Reference Genomes + Sequence Comparison
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Michael Antoni
Stress Management Effects on Biological and Molecular Pathways in Women Treated for Breast Cancer APS/NCI Conference on “Toward Precision Cancer Care: Biobehavioral Contributions to the Exposome” Chicago IL Michael H. Antoni, Ph.D. Department of Psychology Div of Health Psychology Director, Center for Psycho- Oncology Director, Cancer Prevention and Control Research, Sylvester Cancer Center University of Miami E.g., Stress Management for Women with Breast Cancer • Rationale – Breast Cancer (BCa) is a stressor – Challenges of surgery and adjuvant tx – Patient assets can facilitate adjustment – Cognitive Behavioral Stress Management (CBSM) can fortify these assets in women with BCa – Improving Psychosocial Adaptation may Affect Physiological Adaptation Theoretical Model for CBSM during CA Tx Negative Adapt Positive Adapt Physical Funct Awareness C ∆ Cog Appraisals B Physical Emot Processing + Health Beh. S Health M Relaxation QOL Social Support Normalize endocrine and immune regulation Antoni (2003). Stress Management for Women with Breast Cancer. American Psychological Association. Assessment Time Points T1 T2 T3 T4 B SMART-10 wks. 2-8 wks post 3 months post 6 months post surgery One year post surgery Topics of CBSM Week Relaxation Stress Management 1 PMR 7 Stress & Awareness 2 PMR 4/D.B. Stress & Awareness/Stress Appraisals 3 D.B./PMR Disease-Specific, Automatic Thoughts 4 Autogenics Auto. Thghts, Distortions, Thght Rep. 5 D.B./Visualiz. Cognitive Restructuring 6 Sunlight Med. Effective Coping I 7 Color Meditation Effective Coping -

Role of RUNX1 in Aberrant Retinal Angiogenesis Jonathan D
Page 1 of 25 Diabetes Identification of RUNX1 as a mediator of aberrant retinal angiogenesis Short Title: Role of RUNX1 in aberrant retinal angiogenesis Jonathan D. Lam,†1 Daniel J. Oh,†1 Lindsay L. Wong,1 Dhanesh Amarnani,1 Cindy Park- Windhol,1 Angie V. Sanchez,1 Jonathan Cardona-Velez,1,2 Declan McGuone,3 Anat O. Stemmer- Rachamimov,3 Dean Eliott,4 Diane R. Bielenberg,5 Tave van Zyl,4 Lishuang Shen,1 Xiaowu Gai,6 Patricia A. D’Amore*,1,7 Leo A. Kim*,1,4 Joseph F. Arboleda-Velasquez*1 Author affiliations: 1Schepens Eye Research Institute/Massachusetts Eye and Ear, Department of Ophthalmology, Harvard Medical School, 20 Staniford St., Boston, MA 02114 2Universidad Pontificia Bolivariana, Medellin, Colombia, #68- a, Cq. 1 #68305, Medellín, Antioquia, Colombia 3C.S. Kubik Laboratory for Neuropathology, Massachusetts General Hospital, 55 Fruit St., Boston, MA 02114 4Retina Service, Massachusetts Eye and Ear Infirmary, Department of Ophthalmology, Harvard Medical School, 243 Charles St., Boston, MA 02114 5Vascular Biology Program, Boston Children’s Hospital, Department of Surgery, Harvard Medical School, 300 Longwood Ave., Boston, MA 02115 6Center for Personalized Medicine, Children’s Hospital Los Angeles, Los Angeles, 4650 Sunset Blvd, Los Angeles, CA 90027, USA 7Department of Pathology, Harvard Medical School, 25 Shattuck St., Boston, MA 02115 Corresponding authors: Joseph F. Arboleda-Velasquez: [email protected] Ph: (617) 912-2517 Leo Kim: [email protected] Ph: (617) 912-2562 Patricia D’Amore: [email protected] Ph: (617) 912-2559 Fax: (617) 912-0128 20 Staniford St. Boston MA, 02114 † These authors contributed equally to this manuscript Word Count: 1905 Tables and Figures: 4 Diabetes Publish Ahead of Print, published online April 11, 2017 Diabetes Page 2 of 25 Abstract Proliferative diabetic retinopathy (PDR) is a common cause of blindness in the developed world’s working adult population, and affects those with type 1 and type 2 diabetes mellitus. -

Human CCL3L1 Copy Number Variation, Gene Expression, and The
bioRxiv preprint doi: https://doi.org/10.1101/249508; this version posted January 17, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is Pagemade available 1 of 19 under aCC-BY 4.0 International license. 1 Human CCL3L1 copy number variation, gene expression, and the role of the CCL3L1-CCR5 axis 2 in lung function 3 4 Adeolu B Adewoye (1)*, Nick Shrine (2)*, Linda Odenthal-Hesse (1), Samantha Welsh (3), 5 Anders Malarstig (4), Scott Jelinsky (5), Iain Kilty (5), Martin D Tobin (2,6), Edward J Hollox (1)†, 6 Louise V Wain (2,6)† 7 8 1. Department of Genetics and Genome Biology, University of Leicester, Leicester, UK 9 2. Department of Health Sciences, University of Leicester, Leicester, UK 10 3. UK Biobank, Stockport, UK 11 4. Pfizer Worldwide Research and Development, Stockholm, Sweden. 12 5. Pfizer Worldwide Research and Development, Cambridge, Massachusetts, USA 13 6. National Institute of Health Research Biomedical Research Centre, University of 14 Leicester, Leicester, UK 15 16 * † These authors contributed equally to this work. 17 18 Corresponding authors: Edward J Hollox ([email protected]), Louise V Wain 19 ([email protected]) 20 21 Keywords: copy number variation, lung function, CCL3L1, CCR5, CNV, UK Biobank 22 23 Abstract 24 25 The CCL3L1-CCR5 signaling axis is important in a number of inflammatory responses, including 26 macrophage function, and T-cell-dependent immune responses. Small molecule CCR5 27 antagonists exist, including the approved antiretroviral drug maraviroc, and therapeutic 28 monoclonal antibodies are in development. -
Supplementary Figures and Tables
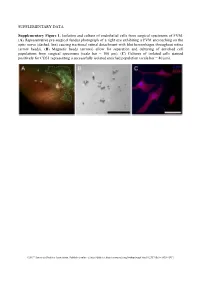
SUPPLEMENTARY DATA Supplementary Figure 1. Isolation and culture of endothelial cells from surgical specimens of FVM. (A) Representative pre-surgical fundus photograph of a right eye exhibiting a FVM encroaching on the optic nerve (dashed line) causing tractional retinal detachment with blot hemorrhages throughout retina (arrow heads). (B) Magnetic beads (arrows) allow for separation and culturing of enriched cell populations from surgical specimens (scale bar = 100 μm). (C) Cultures of isolated cells stained positively for CD31 representing a successfully isolated enriched population (scale bar = 40 μm). ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Figure 2. Efficient siRNA knockdown of RUNX1 expression and function demonstrated by qRT-PCR, Western Blot, and scratch assay. (A) RUNX1 siRNA induced a 60% reduction of RUNX1 expression measured by qRT-PCR 48 hrs post-transfection whereas expression of RUNX2 and RUNX3, the two other mammalian RUNX orthologues, showed no significant changes, indicating specificity of our siRNA. Functional inhibition of Runx1 signaling was demonstrated by a 330% increase in insulin-like growth factor binding protein-3 (IGFBP3) RNA expression level, a known target of RUNX1 inhibition. Western blot demonstrated similar reduction in protein levels. (B) siRNA- 2’s effect on RUNX1 was validated by qRT-PCR and western blot, demonstrating a similar reduction in both RNA and protein. Scratch assay demonstrates functional inhibition of RUNX1 by siRNA-2. ns: not significant, * p < 0.05, *** p < 0.001 ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Table 1. -

Downloaded From
Multiple Products Derived from Two CCL4 Loci: High Incidence of a New Polymorphism in HIV + Patients This information is current as Roger Colobran, Patricia Adreani, Yaqoub Ashhab, Anuska of October 2, 2021. Llano, José A. Esté, Orlando Dominguez, Ricardo Pujol-Borrell and Manel Juan J Immunol 2005; 174:5655-5664; ; doi: 10.4049/jimmunol.174.9.5655 http://www.jimmunol.org/content/174/9/5655 Downloaded from References This article cites 56 articles, 19 of which you can access for free at: http://www.jimmunol.org/content/174/9/5655.full#ref-list-1 http://www.jimmunol.org/ Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists • Fast Publication! 4 weeks from acceptance to publication by guest on October 2, 2021 *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2005 by The American Association of Immunologists All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. The Journal of Immunology Multiple Products Derived from Two CCL4 Loci: High Incidence of a New Polymorphism in HIV؉ Patients1 Roger Colobran,*‡ Patricia Adreani,* Yaqoub Ashhab,* Anuska Llano,† Jose´A. Este´,† Orlando Dominguez,* Ricardo Pujol-Borrell,*‡ and Manel Juan2*‡ Human CCL4/macrophage inflammatory protein (MIP)-1 and CCL3/MIP-1␣ are two highly related molecules that belong to a cluster of inflammatory CC chemokines located in chromosome 17. -

Patients + in HIV Polymorphism Loci: High Incidence of a New Multiple
Multiple Products Derived from Two CCL4 Loci: High Incidence of a New Polymorphism in HIV + Patients This information is current as Roger Colobran, Patricia Adreani, Yaqoub Ashhab, Anuska of September 24, 2021. Llano, José A. Esté, Orlando Dominguez, Ricardo Pujol-Borrell and Manel Juan J Immunol 2005; 174:5655-5664; ; doi: 10.4049/jimmunol.174.9.5655 http://www.jimmunol.org/content/174/9/5655 Downloaded from References This article cites 56 articles, 19 of which you can access for free at: http://www.jimmunol.org/content/174/9/5655.full#ref-list-1 http://www.jimmunol.org/ Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists • Fast Publication! 4 weeks from acceptance to publication by guest on September 24, 2021 *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2005 by The American Association of Immunologists All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. The Journal of Immunology Multiple Products Derived from Two CCL4 Loci: High Incidence of a New Polymorphism in HIV؉ Patients1 Roger Colobran,*‡ Patricia Adreani,* Yaqoub Ashhab,* Anuska Llano,† Jose´A. Este´,† Orlando Dominguez,* Ricardo Pujol-Borrell,*‡ and Manel Juan2*‡ Human CCL4/macrophage inflammatory protein (MIP)-1 and CCL3/MIP-1␣ are two highly related molecules that belong to a cluster of inflammatory CC chemokines located in chromosome 17. -

CCL3L1 and CCL4L1: Variable Gene Copy Number in Adolescents with and Without Human Immunodeficiency Virus Type 1 (HIV-1) Infection
Genes and Immunity (2007) 8, 224–231 & 2007 Nature Publishing Group All rights reserved 1466-4879/07 $30.00 www.nature.com/gene ORIGINAL ARTICLE CCL3L1 and CCL4L1: variable gene copy number in adolescents with and without human immunodeficiency virus type 1 (HIV-1) infection W Shao1, J Tang2, W Song1, C Wang1,YLi2, CM Wilson2,3 and RA Kaslow1,2 1Department of Epidemiology, University of Alabama at Birmingham, Birmingham, AL, USA; 2Department of Medicine, University of Alabama at Birmingham, Birmingham, AL, USA and 3Department of Pediatrics, University of Alabama at Birmingham, Birmingham, AL, USA As members of the chemokine family, macrophage inflammatory protein 1 alpha (MIP-1a) and MIP-1b are unique in that they both consist of non-allelic isoforms encoded by different genes, namely chemokine (C-C motif) ligand 3 (CCL3), CCL4, CCL3- like 1 (CCL3L1) and CCL4L1. The products of these genes and of CCL5 (encoding RANTES, i.e., regulated on activation, normal T expressed and secreted) can block or interfere with human immunodeficiency virus type 1 (HIV-1) infection through competitive binding to chemokine (C-C motif) receptor 5 (CCR5). Our analyses of 411 adolescents confirmed that CCL3 and CCL4 genes occurred invariably as single copies (two per diploid genome), whereas the copy numbers of CCL3L1 and CCL4L1 varied extensively (0–11 and 1–6 copies, respectively). Neither CCL3L1 nor CCL4L1 gene copy number variation showed appreciable impact on susceptibility to or control of HIV-1 infection. Within individuals, linear correlation between CCL3L1 and CCL4L1 copy numbers was moderate regardless of ethnicity (Pearson correlation coefficients ¼ 0.63–0.65, Po0.0001), suggesting that the two loci are not always within the same segmental duplication unit. -

Accuracy and Differential Bias in Copy Number Measurement of CCL3L1 In
Carpenter et al. BMC Genomics 2011, 12:418 http://www.biomedcentral.com/1471-2164/12/418 RESEARCH ARTICLE Open Access Accuracy and differential bias in copy number measurement of CCL3L1 in association studies with three auto-immune disorders Danielle Carpenter1, Susan Walker1, Natalie Prescott2, Joost Schalkwijk3 and John AL Armour1* Abstract Background: Copy number variation (CNV) contributes to the variation observed between individuals and can influence human disease progression, but the accurate measurement of individual copy numbers is technically challenging. In the work presented here we describe a modification to a previously described paralogue ratio test (PRT) method for genotyping the CCL3L1/CCL4L1 copy variable region, which we use to ascertain CCL3L1/CCL4L1 copy number in 1581 European samples. As the products of CCL3L1 and CCL4L1 potentially play a role in autoimmunity we performed case control association studies with Crohn’s disease, rheumatoid arthritis and psoriasis clinical cohorts. Results: We evaluate the PRT methodology used, paying particular attention to accuracy and precision, and highlight the problems of differential bias in copy number measurements. Our PRT methods for measuring copy number were of sufficient precision to detect very slight but systematic differential bias between results from case and control DNA samples in one study. We find no evidence for an association between CCL3L1 copy number and Crohn’s disease, rheumatoid arthritis or psoriasis. Conclusions: Differential bias of this small magnitude, but applied systematically across large numbers of samples, would create a serious risk of false positive associations in copy number, if measured using methods of lower precision, or methods relying on single uncorroborated measurements. -

Table S1. 103 Ferroptosis-Related Genes Retrieved from the Genecards
Table S1. 103 ferroptosis-related genes retrieved from the GeneCards. Gene Symbol Description Category GPX4 Glutathione Peroxidase 4 Protein Coding AIFM2 Apoptosis Inducing Factor Mitochondria Associated 2 Protein Coding TP53 Tumor Protein P53 Protein Coding ACSL4 Acyl-CoA Synthetase Long Chain Family Member 4 Protein Coding SLC7A11 Solute Carrier Family 7 Member 11 Protein Coding VDAC2 Voltage Dependent Anion Channel 2 Protein Coding VDAC3 Voltage Dependent Anion Channel 3 Protein Coding ATG5 Autophagy Related 5 Protein Coding ATG7 Autophagy Related 7 Protein Coding NCOA4 Nuclear Receptor Coactivator 4 Protein Coding HMOX1 Heme Oxygenase 1 Protein Coding SLC3A2 Solute Carrier Family 3 Member 2 Protein Coding ALOX15 Arachidonate 15-Lipoxygenase Protein Coding BECN1 Beclin 1 Protein Coding PRKAA1 Protein Kinase AMP-Activated Catalytic Subunit Alpha 1 Protein Coding SAT1 Spermidine/Spermine N1-Acetyltransferase 1 Protein Coding NF2 Neurofibromin 2 Protein Coding YAP1 Yes1 Associated Transcriptional Regulator Protein Coding FTH1 Ferritin Heavy Chain 1 Protein Coding TF Transferrin Protein Coding TFRC Transferrin Receptor Protein Coding FTL Ferritin Light Chain Protein Coding CYBB Cytochrome B-245 Beta Chain Protein Coding GSS Glutathione Synthetase Protein Coding CP Ceruloplasmin Protein Coding PRNP Prion Protein Protein Coding SLC11A2 Solute Carrier Family 11 Member 2 Protein Coding SLC40A1 Solute Carrier Family 40 Member 1 Protein Coding STEAP3 STEAP3 Metalloreductase Protein Coding ACSL1 Acyl-CoA Synthetase Long Chain Family Member 1 Protein -

Table S1 : Upregulated Intragraft Gene Transcripts in Only Graft Loss Group
Table S1 : Upregulated intragraft gene transcripts in only graft loss group (Table S1a), in only functioning allograft group (Table S1b) and in both groups (Table S1c) compared to normal transplant kidney biopsies Table S1a: Transcript Gene Name Adjusted Cluster ID P value 7898793 Complement component 1, q subcomponent, A chain 0.0176 (C1QA),mRNA 7898799 Complement component 1, q subcomponent, C chain (C1QC), 0.0325 transcript variant 1, mRNA 7899394 Chromosome 1 open reading frame 38 (C1orf38), transcript 0.004 variant 3, mRNA 7906435 Duffy blood group, chemokine receptor (DARC), transcript 0.0007 variant 2, mRNA 7906486 SLAM family member 8 (SLAMF8), mRNA 0.0154 7906757 Fc fragment of IgG, low affinity IIa, receptor (CD32) 0.0062 (FCGR2A), transcript variant 1, mRNA 7912145 Tumor necrosis factor receptor superfamily, member 9 0.0128 (TNFRSF9), mRNA 7922773 Neutrophil cytosolic factor 2 (NCF2), transcript variant 1, 0.004 mRNA 7923043 Potassium channel, subfamily T, member 2 (KCNT2), mRNA 0.002 7926410 Mannose receptor, C type 1 (MRC1), mRNA 0.002 7926451 Mannose receptor, C type 1 (MRC1), mRNA 0.002 7934979 Ankyrin repeat domain 1 (cardiac muscle) (ANKRD1), mRNA 0.008 7943749 Layilin (LAYN), mRNA 0.001 7943998 Nicotinamide N-methyltransferase (NNMT), mRNA 0.005 7948455 Membrane-spanning 4-domains, subfamily A, member 6A 0.006 (MS4A6A), transcript variant 1, mRNA 7951217 Matrix metallopeptidase 7 (matrilysin, uterine) (MMP7), 0.029 mRNA 7953200 Cyclin D2 (CCND2), mRNA 0.01 7953901 C-type lectin domain family 12, member A (CLEC12A), 0.004 -

Cytokines Mapping for Tissue-Specific Expression, Eqtls and GWAS Traits
www.nature.com/scientificreports OPEN Cytokines mapping for tissue‑specifc expression, eQTLs and GWAS traits Lyubov E. Salnikova1,2*, Maryam B. Khadzhieva1,2, Dmitry S. Kolobkov1,3,4, Alesya S. Gracheva1,2, Artem N. Kuzovlev2 & Serikbay K. Abilev1 Dysregulation in cytokine production has been linked to the pathogenesis of various immune‑ mediated traits, in which genetic variability contributes to the etiopathogenesis. GWA studies have identifed many genetic variants in or near cytokine genes, nonetheless, the translation of these fndings into knowledge of functional determinants of complex traits remains a fundamental challenge. In this study we aimed at collection, analysis and interpretation of data on cytokines focused on their tissue‑specifc expression, eQTLs and GWAS traits. Using GO annotations, we generated a list of 314 cytokines and analyzed them with the GTEx resource. Cytokines were highly tissue‑specifc, 82.3% of cytokines had Tau expression metrics ≥ 0.8. In total, 3077 associations for 1760 unique SNPs in or near 244 cytokines were mapped in the NHGRI‑EBI GWAS Catalog. According to the Experimental Factor Ontology resource, the largest numbers of disease associations were related to ‘Infammatory disease’, ‘Immune system disease’ and ‘Asthma’. The GTEx‑based analysis revealed that among GWAS SNPs, 1142 SNPs had eQTL efects and infuenced expression levels of 999 eGenes, among them 178 cytokines. Several types of enrichment analysis showed that it was cytokines expression variability that fundamentally contributed to the molecular origins of considered immune-mediated conditions. Cytokines are regulatory proteins and glycoproteins that are synthesized and secreted by immune system cells and other cell types. Tey regulate innate and acquired immunity, embryogenesis, hematopoiesis, infammation and regeneration processes, and proliferation. -

An Integrated Analysis Reveals Geniposide Extracted from Gardenia Jasminoides Ellis Regulates Calcium Signaling Pathway Essential for Infuenza a Virus Replication
An Integrated Analysis Reveals Geniposide Extracted From Gardenia Jasminoides Ellis Regulates Calcium Signaling Pathway Essential for Inuenza a Virus Replication LiRun Zhou China Academy of Chinese Medical Sciences https://orcid.org/0000-0002-1350-940X Lei Bao China Academy of Chinese Medical Sciences Yaxin Wang China Academy of Chinese Medical Sciences Mengping Chen China Academy of Chinese Medical Sciences Yingying Zhang Beijing University of Chinese Medicine Aliated Dongzhimen Hospital Zihan Geng China Academy of Chinese Medical Sciences Ronghua Zhao China Academy of Chinese Medical Sciences Jing Sun China Academy of Chinese Medical Sciences Yanyan Bao China Academy of Chinese Medical Sciences Yujing Shi China Academy of Chinese Medical Sciences Rongmei Yao China Academy of Chinese Medical Sciences Shanshan Guo ( [email protected] ) China Academy of Chinese Medical Sciences Xiaolan Cui China Academy of Chinese Medical Sciences Research Page 1/30 Keywords: Geniposide, Inuenza A virus, RNA polymerase, Calcium signaling pathway, CAMKII Posted Date: August 9th, 2021 DOI: https://doi.org/10.21203/rs.3.rs-764303/v1 License: This work is licensed under a Creative Commons Attribution 4.0 International License. Read Full License Page 2/30 Abstract Background Geniposide, an iridoid glycoside puried from the fruit of Gardenia jasminoides Ellis, has been reported to possess pleiotropic activity against different diseases. In particular, geniposide possesses a variety of biological activities and exerts good therapeutic effects in the treatment of several strains of the inuenza virus. However, the molecular mechanism for the therapeutic effect has not been well dened. Methods This study aimed to investigate the mechanism of geniposide on inuenza A virus (IAV).