Graphical Process Unit a New Era
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Release Notes for X11R6.8.2 the X.Orgfoundation the Xfree86 Project, Inc
Release Notes for X11R6.8.2 The X.OrgFoundation The XFree86 Project, Inc. 9February 2005 Abstract These release notes contains information about features and their status in the X.Org Foundation X11R6.8.2 release. It is based on the XFree86 4.4RC2 RELNOTES docu- ment published by The XFree86™ Project, Inc. Thereare significant updates and dif- ferences in the X.Orgrelease as noted below. 1. Introduction to the X11R6.8.2 Release The release numbering is based on the original MIT X numbering system. X11refers to the ver- sion of the network protocol that the X Window system is based on: Version 11was first released in 1988 and has been stable for 15 years, with only upwardcompatible additions to the coreX protocol, a recordofstability envied in computing. Formal releases of X started with X version 9 from MIT;the first commercial X products werebased on X version 10. The MIT X Consortium and its successors, the X Consortium, the Open Group X Project Team, and the X.OrgGroup released versions X11R3 through X11R6.6, beforethe founding of the X.OrgFoundation. Therewill be futuremaintenance releases in the X11R6.8.x series. However,efforts arewell underway to split the X distribution into its modular components to allow for easier maintenance and independent updates. We expect a transitional period while both X11R6.8 releases arebeing fielded and the modular release completed and deployed while both will be available as different consumers of X technology have different constraints on deployment. Wehave not yet decided how the modular X releases will be numbered. We encourage you to submit bug fixes and enhancements to bugzilla.freedesktop.orgusing the xorgproduct, and discussions on this server take place on <[email protected]>. -

Stephen Clarke-Willson
Contact Stephen Clarke-Willson www.linkedin.com/in/drstephencw Programmer, Producer, Executive (LinkedIn) Sammamish www.arena.net (Company) www.above-the-garage.com (Personal) Summary above-the-garage.com/blog (Blog) Software technology development leadership and management. Top Skills Specialties: Technical / Product team building and management; Systems Programming System Architecture experience as first, second and third level manager in fast growing Game Development companies; systems programming, systems architecture, technology development. Publications Guild Wars Microservices and 24/7 Uptime Guild Wars 2 - Scaling from one to Experience millions Applying Game Design To Virtual NCSOFT Environments VP of Technology Nano-Plasm March 2019 - Present (1 year 7 months) Bellevue, WA ArenaNet LLC 13 years 6 months Programmer in the role of Studio Technical Director May 2013 - March 2019 (5 years 11 months) Bellevue, WA Lead engineering staff (about 100 members) for "gaming as a service" with continuous high volume content creation and delivery at MMO scale. Translate business objectives into innovative yet achievable technical challenges. Created technical unit with flat reporting structure and peer input reviews. Programmer in the roles of Server Programmer / Server Team Lead October 2005 - April 2013 (7 years 7 months) Developing multi-threaded, restartable, dynamically updatable, high performance, internet-resilient, bug free server code for the MMO Guild Wars (1 and 2). Above the Garage Productions Programmer / Owner Page 1 of 4 May 2004 - October 2005 (1 year 6 months) Game Technology Developer, Above the Garage Productions Developed downloadable music system "DirectSong.com" (from payment system [PayPal] to delivery system to embedded music player using Microsoft WMA technology). -

Reviving the Development of Openchrome
Reviving the Development of OpenChrome Kevin Brace OpenChrome Project Maintainer / Developer XDC2017 September 21st, 2017 Outline ● About Me ● My Personal Story Behind OpenChrome ● Background on VIA Chrome Hardware ● The History of OpenChrome Project ● Past Releases ● Observations about Standby Resume ● Developmental Philosophy ● Developmental Challenges ● Strategies for Further Development ● Future Plans 09/21/2017 XDC2017 2 About Me ● EE (Electrical Engineering) background (B.S.E.E.) who specialized in digital design / computer architecture in college (pretty much the only undergraduate student “still” doing this stuff where I attended college) ● Graduated recently ● First time conference presenter ● Very experienced with Xilinx FPGA (Spartan-II through 7 Series FPGA) ● Fluent in Verilog / VHDL design and verification ● Interest / design experience with external communication interfaces (PCI / PCIe) and external memory interfaces (SDRAM / DDR3 SDRAM) ● Developed a simple DMA engine for PCI I/F validation w/Windows WDM (Windows Driver Model) kernel device driver ● Almost all the knowledge I have is self taught (university engineering classes were not very useful) 09/21/2017 XDC2017 3 Motivations Behind My Work ● General difficulty in obtaining meaningful employment in the digital hardware design field (too many students in the field, difficulty obtaining internship, etc.) ● Collects and repairs abandoned computer hardware (It’s like rescuing puppies!) ● Owns 100+ desktop computers and 20+ laptop computers (mostly abandoned old stuff I -

Pcbs : 465 in 1 Babystar PCB
PCBs : 465 in 1 BabyStar PCB 465 in 1 BabyStar PCB 465 in 1 BabyStar PCB 465 Games in 1 BabyStar PCB Rating: Not Rated Yet Price: Sales price: $274.95 Discount: Ask a question about this product Description 465 in 1 BabyStar PCB ***ATX Power Supply with P4 connector required for operation*** JAMMA ready arcade system containing 465 vertical ready to play games. Choose from classics like Ms. Pac man, Donkey Kong, and Frogger to great shooters like 19XX, Strikers 1945 II, and Varth! The game selection menu is easy to understand and navigate. To select a game, scroll through the list and press your button to select. At anytime during the active game aplayer can return back to main game selection menu by holding in the start button for 3 seconds. This sytem runs on a stable flash drive. No hard drive to ever fail! Supports Vertically mounted monitors only. Universal JAMMA Connector. User Friendly Game Selection Screen. P4 Motherboard using genuine Intel Processor and Card Flash memory creates a faster/more stable system! User Adjustable Game Options (Game Dip Switch Settings; Number of Lives, Difficulty, etc). Supports 1-4 Player Games (players 3 & 4 via linking - kit included). Supports two-channel audio (Stereo Sound). Supports CGA Standard Arcade Monitor (15kHz). Supports Upright Cabinets (will not flip screen for cocktails). Enable One Game (for a dedicated machine if desired) or All Games. Enable/Disable Individual Game Categories From Showing. Delete/Undelete Each Game. Set Coin/Credit Ratio of All Games with One Setting. Supports a Coin Counter. System Specifications: JAMMA Controller/Interface PCB. -

Master Thesis
Faculty of Computer Science and Management Field of study: COMPUTER SCIENCE Specialty: Information Systems Design Master Thesis Multithreaded game engine architecture Adrian Szczerbiński keywords: game engine multithreading DirectX 12 short summary: Project, implementation and research of a multithreaded 3D game engine architecture using DirectX 12. The goal is to create a layered architecture, parallelize it and compare the results in order to state the usefulness of multithreading in game engines. Supervisor ...................................................... ............................ ……………………. Title/ degree/ name and surname grade signature The final evaluation of the thesis Przewodniczący Komisji egzaminu ...................................................... ............................ ……………………. dyplomowego Title/ degree/ name and surname grade signature For the purposes of archival thesis qualified to: * a) Category A (perpetual files) b) Category BE 50 (subject to expertise after 50 years) * Delete as appropriate stamp of the faculty Wrocław 2019 1 Streszczenie W dzisiejszych czasach, gdy społeczność graczy staje się coraz większa i stawia coraz większe wymagania, jak lepsza grafika, czy ogólnie wydajność gry, pojawia się potrzeba szybszych i lepszych silników gier, ponieważ większość z obecnych jest albo stara, albo korzysta ze starych rozwiązań. Wielowątkowość jest postrzegana jako trudne zadanie do wdrożenia i nie jest w pełni rozwinięta. Programiści często unikają jej, ponieważ do prawidłowego wdrożenia wymaga wiele pracy. Według mnie wynikający z tego wzrost wydajności jest warty tych kosztów. Ponieważ nie ma wielu silników gier, które w pełni wykorzystują wielowątkowość, celem tej pracy jest zaprojektowanie i zaproponowanie wielowątkowej architektury silnika gry 3D, a także przedstawienie głównych systemów używanych do stworzenia takiego silnika gry 3D. Praca skupia się na technologii i architekturze silnika gry i jego podsystemach wraz ze strukturami danych i algorytmami wykorzystywanymi do ich stworzenia. -

September 1999
SEPTEMBER 1999 GAME DEVELOPER MAGAZINE ON THE FRONT LINE OF GAME INNOVATION GAME PLAN DEVELOPER 600 Harrison Street, San Francisco, CA 94107 t: 415.905.2200 f: 415.905.2228 w: www.gdmag.com Fast, Cheap, and Publisher Cynthia A. Blair cblair@mfi.com EDITORIAL Out of Control Editorial Director Alex Dunne [email protected] Managing Editor his past July I was fortunate mond Rio. If major motion picture stu- Kimberley Van Hooser [email protected] to fly out to Monte Carlo for dios, television networks, radio sta- Departments Editor Medpi, a gathering of game tions, and record labels decide that the Jennifer Olsen [email protected] publishers and representa- time’s right to push their content onto Art Director T Laura Pool lpool@mfi.com tives from the largest French game dis- the Internet (I’m talking in a major Editor-At-Large tributors. In a sense it’s like E3, except way — not the half-hearted attempts Chris Hecker [email protected] that the entire Medpi exhibition area we’re seeing today), what will that do Contributing Editors could have fit within Nintendo’s E3 to game sales? Will the competition Jeff Lander [email protected] Mel Guymon [email protected] booth. During my second day at the from other forms of digital entertain- Omid Rahmat [email protected] show, I met a developer on the show ment mean opportunities for game Advisory Board floor who works for a major game developers, or will it threaten the pre- Hal Barwood LucasArts development/publishing company. As eminence of games as computer-based Noah Falstein The Inspiracy Brian Hook id Software 6 we toured his company’s booth and he digital entertainment? Susan Lee-Merrow Lucas Learning demonstrated their upcoming titles for While the current retail model for Mark Miller Harmonix Paul Steed id Software me, we began discussing movies — The games is far from dead and competition Dan Teven Teven Consulting Phantom Menace, specifically. -

GPU Developments 2018
GPU Developments 2018 2018 GPU Developments 2018 © Copyright Jon Peddie Research 2019. All rights reserved. Reproduction in whole or in part is prohibited without written permission from Jon Peddie Research. This report is the property of Jon Peddie Research (JPR) and made available to a restricted number of clients only upon these terms and conditions. Agreement not to copy or disclose. This report and all future reports or other materials provided by JPR pursuant to this subscription (collectively, “Reports”) are protected by: (i) federal copyright, pursuant to the Copyright Act of 1976; and (ii) the nondisclosure provisions set forth immediately following. License, exclusive use, and agreement not to disclose. Reports are the trade secret property exclusively of JPR and are made available to a restricted number of clients, for their exclusive use and only upon the following terms and conditions. JPR grants site-wide license to read and utilize the information in the Reports, exclusively to the initial subscriber to the Reports, its subsidiaries, divisions, and employees (collectively, “Subscriber”). The Reports shall, at all times, be treated by Subscriber as proprietary and confidential documents, for internal use only. Subscriber agrees that it will not reproduce for or share any of the material in the Reports (“Material”) with any entity or individual other than Subscriber (“Shared Third Party”) (collectively, “Share” or “Sharing”), without the advance written permission of JPR. Subscriber shall be liable for any breach of this agreement and shall be subject to cancellation of its subscription to Reports. Without limiting this liability, Subscriber shall be liable for any damages suffered by JPR as a result of any Sharing of any Material, without advance written permission of JPR. -

Driver Riva Tnt2 64
Driver riva tnt2 64 click here to download The following products are supported by the drivers: TNT2 TNT2 Pro TNT2 Ultra TNT2 Model 64 (M64) TNT2 Model 64 (M64) Pro Vanta Vanta LT GeForce. The NVIDIA TNT2™ was the first chipset to offer a bit frame buffer for better quality visuals at higher resolutions, bit color for TNT2 M64 Memory Speed. NVIDIA no longer provides hardware or software support for the NVIDIA Riva TNT GPU. The last Forceware unified display driver which. version now. NVIDIA RIVA TNT2 Model 64/Model 64 Pro is the first family of high performance. Drivers > Video & Graphic Cards. Feedback. NVIDIA RIVA TNT2 Model 64/Model 64 Pro: The first chipset to offer a bit frame buffer for better quality visuals Subcategory, Video Drivers. Update your computer's drivers using DriverMax, the free driver update tool - Display Adapters - NVIDIA - NVIDIA RIVA TNT2 Model 64/Model 64 Pro Computer. (In Windows 7 RC1 there was the build in TNT2 drivers). http://kemovitra. www.doorway.ru Use the links on this page to download the latest version of NVIDIA RIVA TNT2 Model 64/Model 64 Pro (Microsoft Corporation) drivers. All drivers available for. NVIDIA RIVA TNT2 Model 64/Model 64 Pro - Driver Download. Updating your drivers with Driver Alert can help your computer in a number of ways. From adding. Nvidia RIVA TNT2 M64 specs and specifications. Price comparisons for the Nvidia RIVA TNT2 M64 and also where to download RIVA TNT2 M64 drivers. Windows 7 and Windows Vista both fail to recognize the Nvidia Riva TNT2 ( Model64/Model 64 Pro) which means you are restricted to a low. -

I TMS34010 I Development ~ I Board : User's Guide
SPVU002A j ~ 1 r l I TMS34010 ~ I S £ ~ i Oltware i Development ~ I Board 0. 1 ~ :I User's Guide .., TEXAS INSTRUMENTS TMS34010 Software Developtnent Board User's Guide ~ TEXAS INSTRUMENTS IMPORTANT NOTICE Texas Instruments (TI) reserves the right to make changes in the devices or the device specifications identified in this publication without notice. TI advises its customers to obtain the latest version of device specifications to verify, before placing orders, that the information being relied upon by the customer is current. In the absence of written agreement to the contrary, TI assumes no liability for TI applications assistance, customer's product design, or infringement of pat ents or copyrights of third parties by or arising from use of semiconduct9r devices described herein. Nor does TI warrant or represent that any license, either express or implied, is granted under any patent right, copyright, or other intellectual property right of TI covering or relating to any combination, ma chine, or process in which such semiconductor devices might be or are used. WARNING This equipment is intended for use in a laboratory test environment only. It generates, uses, and can radiate radio frequency energy and has not been tested for compliance with the limits for computing devices persuant to Sub part J of Part 15 of FCC rules, which are designed to provide reasonable pro tection against radio frequency interference. Operation of this equipment in other environments may cause interference with radio communications. In which case the user at this own expense will be required to take whatever measures may be required to correct the interference. -

4010, 237 8514, 226 80486, 280 82786, 227, 280 a AA. See Anti-Aliasing (AA) Abacus, 16 Accelerated Graphics Port (AGP), 219 Acce
Index 4010, 237 AIB. See Add-in board (AIB) 8514, 226 Air traffic control system, 303 80486, 280 Akeley, Kurt, 242 82786, 227, 280 Akkadian, 16 Algebra, 26 Alias Research, 169 Alienware, 186 A Alioscopy, 389 AA. See Anti-aliasing (AA) All-In-One computer, 352 Abacus, 16 All-points addressable (APA), 221 Accelerated Graphics Port (AGP), 219 Alpha channel, 328 AccelGraphics, 166, 273 Alpha Processor, 164 Accel-KKR, 170 ALT-256, 223 ACM. See Association for Computing Altair 680b, 181 Machinery (ACM) Alto, 158 Acorn, 156 AMD, 232, 257, 277, 410, 411 ACRTC. See Advanced CRT Controller AMD 2901 bit-slice, 318 (ACRTC) American national Standards Institute (ANSI), ACS, 158 239 Action Graphics, 164, 273 Anaglyph, 376 Acumos, 253 Anaglyph glasses, 385 A.D., 15 Analog computer, 140 Adage, 315 Anamorphic distortion, 377 Adage AGT-30, 317 Anatomic and Symbolic Mapper Engine Adams Associates, 102 (ASME), 110 Adams, Charles W., 81, 148 Anderson, Bob, 321 Add-in board (AIB), 217, 363 AN/FSQ-7, 302 Additive color, 328 Anisotropic filtering (AF), 65 Adobe, 280 ANSI. See American national Standards Adobe RGB, 328 Institute (ANSI) Advanced CRT Controller (ACRTC), 226 Anti-aliasing (AA), 63 Advanced Remote Display Station (ARDS), ANTIC graphics co-processor, 279 322 Antikythera device, 127 Advanced Visual Systems (AVS), 164 APA. See All-points addressable (APA) AED 512, 333 Apalatequi, 42 AF. See Anisotropic filtering (AF) Aperture grille, 326 AGP. See Accelerated Graphics Port (AGP) API. See Application program interface Ahiska, Yavuz, 260 standard (API) AI. -

Development of Synthetic Cameras for Virtual Commissioning
DEVELOPMENT OF SYNTHETHIC CAMERAS FOR VIRTUAL COMMISSIONING Bachelor Degree Project in Automation Engineer 2020 DEVELOPMENT OF SYNTHETIC CAMERAS FOR VIRTUAL COMMISSIONING Bachelor Degree Project in Automation Engineering Bachelor Level 30 ECTS Spring term 2020 Francisco Vico Arjona Daniel Pérez Torregrosa Company supervisor: Mikel Ayani University supervisor: Wei Wang Examiner: Stefan Ericson 1 DEVELOPMENT OF SYNTHETHIC CAMERAS FOR VIRTUAL COMMISSIONING Bachelor Degree Project in Automation Engineer 2020 Abstract Nowadays, virtual commissioning has become an incredibly useful technology which has raised its importance hugely in the latest years. Creating virtual automated systems, as similar to reality as possible, to test their behaviour has become into a great tool for avoiding waste of time and cost in the real commissioning stage of any manufacturing system. Currently, lots of virtual automated systems are controlled by different vision tools, however, these tools are not integrated in most of emulation platforms, so it precludes testing the performance of numerous virtual systems. This thesis intends to give a solution to this limitation that nowadays exists for virtual commissioning. The main goal is the creation of a synthetic camera that allows to obtain different types of images inside any virtual automated system in the same way it would have been obtained in a real system. Subsequently, a virtual demonstrator of a robotic cell controlled by computer vision is developed to show the immense opportunities that synthetic camera can open for testing vision systems. 2 DEVELOPMENT OF SYNTHETIC CAMERAS FOR VIRTUAL COMMISSIONING Bachelor Degree Project in Automation Engineering 2020 Certify of Authenticity This thesis has been submitted by Francisco Vico Arjona and Daniel Pérez Torregrosa to the University of Skövde as a requirement for the degree of Bachelor of Science in Production Engineering. -
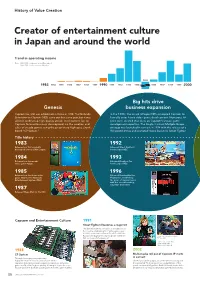
History of Value Creation
History of Value Creation Creator of entertainment culture in Japan and around the world Trend in operating income Note: 1983–1988: Fiscal years ended December 31 1989–2020: Fiscal years ended March 31 1995 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1996 1997 1998 1999 2000 Big hits drive Genesis business expansion Capcom Co., Ltd. was established in Osaka in 1983. The Nintendo In the 1990s, the arrival of Super NES prompted Capcom to Entertainment System (NES) came out that same year, but it was formally enter home video game development. Numerous hit difficult to develop high-quality arcade-level content for, so titles were created that drew on Capcom’s arcade game Capcom focused business development on the creation and development expertise. The Single Content Multiple Usage sales of arcade games using the proprietary high-spec circuit strategy was launched in earnest in 1994 with the release of a board “CP System.” Hollywood movie and animated movie based on Street Fighter. Title history 1983 1992 Released our first originally Released Street Fighter II developed coin-op Little League. for the Super NES. 1984 1993 Released our first arcade Released Breath of Fire video game Vulgus. for the Super NES. 1985 1996 Released our first home video Released Resident Evil for game 1942 for the Nintendo PlayStation, establishing Entertainment System (NES). the genre of survival horror with this record-breaking, long-time best-seller. 1987 Released Mega Man for the NES. Capcom and Entertainment Culture 1991 Street Fighter II becomes a major hit The game became a sensation in arcades across the country, establishing the fighting game genre.