Threading Hardware in G80
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nvidia Geforce 6 Series Specifications
NVIDIA GEFORCE 6 SERIES PRODUCT OVERVIEW DECEMBER 2004v06 NVIDIA GEFORCE 6 SERIES SPECIFICATIONS CINEFX 3.0 SHADING ARCHITECTURE ULTRASHADOW II TECHNOLOGY ADVANCED ENGINEERING • Vertex Shaders • Designed to enhance the performance of • Designed for PCI Express x16 ° Support for Microsoft DirectX 9.0 shadow-intensive games, like id Software’s • Support for AGP 8X including Fast Writes and Vertex Shader 3.0 Doom 3 sideband addressing Displacement mapping 3 • Designed for high-speed GDDR3 memory ° TURBOCACHE TECHNOLOGY Geometry instancing • Advanced thermal management and thermal ° • Shares the capacity and bandwidth of Infinite length vertex programs monitoring ° dedicated video memory and dynamically • Pixel Shaders available system memory for optimal system NVIDIA® DIGITAL VIBRANCE CONTROL™ Support for DirectX 9.0 Pixel Shader 3.0 ° performance (DVC) 3.0 Full pixel branching support ° • DVC color controls PC graphics such as photos, videos, and games require a Support for Multiple Render Targets (MRTs) PUREVIDEO TECHNOLOGY4 ° • DVC image sharpening controls ° Infinite length pixel programs • Adaptable programmable video processor lot of processing power. Without any help, the CPU • Next-Generation Texture Engine • High-definition MPEG-2 hardware acceleration OPERATING SYSTEMS ° Up to 16 textures per rendering pass • High-quality video scaling and filtering • Windows XP must handle all of the system and graphics ° Support for 16-bit floating point format • DVD and HDTV-ready MPEG-2 decoding up to • Windows ME and 32-bit floating point format 1920x1080i resolution • Windows 2000 processing which can result in decreased system ° Support for non-power of two textures • Display gamma correction • Windows 9X ° Support for sRGB texture format for • Microsoft® Video Mixing Renderer (VMR) • Linux performance. -

Club 3D Geforce 7300GS Pcie “512MB Turbocache”
Club 3D GeForce 7300GS PCIe “512MB TurboCache” Introduction: The Club 3D 7300GS shows stunningly fast, 3D effects in your Games, crystal clear high definition video in your Home-Theater and a brilliant and sharp image when browsing the Internet. The Club 3D GeForce 7300GS is designed for high performance desktop PC’s and quality in all Windows XP versions. High Quality analogue and digital CyberLink PowerPack display outputs make the Club 3D GeForce 7300GS the best solution for high resolution LCD and CRT monitors. HDTV support, up to 720p/1080i, is excellent for the ultimate Home-Theater experience. The latest NVIDIA GeForce tech- nology is fully compatible with all games and PC platforms and makes it possible to run your games with high framer- ates and excellent detail. Order Information: • GeForce 7300GS 256MB/512MBTC : CGNX-GS736 Product Positioning: • Office Applications • Gaming Panda Jr Game Specifications: Features: System requirements Item code: CGNX-GS736 • NVIDIA® PureVideo™ Technology • Intel® Pentium® or AMD™ Athlon™ • NVIDIA® nView™ multi-display Technology Format: PCIe or compatible • NVIDIA® Intellysample™ 4.0 Technology • 128MB of system memory YPrPb breakout cable Engine Clock: 550MHz • Full support for DirectX® 9.0 • Mainboard with free PCIe (x16) slot Memory Clock: 533MHz • Shader Model 3.0 • CD-ROM drive for software installation Memory: 256MB DDR2 • DVI-I display output • 350Watt or greater Power Supply Memory Bus: 64 bit • CVBS and S-video output Pixel Pipelines: 4 • TurboCache Technology supports 512MB, 1GB System -

TOSHIBA NOTEBOOKS, PRICELIST – July 30Th, 2013 INCL
TOSHIBA NOTEBOOKS, PRICELIST – July 30th, 2013 INCL. PC OPTIONS, PERIPHERALS, SERVICE & MULTIMEDIA www.toshiba.ch/computer Toshiba recommends Windows 8 Pro. PORTÉGÉ Z10t-A-102 ADAPTS AS OFTEN ASYOU DO With a powerful laptop and high-performance tablet in one device, the 29.5 cm (11.6“) Portégé Z10t-A Ultrabook™ from Toshiba adapts to any professional‘s changing needs. It‘s made for business, so you can use it as a laptop to type emails on the way to a meeting, and then click into tablet mode to make notes when you get there. The latest Intel Core processors for Ultrabook™ will give you all the power you need to cut through your workload, in or out the office. And because it runs Windows 8 Pro, you can rely on an intuitive experience, whether you‘re using the touchscreen, touchpad or keyboard. All of these flexible functions can be found in one travel friendly device, which comes with Accupoint navigation and the optional pen to help you work more precisely. And as the Z10t-A also has the latest high-performance components and a full set of ports, it can adapt as often as you do. * Spill-resistant keyboards help protect your data from accidental spills up to 30 ml, allowing you 3 minutes shut down time to save your data. ** Pen included with selected models only. Model Part No. List Price EAN Code incl. VAT Portégé Z10t-A-102 PT131E-00500US4 1799 4051528083163 Specification Processor / Technology 3rd generation Intel® Core™ i5-3339Y Processor with Intel® Turbo Boost Technology 2.0 (1.50/2.00 GHz Turbo, 3 MB shared L3 cache, FSB 1600 MHz, -

最新 7.3.X 6.0.0-6.02 6.0.3 6.0.4 6.0.5-6.09 6.0.2(RIQ)
2017/04/24現在 赤字は標準インストール外 最新 RedHawk Linux 6.0.x 6.3.x 6.5.x 7.0.x 7.2.x 7.3.x Version 6.0.0-6.02 6.0.3 6.0.4 6.0.5-6.09 6.0.2(RIQ) 6.3.1-6.3.2 6.3.3 6.3.4-6.3.6 6.3.7-6.3.11 6.5.0 6.5.1 6.5-6.5.8 7.0 7.01-7.03 7.2-7.2.5 7.3-7.3.1 Xorg-version 1.7.7(X11R7.4) 1.10.6(X11R7.4) 1.13.0(X11R7.4) 1.15.0(X11R7.7) 1.17.2-10(X11R7.7) 1.17.2-22(X11R7.7) X.Org ANSI C 0.4 0.4 0.4 0.4 0.4 0.4 Emulation X.Org Video Driver 6.0 10.0 13.1 19.0 19.0 15.0 X.Org Xinput driver 7.0 12.2 18.1 21.0 21.0 20.0 X.Org Server 2.0 5.0 7.0 9.0 9.0 8.0 Extention RandR Version 1.1 1.1 1.1 1.1/1.2 1.1/1.2/1.3/1.4 1.1/1.2 1.1/1.2/1.3 1.1/1.2/1.3 1.1/1.2/1.3/1.4 1.1/1.2/1.3/1.4 1.1/1.2/1.3/1.4 1.1/1.2/1.3/1.4 1.1/1.2/1.3/1.4 1.1/1.2/1.3/1.4 1.1/1.2/1.3/1.4 1.1/1.2/1.3/1.4 1.1/1.2/1.3/1.4 1.1/1.2/1.3/1.4 NVIDIA driver 340.76 275.09.07 295.20 295.40 304.54 331.20 304.37 304.54 310.32 319.49 331.67 337.25 340.32 346.35 346.59 352.79 367.57 375.51 version (Download) PTX ISA 2.3(CUDA4.0) 3.0(CUDA 4.1,4.2) 3.0(CUDA4.1,4.2) 3.1(CUDA5.0) 4.0(CUDA6.0) 3.1(CUDA5.0) 3.1(CUDA5.0) 3.1(CUDA5.0) 3.2(CUDA5.5) 4.0(CUDA6.0) 4.0(CUDA6.0) 4.1(CUDA6.5) 4.1(CUDA6.5) 4.3(CUDA7.5) 5.0(CUDA8.0) 5.0(CUDA8.0) Version(対応可能 4.2(CUDA7.0) 4.2(CUDA7.0) CUDAバージョン) Unified Memory N/A Yes N/A Yes kernel module last update Aug 17 2011 Mar 20 2012 May 16 2012 Nov 13 2012 Sep 27 2012 Nov 20 2012 Aug 16 2013 Jan 08 2014 Jun 30 2014 May 16 2014 Dec 10 2014 Jan 27 2015 Mar 24 2015 Apr 7 2015 Mar 09 2016 Dec 21 2016 Arp 5 2017 標準バンドル 4.0.1 4.1.28 4.1.28 4.2.9 5.5 5.0 5.0 5.0 5.5 5.5,6.0 5.5,6.0 5.5,6.0 7.5 7.5 8.0 -

Graphical Process Unit a New Era
Nov 2014 (Volume 1 Issue 6) JETIR (ISSN-2349-5162) Graphical Process Unit A New Era Santosh Kumar, Shashi Bhushan Jha, Rupesh Kumar Singh Students Computer Science and Engineering Dronacharya College of Engineering, Greater Noida, India Abstract - Now in present days every computer is come with G.P.U (graphical process unit). The graphics processing unit (G.P.U) has become an essential part of today's mainstream computing systems. Over the past 6 years, there has been a marked increase in the performance and potentiality of G.P.U. The modern G.P.Us is not only a powerful graphics engine but also a deeply parallel programmable processor showing peak arithmetic and memory bandwidth that substantially outpaces its CPU counterpart. The G.P.U's speedy increase in both programmability and capability has spawned a research community that has successfully mapped a broad area of computationally demanding, mixed problems to the G.P.U. This effort in general-purpose computing on the G.P.Us, also known as G.P.U computing, has positioned the G.P.U as a compelling alternative to traditional microprocessors in high-performance computer systems of the future. We illustrate the history, hardware, and programming model for G.P.U computing, abstract the state of the art in tools and techniques, and present 4 G.P.U computing successes in games physics and computational physics that deliver order-of- magnitude performance gains over optimized CPU applications. Index Terms - G.P.U, History of G.P.U, Future of G.P.U, Problems in G.P.U, eG.P.U, Integrated graphics ________________________________________________________________________________________________________ I. -

Release 70 Notes
ForceWare Graphics Drivers Release 70 Notes Version 71.89 For Windows XP / 2000 Windows XP Media Center Edition Windows 98 / ME Windows NT 4.0 NVIDIA Corporation April 14, 2005 Published by NVIDIA Corporation 2701 San Tomas Expressway Santa Clara, CA 95050 Notice ALL NVIDIA DESIGN SPECIFICATIONS, REFERENCE BOARDS, FILES, DRAWINGS, DIAGNOSTICS, LISTS, AND OTHER DOCUMENTS (TOGETHER AND SEPARATELY, “MATERIALS”) ARE BEING PROVIDED “AS IS.” NVIDIA MAKES NO WARRANTIES, EXPRESSED, IMPLIED, STATUTORY, OR OTHERWISE WITH RESPECT TO THE MATERIALS, AND EXPRESSLY DISCLAIMS ALL IMPLIED WARRANTIES OF NONINFRINGEMENT, MERCHANTABILITY, AND FITNESS FOR A PARTICULAR PURPOSE. Information furnished is believed to be accurate and reliable. However, NVIDIA Corporation assumes no responsibility for the consequences of use of such information or for any infringement of patents or other rights of third parties that may result from its use. No license is granted by implication or otherwise under any patent or patent rights of NVIDIA Corporation. Specifications mentioned in this publication are subject to change without notice. This publication supersedes and replaces all information previously supplied. NVIDIA Corporation products are not authorized for use as critical components in life support devices or systems without express written approval of NVIDIA Corporation. Trademarks NVIDIA, the NVIDIA logo, 3DFX, 3DFX INTERACTIVE, the 3dfx Logo, STB, STB Systems and Design, the STB Logo, the StarBox Logo, NVIDIA nForce, GeForce, NVIDIA Quadro, NVDVD, NVIDIA Personal -

Release 80 Notes
ForceWare Graphics Drivers Release 80 Notes Version 81.94 For Windows XP / 2000 Windows XP Media Center Edition Windows NT 4.0 NVIDIA Corporation November 2005 Published by NVIDIA Corporation 2701 San Tomas Expressway Santa Clara, CA 95050 Notice ALL NVIDIA DESIGN SPECIFICATIONS, REFERENCE BOARDS, FILES, DRAWINGS, DIAGNOSTICS, LISTS, AND OTHER DOCUMENTS (TOGETHER AND SEPARATELY, “MATERIALS”) ARE BEING PROVIDED “AS IS.” NVIDIA MAKES NO WARRANTIES, EXPRESSED, IMPLIED, STATUTORY, OR OTHERWISE WITH RESPECT TO THE MATERIALS, AND EXPRESSLY DISCLAIMS ALL IMPLIED WARRANTIES OF NONINFRINGEMENT, MERCHANTABILITY, AND FITNESS FOR A PARTICULAR PURPOSE. Information furnished is believed to be accurate and reliable. However, NVIDIA Corporation assumes no responsibility for the consequences of use of such information or for any infringement of patents or other rights of third parties that may result from its use. No license is granted by implication or otherwise under any patent or patent rights of NVIDIA Corporation. Specifications mentioned in this publication are subject to change without notice. This publication supersedes and replaces all information previously supplied. NVIDIA Corporation products are not authorized for use as critical components in life support devices or systems without express written approval of NVIDIA Corporation. Trademarks NVIDIA, the NVIDIA logo, 3DFX, 3DFX INTERACTIVE, the 3dfx Logo, STB, STB Systems and Design, the STB Logo, the StarBox Logo, NVIDIA nForce, GeForce, NVIDIA Quadro, NVDVD, NVIDIA Personal Cinema, NVIDIA -

The NVIDIA Windows PC Opengl ES 2.0 and Khronos API Emulator Support Pack
The NVIDIA Windows PC OpenGL ES 2.0 and Khronos API Emulator Support Pack Version 100 - 1 - January 2010 Contents INTRODUCTION 3 SYSTEM REQUIREMENTS 3 INSTALLING THE SUPPORT PACK 4 BUILDING CODE FOR THE KHRONOS API PC EMULATOR 7 LIMITATIONS/DIFFERENCES BETWEEN EMULATION AND THE TEGRA 8 EMULATOR PROGRAMMING NOTES 10 January 2010 - 2 - Introduction This support pack includes a sort of “virtual platform”; a PC-based set of “wrapper” libraries that allow applications written to Khronos APIs (OpenKODE, OpenGL ES, EGL) to run (or at least link, depending on the Khronos API) with no source code modifications on both Tegra devkits and on a Windows-based PC. The Windows PC wrapper can make it easier for developers to share devkits by allowing application development for Tegra-targetted applications to be started on a Windows-based PC. The pack includes Khronos headers and link libraries, as well as Windows PC DLLs that implement emulators for key Khronos media APIs. The pack is laid out in exactly the same format as any of the Windows CE 6.0 platform support packs, to ensure that minimal changes are required to move between the emulator’s “virtual platform” and the Tegra devkit platform. System Requirements The minimum specifications for a PC to run emulator-based applications (details are given in the installation sections of this documentation) are: Hardware • Windows-compatible PC o ~2.0GHz CPU o 1-2GB RAM or better • NVIDIA GPU, ~GeForce 6200 or newer (NV43), GeForce 8xxx series or newer recommended. Tested/supported GPU hardware includes: -

GV-NX62TC256P8-RH / GV-NX62TC256P4-RH Geforce™ 6200
GV-NX62TC256P8-RH / GV-NX62TC256P4-RH GeForce™ 6200 Rev. 101 * WEEE logo * WEEE © 2006 GIGABYTE TECHNOLOGY CO., LTD GIGA-BYTE TECHNOLOGY CO., LTD. ("GBT") GBT 1. ................................................................................................... 3 1.1. ................................................................................................. 3 1.2. ................................................................................................. 3 2. ............................................................................................ 4 2.1. ......................................................................... 4 2.2. ................................................................................................. 6 3. ................................................................................... 9 3.1. Windows® XP ............................................................ 9 3.1.1. ................................................................................ 9 3.1.2. DirectX ................................................................................................. 10 3.1.3. ............................................................................................. 11 3.1.4. ............................................................. 13 3.1.5. ....................................................................................... 15 3.1.6. ....................................................................................... 18 3.1.7. nView ......................................................................................... -

Toshiba Notebooks, Pricelist – January 31Th, 2012 Incl
TOSHIBA NOTEBOOKS, PRICELIST – JANUARY 31TH, 2012 INCL. PC OPTIONS, PERIPHERALS, SERVICE & MULTIMEDIA TOSHIBA PORTÉGÉ Z830 ULTRA-LIGHT. ULTRA-THIN. Although it's among the world's thinnest and lightest Ultrabooks™, the elegant new Portégé Z830 is less about what Toshiba took out, but more about what we put in. No need to settle for mini ports. Our engineers had maxi in mind when they integrated a full-size HDMI interface, three full size USB ports, a VGA port, and an SD slot. No compromises on power either: you get 2nd gen Intel® Core™ processors for Ultrabook™ featuring Intel® HD Graphics 3000 for great performance even for demanding video editing tasks. The embedded high performance Toshiba solid state drive gives you not only fast access to files, but also increased data protection thanks to no moving parts. To round everything off, the Z830 also comes with the solid build of other Portégé models, featuring Toshiba's signature honeycomb design reinforcing the magnesium chassis. www.toshiba.ch/computer Toshiba recommends Windows® 7 Professional. PORTÉGÉ Z830-10Z The Portégé Z830 is very light and very thin, but engineered for big things. Although it's among the world's thinnest and lightest Ultrabooks™¹, the elegant new Portégé Z830 is less about what Toshiba took out, but more about what we put in. No need to settle for mini ports. Our engineers had maxi in mind when they integrated a full-size HDMI interface, three full size USB ports, a VGA port, and an SD slot. We also reinforced the magnesium chassis with an internal honeycomb design for additional reinforcement. -

Linux Hardware Compatibility HOWTO
Linux Hardware Compatibility HOWTO Steven Pritchard Southern Illinois Linux Users Group / K&S Pritchard Enterprises, Inc. <[email protected]> 3.2.4 Copyright © 2001−2007 Steven Pritchard Copyright © 1997−1999 Patrick Reijnen 2007−05−22 This document attempts to list most of the hardware known to be either supported or unsupported under Linux. Copyright This HOWTO is free documentation; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free software Foundation; either version 2 of the license, or (at your option) any later version. Linux Hardware Compatibility HOWTO Table of Contents 1. Introduction.....................................................................................................................................................1 1.1. Notes on binary−only drivers...........................................................................................................1 1.2. Notes on proprietary drivers.............................................................................................................1 1.3. System architectures.........................................................................................................................1 1.4. Related sources of information.........................................................................................................2 1.5. Known problems with this document...............................................................................................2 1.6. New versions of this document.........................................................................................................2 -
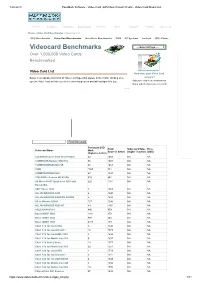
Videocard Benchmarks ----Select a Page ---- Over 1,000,000 Video Cards Benchmarked
1.08.2019 PassMark Software - Video Card (GPU) Benchmark Charts - Video Card Model List Home Software Hardware Benchmarks Services Store Support Forums About Us Home » Video Card Benchmarks » Video Card List CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks RAM PC Systems Android iOS / iPhone Videocard Benchmarks ----Select A Page ---- Over 1,000,000 Video Cards Benchmarked Video Card List How does your Video Card Below is an alphabetical list of all Video Card types that appear in the charts. Clicking on a compare? specific Video Card will take you to the chart it appears in and will highlight it for you. Add your card to our benchmark charts with PerformanceTest V9! Find Videocard Passmark G3D Rank Videocard Value Price Videocard Name Mark (lower is better) (higher is better) (USD) (higher is better) 128 DDR Radeon 9700 TX w/TV-Out 44 1469 NA NA 128MB DDR Radeon 9800 Pro 66 1409 NA NA 128MB RADEON X600 SE 49 1453 NA NA 15DD 1567 381 NA NA 256MB RADEON X600 67 1401 NA NA 7900 MOD - Radeon HD 6520G 610 842 NA NA A6 Micro-6500T Quad-Core APU with 220 1141 NA NA RadeonR4 ABIT Siluro T400 3 1669 NA NA ALL-IN-WONDER 9000 4 1640 NA NA ALL-IN-WONDER RADEON 8500DV 5 1628 NA NA All-in-Wonder X1900 127 1248 NA NA ALL-IN-WONDER X800 GT 84 1354 NA NA ASUS EAH4870x2 496 959 NA NA Barco MXRT 5400 1161 470 NA NA Barco MXRT 5450 992 548 NA NA Barco MXRT 7500 4319 173 NA NA Chell 1.7b for Intel 945G 9 1594 NA NA Chell 1.7b for Intel G33/G31 16 1573 NA NA Chell 1.7b for Intel GMA 3150 4 1648 NA NA Chell 1.7b for Mobile Intel 945 6 1607 NA NA Chell