequencing identifies highly recurrent point mutations in cancer driver genes, but rare functional mutations are hard to distinguish from large numbers of passengers. We developed a novel computational platform applying a multi-modal approach to filter out passengers and more robustly identify putative driver genes. The primary filter identifies enrichment of cancer mutations in CATH functional families (CATH-FunFams) – structurally and functionally coherent sets of evolutionary related domains. Using structural representatives from CATH-FunFams, we subsequently seek enrichment of mutations in 3D and show that these mutation clusters have a very significant tendency to lie close to known functional sites or conserved sites predicted using CATH-FunFams. Our third filter identifies enrichment of putative driver genes in functionally coherent protein network modules confirmed by literature analysis to be cancer associated.