Running Xen-A Hands-On Guide to the Art of Virt
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Design and Evaluation of Self-Management Approaches for Virtual Machine-Based Environments
Fachhochschule Wiesbaden Fachbereich Design Informatik Medien Studiengang Informatik Master-Thesis zur Erlangung des akademischen Grades Master of Science – M.Sc. Design and Evaluation of Self-Management Approaches for Virtual Machine-Based Environments vorgelegt von Dan Marinescu am 29. Februar 2008 Referent: Prof. Dr. Reinhold Kröger Korreferent: Prof. Dr. Steffen Reith II Erklärung gem. BBPO, Ziff. 6.4.2 Ich versichere, dass ich die Master-Thesis selbstständig verfasst und keine anderen als die angegebenen Hilfsmittel benutzt habe. Wiesbaden, 29.02.2008 Dan Marinescu Hiermit erkläre ich mein Einverständnis mit den im Folgenden aufgeführten Verbreitungs- formen dieser Master-Thesis: Verbreitungsform ja nein Einstellung der Arbeit in die √ Bibliothek der FHW Veröffentlichung des Titels der √ Arbeit im Internet Veröffentlichung der Arbeit im √ Internet Wiesbaden, 29.02.2008 Dan Marinescu III IV Contents 1 Introduction 1 2 Background 5 2.1 Virtualization ................................ 5 2.1.1 Taxonomy ............................. 5 2.1.2 Case Study: Xen .......................... 10 2.1.3 Live Migration ........................... 13 2.1.4 Hardware-Assisted Virtualization ................. 16 2.1.5 Management of Vitual Machine Environments .......... 17 2.2 Service Level Management ......................... 20 2.3 Autonomic Computing ........................... 21 2.3.1 Motivation ............................. 21 2.3.2 Taxonomy ............................. 22 2.3.3 Architectural Considerations .................... 23 2.3.4 Examples of Autonomic Computing Systems ........... 24 2.4 Complexity theory and Optimization .................... 25 2.4.1 Introduction to Complexity Theory ................ 25 2.4.2 Complexity Classes ......................... 25 2.4.3 Optimization Problems ....................... 26 2.4.4 The Knapsack Family of Problems ................. 27 2.4.5 Approximation Algorithms ..................... 29 2.4.6 Heuristics .............................. 32 V 3 Analysis 37 3.1 State of the Art .............................. -

Virtual Square: All the Virtuality You Always Wanted but You Were Afraid to Ask
Virtual Square: all the virtuality you always wanted but you were afraid to ask. Renzo Davoli i Computer Science Department vol Da ALMA MATER STUDIORUM: University of Bologna o Renz eft, yl WorkShop 2007 sul Calcolo e Reti dell'INFN op C 7 Rimini, 10 maggio 2007 00 2 © re ua Sq l ua t Vir Virtual Square VIRTUAL VIRTUAL VIRTUAL SQUARED i VIRTUAL SQUARE vol Da o VIRTUAL VIRTUAL Renz eft, VIRTUAL yl VIRTUAL op C 7 00 2 VIRTUAL © re VIRTUAL ua Sq l ua t Vir VIRTUALITY today ● Virtual Machines – historical topic – lots of papers – lots of tools i vol Da – ... but something is already missing o Renz ● Virtual Networking eft, yl op – less historical C 7 00 2 – several papers © re ua Sq l ua t Vir Virtual Square Virtualization concepts and tools are disconnected. i There is a world of new applications that vol Da can be realized by interoperating, o Renz integrated virtuality eft, yl op C 7 UNIFICATION IS NEEDED 00 2 © re ua Sq l ua t Vir Virtual Square © 2007 Copyleft, Renzo Davoli Vi rtual S qu are Some Examples of VM (free software) ● Qemu: PVM or SVM, User Mode User Access (or dual-mode with KQEMU, proprietary sw). – cross emulation platform (ia32, ia64, ppc, i m68k, sparc, arm...) vol Da o – dynamic translation Renz ● eft, XEN: SVM, Native. yl op C 7 – xen uses para-virtualization (O.S. in domain0 00 2 © has the real device drivers). re ua – (xen ideas come from the Denali project: Sq l ua t SVN, Native, real virtualization). -

Virtual Machine Technologies and Their Application in the Delivery of ICT
Virtual Machine Technologies and Their Application In The Delivery Of ICT William McEwan accq.ac.nz n Christchurch Polytechnic Institute of Technology Christchurch, New Zealand [email protected] ABSTRACT related areas - a virtual machine or network of virtual machines can be specially configured, allowing an Virtual Machine (VM) technology was first ordinary user supervisor rights, and it can be tested implemented and developed by IBM to destruction without any adverse effect on the corporation in the early 1960's as a underlying host system. mechanism for providing multi-user facilities This paper hopes to also illustrate how VM in a secure mainframe computing configurations can greatly reduce our dependency on environment. In recent years the power of special purpose, complex, and expensive laboratory personal computers has resulted in renewed setups. It also suggests the important additional role interest in the technology. This paper begins that VM and VNL is likely to play in offering hands-on by describing the development of VM. It practical experience to students in a distance e- discusses the different approaches by which learning environment. a VM can be implemented, and it briefly considers the advantages and disadvantages Keywords: Virtual Machines, operating systems, of each approach. VM technology has proven networks, e-learning, infrastructure, server hosting. to be extremely useful in facilitating the Annual NACCQ, Hamilton New Zealand July, 2002 www. Annual NACCQ, Hamilton New Zealand July, teaching of multiple operating systems. It th offers an alternative to the traditional 1. INTRODUCTION approaches of using complex combinations Virtual Machine (VM) technology is not new. It was of specially prepared and configured OS implemented on mainframe computing systems by the images installed via the network or installed IBM Corporation in the early 1960’s (Varian 1997 pp permanently on multiple partitions or on 3-25, Gribben 1989 p.2, Thornton 2000 p.3, Sugarman multiple physical hard drives. -

Lguest a Journey of Learning the Linux Kernel Internals
Lguest A journey of learning the Linux kernel internals Daniel Baluta <[email protected]> What is lguest? ● “Lguest is an adventure, with you, the reader, as a Hero” ● Minimal 32-bit x86 hypervisor ● Introduced in 2.6.23 (October, 2007) by Rusty Russel & co ● Around 6000 lines of code ● “Relatively” “easy” to understand and hack on ● Support to learn linux kernel internals ● Porting to other architectures is a challenging task Hypervisor types make Preparation ● Guest ○ Life of a guest ● Drivers ○ virtio devices: console, block, net ● Launcher ○ User space program that sets up and configures Guests ● Host ○ Normal linux kernel + lg.ko kernel module ● Switcher ○ Low level Host <-> Guest switch ● Mastery ○ What’s next? Lguest overview make Guest ● “Simple creature, identical to the Host [..] behaving in simplified ways” ○ Same kernel as Host (or at least, built from the same source) ● booting trace (when using bzImage) ○ arch/x86/boot/compressed/head_32.S: startup_32 ■ uncompresses the kernel ○ arch/x86/kernel/head_32.S : startup_32 ■ initialization , checks hardware_subarch field ○ arch/x86/lguest/head_32.S ■ LGUEST_INIT hypercall, jumps to lguest_init ○ arch/x86/lguest/boot.c ■ once we are here we know we are a guest ■ override privileged instructions ■ boot as normal kernel, calling i386_start_kernel Hypercalls struct lguest_data ● second communication method between Host and Guest ● LHCALL_GUEST_INIT ○ hypercall to tell the Host where lguest_data struct is ● both Guest and Host publish information here ● optimize hypercalls ○ irq_enabled -

IBM Thinkpad Notebooks 1992 to 2001 - Withdrawn January 2001 - Version 214 IBM Thinkpad 240 - Withdrawn
IBM PC Institute IBM Personal Systems Reference IBM ThinkPad Notebooks 1992 to 2001 - withdrawn January 2001 - Version 214 IBM ThinkPad 240 - withdrawn IBM ThinkPad Processor Intel Mobile Celeron 300, 366, or 400MHz1 / 66MHz system bus Processor features No upgrade / processor on Ball Grid Array (H-PBGA) L2 cache 128KB / onboard (full speed) / synchronous pipelined burst / ECC / write-back Diskette drive External 3.5" 1.44MB / connects to left side with FDD port / includes case and cable CD-ROM Option: External CD-ROM / via Portable Drive Bay and 24X-10X5 CD-ROM UltraslimBay Drive DVD-ROM Option: External DVD-ROM / via Portable Drive Bay and DVD-ROM UltraslimBay Drive Type-model ✂ 2609-21U ✂ 2609-31U ✂ 2609-41U Processor Celeron 300MHz Celeron 366MHz Celeron 400MHz Disk - size / ms 6.4GB4 / 13ms read / Ultra DMA/33 or PIO Mode 4 12.0GB / 12ms read / ATA-66 or PIO4 Preload (see side) Windows 987 Windows 987 SE Windows 987 SE Avail / withdrawn date June 1999 / February 2000 November 1999 / February 2000 February 2000 / February 2001 Display - size and type 10.4" TFT color (264.16mm) / Active Matrix Display - technology SVGA / 800x600 / 15ms refresh (typical) / 50 to 110 nits 16.7 million simultaneous colors / 250 to 1 contrast (typical) Graphics - controller NeoMagic MagicMedia128XD (NM2160C) / 128-bit accelerator / DDC2B / 2MB / SGRAM (embedded) / color space conversion Graphics - features Simultaneous LCD and CRT26 / 180 degree tilt / no multiple-monitor support / ext SVGA to 1024x768 with 65,536 colors Memory - std / max 64MB / 192MB33 -

CASE STUDY Userful Multiplier and Win4lin Pro Reduce Costs of Point
CASE STUDY TM Userful Multiplier and Win4Lin Pro Reduce Costs of Point-of-Sale Terminals A Case Study by Omni Technology Solutions, leverage the Linux Desktop, he recommended the Userful a Userful Partner Multiplier*, a software add-on that allows multiple users to share a single computer. Win4Lin Pro Desktop was installed to allow Birchwood to run Simply Accounting on Linux. “Userful Multiplier* cut the hardware DOSEMU, which comes bundled with SUSE Linux, handled costs in half and Win4Lin Pro Desktop the DOS-based Framer’s Assistant point-of-sale application provided Windows compatibility to run quite nicely. their Simply Accounting package.” “Birchwood Art Gallery was always running into virus and - Mike Ducharme, spyware infections when they were using Windows 98 and IT consultant, Windows XP. Even with up-to-date anti-virus and anti- Birchwood Art Gallery spyware software, the systems were still getting major infections on a monthly basis, resulting in costly down-time Overview until they were cleaned up,” said Mr. Ducharme. “The security of Novell’s SUSE Linux Desktop provides peace of mind to Birchwood Art Gallery - based in Winnipeg, Canada - their staff,” continued Ducharme, “allowing them to carry out specializes in fine art reproductions and original artwork their work activities without fear of virus or spyware infesta- by a wide range of Canadian and international artists. On tion. Additionally, the Userful Multiplier* cut the hardware their web site and in their gallery, you will find artwork, costs in half and Win4Lin Pro Desktop provided Windows sculptures, prints and books from hundreds of artists. Lyn compatibility to run their Simply Accounting package.” Chercoe and Carole Solmundson, Birchwood Art Gallery’s owners, have earned a reputation for customer service The Results excellence since 1993 and sell art online all over the world. -

Lguest the Little Hypervisor
Lguest the little hypervisor Matías Zabaljáuregui [email protected] based on lguest documentation written by Rusty Russell note: this is a draft and incomplete version lguest introduction launcher guest kernel host kernel switcher don't have time for: virtio virtual devices patching technique async hypercalls rewriting technique guest virtual interrupt controller guest virtual clock hw assisted vs paravirtualization hybrid virtualization benchmarks introduction A hypervisor allows multiple Operating Systems to run on a single machine. lguest paravirtualization within linux kernel proof of concept (paravirt_ops, virtio...) teaching tool guests and hosts A module (lg.ko) allows us to run other Linux kernels the same way we'd run processes. We only run specially modified Guests. Setting CONFIG_LGUEST_GUEST, compiles [arch/x86/lguest/boot.c] into the kernel so it knows how to be a Guest at boot time. This means that you can use the same kernel you boot normally (ie. as a Host) as a Guest. These Guests know that they cannot do privileged operations, such as disable interrupts, and that they have to ask the Host to do such things explicitly. Some of the replacements for such low-level native hardware operations call the Host through a "hypercall". [ drivers/lguest/hypercalls.c ] high level overview launcher /dev/lguest guest kernel host kernel switcher Launcher main() some implementations /dev/lguest write → initialize read → run guest Launcher main [ Documentation/lguest/lguest.c ] The Launcher is the Host userspace program which sets up, runs and services the Guest. Just to confuse you: to the Host kernel, the Launcher *is* the Guest and we shall see more of that later. -

Proceedings of the Linux Symposium
Proceedings of the Linux Symposium Volume One June 27th–30th, 2007 Ottawa, Ontario Canada Contents The Price of Safety: Evaluating IOMMU Performance 9 Ben-Yehuda, Xenidis, Mostrows, Rister, Bruemmer, Van Doorn Linux on Cell Broadband Engine status update 21 Arnd Bergmann Linux Kernel Debugging on Google-sized clusters 29 M. Bligh, M. Desnoyers, & R. Schultz Ltrace Internals 41 Rodrigo Rubira Branco Evaluating effects of cache memory compression on embedded systems 53 Anderson Briglia, Allan Bezerra, Leonid Moiseichuk, & Nitin Gupta ACPI in Linux – Myths vs. Reality 65 Len Brown Cool Hand Linux – Handheld Thermal Extensions 75 Len Brown Asynchronous System Calls 81 Zach Brown Frysk 1, Kernel 0? 87 Andrew Cagney Keeping Kernel Performance from Regressions 93 T. Chen, L. Ananiev, and A. Tikhonov Breaking the Chains—Using LinuxBIOS to Liberate Embedded x86 Processors 103 J. Crouse, M. Jones, & R. Minnich GANESHA, a multi-usage with large cache NFSv4 server 113 P. Deniel, T. Leibovici, & J.-C. Lafoucrière Why Virtualization Fragmentation Sucks 125 Justin M. Forbes A New Network File System is Born: Comparison of SMB2, CIFS, and NFS 131 Steven French Supporting the Allocation of Large Contiguous Regions of Memory 141 Mel Gorman Kernel Scalability—Expanding the Horizon Beyond Fine Grain Locks 153 Corey Gough, Suresh Siddha, & Ken Chen Kdump: Smarter, Easier, Trustier 167 Vivek Goyal Using KVM to run Xen guests without Xen 179 R.A. Harper, A.N. Aliguori & M.D. Day Djprobe—Kernel probing with the smallest overhead 189 M. Hiramatsu and S. Oshima Desktop integration of Bluetooth 201 Marcel Holtmann How virtualization makes power management different 205 Yu Ke Ptrace, Utrace, Uprobes: Lightweight, Dynamic Tracing of User Apps 215 J. -

P2b User's Manual
R P2B Pentium® II Motherboard USER’S MANUAL USER'S NOTICE No part of this manual, including the products and software described in it, may be repro- duced, transmitted, transcribed, stored in a retrieval system, or translated into any language in any form or by any means, except documentation kept by the purchaser for backup purposes, without the express written permission of ASUSTeK COMPUTER INC. (“ASUS”). ASUS PROVIDES THIS MANUAL “AS IS” WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OR CONDITIONS OF MERCHANTABILITY OR FITNESS FOR A PAR- TICULAR PURPOSE. IN NO EVENT SHALL ASUS, ITS DIRECTORS, OFFICERS, EMPLOYEES OR AGENTS BE LIABLE FOR ANY INDIRECT, SPECIAL, INCIDEN- TAL, OR CONSEQUENTIAL DAMAGES (INCLUDING DAMAGES FOR LOSS OF PROFITS, LOSS OF BUSINESS, LOSS OF USE OR DATA, INTERRUPTION OF BUSI- NESS AND THE LIKE), EVEN IF ASUS HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES ARISING FROM ANY DEFECT OR ERROR IN THIS MANUAL OR PRODUCT. Product warranty or service will not be extended if: (1) the product is repaired, modified or altered, unless such repair, modification of alteration is authorized in writing by ASUS; or (2) the serial number of the product is defaced or missing. Products and corporate names appearing in this manual may or may not be registered trade- marks or copyrights of their respective companies, and are used only for identification or explanation and to the owners’ benefit, without intent to infringe. • Intel, LANDesk, and Pentium are registered trademarks of Intel Corporation. • IBM and OS/2 are registered trademarks of International Business Machines. -

Bunker: a Privacy-Oriented Platform for Network Tracing Andrew G
Bunker: A Privacy-Oriented Platform for Network Tracing Andrew G. Miklas†, Stefan Saroiu‡, Alec Wolman‡, and Angela Demke Brown† †University of Toronto and ‡Microsoft Research Abstract: ISPs are increasingly reluctant to collect closing social security numbers, names, addresses, or and store raw network traces because they can be used telephone numbers [5, 54]. to compromise their customers’ privacy. Anonymization Trace anonymization is the most common technique techniques mitigate this concern by protecting sensitive information. Trace anonymization can be performed of- for addressing these privacy concerns. A typical imple- fline (at a later time) or online (at collection time). Of- mentation uses a keyed one-way secure hash function to fline anonymization suffers from privacy problems be- obfuscate sensitive information contained in the trace. cause raw traces must be stored on disk – until the traces This could be as simple as transforming a few fields in are deleted, there is the potential for accidental leaks or the IP headers, or as complex as performing TCP connec- exposure by subpoenas. Online anonymization drasti- tion reconstruction and then obfuscating data (e.g., email cally reduces privacy risks but complicates software en- addresses) deep within the payload. There are two cur- gineering efforts because trace processing and anony- mization must be performed at line speed. This paper rent approaches to anonymizing network traces: offline presents Bunker, a network tracing system that combines and online. Offline anonymization collects and stores the software development benefits of offline anonymiz- the entire raw trace and then performs anonymization ation with the privacy benefits of online anonymization. as a post-processing step. -

Linux Games Page 1 of 7
Linux Games Page 1 of 7 Linux Games INTRODUCTION such as the number of players and the size of the map, then you start the game. Once the game is running clients may Hello. My name is Andrew Howlett. I've been using Linux join the game. Clients connect to the game using TCP/IP, since 1997. In 2000 I cutover to Linux for all my projects, so it is very easy to play multi-player games over the except I dual-booted Windows to play games. I like to play Internet. Like many Free games, clients are available for computer games. About a year ago I stopped dual booting. many platforms, including Windows, Amiga and Now I play computer games under Linux. The games I Macintosh. So there are lots of players out there. If you play can be divided into four groups: Free Games, native don't want to play against other humans, then Freeciv linux commercial games, Windows Emulated games, and includes some nasty AIs. Win4Lin enabled games. This presentation will demonstrate games from each of these four groups. BZFlag Platform BZFlag is a tank combat game along the same lines as the old BattleZone game. Like FreeCiv, BZFlag uses a client/ Before I get started, a little bit about my setup so you can server architecture over TCP/IP networks. Unlike FreeCiv, relate this to whatever you are running. This is a P3 900 the game contains no AIs – you must play this game MHz machine. It has a Crystal Sound 4600 sound card and against other humans (? entities ?) over the Internet. -
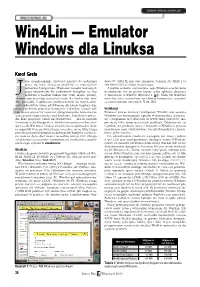
Win4lin — Emulator Windows Dla Linuksa
Win4Lin — Emulator Windows dla Linuksa Karol Grela ako chemik−organik, używający Linuksa do codziennej dows 95 OSR2 PL mój stary komputer Pentium 233 MMX z 64 pracy, nie mam zazwyczaj problemu ze znalezieniem MB RAM−u był aż nadto wystarczający. potrzebnych programów. Większość narzędzi tworzonych Z punktu widzenia użytkownika, sesja Windows uruchomiona przez naukowców dla naukowców kompiluje się bez w emulatorze jest po prostu jeszcze jedną aplikacją działającą problemu w każdym Uniksie (np. VMD, mopac, platon), w środowisku X Window (Rysunek 1, [8a]). Okno MS Windows a komercyjne posiadają zazwyczaj wersje dla Linuksa (np. mol− może być także wyświetlone na zdalnym komputerze, za pomo− den, pcmodel). Z aplikacjami przeznaczonymi dla innych syste− cą mechanizmów sieciowych X−ów [8b]. mów uniksowych, takimi jak XWinnmr dla Silicon Graphics, daje się bez problemu pracować w systemie X Window. Czasem jed− Instalacja nak muszę używać lub testować oprogramowanie, które nie po− Ponieważ proces instalacji i konfiguracji Win4Lin oraz systemu siada jeszcze odpowiednika pod Linuksem. Dodatkowo prowa− Windows jest wyczerpująco opisany w dokumentacji dostarcza− dzę kilka projektów, takich jak ChemPerfect — zestaw narzędzi nej z programem oraz dostępnej na WWW firmy TreLOS [5], sku− chemicznych do Wordperfecta. Projekt ten rozwijam w dwu wer− pię się na kilku mniej oczywistych punktach. Zakładam też, że sjach — dla Windows i Linuksa. Czasem muszę wprowadzić drob− Czytelnik zna podstawy pracy z Linuksem (i Windows), posiada ne poprawki w tej pierwszej wersji, a nie chce mi się tylko z tego uprawnienia roota i (ewentualnie) wie jak skompilować i zainsta− powodu restartować komputera i ładować MS Windows. Co więcej, lować jądro systemu.