Kernel Address Space
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introduction to UEFI Technology
Introduction to UEFI Technology Abd El-Aziz, Mostafa Tarek, Aly [email protected] [email protected] Eldefrawy, Amr [email protected] December 3, 2013 Contents 1 BIOS 1 1.1 Introduction to System BIOS . .1 1.1.1 BIOS Operations . .3 1.1.2 BIOS Service Routines . .3 1.2 BIOS Limitations . .4 2 UEFI 5 2.1 Introduction to Unified Extensible Firmware Interface . .5 2.2 UEFI Components . .6 2.2.1 Boot Manager . .6 2.2.2 UEFI Services . .7 2.3 UEFI vs BIOS . .9 2.3.1 UEFI is properly standardized . .9 2.3.2 UEFI can work in either 32-bit or 64-bit mode . .9 2.3.3 A simple boot procedure . .9 3 Code Examples 10 3.1 BIOS Code Example . 10 3.2 UEFI Code Example . 12 1 BIOS 1.1 Introduction to System BIOS In the wonderful world of computing, it is well known that the operating system is an essential component of the computer system. Not only does the OS drive the computer hardware and control software programs, but it also provides complicated services and routines that can be used by programs to facilitate their job. Most computers today are based on Von Neumenn architecture. This implies that a program should be first loaded to some memory, which is directly accessible by the processing unit, before execution. The operating system, like any other program, abides by that rule. We note that an 1 operating system is not a single piece of code; large operating systems (like openBSD and IBM AIX) consist of hundreds of programs. -

Bringing Virtualization to the X86 Architecture with the Original Vmware Workstation
12 Bringing Virtualization to the x86 Architecture with the Original VMware Workstation EDOUARD BUGNION, Stanford University SCOTT DEVINE, VMware Inc. MENDEL ROSENBLUM, Stanford University JEREMY SUGERMAN, Talaria Technologies, Inc. EDWARD Y. WANG, Cumulus Networks, Inc. This article describes the historical context, technical challenges, and main implementation techniques used by VMware Workstation to bring virtualization to the x86 architecture in 1999. Although virtual machine monitors (VMMs) had been around for decades, they were traditionally designed as part of monolithic, single-vendor architectures with explicit support for virtualization. In contrast, the x86 architecture lacked virtualization support, and the industry around it had disaggregated into an ecosystem, with different ven- dors controlling the computers, CPUs, peripherals, operating systems, and applications, none of them asking for virtualization. We chose to build our solution independently of these vendors. As a result, VMware Workstation had to deal with new challenges associated with (i) the lack of virtual- ization support in the x86 architecture, (ii) the daunting complexity of the architecture itself, (iii) the need to support a broad combination of peripherals, and (iv) the need to offer a simple user experience within existing environments. These new challenges led us to a novel combination of well-known virtualization techniques, techniques from other domains, and new techniques. VMware Workstation combined a hosted architecture with a VMM. The hosted architecture enabled a simple user experience and offered broad hardware compatibility. Rather than exposing I/O diversity to the virtual machines, VMware Workstation also relied on software emulation of I/O devices. The VMM combined a trap-and-emulate direct execution engine with a system-level dynamic binary translator to ef- ficiently virtualize the x86 architecture and support most commodity operating systems. -

Hacking Toshiba Laptops Or How to Mess up Your Firmware Security
Hacking Toshiba Laptops Or how to mess up your firmware security REcon Brussels 2018 whois Serge Bazanski Michał Kowalczyk Freelancer in devops & (hardware) security. Vice-captain @ Dragon Sector Researcher @ Invisible Things Lab Twitter: @q3k Reverse engineer, amateur cryptanalyst IRC: q3k @ freenode.net Twitter: @dsredford IRC: Redford @ freenode.net Toshiba Portégé R100 Intel Pentium M 1 GHz 256MB RAM But there’s a catch... Quite the catch, actually. CMOS clear jumper? None to be found. Yank out the battery? Password still there. Take a door key and pass it over the pins of things that look like flash chips hopefully causing a checksum failure and resetting the password? Nice try. No luck, though. A-ha! BIOS analysis How to get the BIOS code? Physical memory? Not with a locked-down laptop. Dump of the flash chip? Ugh. Unpack some updates? Let’s see. Unpacking the updates https://support.toshiba.com/ 7-Zip + 254 KB of compressed data Decompression Unknown format Default unpacker is a 16-bit EXE There’s an alternative one, 32-bit! Decompression BuIsFileCompressed BuGetFileSize BuDecodeFile Decompression Just ~50 lines of C! ... BuIsFileCompressed(compressed, &is_compressed); if (is_compressed) { BuDecodeFile(compressed, fsize, decompressed); } ... The result Dumping the BIOS flash Where to start looking Chip Safari RAM Flash Google it Interfacing to flash chips In-circuit: test pads or protocol that permits multi-master access Out-of-circuit (?): desolder, attach to breakout/clip, use main communication interface Custom breakout board KiCAD (or $whatever, really) PCB design. Thermal transfer for DIY PCB manufacturing. Hot air gun to desolder, soldering station to re-solder. -

Professional Xen® Virtualization
Professional Xen® Virtualization William von Hagen Wiley Publishing, Inc. fffirs.inddfirs.indd iiiiii 112/14/072/14/07 44:35:46:35:46 PPMM fffirs.inddfirs.indd iiii 112/14/072/14/07 44:35:46:35:46 PPMM Professional Xen® Virtualization Acknowledgments .........................................................................................ix Introduction ................................................................................................ xix Chapter 1: Overview of Virtualization .............................................................. 1 Chapter 2: Introduction to Xen ..................................................................... 27 Chapter 3: Obtaining and Installing Xen........................................................ 57 Chapter 4: Booting and Configuring a Xen Host ............................................ 87 Chapter 5: Configuring and Booting Virtual Machines ................................. 117 Chapter 6: Building Filesystems for Virtual Machines ................................. 141 Chapter 7: Managing and Monitoring Virtual Machines ............................... 175 Chapter 8: Xen Networking ........................................................................ 201 Chapter 9: Advanced Virtual Machine Configuration ................................... 231 Chapter 10: Using Xen in the Data Center .................................................. 283 Appendix A: xm Command and Option Reference ........................................ 339 Appendix B: Xen Virtual Machine Configuration File Reference -

Intel X86 Assembly Language & Microarchitecture
Intel x86 Assembly Language & Microarchitecture #x86 Table of Contents About 1 Chapter 1: Getting started with Intel x86 Assembly Language & Microarchitecture 2 Remarks 2 Examples 2 x86 Assembly Language 2 x86 Linux Hello World Example 3 Chapter 2: Assemblers 6 Examples 6 Microsoft Assembler - MASM 6 Intel Assembler 6 AT&T assembler - as 7 Borland's Turbo Assembler - TASM 7 GNU assembler - gas 7 Netwide Assembler - NASM 8 Yet Another Assembler - YASM 9 Chapter 3: Calling Conventions 10 Remarks 10 Resources 10 Examples 10 32-bit cdecl 10 Parameters 10 Return Value 11 Saved and Clobbered Registers 11 64-bit System V 11 Parameters 11 Return Value 11 Saved and Clobbered Registers 11 32-bit stdcall 12 Parameters 12 Return Value 12 Saved and Clobbered Registers 12 32-bit, cdecl — Dealing with Integers 12 As parameters (8, 16, 32 bits) 12 As parameters (64 bits) 12 As return value 13 32-bit, cdecl — Dealing with Floating Point 14 As parameters (float, double) 14 As parameters (long double) 14 As return value 15 64-bit Windows 15 Parameters 15 Return Value 16 Saved and Clobbered Registers 16 Stack alignment 16 32-bit, cdecl — Dealing with Structs 16 Padding 16 As parameters (pass by reference) 17 As parameters (pass by value) 17 As return value 17 Chapter 4: Control Flow 19 Examples 19 Unconditional jumps 19 Relative near jumps 19 Absolute indirect near jumps 19 Absolute far jumps 19 Absolute indirect far jumps 20 Missing jumps 20 Testing conditions 20 Flags 21 Non-destructive tests 21 Signed and unsigned tests 22 Conditional jumps 22 Synonyms and terminology 22 Equality 22 Greater than 23 Less than 24 Specific flags 24 One more conditional jump (extra one) 25 Test arithmetic relations 25 Unsigned integers 25 Signed integers 26 a_label 26 Synonyms 27 Signed unsigned companion codes 27 Chapter 5: Converting decimal strings to integers 28 Remarks 28 Examples 28 IA-32 assembly, GAS, cdecl calling convention 28 MS-DOS, TASM/MASM function to read a 16-bit unsigned integer 29 Read a 16-bit unsigned integer from input. -

The Memory Sinkhole : an Architectural Privilege Escalation Vulnerability { Domas // Black Hat 2015 Christopher Domas
The Memory Sinkhole : An architectural privilege escalation vulnerability { domas // black hat 2015 Christopher Domas Battelle Memorial Institute ./bio x86 architectural vulnerability Hidden for 20 years A new class of exploits Overview (demonstration) Ring 3 Ring 2 Ring 1 Ring 0 The x86 Rings Virtualization The Negative Rings… Some things are so important… Ring 0 should not have access to them The Negative Rings… Ring -1 The hypervisor The Negative Rings… CIH The Negative Rings… Some things are so important… Ring -1 should not have access to them The Negative Rings… Ring -2 System Management Mode (SMM) The Negative Rings… What if… A mode invisible to the OS SMM Power management SMM … in the beginning System safety Power button Century rollover Error logging Chipset errata Platform security SMM … evolution Cryptographically authenticated variables Signature verifications Firmware, SecureBoot Hardware locks TPM emulation and communication Platform Lock Box Interface to the Root of Trust SMM … pandora’s box Whenever we have anything … So important, we don’t want the kernel to screw it up So secret, it needs to hide from the OS and DMA So sensitive, it should never be touched … it gets tossed into SMM SMM … pandora’s box Ring 3 (Userland) Ring 0 (Kernel) Ring -1 (Hypervisor) Ring -2 (SMM) Processor If you think you own a system when you get to ring 0 … … you're wrong On modern systems, ring 0 is not in control Ring -2 has the hardware the firmware all the most critical security checks The deepest -

Hacking the Preboot Execution Environment
Hacking the Preboot eXecution Environment Using the BIOS network stack for other purposes Julien Vanegue [email protected] CESAR Recife Center for Advanced Studies and Systems, Brasil. September 27, 2008 Abstract It is well known that most modern BIOS come with a Preboot eXecution Environment (PXE) featuring network capabilities. Such a PXE stack allows computers to boot on the network using standard protocols such as DHCP and TFTP for obtaining an IP address and downloading an Operating System image to start with. While some security researchers have been exposing the insecurity of using kernel images downloaded in such way, it is less known that the PXE stack remains usable even after the operating system has started. This article describes how to come back to real-mode from a protected mode environment in order to use the PXE stack for receiving and sending any kind of packets, and come back to protected mode as if nothing had happened. The proposed proof of concept implementation allows to send and receive UDP packets. It is explained in great details and was tested on Intel Pentium 4 and AMD64 processors on a variety of five different BIOS. 1 Introduction The PXE protocol version 2.1 [1] was defined by Intel Corp. in 1999. It has now become a widely used standard in any modern BIOS environment for allowing network capabilities since the very first moment of code execution on Intel processors based computers. It is common knowledge that PXE capabilities can be used for sending and receiving DHCP and TFTP packets over the LAN. -

Intel X86 Assembly Language & Microarchitecture
Intel x86 Assembly Language & Microarchitecture #x86 1 1: x86 2 2 Examples 2 x86 2 x86 Linux Hello World 3 2: 5 5 5 Examples 5 5 Carry 5 5 'sbb' 5 5 5 0 6 6 test 6 6 6 Linux 6 35 7 7 lea 7 7 7 3: - 8 Examples 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 9 9 80386 9 9 9 PDBR PDBR 10 10 80486 10 10 10 10 PAE 11 11 11 11 PSE 11 PSE-32PSE-40 11 4: 13 13 13 Examples 13 32cdecl 13 13 13 Clobbered 13 64V. 13 13 14 Clobbered 14 32stdcall 14 14 14 Clobbered 14 32cdecl - 14 8,16,32 14 64 14 15 32cdecl - 16 floatdouble 16 16 17 64Windows 17 17 17 Clobbered 17 18 32cdecl - 18 18 18 18 18 5: 20 20 20 Examples 22 22 6: 29 29 Examples 29 IA-32GAScdecl 29 MS-DOSTASM / MASM16 30 16 30 30 31 31 NASM 33 MS-DOSTASM / MASM16 33 33 33 33 33 35 NASM 35 35 MS-DOSTASM / MASM16 36 16 36 36 36 36 NASM 37 7: 38 Examples 38 38 38 38 38 38 38 39 39 39 40 40 40 40 ... 40 41 41 42 42 42 42 a_label 43 43 43 8: 44 44 44 Examples 44 MOV 44 9: 46 Examples 46 Microsoft Assembler - MASM 46 46 ATT - 46 BorlandTurbo Assembler - TASM 47 GNU - 47 Netwide Assembler - NASM 47 - YASM 48 10: 49 Examples 49 16 49 49 32 49 8 50 50 50 50 50 50 64 51 51 51 FLAGS 52 52 80286 53 80386 53 80486 53 53 11: 54 Examples 54 54 54 54 54 54 / 54 55 55 55 55 55 56 12: 59 Examples 59 BIOS 59 BIOS 59 BIOS 59 59 59 59 CHS 59 RTC 60 RTC 60 RTC 60 60 61 61 61 62 You can share this PDF with anyone you feel could benefit from it, downloaded the latest version from: intel-x86-assembly-language---microarchitecture It is an unofficial and free Intel x86 Assembly Language & Microarchitecture ebook created for educational purposes. -

Pagedout 001 Beta1.Pdf
Paged Out! is what happens when a technical reviewer sees too many 20-page long programming articles in a short period of time. Though that's only part of the story. The idea of an experimental zine focusing on very short articles spawned in my mind around a year ago and was slowly — almost unconsciously Paged Out! Institute — developing in my head until early 2019, when I finally decided https://pagedout.institute/ that this whole thing might actually work (even given my chronic lack of time). Project Lead Why short articles in the first place, you ask? They are faster to Gynvael Coldwind read, faster to write, faster to review, and it's fully acceptable to write a one-pager on this one cool trick you just used in a project / exploit. Furthermore, as is the case with various forms Executive Assistant of constraint programming and code golfing, I believe adding Arashi Coldwind some limitations might push one to conjure up interesting tricks while constructing the article (especially if the author has DTP Programmer almost full control of the article's layout) and also, hopefully, foxtrot_charlie increase the knowledge-to-space ratio. Giving authors freedom to arrange the layout as they please has DTP Advisor interesting consequences by itself. First of all, we can totally tusiak_charlie dodge a standard DTP process – after all, we get PDFs that already use the final layouts and can be merged into an issue with just a set of scripts (therefore our Institute has a DTP Lead Reviewers Programmer instead of a DTP Artist). Secondly, well, every Mateusz "j00ru" Jurczyk article looks distinctly different — this is the reason I say our KrzaQ project is "experimental" — because nobody can predict whether this artistic chaos of a magazine will get accepted by our technical community. -
Symbols Numerics A
IA32.book Page 1619 Friday, June 18, 2004 3:11 PM Index Symbols A20 Mask 419 µop Decode events 1412 A20M# 89, 419, 1314 µop Fusion 1437 Aborts 260 µops 10, 843 AC ‘97 Link 17 “u” and the “v” pipelines 465 Accelerated Graphics Port 16 Accessed Bit 224, 243 Numerics ACPI 833, 1597 16-bit Code Optimization, Pentium II 672 ACPI Table 833, 1516 286 255 ACPI table 1596 286 DOS Extender Programs 485 Active Thread field 1399 286 DOS Extenders on Post-286 Address and Data Strobes 1119 Processors 487 Address bit 20 Mask 1314 2MB Page 559, 561 address bus width, Pentium 4 1429 2-wide SSE instructions 754 Address Size 1217 386 Power-Up State 66 Address Size Override Prefix 339 386SL 1465 Address Strobe 1203 3D Rasterization 790 Address Strobe signals 1120 486 412 ADDRV 595 486 FSB 415 ADS# 1213 486 Instruction Set Changes 456 ADSTB[1:0]# 1120, 1203 486DX 412 Advanced Configuration and Power 486DX2 (WB) 412 Interface 1516 486DX2 (WT) 412 Advanced Stack Management 1439 486DX4 412 Advanced Transfer Cache 746 486SX 412 Agent ID 1141, 1221 486SX2 412 Agent ID assignment, Pentium 4 1150 487SX 412 Agent Type 1221 4MB Pages 244, 501, 735 AGP 16 4-wide SSE instructions 754 AGTL+ 723, 1116, 1127, 1429 8088 255 AGTL+ Sample Point 1131 8259A interrupt controller 17, 255, 351, AGTL+ Setup and Hold Specs 1134 1303, 1498 Alarm output of the real-time clock 258 855MCH 1426 Alignment Check 269 Alignment Check Exception 321, 448, 460 A Alignment Checking 448 A bit 224 Alignment Checking, SSE 792 A[15:8]# 1209, 1220 All Excluding Self 1559 A[23:16]# 1209, 1220 All Including -

Assembly Language Programming Lecture Notes
Assembly Language Programming Lecture Notes Delivered by Belal Hashmi Compiled by Junaid Haroon Preface Assembly language programming develops a very basic and low level understanding of the computer. In higher level languages there is a distance between the computer and the programmer. This is because higher level languages are designed to be closer and friendlier to the programmer, thereby creating distance with the machine. This distance is covered by translators called compilers and interpreters. The aim of programming in assembly language is to bypass these intermediates and talk directly with the computer. There is a general impression that assembly language programming is a difficult chore and not everyone is capable enough to understand it. The reality is in contrast, as assembly language is a very simple subject. The wrong impression is created because it is very difficult to realize that the real computer can be so simple. Assembly language programming gives a freehand exposure to the computer and lets the programmer talk with it in its language. The only translator that remains between the programmer and the computer is there to symbolize the computer’s numeric world for the ease of remembering. To cover the practical aspects of assembly language programming, IBM PC based on Intel architecture will be used as an example. However this course will not be tied to a particular architecture as it is often done. In our view such an approach does not create versatile assembly language programmers. The concepts of assembly language that are common across all platforms will be developed in such a manner as to emphasize the basic low level understanding of the computer instead of the peculiarities of one particular architecture. -
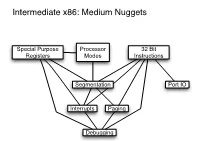
Intermediate X86: Medium Nuggets
Intermediate x86: Medium Nuggets Special Purpose Processor 32 Bit Registers Modes Instructions Segmentation Port IO Interrupts Paging Debugging x86 Instruction: Instruction: Processor Instruction Instruction CPUID RDTSC Intermediate x86: Small Nuggets Modes Prefixes Format Repeat (REP), Special Processor Processor Processor Mode: Processor Repeat While Zero Flag is Operand or Purpose Debugger VM Mode: Mode: VMX Long Mode Mode: Set (REPZ, REPE), Segment Branch Address Register: Detection: Detection: Protected Mode System Enabled LOCK (64 bit & Real Mode Override Hints Size EFLAGS: RDTSC RDTSC (Virtual 8086 Management Compatibility Mode) (Unreal Mode) Repeat While Zero Flag is Override ID Flag Mode) Mode Not Set (REPNZ, REPNE) Real & Instructions GOTO: GOTO: Virtual 8086 GOTO: : Privilege x86 Tasks: John's John's Mode David's PUSHFD Rings Concept class class Interrupts: class POPFD nodes nodes Concept nodes Protected & x86 Tasks: Interrupt Segmentation: Long Mode Task State Debugging: Vector Concept Interrupts: Segment Concept Table (IVT) Concept (TSS) Interrupt Interrupts: Special Debugging: Virtual Memory & Segmentation: Interrupts: Segmentation: Interrupt Port I/O: Descriptor Faults, Purpose x86 Paging: Segment Interrupt Addressing Masking Concept Table (IDT): Traps, Register: Task Hardware Concept Selectors Frame Concept Aborts Register (TR) Support Paging: Special Instructions: Per- Per- Special Purpose Physical Paging: Special Purpose Logical Special Purpose Register: Purpose IRET, Special Translation Paging: process process Interrupts: