Rapidio® the Embedded System Interconnect
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Compactpci Serial ...The Smart Solution
CompactPCI® Serial ... ... the Smart Solution © EKF •www. ekf.com CompactPCI® Serial Systems Designed for performance • 40 x PCI® Express • 8 x Gigabit Ethernet • 8 x SATA • 8 x USB3 CompactPCI® Serial - the Smart Solution www.ekf.com/s/serial.html © EKF •www. ekf.com CompactPCI® Serial Systems CPCI Serial backplanes for optimum throughput CompactPCI® Serial - the Smart Solution Sample Backplanes CompactPCI® Serial The CompactPCI® Serial system slot is located either most left or most right © EKF •www. ekf.com CompactPCI® Serial Systems Reverse order backplanes (system slot right aligned) for CPU cards with 4HP to 12HP front panel CompactPCI® Serial - the Smart Solution www.ekf.com/s/serial.html © EKF •www. ekf.com CompactPCI® Serial Systems CPCI® Serial BLUBRICK series - ultra rugged CompactPCI® Serial - the Smart Solution www.ekf.com/s/srs/srs1201/srs1201.html SRS-1201-BLUBRICK CompactPCI® Serial © EKF • www.ekf.com CompactPCI® Serial Systems CPCI Serial BluBoxx series - small and economic www.ekf.com/s/srs/srs3201/srs3201.html CompactPCI® Serial - the Smart Solution SRS-3201-BLUBOXX CompactPCI® Serial © EKF •www. ekf.com CompactPCI® Serial Systems CPCI Serial rugged system racks www.ekf.com/s/srs/srs4401/srs4401.html CompactPCI® Serial - the Smart Solution SRS-4401-SERIAL CompactPCI® Serial © EKF •www. ekf.com CompactPCI® Serial Systems CPCI® Serial racks 84HP CompactPCI® Serial - the Smart Solution www.ekf.com/s/srs/srs8401/srs8401.html SRS-8401-SERIAL CompactPCI® Serial © EKF •www. ekf.com Embedded Blue® CPCI® Serial boxed solutions • fixed & custom configuration CompactPCI® Serial - the Smart Solution www.ekf.com/b/bc200/bc200.html BC200 Embedded Blue® © EKF •www. -
3U Compactpci Serial Communications Products
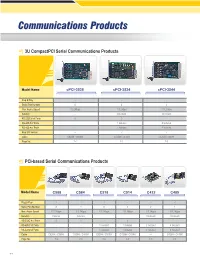
CommunicationsCommunications ProductsProducts 3U CompactPCI Serial Communications Products Model Name cPCI-3538 cPCI-3534 cPCI-3544 Plug & Play √ √ √ Serial Port Number 8 4 4 Max. Async Speed 115.2Kbps 115.2Kbps 115.2Kbps Isolation - On-board On-board RS-232C # of Ports 8 3 - RS-485 # of Ports - 1 Isolated 4 Isolated RS-422 # of Ports - 1 Isolated 4 Isolated Rear I/O Version √ √ √ Cable C825M / C809M C425M / C409M C425M / C409M Page No. 7-4 7-4 7-5 PCI-based Serial Communications Products 7 Model Name C588 C584 C518 C514 C422 C485 Plug & Play √ √ √ √ √ √ Serial Port Number 8 4 8 4 2 4 Max. Async Speed 115.2Kbps 115.2Kbps 115.2Kbps 115.2Kbps 115.2Kbps 115.2Kbps Isolation External External –– –– On-board On-board RS-232C # of Ports 8 4 7 3 - - RS-485 # of Ports - - 1 Isolated 1 Isolated 2 Isolated 4 Isolated RS-422 # of Ports - - 1 Isolated 1 Isolated 2 Isolated 4 Isolated Cable C825M / C809M C425M / C409M C825M / C809M C425M / C409M –– C425M / C409M Page No. 7-3 7-3 7-3 7-3 7-3 7-3 7-1 PCI-7841/cPCI-7841PCI-7841 Dual-port Isolated CAN Interface Cards Introduction 1 The PCI-7841/cPCI-7841 is a Controller Area Network (CAN) interface Software card. It supports a dual-port CAN's interface that can run independently or bridged at the same time. The built-in CAN controller of this card is Philips SJA1000, which provides bus arbitration and error detection with auto correction and re-transmission function. 2 GEME Series Controller Area Network The CAN (Controller Area Network), a serial bus system originally 3 developed by Bosch for use in automobiles, is increasingly being used DPAC for industry automation. -

ADLINK Technology, Inc
Enduring Performance ADLINK’s extensive rugged portfolio delivers power, flexibility, affordability, endurance and longevity CompactPCI | Enduring Performance In the most severe environments, CompactPCI shines brightest. Standard hardware is typically designed for home or office use, which means climate-controlled spaces and narrow operating temperature ranges. Outside of these parameters, failure can quickly go from possibility to reality. From the hottest places on Earth to the bleak expanse of outer space, CompactPCI endures where other solutions falter. Benefitting from decades of research and development, CompactPCI has emerged as an outstanding platform across a range of industries. The CompactPCI architecture perfectly suits mission-critical situations that demand resilience and high performance. ADLINK is dedicated to offering a robust portfolio of cost-effective, cutting-edge CompactPCI solutions for today’s applications and years into the future. P 1 At ADLINK, we strive to be at the forefront of innovation. Our commitment to building best-of-breed products for many demanding verticals makes us an industry leader. When we support a particular technology, we are fully committed investing resources and joining relevant industry consortia. As such, ADLINK is an executive member of the PCI Industrial Core™, Xeon®, and Atom® processors. ADLINK also owns and Computer Manufacturers Group (PICMG) consortium, which has full control of its manufacturing facilities, based in our initially introduced CompactPCI in 1999. By participating Asia headquarters. Incorporating top-tier hardware into our in PICMG, we are able to contribute expertise that guides own manufacturing capabilities lets ADLINK create products future CompactPCI development and helps us position the with exceptional life spans. -

HARTMANN ELEKTRONIK Innovationen Aus Erfahrung Innovations Bases on Experience
System platforms 03 Komfortlösungen CPCI, VME, VPX Comfort solutions CPCI, VME, VPX Inhalt Contents Einführung 4 Introduction 4 Systemplattformen System platforms PXI 4 HE, 63 TE 6 PXI 4 U, 63 HP 6 CompactPCI ® CompactPCI ® • CPCI 3 HE, 30 TE 7 • CPCI 3 U, 30 HP 7 • CPCI 3,5 HE, 42 TE 8 • CPCI 3,5 U, 42 HP 8 • CPCI 3 HE, 84 TE 9 • CPCI 3 U, 84 HP 9 • CPCI 6 HE, 84 TE 10 • CPCI 6 U, 84 HP 10 • CPCI 4 HE, 63 TE 11 • CPCI 4 U, 63 HP 11 • CPCI 1 HE, 84 TE 12 • CPCI 1 U, 84 HP 12 • CPCI 2 HE, 84 TE 14 • CPCI 2 U, 84 HP 14 • CPCI 4 HE, 84 TE 16 • CPCI 4 U, 84 HP 16 CompactPCI ® 2.16 CompactPCI ® 2.16 • CPCI 2.16 4 HE, 84 TE 18 • CPCI 2.16 4 U, 84 HP 18 • CPCI 2.16 10 HE, 84 TE 19 • CPCI 2.16 10 U, 84 HP 19 VME64x VME64x • VME64x 1 HE, 84 TE 20 • VME64x 1 U, 84 HP 20 • VME64x 2 HE, 84 TE 22 • VME64x 2 U, 84 HP 22 • VME64x 4 HE, 84 TE 24 • VME64x 4 U, 84 HP 24 • VME64x 7 HE, 84 TE 26 • VME64x 7 U, 84 HP 26 VME 7 HE, 84 TE 28 VME 7 U, 84 HP 28 VXS 11 HE, 84 TE 29 VXS 11 U, 84 HP 29 VPX 4 HE, 84 TE 30 VPX 4 U, 84 HP 30 Baugruppenträger Subracks Open Frame 32 Open Frame 32 CompactPCI ® CompactPCI ® • CPCI 3 HE, 30 TE 34 • CPCI 3 U, 30 HP 34 • CPCI 3 HE, 84 TE 35 • CPCI 3 U, 84 HP 35 • CPCI 6 HE, 84 TE 37 • CPCI 6 U, 84 HP 37 VME64x VME64x • VME64x 3 HE, 84 TE 38 • VME64x 3 U, 84 HP 38 • VME64x 6 HE, 84 TE 39 • VME64x 6 U, 84 HP 39 Baugruppenträgerzubehör Accessories for subracks Zubehör 41 Accessories 41 Shelfmanager 42 Shelf manager 42 Netzteile 50 Power supplies 50 Lüfterschublade 1 HE, 84 TE 52 Fan tray 1 U, 84 HP 52 Kundenspezifi sche Lösungen 53 Customized Solutions 53 Die passenden Bausteine für Ihren Erfolg Exactly the right modules for your success 4 HARTMANN ELEKTRONIK Innovationen aus Erfahrung Innovations bases on experience Hartmann Elektronik ist ein Hartmann Elektronik is a langjähriger Partner der Embedded longstanding partner of the Industrie und verfügt über embedded industry and has a variety eine Vielzahl unterschiedlicher of different backplanes. -

20G022-00 E1 User Manual
20G022-00 E2 – 2014-04-10 User Manual G22 – 3U CompactPCI® Serial Intel® Core™ i7 CPU Board Configuration example G22 - 3U CompactPCI® Serial Intel® Core™ i7 CPU Board G22 - 3U CompactPCI® Serial Intel® Core™ i7 CPU Board The G22 is a versatile 4HP/3U single-board computer supporting a multitude of modern serial interfaces according to the CompactPCI® Serial standard. It is thus perfectly suited for data-intensive applications which require high computing- power. The CPU card is equipped with the Intel® third-generation Core i7 processor running at up to 3.3 GHz maximum turbo frequency and offering the latest multi- core processor architecture from Intel® with full 64-bit support. The processor frequency can be stepped down via the BIOS to lower power consumption and make the board more suitable for high temperatures. The G22 supports the Intel® Active Management technology which makes it possible to access the board via the network even when it is in soft-off or standby state. For system security, a Trusted Platform Module is available on request. The memory configuration of the G22 includes a state-of-the-art fast DDR3 DRAM which is soldered to the board to guarantee optimum shock and vibration resistance. An mSATA disk connected via a SATA channel and a microSD™ card device which is connected via a USB interface offer nearly unlimited space for user applications. The board delivers an excellent graphics performance. Two DisplayPort® interfaces are accessible at the board front. Using an external adapter two HDMI or two DVI ports can also be realized. -

User Guide SC3-LARGO • Compactpci ® Serial CPU Card 5Th Generation Intel® Core™ Processor (Broadwell H)
User Guide SC3-LARGO • CompactPCI ® Serial CPU Card 5th Generation Intel® Core™ Processor (Broadwell H) Document No. 7951 • Edition 20 • 3rd April 2019 User Guide • SC3-LARGO • CompactPCI® Serial CPU Board • Intel® CoreTM 5xxx Processor Contents About this Manual........................................................... 5 Edition History......................................................... 5 Related Documents..................................................... 6 Nomenclature......................................................... 6 Trade Marks .......................................................... 6 Legal Disclaimer - Liability Exclusion ......................................... 6 Standards............................................................ 7 Overview............................................................. 8 Technical Features .......................................................... 10 Feature Summary ..................................................... 10 Power Requirements................................................... 15 Block Diagram........................................................ 16 Top View Component Assembly .......................................... 17 Bottom View Component Assembly........................................ 18 Front Panel Connectors ................................................. 19 Front Panel Switches & Indicators ......................................... 19 On-Board Connectors & Sockets .......................................... 20 Pin Headers......................................................... -

Embedded Modules Industrial Pcs • Systems & Customization
Embedded modules l Industrial PCs • Systems & Customization Our membership PC/104 Consortium is an international organization of The OPC Foundation is dedicated to ensuring interoperabil - PC/104 products manufacturers that maintains the PC/104 ity in automation by creating and maintaining open speci - specifications, disseminates PC/104 technology, and pro - fications that standardize the communication of acquired motes the welfare of its members. process data, alarm and event records, historical data, and Executive Member batch data to multi-vendor enterprise systems and be - tween production. PICMG (PCI Industrial Computer Manufacturers Group) is a consortium of companies who collaboratively develop The EtherCAT Technology Group (ETG) is the forum in open specifications for high performance telecommunica - which key user companies from various industries and tions and industrial computing applications. leading automation suppliers join forces to support, pro - Associate Member mote and advance the EtherCAT technology. EtherCAT Technology Group aims to ensure the compatibility of EtherCAT implementations by defining functional require - Intel ® Embedded and Communications Alliance (Intel ® ments, conformance tests as well as certification proce - ECA) is a community of developers and solution providers dures. committed to the design and implementation of modular systems based on Intel technologies in the area of com - StackPC – New Standard of Embedded Stackable Systems munication and embedded applications. Design. The StackPC Specification defines new approach to stackable systems design and development. The spec - CAN in Automation (CiA) is the international users’ and ification includes all valuable heritage of PC/104 standards manufacturers’ organization that develops and supports along with the new features of StackPC connector. The CAN-based higher-layer protocols. -

Serial Communications Products
Serial Communications Products 3U CompactPCI Serial Communications Products Model Name cPCI-3538 cPCI-3534 cPCI-3544 Plug & Play √ √ √ Serial Port Number 8 4 4 Max. Async Speed 115.2 kbps 115.2 kbps 115.2 kbps Isolation - On-board On-board RS-232C # of Ports 8 3 - RS-485 # of Ports - 1 Isolated 4 Isolated RS-422 # of Ports - 1 Isolated 4 Isolated Rear I/O Version √ √ √ Cable C825M / C809M C425M / C409M C425M / C409M Page No. 10-4 10-4 10-5 PCI-based Serial Communications Products Model Name C588 C584 C518 C514 C422 C485 Plug & Play √ √ √ √ √ √ Serial Port Number 8 4 8 4 2 4 Max. Async Speed 115.2 kbps 115.2 kbps 115.2 kbps 115.2 kbps 115.2 kbps 115.2 kbps Isolation External External - - On-board On-board RS-232C # of Ports 8 4 7 3 - - RS-485 # of Ports - - 1 Isolated 1 Isolated 2 Isolated 4 Isolated RS-422 # of Ports - - 1 Isolated 1 Isolated 2 Isolated 4 Isolated Cable C825M / C809M C425M / C409M C825MI / C809MI C425M / C409M - C425M / C409M Page No. 10-3 10-3 10-3 10-3 10-3 10-3 10-1 www.adlinktech.com 1 Software & PCI-7841 / cPCI-7841 Utilities Dual-port Isolated CAN Interface Cards 2 DAQ Introduction 3 The PCI-7841/cPCI-7841 is a Controller Area Network (CAN) interface card. It supports a dual-port CAN interface that can run independently or bridged together. The built-in CAN controller is a Philips SJA1000, PXI which provides bus arbitration and error detection with auto correction and re-transmission functionality. -

System Solutions
System Solutions Networked with the technologies of the future Your Partner FOR SINGLE-SOURCE MECHANICAL AND ELECTRONIC SYSTEMS nVent, with SCHROFF brand products, has been one of TABLE OF CONTENTS the worldwide leading developers and manufacturers of components and systems for over 50 years. Together we Scope of services ............................................................................... 3 can solve any technical challenge. Throughout this process innovation, cost optimization, component standardization as Open standards .................................................................................. 4 well as short development times are our focus. Markets ................................................................................................. 5 Whether they are system solutions that conform to standards, AdvancedTCA ...................................................................................... 6 modified standard components or even custom developments, we offer our expertise in mechanical and electronic systems. MicroTCA .............................................................................................. 7 Our development capabilities extend to backplanes, power CompactPCI ........................................................................................ 8 supplies and system management solutions. We provide fully-equipped and tested systems from a single source with VME, VXS and VPX ............................................................................. 9 design, project management, -

Railway Communication
WHITEPApeR RAILWAY COMMUNICATION COMPACT PCI seRIAL FAst AND SAFE Railway technology needs to meet the highest standards of safety, reliability and availability. The most widely used, proven CompactPCI standard with its parallel bus structure has now reached the limits of its performance capacity. System specialist ELMA presents compatible migration paths to systems with state-of-the-art, high-speed serial architectures such as Com- pactPCI Serial and CompactPCI PlusIO. Systems that will be used in railway technology must meet chanical form factors in single or double Eurocard formats. the highest requirements. They include maximum reliabil- Many sub-standards are also defined for a wide variety of ity and availability even under adverse environmental mechanical railway standards and electrical requirements. conditions such as extreme temperatures (e.g. -40° C to 85° C), dust, moisture, and mobile operation. In addition, WHAT ARE TODAY'S the systems must be impervious to the strong electric and CHALLENGes? magnetic fields that occur in the rail sector and they must The problem is that CompactPCI is still based on the exhibit excellent EMC performance. parallel bus structures typical of recent decades and that the connectors defined by the standard are also starting Because developing such systems from scratch is so ex- to show their age. This limits the available bandwidth pensive, suppliers of railway technology started, at a very relatively clearly to rates up to 500 Mbps. With se- early stage, to rely on modular, international standards- rial buses winning the battle for the PC world with PCI based systems capable of implementing requirements Express in 2003, it is also becoming increasingly difficult faster and more cheaply due to the properties of this to source highly-integrated active components with direct type of modular system architecture. -

3U Compactpci® Serial Intel® Core™ I7 CPU Board
Embedded Solutions for Transportation and Industrial Markets www.men.de/products/02G022-.html G22 – 3U CompactPCI® Serial Intel® Core™ i7 CPU Board n Intel® Core™ i7, 3rd generation n Quad-core 64-bit processor n 4 HP system master and peripheral slot n PICMG CPCI-S.0 CompactPCI® Serial n 4 or 8 GB DDR3 DRAM soldered, ECC n mSATA and microSD™ card slots n Standard front I/O: 2 DisplayPorts, 2 Gb Ethernet, 2 USB 2.0 n Standard rear I/O: 7 PCIe®, 4 USB 2.0, 4 USB 3.0, 5 SATA, DisplayPort®/HDMI n Rear I/O via mezzanine board: up to 8 Gigabit Ethernet n Intel® Turbo Boost, Hyper-Threading, AMT 8.0 n Open CL support The G22 is a versatile 4HP/3U single-board computer The board delivers an excellent graphics performance. Two DisplayPort® supporting a multitude of modern serial interfaces interfaces are accessible at the board front. Using an external adapter according to the CompactPCI® Serial standard. It is two HDMI or two DVI ports can also be realized. In addition the thus perfectly suited for data-intensive applications standard front I/O comprises two PCIe®-driven Gigabit Ethernet and two which require high computing-power. The CPU card is USB 2.0 ports. equipped with the Intel® third-generation Core i7 Serial interfaces at the rear I/O connectors are 4 USB 2.0, 4 USB 3.0, 5 processor running at up to 3.3 GHz maximum turbo SATA interfaces, one DisplayPort® or HDMI, 5 PCI Express® x1 links, and frequency and offering the latest multi-core processor two PEG x8 links. -
Compactpci Serial – Compendium
CompactPCI Serial – Compendium Both CompactPCI PlusIO and CompactPCI Serial is based on CompactPCI, an established standard for building cost-effective, industrial and reliable computers. Users appreciate the modularity, robustness and economic efficiency of CompactPCI. With the new standards they get all these advantages plus fast serial data transfer – including the migration path. Content CompactPCI Serial – Compendium ......................................................................................... 1 History of a New Standard ....................................................................................................... 4 CompactPCI Serial ................................................................................................................... 7 Architecture Overview ................................................................................................................................7 Key Characteristics ............................................................................................................................. 10 Wiring and Connectors ........................................................................................................................ 11 Look Back on CompactPCI: Keep What is Tried and Tested ............................................................. 13 Computer Set-Up as a Star and Mesh .................................................................................................... 13 Modern Computer Architecture ..........................................................................................................