Expectimax Enhancement Through Parallel Search for Non-Deterministic Games
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Adversarial Search
Artificial Intelligence CS 165A Oct 29, 2020 Instructor: Prof. Yu-Xiang Wang ® ExamplEs of heuristics in A*-search ® GamEs and Adversarial SEarch 1 Recap: Search algorithms • StatE-spacE diagram vs SEarch TrEE • UninformEd SEarch algorithms – BFS / DFS – Depth Limited Search – Iterative Deepening Search. – Uniform cost search. • InformEd SEarch (with an heuristic function h): – Greedy Best-First-Search. (not complete / optimal) – A* Search (complete / optimal if h is admissible) 2 Recap: Summary table of uninformed search (Section 3.4.7 in the AIMA book.) 3 Recap: A* Search (Pronounced “A-Star”) • Uniform-cost sEarch minimizEs g(n) (“past” cost) • GrEEdy sEarch minimizEs h(n) (“expected” or “future” cost) • “A* SEarch” combines the two: – Minimize f(n) = g(n) + h(n) – Accounts for the “past” and the “future” – Estimates the cheapest solution (complete path) through node n function A*-SEARCH(problem, h) returns a solution or failure return BEST-FIRST-SEARCH(problem, f ) 4 Recap: Avoiding Repeated States using A* Search • Is GRAPH-SEARCH optimal with A*? Try with TREE-SEARCH and B GRAPH-SEARCH 1 h = 5 1 A C D 4 4 h = 5 h = 1 h = 0 7 E h = 0 Graph Search Step 1: Among B, C, E, Choose C Step 2: Among B, E, D, Choose B Step 3: Among D, E, Choose E. (you are not going to select C again) 5 Recap: Consistency (Monotonicity) of heuristic h • A heuristic is consistEnt (or monotonic) provided – for any node n, for any successor n’ generated by action a with cost c(n,a,n’) c(n,a,n’) • h(n) ≤ c(n,a,n’) + h(n’) n n’ – akin to triangle inequality. -

Guru Nanak Dev University Amritsar
FACULTY OF ENGINEERING & TECHNOLOGY SYLLABUS FOR B.TECH. COMPUTER ENGINEERING (Credit Based Evaluation and Grading System) (SEMESTER: I to VIII) Session: 2020-21 Batch from Year 2020 To Year 2024 GURU NANAK DEV UNIVERSITY AMRITSAR Note: (i) Copy rights are reserved. Nobody is allowed to print it in any form. Defaulters will be prosecuted. (ii) Subject to change in the syllabi at any time. Please visit the University website time to time. 1 CSA1: B.TECH. (COMPUTER ENGINEERING) SEMESTER SYSTEM (Credit Based Evaluation and Grading System) Batch from Year 2020 to Year 2024 SCHEME SEMESTER –I S. Course Credit Course Title L T P No. Code s 1. CEL120 Engineering Mechanics 3 1 0 4 Engineering Graphics & Drafting 2. MEL121 3 0 1 4 Using AutoCAD 3 MTL101 Mathematics-I 3 1 0 4 4. PHL183 Physics 4 0 1 5 5. MEL110 Introduction to Engg. Materials 3 0 0 3 6. Elective-I 2 0 0 2 SOA- 101 Drug Abuse: Problem, Management 2 0 0 2 7. and Prevention -Interdisciplinary Course (Compulsory) List of Electives–I: 1. PBL121 Punjabi (Compulsory)OR 2 0 0 2. PBL122* w[ZYbh gzikph OR 2 0 0 2 Punjab History & Culture 3. HSL101* 2 0 0 (1450-1716) Total Credits: 20 2 2 24 SEMESTER –II S. Course Code Course Title L T P Credits No. 1. CYL197 Engineering Chemistry 3 0 1 4 2. MTL102 Mathematics-II 3 1 0 4 Basic Electrical &Electronics 3. ECL119 4 0 1 5 Engineering Fundamentals of IT & Programming 4. CSL126 2 1 1 4 using Python 5. -

Lecture 9: Games I
Lecture 9: Games I CS221 / Spring 2018 / Sadigh Course plan Search problems Markov decision processes Constraint satisfaction problems Adversarial games Bayesian networks Reflex States Variables Logic "Low-level intelligence" "High-level intelligence" Machine learning CS221 / Spring 2018 / Sadigh 1 • This lecture will be about games, which have been one of the main testbeds for developing AI programs since the early days of AI. Games are distinguished from the other tasks that we've considered so far in this class in that they make explicit the presence of other agents, whose utility is not generally aligned with ours. Thus, the optimal strategy (policy) for us will depend on the strategies of these agents. Moreover, their strategies are often unknown and adversarial. How do we reason about this? A simple game Example: game 1 You choose one of the three bins. I choose a number from that bin. Your goal is to maximize the chosen number. A B C -50 50 1 3 -5 15 CS221 / Spring 2018 / Sadigh 3 • Which bin should you pick? Depends on your mental model of the other player (me). • If you think I'm working with you (unlikely), then you should pick A in hopes of getting 50. If you think I'm against you (likely), then you should pick B as to guard against the worst case (get 1). If you think I'm just acting uniformly at random, then you should pick C so that on average things are reasonable (get 5 in expectation). Roadmap Games, expectimax Minimax, expectiminimax Evaluation functions Alpha-beta pruning CS221 / Spring 2018 / Sadigh 5 Game tree Key idea: game tree Each node is a decision point for a player. -

Uninformed Search Strategies
Chapter 1 Uninformed Search Strategies Exercise 1.1 Given the search problem defined by the following graph, where A is the initial state and L is the goal state and the cost of each action is indicated on the corresponding edge E 2 L 1 3 4 3 1 B 1 A 2 G 1 I 1 1 3 3 2 2 D 1 C F 1 H Solve the search problem using the following search strategies: 1. breadth-first with elimination of repeated states 2. uniform-cost with elimination of repeated states 3. depth-first with elimination of repeated states 1 Answer of exercise 1.1 Breadth-first search with elimination of repeated states. 1 A 2 3 4 B E F 5 6 C A F G H D IF L Uniform-cost search with elimination of repeated states. 1 A c=1 c=3 c=3 2 5 6 B E F c=2 c=4 3 7 C A F G H c=6 c=6 c=3 4 8 9 D G I c=9 B F LI In case of ties, nodes have been considered in lexicographic order. 2 Depth-first search with elimination of repeated states. 1 A 2 5 B E F 3 6 C A F G 4 7 D H 8 B G I 9 F I L 3 Exercise 1.2 You have three containers that may hold 12 liters, 8 liters and 3 liters of water, respectively, as well as access to a water faucet. You canfill a container from the faucet, pour it into another container, or empty it onto the ground. -

Minimax Search • Alpha-Beta Search • Games with an Element of Chance • State of the Art
Foundations of AI 6. Adversarial Search Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard & Luc De Raedt & Bernhard Nebel 1 Contents • Game Theory • Board Games • Minimax Search • Alpha-Beta Search • Games with an Element of Chance • State of the Art 2 Games & Game Theory • When there is more than one agent, the future is not anymore easily predictable for the agent • In competitive environments (when there are conflicting goals), adversarial search becomes necessary • Mathematical game theory gives the theoretical framework (even for non-competitive environments) • In AI, we usually consider only a special type of games, namely, board games, which can be characterized in game theory terminology as – Extensive, deterministic, two-player, zero-sum games with perfect information 3 Why Board Games? • Board games are one of the oldest branches of AI (Shannon, Turing, Wiener, and Shanon 1950). • Board games present a very abstract and pure form of competition between two opponents and clearly require a form on “intelligence”. • The states of a game are easy to represent. • The possible actions of the players are well defined. • Realization of the game as a search problem • The world states are fully accessible • It is nonetheless a contingency problem, because the characteristics of the opponent are not known in advance. Note: Nowadays, we also consider sport games 4 Problems • Board games are not only difficult because they are contingency problems, but also because the search trees can become astronomically large. • Examples: – Chess: On average 35 possible actions from every position, 100 possible moves 35100 nodes in the search tree (with “only” approx. -

Constraint Propagation
Motivation Suppose you are an independent software developer, and your software package Windows Defeater R , widely available on sourceforge under a GNU GPL license, is getting an international attention and acclaim. One of your fan clubs, located in the Polish city of Łódź (pron. woodge), calls you on a Sunday afternoon, urging you to pay them a visit on Monday morning and give a talk on open source software initiative and standards. The talk is scheduled for 10am Monday at the largest regional university, and both the university President and the city Mayor have been invited to attend, and both have confirmed their arrivals. What should you do? Obviously, you want to go, but it is not so simple. You are located in a Polish city of Wrocław (pron. vrotslaf), and while only 200 km away from Łódź, there is no convenient morning train connection from Wrocław to Łódź. The only direct train leaves Wrocław at 7:18 in the morning, but arrives 11:27 at Łódź Kaliska, which is across town from the University’s Department of Mathematics and Computer Science. An earlier regional train leaves Wrocław at 5am, but with two train switches, you would arrive at Łódź Kaliska at 10:09, which is still not early enough. There are no flights connecting the two cities, but there are numerous buses, which are probably your best choice. And there is still the option of driving, as much as you love it. Search methods — motivation 1 What we are dealing with here is a planning problem, with a number of choices, which need to be taken under consideration in turn, their outcomes analyzed and further actions determined, which bring about still more choices. -

CS440/ECE448 Fall 2016 Midterm Review You Need to Be Able To
CS440/ECE448 Fall 2016 Midterm Review You need to be able to define the following terms and answer basic questions about them: • Intro to AI, agents and environments o Possible definitions of AI, pros and cons of each o Turing test: pros and cons, alternatives o Rationality o Utility, expected utility o PEAS o Environment characteristics: fully vs. partially observable, deterministic vs. stochastic, episodic vs. sequential, static vs. dynamic, discrete vs. continuous, single-agent vs. multi-agent, known vs. unknown • Search o Search problem formulation: initial state, actions, transition model, goal state, path cost, state space o Tree search algorithm outline, frontier, search strategy, repeated state detection o Evaluation of search strategies: completeness, optimality, time complexity, space complexity o Uninformed search strategies: breadth-first search, uniform cost search, depth- first search, iterative deepening search o Informed search strategies: greedy best-first, A*, weighted A* o Heuristics: admissibility, consistency, dominance o Optimality of A* • Constraint satisfaction problems o Backtracking search o Heuristics: most constrained/most constraining variable, least constraining value o Forward checking, constraint propagation, arc consistency o Tree-structured CSPs o Local search o SAT problem, NP-completeness • Games o Zero-sum games o Game tree o Minimax strategy, minimax search o Alpha-beta pruning o Evaluation functions o Quiescence search, horizon effect o Monte Carlo tree search, AlphaGo o Stochastic games, expectiminimax o Partially observable games • Game theory o Normal form representation o Dominant strategy o Nash equilibrium (pure and mixed strategy) o Pareto optimality o Examples of games: Prisoner’s Dilemma, Stag Hunt, Game of Chicken o Mechanism design: auctions, regulation • Planning o Situation space vs. -
Learning to Play Two-Player Perfect-Information Games Without Knowledge
Learning to Play Two-Player Perfect-Information Games without Knowledge Quentin Cohen-Solala aCRIL, Univ. Artois and CNRS, F-62300 Lens, France LAMSADE, Universite´ Paris-Dauphine, PSL, CNRS, France Abstract In this paper, several techniques for learning game state evaluation functions by rein- forcement are proposed. The first is a generalization of tree bootstrapping (tree learn- ing): it is adapted to the context of reinforcement learning without knowledge based on non-linear functions. With this technique, no information is lost during the rein- forcement learning process. The second is a modification of minimax with unbounded depth extending the best sequences of actions to the terminal states. This modified search is intended to be used during the learning process. The third is to replace the classic gain of a game (+1 / −1) with a reinforcement heuristic. We study particular reinforcement heuristics such as: quick wins and slow defeats ; scoring ; mobility or presence. The fourth is another variant of unbounded minimax, which plays the safest action instead of playing the best action. This modified search is intended to be used af- ter the learning process. The fifth is a new action selection distribution. The conducted experiments suggest that these techniques improve the level of play. Finally, we apply these different techniques to design program-players to the game of Hex (size 11 and 13) surpassing the level of Mohex 3HNN with reinforcement learning from self-play arXiv:2008.01188v2 [cs.AI] 21 Dec 2020 without knowledge. Keywords: Machine Learning, Tree Search, Games, Game Tree Learning, Minimax, Heuristic, Action Distribution, Unbound Minimax, Hex. -

Alpha-Beta Pruning – the Fact of the Adversary Leads to an Advantage in Search!
Game-Playing & Adversarial Search This lecture topic: Game-Playing & Adversarial Search (two lectures) Chapter 5.1-5.5 Next lecture topic: Constraint Satisfaction Problems (two lectures) Chapter 6.1-6.4, except 6.3.3 (Please read lecture topic material before and after each lecture on that topic) Overview • Minimax Search with Perfect Decisions – Impractical in most cases, but theoretical basis for analysis • Minimax Search with Cut-off – Replace terminal leaf utility by heuristic evaluation function • Alpha-Beta Pruning – The fact of the adversary leads to an advantage in search! • Practical Considerations – Redundant path elimination, look-up tables, etc. • Game Search with Chance – Expectiminimax search You Will Be Expected to Know • Basic definitions (section 5.1) • Minimax optimal game search (5.2) • Alpha-beta pruning (5.3) • Evaluation functions, cutting off search (5.4.1, 5.4.2) • Expectiminimax (5.5) Types of Games battleship Kriegspiel Not Considered: Physical games like tennis, croquet, ice hockey, etc. (but see “robot soccer” http://www.robocup.org/) Typical assumptions • Two agents whose actions alternate • Utility values for each agent are the opposite of the other – This creates the adversarial situation • Fully observable environments • In game theory terms: – “Deterministic, turn-taking, zero-sum games of perfect information” • Generalizes to stochastic games, multiple players, non zero-sum, etc. • Compare to, e.g., “Prisoner’s Dilemma” (p. 666-668, R&N 3rd ed.) – “Deterministic, NON-turn-taking, NON-zero-sum game of IMperfect information” Game tree (2-player, deterministic, turns) How do we search this tree to find the optimal move? Search versus Games • Search – no adversary – Solution is (heuristic) method for finding goal – Heuristics and CSP techniques can find optimal solution – Evaluation function: estimate of cost from start to goal through given node – Examples: path planning, scheduling activities • Games – adversary – Solution is strategy • strategy specifies move for every possible opponent reply. -

Notes for Introduction to Artificial Intelligence
Anca MĂRGINEAN NOTES FOR INTRODUCTION TO ARTIFICIAL INTELLIGENCE U.T. PRESS Cluj-Napoca, 2015 ISBN 978-606-737-077-5 Editura U.T.PRESS Str.Observatorului nr. 34 C.P.42, O.P. 2, 400775 Cluj-Napoca Tel.:0264-401.999 / Fax: 0264 - 430.408 e-mail: [email protected] www.utcluj.ro/editura Director: Prof.dr.ing. Daniela Manea Consilier editorial: Ing. Călin D. Câmpean Copyright © 2015 Editura U.T.PRESS Reproducerea integrală sau parţială a textului sau ilustraţiilor din această carte este posibilă numai cu acordul prealabil scris al editurii U.T.PRESS. Multiplicareaă executat la Editura U.T.PRESS. ISBN 978-606-737-077-5 Bun de tipar: 22.06.2015 Preface This book contains laboratory works related to artificial intelligence domain and it is aimed as an introduction to AI through examples. Its main focus are the students from the third year of Computer Science Department from the Faculty of Automation and Computer Science, Technical University of Cluj-Napoca. Each laboratory work, except the first one, includes a brief theoretical de- scription of the algorithms, followed by a section of problems, either theoretical or practical. For the theoretical problems, one or more steps of the studied algo- rithms must be applied. Proper justifications are also required. For the practical ones, two environments are proposed: Aima3e-Java and Pac-Man projects. AIMA3e-Java is a Java implementation of the algorithms from Norvig and Russell's Artificial Intelligence - A Modern Approach 3rd Edition. It is available online at https://github.com/aima-java/aima-java. Pac-Man projects are educational Python projects aimed for teaching foundational AI concepts, such as search, probabilistic inference, and reinforcement projects. -

Sparse Sampling for Adversarial Games
Sparse Sampling for Adversarial Games Marc Lanctot1, Abdallah Saffidine2, Joel Veness1, Chris Archibald1 1University of Alberta, Edmonton, Alberta, Canada 2LAMSADE, Universite´ Paris-Dauphine, Paris, France Abstract. This paper introduces Monte Carlo *-Minimax Search (MCMS), a Monte-Carlo search algorithm for finite, turned based, stochastic, two-player, zero-sum games of perfect information. Through a combination of sparse sam- pling and classical pruning techniques, MCMS allows deep plans to be con- structed. Unlike other popular tree search techniques, MCMS is suitable for densely stochastic games, i.e., games where one would never expect to sample the same state twice. We give a basis for the theoretical properties of the al- gorithm and evaluate its performance in three games: Pig (Pig Out), EinStein Wurfelt¨ Nicht!, and Can’t Stop. 1 Introduction Monte-Carlo Tree Search (MCTS) has recently become one of the dominant paradigms for online planning in large sequential games. Since its initial application to Computer Go [Gelly et al., 2006, Coulom, 2007a], numerous extensions have been proposed, al- lowing this general approach [Chaslot et al., 2008a] to be successfully adapted to a variety of challenging problem settings, including real-time strategy games, imperfect information games and General Game Playing [Finnsson and Bjornsson,¨ 2008, Szita et al., 2010, Winands et al., 2010, Auger, 2011, Ciancarini and Favini, 2010]. At first, the method was applied to games lacking strong Minimax players, but recently has been shown to compete against strong Minimax players in such games [Ramanujan and Selman, 2011, Winands and Bjornsson,¨ 2010]. One class of games that has proven more resistant is stochastic games. -
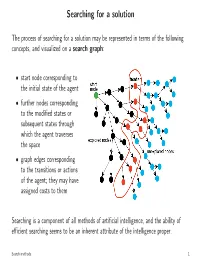
Searching for a Solution
Searching for a solution The process of searching for a solution may be represented in terms of the following concepts, and visualized on a search graph: • start node corresponding to the initial state of the agent • further nodes corresponding to the modified states or subsequent states through which the agent traverses the space • graph edges corresponding to the transitions or actions of the agent; they may have assigned costs to them Searching is a component of all methods of artificial intelligence, and the ability of efficient searching seems to be an inherent attribute of the intelligence proper. Search methods 1 Backtracking search (BT) FUNCTION BT(st) BEGIN IF Term(st) THEN RETURN(NIL) ; trivial solution IF DeadEnd(st) THEN RETURN(FAIL) ; no solution ops:=ApplOps(st) ;applicableoperators L: IF null(ops) THEN RETURN(FAIL) ; no solution o1 := first(ops) ops := rest(ops) st2 := Apply(o1,st) path := BT(st2) IF path == FAIL THEN GOTO L RETURN(push(o1,path)) END The BT algorithm efficiently searches the solution space without explicitly building the search tree. The data structures it utilizes to hold the search process state are hidden (on the execution stack). It is possible to convert this algorithm to an iterative version, which builds these structures explicitly. The iterative version is more efficient computationally, but lack the clarity of the above recursive statement of the algorithm. Search methods — backtracking search 2 Backtracking search — properties BT has minimal memory requirements. During the search it only keeps a single solution path (along with some context for each element of the path). Its space complexity of the average case is O(d), where d — the distance from the initial state to the solution (measured in the number of the operator steps).