ECE 3574: Applied Software Design
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Avatud Lähtekoodiga Vahendite Kohandamine Microsoft Visual C++ Tarkvaralahenduste Kvaliteedi Analüüsiks Sonarqube Serveris
TALLINNA TEHNIKAÜLIKOOL Infotehnoloogia teaduskond Tarkvarateaduse instituut Anton Ašot Roolaid 980774IAPB AVATUD LÄHTEKOODIGA VAHENDITE KOHANDAMINE MICROSOFT VISUAL C++ TARKVARALAHENDUSTE KVALITEEDI ANALÜÜSIKS SONARQUBE SERVERIS Bakalaureusetöö Juhendaja: Juhan-Peep Ernits PhD Tallinn 2019 Autorideklaratsioon Kinnitan, et olen koostanud antud lõputöö iseseisvalt ning seda ei ole kellegi teise poolt varem kaitsmisele esitatud. Kõik töö koostamisel kasutatud teiste autorite tööd, olulised seisukohad, kirjandusallikatest ja mujalt pärinevad andmed on töös viidatud. Autor: Anton Ašot Roolaid 21.05.2019 2 Annotatsioon Käesolevas bakalaureusetöös uuritakse, kuidas on võimalik saavutada suure hulga C++ lähtekoodi kvaliteedi paranemist, kui ettevõttes kasutatakse arenduseks Microsoft Visual Studiot ning koodikaetuse ja staatilise analüüsi ülevaate saamiseks SonarQube serverit (Community Edition). Seejuures SonarSource'i poolt pakutava tasulise SonarCFamily for C/C++ analüsaatori (mille eelduseks on SonarQube serveri Developer Edition) asemel kasutatakse tasuta ja vaba alternatiivi: SonarQube C++ Community pluginat. Analüüsivahenditena eelistatakse avatud lähtekoodiga vabu tarkvaravahendeid. Valituks osutuvad koodi kaetuse analüüsi utiliit OpenCppCoverage ja staatilise analüüsi utiliit Cppcheck. Siiski selgub, et nende utiliitide töö korraldamiseks ja väljundi sobitamiseks SonarQube Scanneri vajadustega tuleb kirjutada paar skripti: üks PowerShellis ja teine Windowsi pakkfailina. Regulaarselt ajastatud analüüside käivitamist tagab QuickBuild, -

The Kate Handbook
The Kate Handbook Anders Lund Seth Rothberg Dominik Haumann T.C. Hollingsworth The Kate Handbook 2 Contents 1 Introduction 10 2 The Fundamentals 11 2.1 Starting Kate . 11 2.1.1 From the Menu . 11 2.1.2 From the Command Line . 11 2.1.2.1 Command Line Options . 12 2.1.3 Drag and Drop . 13 2.2 Working with Kate . 13 2.2.1 Quick Start . 13 2.2.2 Shortcuts . 13 2.3 Working With the KateMDI . 14 2.3.1 Overview . 14 2.3.1.1 The Main Window . 14 2.3.2 The Editor area . 14 2.4 Using Sessions . 15 2.5 Getting Help . 15 2.5.1 With Kate . 15 2.5.2 With Your Text Files . 16 2.5.3 Articles on Kate . 16 3 Working with the Kate Editor 17 4 Working with Plugins 18 4.1 Kate Application Plugins . 18 4.2 External Tools . 19 4.2.1 Configuring External Tools . 19 4.2.2 Variable Expansion . 20 4.2.3 List of Default Tools . 22 4.3 Backtrace Browser Plugin . 25 4.3.1 Using the Backtrace Browser Plugin . 25 4.3.2 Configuration . 26 4.4 Build Plugin . 26 The Kate Handbook 4.4.1 Introduction . 26 4.4.2 Using the Build Plugin . 26 4.4.2.1 Target Settings tab . 27 4.4.2.2 Output tab . 28 4.4.3 Menu Structure . 28 4.4.4 Thanks and Acknowledgments . 28 4.5 Close Except/Like Plugin . 28 4.5.1 Introduction . 28 4.5.2 Using the Close Except/Like Plugin . -

Formal Verification to Ensuring the Memory Safety of C++ Programs
FORMAL VERIFICATION TO ENSURING THE MEMORY SAFETY OF C++ PROGRAMS A DISSERTATION SUBMITTED TO THE POSTGRADUATE PROGRAM IN INFORMATICS OF FEDERAL UNIVERSITY OF AMAZONAS IN FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER OF SCIENCE Felipe R. Monteiro April 2020 © Copyright by Felipe R. Monteiro 2020 All Rights Reserved ii I certify that I have read this dissertation and that, in my opinion, it is fully adequate in scope and quality as a dissertation for the degree of Master of Science. (Lucas Cordeiro) Principal Adviser I certify that I have read this dissertation and that, in my opinion, it is fully adequate in scope and quality as a dissertation for the degree of Master of Science. (Raimundo Barreto) I certify that I have read this dissertation and that, in my opinion, it is fully adequate in scope and quality as a dissertation for the degree of Master of Science. (Herbert Rocha) Approved for the Institute of Computing Committee on Postgraduate Studies iii Abstract In the last three decades, memory safety issues in low-level programming languages such as C or C++ have been one of the significant sources of security vulnerabilities; however, there exist only a few attempts with limited success to cope with the complexity of C++ program verification. This work describes and evaluates a novel verification approach based on bounded model checking (BMC) and satisfiability modulo theories (SMT) to verify C++ programs formally. This verification approach analyzes bounded C++ programs by encoding various sophisticated features that the C++ programming language offers into SMT, such as templates, sequential and associative containers, inheritance, polymorphism, and exception handling. -

Part 2 Jenkins Continuous Integration Server
Configuring a professional open source development environment – Part 2 By Thomas Arnbjerg, TechPeople, 2018 Jenkins Continuous Integration Server Introduction 2 Prerequisites 3 Installing Jenkins 3 Introduction 4 Steps 4 Installing external programs 7 Cppcheck 8 cpplint 9 sloccount 9 valgrind 10 gcovr 10 Eclipse 10 Installing Jenkins plugins 11 Creating a build job 12 Build job ‘HelloWorld’ 13 Generating a data basis 13 Visualizing the result 22 Other 24 Tour of the ‘HelloWorld’ and the Jenkins user interface 25 Summary page 25 Live build console output 26 Job overview 27 Automatic start of build 28 Jenkins and branches 29 Branching – GitFlow 29 Branches and Jenkins file 30 Multibranch pipeline build and HelloWorld 31 Final Jenkins tips 37 Mission Control Plugin 37 Build Monitor Plugin 38 ThinBackup 38 Job Configuration History 39 Docker support 39 Cpplint support 39 More Jenkins nodes 39 Blue Ocean user interface 39 Rounding off 41 1/42 Introduction In Part 1,a variety of functions in Jenkins were visualized. I this part, we are going to drill below the surface and look at the configuration and use in a Continuous Integration (CI) scenario in which Jenkins supports the development in feature branches. We configure a number of build jobs using the support functions which were visualized in Part 1 (shown below in reduced format). CppCheck, Unit Tests (TAP format) and Code SLOCCount (Source Lines Of Code Count), Valgrind Coverage. analysis For a Linux system, we will then configure Jenkins to do the following: ● Check the source code using the CPPCheck and CPPLint tools which means creating static code analysis to locate basic code errors and deviations from the code standard. -

Arm® Forge User Guide Copyright © 2021 Arm Limited Or Its Affiliates
Arm® Forge Version 21.0.2 User Guide Copyright © 2021 Arm Limited or its affiliates. All rights reserved. 101136_21.0.2_00_en Arm® Forge Arm® Forge User Guide Copyright © 2021 Arm Limited or its affiliates. All rights reserved. Release Information Document History Issue Date Confidentiality Change 2100-00 01 March 2021 Non-Confidential Document update to version 21.0 2101-00 30 March 2021 Non-Confidential Document update to version 21.0.1 2102-00 30 April 2021 Non-Confidential Document update to version 21.0.2 Non-Confidential Proprietary Notice This document is protected by copyright and other related rights and the practice or implementation of the information contained in this document may be protected by one or more patents or pending patent applications. No part of this document may be reproduced in any form by any means without the express prior written permission of Arm. No license, express or implied, by estoppel or otherwise to any intellectual property rights is granted by this document unless specifically stated. Your access to the information in this document is conditional upon your acceptance that you will not use or permit others to use the information for the purposes of determining whether implementations infringe any third party patents. THIS DOCUMENT IS PROVIDED “AS IS”. ARM PROVIDES NO REPRESENTATIONS AND NO WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, INCLUDING, WITHOUT LIMITATION, THE IMPLIED WARRANTIES OF MERCHANTABILITY, SATISFACTORY QUALITY, NON-INFRINGEMENT OR FITNESS FOR A PARTICULAR PURPOSE WITH RESPECT TO THE DOCUMENT. For the avoidance of doubt, Arm makes no representation with respect to, and has undertaken no analysis to identify or understand the scope and content of, third party patents, copyrights, trade secrets, or other rights. -

Lexical Categories for Source Code Identifiers
Lexical Categories for Source Code Identifiers Christian D. Newman Reem S. AlSuhaibani Michael L. Collard Jonathan I. Maletic Computer Science Computer Science Computer Science Computer Science Kent State University Kent State University The University of Akron Kent State University Kent, OH 44240 USA Kent, OH 44240 USA Akron, Ohio, USA Kent, Ohio, 44240 USA [email protected] [email protected] [email protected] [email protected] Abstract—A set of lexical categories, analogous to part-of- Part of speech tagging is a method of categorizing words speech categories for English prose, is defined for source-code with similar grammatical properties. It has been used in a identifiers. The lexical category for an identifier is determined number of software maintenance tasks including identifier from its declaration in the source code, syntactic meaning in the naming [5], code summarization [6, 7], reformulation of programming language, and static program analysis. Current source-code queries [8], concept location [9], traceability-link techniques for assigning lexical categories to identifiers use natural-language part-of-speech taggers. However, these NLP recovery [10], and bug fixing [11]. In all of these, the approaches assign lexical tags based on how terms are used in underlying need for PoS is to provide information about what English prose. The approach taken here differs in that it uses the word(s) that make up the identifier mean in English, so that only source code to determine the lexical category. The approach this meaning can be correlated with the identifier’s use in code. assigns a lexical category to each identifier and stores this The assumption made is that the words that make up the information along with each declaration. -

Code Audit Report
Code Audit Report Muhammad Uzair May 25, 2017 Abstract Many applications are being used by individuals and businesses these days. Also, these applications becoming a part of daily life. These appli- cations use personal information and sometimes very important business transaction information. The security of that information is a very im- portant issue. To make the information secure enough, it is required that the application is working as it should be. Code audit/review is done in this regard. If there are any flaws, weaknesses, threats or any kind of vulnerabilities found in the code, then actions are taken accordingly and fixes are applied. Some code audits examples are presented in this report and then the code audit report of DigiDoc is presented, which is a module of Open-EID. 1 Introduction Security of the applications being used is a major concern nowadays. Applica- tions have become a very common part of our daily life. These applications are being used for business and for personal use. Personal data, internal organi- zational data is managed by these applications so it is critical and essential to protect this data. There are many challenges when we talk about the protection of this important data and the security of these applications. Also the exposure to internet has made these applications a prime target for the information they contain. There are many advantages of Free and Open-Source Software (FOSS). One of them is that their source code is available which enables anyone to check the code and fix bugs, anyone can add new features and it is also important from security point of that anyone can check the security of the code and make it better. -

Conversational Code Analysis: the Future of Secure Coding Fitzroy D
i i “conversational˙analysis˙chapter” — 2021/5/14 — 0:17 — page 1 — #1 i i This chapter was accepted on May 12, 2021 for publication in the book Coding Theory - Recent Advances, New Perspectives and Applications, IntechOpen, London Chapter 1 Conversational Code Analysis: The Future of Secure Coding Fitzroy D. Nembhard and Marco M. Carvalho Abstract The area of software development and secure coding can benefit signifi- cantly from advancements in virtual assistants. Research has shown that many coders neglect security in favor of meeting deadlines. This shortcoming leaves systems vulnerable to attackers. While a plethora of tools are available for programmers to scan their code for vulnerabilities, finding the right tool can be challenging. It is therefore imperative to adopt measures to get programmers to utilize code analysis tools that will help them produce more secure code. This chapter looks at the limitations of existing approaches to secure coding and proposes a methodology that allows programmers to scan and fix vulnerabili- ties in program code by communicating with virtual assistants on their smart devices. With the ubiquitous move towards virtual assistants, it is important to design systems that are more reliant on voice than on standard point-and-click and keyboard-driven approaches. Consequently, we propose MyCodeAnalyzer, a Google Assistant app and code analysis framework, which was designed to interactively scan program code for vulnerabilities and flaws using voice commands during development. We describe the proposed methodology, implement a prototype, test it on a vulnerable project and present our results. Keywords: secure coding, virtual assistant, code analysis, static analysis 1. -

Evaluation of Automated Static Analysis Tools Cathleen L
GSTF Journal on Computing (JoC) Vol.2 No.1, April 2012 Performance Evaluation of Automated Static Analysis Tools Cathleen L. Blackmon, Daisy F. Sang, and Chang-Shyh Peng Abstract—Automated static analysis tools can perform as memory corruption, memory leaks and race conditions, efficient thorough checking of important properties of, and of software during execution. Since defects will not be extract and summarize critical information about, a source discovered until late in the software development program. This paper evaluates three open-source static lifecycle, dynamic analysis can be costly. On the other analysis tools; Flawfinder, Cppcheck and Yasca. Each tool hand, static analysis tools perform analysis on source is analyzed with regards to usability, IDE integration, performance, and accuracy. Special emphasis is placed on code or byte code modules. It does not require any the integration of these tools into the development instrumentation or development of test cases, and can be environment to enable analysis during all phases of utilized upon the availability of the code. Static analysis development as well as to enable extension of rules and other tools can go through all paths of the code and uncover improvements within the tools. It is shown that Flawfinder significantly more and wider range of defects, including be the easiest to modify and extend, Cppcheck be inviting to detect logic errors, dead code, security vulnerabilities, and novices, and Yasca be the most accurate and versatile. so on. Index Terms—static, code, analysis, automation. Static analysis techniques range widely. Simple style checkers identify poorly written code that may violate coding standards or consistency rules. -
C++ Developer Survey "Lite": 2018-02
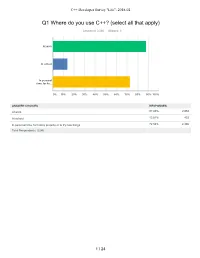
C++ Developer Survey "Lite": 2018-02 Q1 Where do you use C++? (select all that apply) Answered: 3,280 Skipped: 6 At work At school In personal time, for ho... 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES At work 87.93% 2,884 At school 13.81% 453 In personal time, for hobby projects or to try new things 72.56% 2,380 Total Respondents: 3,280 1 / 24 C++ Developer Survey "Lite": 2018-02 Q2 How many years of programming experience do you have in C++ specifically? Answered: 3,271 Skipped: 15 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 10.27% 336 3-5 years 20.85% 682 6-10 years 22.87% 748 10-20 years 30.63% 1,002 >20 years 15.38% 503 TOTAL 3,271 2 / 24 C++ Developer Survey "Lite": 2018-02 Q3 How many years of programming experience do you have overall (all languages)? Answered: 3,276 Skipped: 10 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 2.26% 74 3-5 years 11.66% 382 6-10 years 23.78% 779 10-20 years 33.55% 1,099 >20 years 28.75% 942 TOTAL 3,276 3 / 24 C++ Developer Survey "Lite": 2018-02 Q4 What types of projects do you work on? (select all that apply) Answered: 3,269 Skipped: 17 Business (e.g., B2B,.. -

Arm Forge User Guide
Arm Forge User Guide Version 18.2.1 Arm Forge 18.2.1 Contents Contents 1 I Arm Forge 12 1 Introduction 12 1.1 Arm DDT .......................................... 12 1.2 Arm MAP .......................................... 13 1.3 Online resources ...................................... 13 2 Installation 14 2.1 Linux installation ...................................... 14 2.1.1 Graphical install .................................. 14 2.1.2 Text-mode install .................................. 15 2.2 Mac installation ....................................... 16 2.3 Windows installation .................................... 16 2.4 License files ......................................... 17 2.5 Workstation and evaluation licenses ............................ 17 2.6 Supercomputing and other floating licenses ........................ 18 2.7 Architecture licensing .................................... 18 2.7.1 Using multiple architecture licenses ........................ 18 3 Connecting to a remote system 19 3.1 Remote connections dialog ................................. 19 3.2 Remote launch settings ................................... 20 3.2.1 Remote script .................................... 21 3.3 Reverse Connect ...................................... 21 3.3.1 Overview ...................................... 21 3.3.2 Usage ........................................ 22 3.3.3 Connection details ................................. 22 3.4 Treeserver or general debugging ports ........................... 23 3.5 Using X forwarding or VNC ............................... -

Static Code Analysis for Embedded Systems Master of Science Thesis in Computer Science and Engineering
Static Code Analysis For Embedded Systems Master of Science Thesis in Computer Science and Engineering MAGNUS ÅGREN Department of Computer Science and Engineering CHALMERS UNIVERSITY OF TECHNOLOGY UNIVERSITY OF GOTHENBURG Göteborg, Sweden, August 2009 The Author grants to Chalmers University of Technology and University of Gothenburg the non-exclusive right to publish the Work electronically and in a non-commercial purpose make it accessible on the Internet. The Author warrants that he/she is the author to the Work, and warrants that the Work does not contain text, pictures or other material that violates copyright law. The Author shall, when transferring the rights of the Work to a third party (for example a publisher or a company), acknowledge the third party about this agreement. If the Author has signed a copyright agreement with a third party regarding the Work, the Author warrants hereby that he/she has obtained any necessary permission from this third party to let Chalmers University of Technology and University of Gothenburg store the Work electronically and make it accessible on the Internet. Static Code Analysis For Embedded Systems MAGNUS ÅGREN © MAGNUS ÅGREN, August 2009. Examiner: PATRIK JANSSON Department of Computer Science and Engineering Chalmers University of Technology SE-412 96 Göteborg Sweden Telephone + 46 (0)31-772 1000 Department of Computer Science and Engineering Göteborg, Sweden August 2009 Abstract Much software for embedded systems is written in languages such as C. This is known to be error prone, because of manual memory management and similar insecurities. A countermeasure against such problems is static code analysis. This thesis presents an evaluation of techniques for static code analysis, focusing on methods of fault detection.