Pronunciation-Enhanced Chinese Word Embedding
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
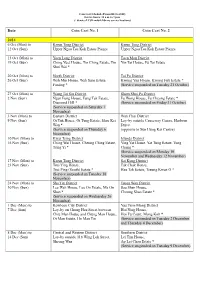
Coin Cart Schedule (From 2014 to 2020) Service Hours: 10 A.M
Coin Cart Schedule (From 2014 to 2020) Service hours: 10 a.m. to 7 p.m. (* denotes LCSD mobile library service locations) Date Coin Cart No. 1 Coin Cart No. 2 2014 6 Oct (Mon) to Kwun Tong District Kwun Tong District 12 Oct (Sun) Upper Ngau Tau Kok Estate Piazza Upper Ngau Tau Kok Estate Piazza 13 Oct (Mon) to Yuen Long District Tuen Mun District 19 Oct (Sun) Ching Yuet House, Tin Ching Estate, Tin Yin Tai House, Fu Tai Estate Shui Wai * 20 Oct (Mon) to North District Tai Po District 26 Oct (Sun) Wah Min House, Wah Sum Estate, Kwong Yau House, Kwong Fuk Estate * Fanling * (Service suspended on Tuesday 21 October) 27 Oct (Mon) to Wong Tai Sin District Sham Shui Po District 2 Nov (Sun) Ngan Fung House, Fung Tak Estate, Fu Wong House, Fu Cheong Estate * Diamond Hill * (Service suspended on Friday 31 October) (Service suspended on Saturday 1 November) 3 Nov (Mon) to Eastern District Wan Chai District 9 Nov (Sun) Oi Yuk House, Oi Tung Estate, Shau Kei Lay-by outside Causeway Centre, Harbour Wan * Drive (Service suspended on Thursday 6 (opposite to Sun Hung Kai Centre) November) 10 Nov (Mon) to Kwai Tsing District Islands District 16 Nov (Sun) Ching Wai House, Cheung Ching Estate, Ying Yat House, Yat Tung Estate, Tung Tsing Yi * Chung * (Service suspended on Monday 10 November and Wednesday 12 November) 17 Nov (Mon) to Kwun Tong District Sai Kung District 23 Nov (Sun) Tsui Ying House, Tak Chak House, Tsui Ping (South) Estate * Hau Tak Estate, Tseung Kwan O * (Service suspended on Tuesday 18 November) 24 Nov (Mon) to Sha Tin District Tsuen Wan -
Online Brochure 01
123 Bulkeley Street, Hung Hom, Kowloon PRIME LOCATION The Grand Blossom Business and Entertainment Visiting Mainland China Ultimate Lifestyle Occupies a prime location in proximity to the Ho Man Tin Just minutes away from the vibrancy of the commercial and To pay a visit to the Mainland China, get onto the East Rail For ultimate retail, dining and entertainment indulgence, the and Hung Hom MTR Station, where guests can avail of the entertainment hub of Tsim Sha Tsui, the 33-storey apartment Line MTR from Hung Hom Station to Lo Wu / Lok Ma Chau. nearby Whampoa Garden is only a five-minute walk away. services of both the East Rail Line and West Rail Line. block lies in a bustling neighborhood. A journey to the core The all-inclusive community center features a comprehensive commercial district of Central is also only 30 minutes via shopping complex which spans over 1.4 million sq.ft. cross-harbor bus 115. N ACCESS Ho Man Tin Station 何文田站 To Ho Man Tin MTR Station To Whampoa Gardens (3 mins) (8 - 12 mins) 6, 6A (5 mins) To Hung Hom MTR Station (10 mins) To Hong Kong International Airport 5C, 8 (6 mins) E23 (70 mins) To Central Station To Kai Tak Cruise Terminal 115 (30 mins) 219X (50 mins) To Tsim Sha Tsui Station To Hung Hom Ferry Pier (Ferry to North Point) 6, 6A, 8, 8A (10 mins) 15 (15 mins) To Mong Kok Station 6C, 6F, 212 (15 mins) On Foot Bus Route Hung Hom Pier 紅磡碼頭 Minibus Route Hung Hom Station 紅磡站 A3 2 Bathrooms with Shower Booths Covered Car Parking Spaces APARTMENTS Twice-a-week Housekeeping and Laundry Services 24 Hours Round-the-clock Professional Management and Security Services Full Kitchen Facilities Kitchenware Electronic Hotel Lock and RFID Keycard Electronic In-room Safe Unlimited Utilities Package Unlimited High-speed Wi-Fi Package FEATURES Television Set Wall-mounted Room Air Conditioning 24-hr House Key Reading Furniture TV Set Security Keeping Card Lounge Bathroom Kitchenware Laundry High Speed Utilities Fitness Amenities Wifi Package Area Gross Size: 700 - 763 sq. -

Useful Information on Hong Kong Where to Stay
Visiting Island School Island School’s Senior School will be based at Shatin Wai from 15 December 2017. This relocation is projected until July 2021 when the school with return to its original site (and new school buildings) on Borrett Road. The Key contact for visits is Rebecca Lucas-Timpany. Island School Higher Education Counselling Team: Roger Wilkinson – [email protected] Rebecca Lucas-Timpany – [email protected] Awing Lui – [email protected] Shirly Cheng-Yuen – [email protected] Other contact details: Tel: (852) 2230 4700 Email: [email protected] School website: www.island.edu.hk Best time to visit us: 10:20 – 11:40AM - Monday, Tuesday, Wednesday, and Thursday 12:55 – 1:20PM - Monday, Tuesday, and Thursday 11:40AM -12:20PM - Wednesdays Show this to your taxi driver: Address: Island School – Shatin Wai campus 沙田圍博康邨 Pok Hong Estate, Shatin Wai, <博華樓對面> Hong Kong Getting here: Taxi: A taxi from Central (HK$160) will take between 30 to 40 minutes and from schools on Kowloon side (HK$40-100) around 10 to 30 minutes. If you are coming from Hong Kong side it’s often hard to get a taxi to take you to the Shatin. Make sure that you ask if the taxi is a ‘Cross-Harbour’ taxi. A red taxi will be able to take you to any part of Hong Kong that you wish to go to with the exception of Lantau and Discovery Bay. MTR: The nearest stop to school is Shatin Wai on the Brown Line. -

Annex II Government Buildings in Kowloon City District
Annex II Government Buildings in Kowloon City District (Information provided by Bureaux and Departments) Buildings Year of Uses Commissioning Hung Hom Municipal Services Building 1996 Public market Public library Sport facilities Office Kowloon City Municipal Services 1988 Public market Building Public library Sport facilities Cleaning services Public facilities To Kwa Wan Market and Government 1983 District leisure services Offices Public library Social welfare services Labour services Kowloon City Government Offices 2013 Community hall Home affairs enquiry centre Medical services Office Trade and Industry Tower 2015 Community hall Labour services Post office Student financial assistance services Trade and industry services Lands services Teacher registration Civil Engineering and Development 1976 Office Building Licences and permits application services Civil Engineering Library Kowloon Animal Management Centre 1960 Animal Management Centre In order to release the existing site for public housing development and improve the facilities and services of the Kowloon Animal Management Centre (AMC(K)), the Government plans to construct an Animal Management and Animal Welfare Building Complex in the Kai Tak Development Area for reprovisioning of AMC(K) and provision of additional space and facilities Kowloon Hospital 1952 Medical services Hong Kong Eye Hospital 2012 Medical services Chung Yee Street Driving Test Centre 1993 Driving test centre Tin Kwong Road Driving Test Centre 1978 Driving test centre Pui Ching Road Driving Test Centre 1961 -

Office Address of the Labour Relations Division
If you wish to make enquiries or complaints or lodge claims on matters related to the Employment Ordinance, the Minimum Wage Ordinance or contracts of employment with the Labour Department, please approach, according to your place of work, the nearby branch office of the Labour Relations Division for assistance. Office address Areas covered Labour Relations Division (Hong Kong East) (Eastern side of Arsenal Street), HK Arts Centre, Wan Chai, Causeway Bay, 12/F, 14 Taikoo Wan Road, Taikoo Shing, Happy Valley, Tin Hau, Fortress Hill, North Point, Taikoo Place, Quarry Bay, Hong Kong. Shau Ki Wan, Chai Wan, Tai Tam, Stanley, Repulse Bay, Chung Hum Kok, South Bay, Deep Water Bay (east), Shek O and Po Toi Island. Labour Relations Division (Hong Kong West) (Western side of Arsenal Street including Police Headquarters), HK Academy 3/F, Western Magistracy Building, of Performing Arts, Fenwick Pier, Admiralty, Central District, Sheung Wan, 2A Pok Fu Lam Road, The Peak, Sai Ying Pun, Kennedy Town, Cyberport, Residence Bel-air, Hong Kong. Aberdeen, Wong Chuk Hang, Deep Water Bay (west), Peng Chau, Cheung Chau, Lamma Island, Shek Kwu Chau, Hei Ling Chau, Siu A Chau, Tai A Chau, Tung Lung Chau, Discovery Bay and Mui Wo of Lantau Island. Labour Relations Division (Kowloon East) To Kwa Wan, Ma Tau Wai, Hung Hom, Ho Man Tin, Kowloon City, UGF, Trade and Industry Tower, Kowloon Tong (eastern side of Waterloo Road), Wang Tau Hom, San Po 3 Concorde Road, Kowloon. Kong, Wong Tai Sin, Tsz Wan Shan, Diamond Hill, Choi Hung Estate, Ngau Chi Wan and Kowloon Bay (including Telford Gardens and Richland Gardens). -

First, Welcome to Hong Kong!
NATIVE ENGLISH SPEAKING TEACHERS’ ASSOCIATION www.nesta.hk First, welcome to Hong Kong! The NESTA Executive and members would like to congratulate you on acceptance to the Education Bureau’s (EDB) NET Scheme and share with you some useful information when coming from a long distance. It is important to fill out all the proper forms and submit them to your school on time so you will get your special allowance, flight reimbursement, baggage allowance, and other contractual benefits in a timely manner. The EDB processes paperwork by the 7th of each month, so make sure you give the school any necessary documents well before that date, and it may be good to inform them of this deadline. Otherwise, you will have to wait a whole month to get paid or refunded. The application forms for the reimbursement and allowances can be found on our website at: https://nesta.hk/net-info/useful-forms/ The cost of accommodations in Hong Kong can be quite expensive, hence the reason why the EDB provides NETs in the Scheme a special allowance to cover housing costs. Please be aware that many landlords in Hong Kong require two month’s rental deposit in addition to the first month’s rent. Most also require that you have a Hong Kong ID before renting, so you may need to find some temporary accommodation. In addition to the usual hotel stay, you may want to consider renting a serviced apartment for a few months or using Airbnb to rent temporary private accommodation. To avoid pitfalls with cable, internet and mobile phone companies, please feel free to contact one of our mentors under “Need more help? Ask a mentor…” Here are additional websites with serviced apartment listings: 1. -

10 Additional MTR Stations and Vending Machines for Distributing COVID-19 Specimen Collection Packs
PR086/20 18 December 2020 10 Additional MTR Stations and Vending Machines for Distributing COVID-19 Specimen Collection Packs The MTR Corporation set up vending machines at ten MTR stations for the public to collect COVID-19 specimen collection packs on 7 December 2020 and the arrangement has been smooth so far. To provide greater convenience to the community, following communication with relevant government departments, the distribution of specimen collection packs will be extended to ten more stations tomorrow (19 December 2020), making the packs available at 20 MTR stations. The ten additional stations are Shau Kei Wan, Wan Chai, Sai Ying Pun, Ho Man Tin, Prince Edward, Kai Tak, Wu Kai Sha, Tsuen Wan West, Sheung Shui and Tung Chung stations. The Corporation will continue to install more vending machines and targets to have two machines in each of the 20 stations by early 2021. The supply of the specimen collection packs by government contractor will be at about 14,000 packs per day and the amount will be suitably adjusted based on actual demand. The MTR Mobile and MTR website will continue to provide updates on the supply at stations. (Please refer to the annex for details about the locations of the vending machines.) Members of the public can scan the QR codes near the vending machines for information about returning the specimen collected. Notices about the designated General Out-patience Clinics of the Hospital Authority or clinics of the Department of Health accepting specimen collected near the relevant stations will also be on display. Please refer to this government website for details about returning specimen collected: https://www.coronavirus.gov.hk/eng/early- testing.html MTR calls on members of the public collecting the packs to maintain social distance and personal hygiene. -

PR003/20 17 January 2020 Tuen Ma Line Phase 1 Commences Service
PR003/20 17 January 2020 Tuen Ma Line Phase 1 commences service on 14 February 2020 The MTR Corporation is making its final preparation for the opening of Tuen Ma Line (“TML”) Phase 1 on 14 February 2020, commencing services at three new stations, namely Hin Keng Station, the expanded part of Diamond Hill Station and Kai Tak Station. The MTR Corporation will provide special fare promotions for TML Phase 1. Upon the opening of TML Phase 1, passengers travelling on the Ma On Shan Line (“MOL”) will be able to travel to Kai Tak Station in East Kowloon via Hin Keng Station and Diamond Hill Station without the need to interchange. The expanded Diamond Hill Station will become a new interchange station between TML and the Kwun Tong Line, allowing passengers to travel from the New Territories (NT) North and NT East districts to the East Kowloon and Hong Kong Island East districts in a more efficient and convenient manner. Such new routing will help relieve the current peak passenger load between Tai Wai and Kowloon Tong Stations on the East Rail Line. At the end of January, all passenger trains on the MOL will carry out non-passenger trains testing along the new railway section, i.e. between Hin Keng and Kai Tak Stations. Train frequency of the MOL during peak hours will be slightly adjusted to around 3.5 minutes intervals, similar to the operation arrangements upon TML Phase 1 Opening. Passengers are reminded to pay attention to our announcement and arrangements. The timing for the full opening of TML would depend on the implementation of the suitable measures at Hung Hom Station extension and its connecting structures, and is expected to take place in 2021. -

12Th September, 1935
HONG KONG LEGISLATIVE COUNCIL. 153 12th September, 1935. PRESENT:― HIS EXCELLENCY THE OFFICER ADMINISTERING THE GOVERNMENT (SIR THOMAS SOUTHORN, K.B.E., C.M.G.). HIS EXCELLENCY THE OFFICER COMMANDING THE TROOPS (LIEUTENANT- GENERAL O. C. BORRETT, C.B., C.M.G., C.B.E., D.S.O.). THE COLONIAL SECRETARY (HON. MR. N. L. SMITH, Acting). THE ATTORNEY GENERAL (HON. MR. C. G. ALABASTER, O.B.E., K.C.). THE SECRETARY FOR CHINESE AFFAIRS (HON. MR. E. H. WILLIAMS, Acting). THE COLONIAL TREASURER (HON. MR. E. TAYLOR). HON. COMMANDER G. F. HOLE, R.N., (Retired) (Harbour Master). HON. MR. R. M. HENDERSON, (Director of Public Works). HON. DR. W. B. A. MOORE, (Acting Director of Medical and Sanitary Services). HON. MR. M. J. BREEN, (Postmaster General). HON. SIR HENRY POLLOCK, KT., K.C., LL.D. HON. SIR WILLIAM SHENTON, KT. HON. MR. R. H. KOTEWALL, C.M.G., LL.D. HON. MR. J. P. BRAGA, O.B.E. HON. MR. S. W. TS'O, C.B.E., LL.D. HON. MR. T. N. CHAU. HON. MR. J. J. PATERSON. MR. H. R. BUTTERS, (Deputy Clerk of Councils). ABSENT:― HON. MR. W. H. BELL. 154 HONG KONG LEGISLATIVE COUNCIL. MINUTES. The Minutes of the previous meeting of the Council were confirmed. PAPERS. THE COLONIAL SECRETARY, by command of H.E. the Officer Administering the Government, laid upon the table the following papers: Amendment to regulation 2 in Schedule B to Buildings Ordinance, 1935. Order under section 4 (a) of the Importation and Exportation Ordinance, 1915. Order for removal of all graves in portion of Section A in New Kowloon Cemetery No. -

JC DISI Season 11 Symposium - Wishes from Ho Man Tin Estate Team 食左飯未? 放假
JC DISI Season 11 Symposium - Wishes from Ho Man Tin Estate Team 食左飯未? 放假 今天天氣好 :) What to drink 有冷氣ah today? Are you Healthy & Happy today? 去飲茶lu afternoon tea? Coffee or Tea? 醫生話我身體好好 CONTENT 1. Site Introduction 2. Our Journey & Experiences 3. Observations 4. Action Plan ➢ Management Upgrading ➢ Public Relation ➢ Physical Design 5. Lesson to Learn 1. SITE TWGHs Wong Cho Tong INTRODUCTION Social Service Building ▫ Ho Man Tin Estate Homantin ▫ Ho Man Tin Plaza Plaza ▫ Ho Man Tin Ho Man Tin East Estate Service Reservoir Ho Man Tin East Service Reservior Ho Man Tin MTR Station 2. OUR JOURNEY & EXPERIENCES USER JOURNEY MAP CLINIC SESSION ▫ Road closure = Traffic congestion ▫ Poor neighbourhood relationship ▫ Low accessibility to the walk around, to the plaza, bus stop, MTR station ▫ Intergeneration ▫ Lack of daily essentials stores 3. OBSERVATION GAIN & PAIN Elderly’s opinion (gain/pain points) Gp1: Some prefer more intergenerational play area; Some prefers ramps than stairs; Low connectivity between destinations Gp2: Food Prices at Ho Man Tin Market are too expensive; Some refers Markets at Mong Kok or To Kwa Wan for more varieties & cheaper prices; Homantin Plaza is missing living essentials e.g. YumCha, banks and Chinese Pharmacy Store Gp3: Some prefers buses or minibuses rather than MTR. Very SHORT VIDEO CLIP HOW MIGHT WE? Strengthen the neighbourhood relationship in Ho Man Tin Estate? Better travelling experience for daily living? (esp. to MTR station) A more elderly-friendly living environment? ----> Ideas on Action Plan Semi-open space with natural Air-conditioned Space? ventilation? A more opened space for outdoor Pathway only limited activities? to Evacuation festive and vibrant Vehicular Access? Elderly-friendly environment? shopping mall? Easier way to reach A more diversified the smart signal shopmix? system? (age-friendly) 4. -

Driving Services Section
DRIVING SERVICES SECTION Taxi Written Test - Part B (Location Question Booklet) Note: This pamphlet is for reference only and has no legal authority. The Driving Services Section of Transport Department may amend any part of its contents at any time as required without giving any notice. Location (Que stion) Place (Answer) Location (Question) Place (Answer) 1. Aberdeen Centre Nam Ning Street 19. Dah Sing Financial Wan Chai Centre 2. Allied Kajima Building Wan Chai 20. Duke of Windsor Social Wan Chai Service Building 3. Argyle Centre Nathan Road 21. East Ocean Centre Tsim Sha Tsui 4. Houston Centre Mody Road 22. Eastern Harbour Centre Quarry Bay 5. Cable TV Tower Tsuen Wan 23. Energy Plaza Tsim Sha Tsui 6. Caroline Centre Ca useway Bay 24. Entertainment Building Central 7. C.C. Wu Building Wan Chai 25. Eton Tower Causeway Bay 8. Central Building Pedder Street 26. Fo Tan Railway House Lok King Street 9. Cheung Kong Center Central 27. Fortress Tower King's Road 10. China Hong Kong City Tsim Sha Tsui 28. Ginza Square Yau Ma Tei 11. China Overseas Wan Chai 29. Grand Millennium Plaza Sheung Wan Building 12. Chinachem Exchange Quarry Bay 30. Hilton Plaza Sha Tin Square 13. Chow Tai Fook Centre Mong Kok 31. HKPC Buil ding Kowloon Tong 14. Prince ’s Building Chater Road 32. i Square Tsim Sha Tsui 15. Clothing Industry Lai King Hill Road 33. Kowloonbay Trademart Drive Training Authority Lai International Trade & King Training Centre Exhibition Centre 16. CNT Tower Wan Chai 34. Hong Kong Plaza Sai Wan 17. Concordia Plaza Tsim Sha Tsui 35. -

Shop 123, 1St Floor, Peninsula Centre, 67 Mody Road, Tsim Sha Tsui East, Kowloon
NO NAME ADDRESS TELP FAX 1 A Maids Employment Services Centre Shop 123, 1st Floor, Peninsula Centre, 67 Mody Road, Tsim Sha Tsui East, Kowloon. 2111 3319 3102 9909 2 A.V.M.S Limited Shop L115, 1st floor, Metro Harbour Plaza, Tai Kok Tsui, Kowloon 3144 3367 3144 3962 3 Abadi Employment Consultant Centre Room 1108, 1st floor, Inciti Kar Shing Building, 15-19 Kau Yuk Road, Yuen Long, New Territories 3106 5716 3106 5717 4 ABNC Employment Agencies Co. Flat 79, Ground floor, Maximall, Blocks 1-3, City Garden, 233 Electric Road, North Point, Hong Kong. 25762911 25763600 5 Active Global Specialised Caregivers (HK) Pte Ltd. Unit 1703-04, 17th floor, Lucky Centre, 165-171 Wan Chai Road, Wan Chai, Hong Kong 3426 2909 3013 9815 6 Advance Court Overseas Employment Co. Shop 34B, Level 2, Waldorf Shopping Centre, Castle Peak Road, TMTL 194, Tuen Mun, New Territories 2458 1573 2452 6735 7 Advantage Consultant Co. Flat C, 12th FIoor, Kam Wah Building, 516 Nathan Road, Yau Ma Tei, Kowlon 26012708 27711420 8 AIE Employment Centre Room 1605, 16th floor, Hollywood Plaza, 610 Nathan Road, Mong Kok, Kowloon 2770 1198 2388 9057 9 Alim Prima Employment Agency Room K & L, 4th floor, Hennessy Apartments, 488 Hennessy Road, Causeway Bay, Hong Kong 25040629 27709803 10 All The Best Employment Limited. 1st floor, 92 Kam Tin Road, Yuen Long, New Territories 2807 0870 2807 0869 11 Allwin Employment Centre Limited Mezzanine floor, 408 Ma Tau Wau Road, Hung Hom, Kowloon 28668585 28669595 12 An Apple Travel & Employment Services Limited Room 907, 9th floor, Tower 2, Silvercord,