System Support for Online Reconfiguration
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Fujitsu PCI Expansion Unit
PCI Expansion Unit The PCI Expansion Unit—an I/O expansion option for Oracle’s Fujitsu SPARC M12 and Fujitsu M10 family of servers—meets demands for applications requiring extensive scalability, mission-critical levels of availability, and Key Features seamless data center integration. The PCI Supports the Fujitsu SPARC M12 and Fujitsu M10 family of servers Expansion Unit takes maximum advantage of Provides 11 PCIe 3.0 slots in a small 2U form factor the high I/O bandwidth of Fujitsu SPARC M12 Powers on and off in synchronization with the power status of Fujitsu and Fujitsu M10 servers. SPARC M12 and Fujitsu M10 servers Enables hot swapping of PCIe cards, power supplies, and fans Monitored and controlled from the XSCF System Monitoring Function of the Fujitsu SPARC M12 and Fujitsu M10 servers Configured with 1 + 1 power supply PRODUCT OVERVIEW redundancy and supports a dual Perfectly suited for Fujitsu SPARC servers, the PCI Expansion Unit offers significant power feed configuration I/O adapter expandability. One or more PCI Expansion Units can be connected to both Fujitsu SPARC M12 and Fujitsu M10 servers, providing connectivity of up to 11 additional PCI Express (PCIe) slots per PCI Expansion Unit in a space-saving rackmount chassis (2U). PCIe generation 3 is supported by the PCI Expansion Unit. Easy Monitoring and Control from Fujitsu SPARC Servers The PCI Expansion Unit can be easily monitored and controlled in conjunction with the XSCF (eXtended System Control Facility) system monitoring function of Fujitsu SPARC servers. PCI Expansion Units power on and off in synchronization with the power status of Fujitsu SPARC servers. -

Nexto Series
Technical Characteristics Nexto Series Doc Code: CE114000 Revision: I Nexto Series Programmable Logic Controller Nexto Series is a powerful and complete Programmable Logic Controllers (PLCs) series with exclusive and innovative features, targeted for covering control systems requirements from medium to large applications or high performance industrial machines. Nexto Series architecture provides a wide range of input and output modules. These modules, combined with a powerful 32-bit processor and a high-speed-Ethernet-based backplane, cover many user applications, such as high-speed machinery control, complex distributed and redundant process applications or even large I/O systems for building automation. Besides, it delivers modules for motion control, communication and interfaces to the most popular fieldbuses, among other features. Nexto Series architecture uses a state-of-the-art high-speed Ethernet backplane bus technology, which allows input, output and processed information to be shared among all modules within the system. The I/O modules can be easily distributed in the field. It can be used local as well as remote I/Os without any loss in performance. In addition, Nexto Series brings a complete tool for programming, configuration, simulation and debugging user application: MasterTool IEC XE. MasterTool IEC XE is flexible and easy to use software that provides the six programming languages defined by IEC 61131-3 standard: Structured Text (ST), Sequential Function Chart (SFC), Function Block Diagram (FBD), Ladder Diagram (LD), Instruction List (IL) and Continuous Function Chart (CFC). MasteTool IEC XE allows the use of different languages on the same application, providing to the user a powerful way to organize the application and to reuse codes used in previous applications. -

USB 3.0 to SATA 2.5" Tool-Less Enclosure Quick Installation Guide
USB 3.0 to SATA 2.5" Tool-less Enclosure Quick Installation Guide Introduction The USB 3.0 to SATA 2.5" Tool-less Enclosure is designed to work USB equipped computers. This enclosure provides large capacity mobile storage using 2.5" SATA hard disk drives through hot-swapping USB 3.0 interface. Key Features and Benefits • Quickly adds more storage space to your USB-enabled PC (USB 3.0 recommended) • Supports USB 3.0 data transfer rate up to 5Gb/s • Tool-less design and no driver installation required • Supports up to 4TB hard disk capacity 04-0790B 1 Note: For maximum data throughput, use a SATA 3Gb/s hard disk with the enclosure and connect to a fully functional USB 3.0 port. System Requirements • Notebook or desktop PC with an available USB 2.0/3.0 port (USB 3.0 recommended) • Windows® 8 (32-/64-bit) / 7 (32-/64-bit) / Vista (32-/64-bit) / XP (32-/64-bit) / Server 2003 & 2008 (32-/64-bit) / Server 2008 R2 Package Contents • USB 3.0 to SATA 2.5" Tool-less Enclosure • USB 3.0 Y-split (data & power) cable • 2 Sponges (optional) • Quick installation guide 2 Layout Top cover USB 3.0 micro-B connector Bottom cover Power/Activity LED Slider to release the cases Figure 1: Back Panel Layout USB 3.0 Y-split Cable Type-A power (white) Type-A data (blue) micro-B Figure 2: USB 3.0 Y-split Cable Connectors 3 Power and Activity LED The LED indicator illuminates when the enclosure is connected and powered up. -

Honeywell's Next Generation Plcs Powerful, Compact, Versatile, Open Network
Programmable Logic Controllers MasterLogic-200 Honeywell's next generation PLCs Powerful, compact, versatile, open network Programmable Logic Controllers MasterLogic-200 · Powerful & versatile · Scalable & modular · Compact pocket-size modules · CPU redundancy, power supply redundancy, network redundancy · Range of I/O modules-digital (source/sink,transistor/relay),analog (voltage/current) · Special modules-High Speed Counter, Position Control, RTD, Thermocouple · Open network-Profibus-DP, DeviceNet, Fast Ethernet, Modbus · Dedicated peer-to-peer networking of PLCs · Large I/O capacity and Remote I/O Contents Overview 4 Overview Introduction System Architecture 8 CPU & System configuration General Specifications CPU Specifications Highlights Introduction Network Fast Ethernet(FEnet) 15 Serial Communication(Snet) Profibus-DP(Pnet) DeviceNet(Dnet) Digital I/O Modules Input/Output Modules 20 Position Control Modules Analog I/O Modules Smart I/O(s) Thermocouple Module RTD Module High Speed Counter Modules Key Features Software 29 Project Management Online Functions Maintenance & Troubleshooting Monitoring PLC Event History Program Navigation & Editing Program Ease Simulation System Requirements SoftMaster-NM (Network setup & diagnostics) Special Interface Special Interface with Experion 37 PKS & Experion Vista MasterLogic-50 Other Related Products Master Panel 38 HCiX Series Product List 39 Product List Overview Introduction Key Features · Powerful & versatile processors - High speed i.e. (28ns/step, flash memory, hot-swapping) · CPU redundancy -

Providing Dynamic Update in an Operating System
Providing Dynamic Update in an Operating System Andrew Baumann, Gernot Heiser University of New South Wales & National ICT Australia Jonathan Appavoo, Dilma Da Silva, Orran Krieger, Robert W. Wisniewski IBM T.J. Watson Research Center Jeremy Kerr IBM Linux Technology Center Abstract Dynamic update [26] is used to avoid such downtime. It involves on-the-fly application of software updates to Dynamic update is a mechanism that allows software a running system without loss of service. The increased updates and patches to be applied to a running system unplanned down-time of computing infrastructure to ap- without loss of service or down-time. Operating systems ply updates, combined with the demand for continuous would benefit from dynamic update, but place unique de- availability, provides strong motivation to investigate dy- mands on any implementation of such features. These namic update techniques for operating systems. demands stem from the event-driven nature of operating In addition to the above mentioned impact on avail- systems, from their restricted run-time execution envi- ability, dynamically updatable systems have other bene- ronment, and from their role in simultaneously servicing fits. Such systems provide a good prototyping environ- multiple clients. ment. They allow, for example, a new page replacement, We have implemented a dynamic update mechanism file system, or network policy to be tested without re- in the K42 research operating system, and tested it us- booting. Further, in more mature systems such as main- ing previous modifications of the system by kernel de- frames, some user constraints prevent the system from velopers. Our system supports updates changing both ever being shutdown. -
Data Sheet 6ES7510-1DJ01-0AB0
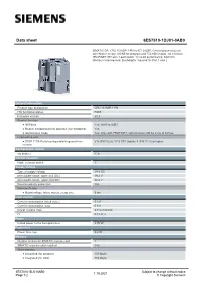
Data sheet 6ES7510-1DJ01-0AB0 SIMATIC DP, CPU 1510SP-1 PN for ET 200SP, Central processing unit with Work memory 100 KB for program and 750 KB for data, 1st interface: PROFINET IRT with 3-port switch, 72 ns bit performance, SIMATIC Memory Card required, BusAdapter required for Port 1 and 2 General information Product type designation CPU 1510SP-1 PN HW functional status FS05 Firmware version V2.8 Product function ● I&M data Yes; I&M0 to I&M3 ● Module swapping during operation (hot swapping) Yes ● Isochronous mode Yes; Only with PROFINET; with minimum OB 6x cycle of 625 µs Engineering with ● STEP 7 TIA Portal configurable/integrated from V16 (FW V2.8) / V13 SP1 Update 4 (FW V1.8) or higher version Configuration control via dataset Yes Control elements Mode selector switch 1 Supply voltage Type of supply voltage 24 V DC permissible range, lower limit (DC) 19.2 V permissible range, upper limit (DC) 28.8 V Reverse polarity protection Yes Mains buffering ● Mains/voltage failure stored energy time 5 ms Input current Current consumption (rated value) 0.6 A Current consumption, max. 0.9 A Inrush current, max. 4.7 A; nominal I²t 0.14 A²·s Power Infeed power to the backplane bus 8.75 W Power loss Power loss, typ. 5.6 W Memory Number of slots for SIMATIC memory card 1 SIMATIC memory card required Yes Work memory ● integrated (for program) 100 kbyte ● integrated (for data) 750 kbyte 6ES75101DJ010AB0 Subject to change without notice 1.19.2021 Page 1/2 © Copyright Siemens Load memory ● Plug-in (SIMATIC Memory Card), max. -

18-Go-And-Erlang.Pdf
Erlang and Go (CS262a, Berkeley Fall 2016) Philipp Moritz The Problem Distributed computation is hard! ● State ○ Hard to do recovery, dependency on order of execution ● Concurrency and Synchronization ○ Hard to reason about, deadlocks ● Fault handling ○ Error origin and handling in different parts of the system ● Complexity of coupled components ○ Makes it hard to develop software in large teams This lecture is about languages/tools that make it easier to write distributed programs Erlang ● Developed at Ericson as a proprietary language to improve development of telephony applications ● High availability of nine “9”s (30 ms downtime per year) ● 1986: initial version in Prolog ● 1992: BEAM (High performance VM) ● since 1998: Open source named after Agner Krarup Erlang, mathematician and inventor of queuing theory Erlang: Requirements ● Designed for telecommunication systems ● Hard requirements: ○ High degree of concurrency ○ Distributed ○ Soft real-time capabilities ○ 100% availability ● Soft requirements: ○ Hot swapping code Erlang: Philosophy Requirements Decision ● 100% availability Erlang: Philosophy Requirements Decision ● 100% availability ● strong fault recovery ○ hierarchy of tasks for recovery ○ isolation between tasks ○ dynamic code upgrade Erlang: Philosophy Requirements Decision ● 100% availability ● strong fault recovery ● portability (e.g. to embedded ○ hierarchy of tasks for recovery devices) ○ isolation between tasks ○ dynamic code upgrade Erlang: Philosophy Requirements Decision ● 100% availability ● strong fault recovery -

JUMO Mtron T – Your System the Scalable Measuring, Control, and Automation System
JUMO mTRON T – Your System The scalable measuring, control, and automation system www.jumo.net Contact: Phone: +49 661 6003-727 Email: [email protected] Dear Reader, JUMO has been a reliable partner for high-quality measure- Extremely high-quality universal analog inputs for a wide ment and control technology for more than 60 years. “More range of input variables and the JUMO control algorithm that than sensors + automation” – this is our philosophy and our has been proven over the years ensure high process reliability commitment. With JUMO mTRON T we have developed a and the greatest possible transparency. measuring, control, and automation system which combines the latest technology and long-standing experience for an Let us surprise you with our JUMO mTRON T system. The innovative complete solution. following pages describe all the important information about our modular measuring, control, and automation system. Do JUMO mTRON T is a dynamic system which is constantly you have questions about a particular application? Our ap- being refined in response to customer requirements and can plication team would be happy to work with you to develop a be used in a multitude of applications. The expertise of our tailored solution. proven control and recording systems as well as the imple- mentation of our experiences with diverse industries make Further information about the JUMO mTRON T system can JUMO mTRON T a flexible system solution that is easy to be found under the specified type/product group number at operate. www.JUMO.mTRON-T.net. The modular component concept with variable I/O modules combined with powerful control panels is just as impressive in the area of measured value recording as it is for complex control tasks and sophisticated automation solutions. -

Regul Rx00 Programmable Logic Controllers
REGUL RX00 PROGRAMMABLE LOGIC CONTROLLERS 2019 automation.gp-systems.com Contents REGUL RX00 Programmable Logic Controllers 2 REGUL R600 Programmable Logic Controller 2 Hardware Configuration 6 Smart I/O Modules 7 Redundancy 8 Dimensional Drawings 9 REGUL R500 Programmable Logic Controller 10 Examples of Rack Connections 15 Smart I/O Modules 16 Redundancy 17 Dimensional Drawings 18 REGUL R400 HMI / Programmable Logic Controller 20 Hardware Configuration 21 Dimensional Drawings 21 REGUL R200 Programmable Logic Controller 22 Hardware Configuration 25 Dimensional Drawings 26 EPSILON LD – IEC 61131-3 Programming and Configuration Software for REGUL Controllers 28 Industrial Solutions and Examples 30 Oil and Gas 30 Fiscal Metering – Control System for Lease Automatic Custody Transfer (LACT) Units 30 Control System for Oil Pumping Stations 32 Control System for Gas Pressure Regulators 34 Fire and Gas System 36 Telemetry Solution 39 Gas Odorizing Control System 40 Power Generation and Distribution 41 Thyone - Protection and Control System for Steam and Gas Turbines 41 Tarvus – Electronic Overspeed Trip for Steam and Gas Turbines 42 Automatic Load-Frequency Control System 43 Turbo-generator Vibration Monitoring System 45 MS5002E (Mark VIe) Gas Turbine Control System 46 Other 47 Industrial Converter Gateway 47 1 REGUL R600 Programmable Logic Controller Regul R600 is a high-availability real-time programmable logic controller, designed for the use in process industries, where additional electromagnetic protection, vandal-proof housing, and/or extended -

Swapbox: a Hot-Swapping Framework for Swappable Javabeans
SwapBox: a Hot-Swapping Framework for Swappable JavaBeans By Lei Tan A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfilment of the requirements for the degree of Master of Science Ottawa-Carleton Institute for Electrical Engineering Faculty of Engineering Department of Systems and Computer Engineering Carleton University 1125 Colonel Drive Ottawa, Ontario, Canada K1S 5B6 September 4, 2001 Copyright 2001, Lei Tan The undersigned hereby recommend to the faculty of Graduate Studies and Research acceptance of the thesis SwapBox: a Hot Swapping Framework for Swappable JavaBeans submitted by Lei Tan in partial fulfilment of the requirements for the degree of Master of Science Thesis Supervisor Chair, Department of Systems and Computer Engineering Carleton University September 4, 2001 Abstract Software hot swapping refers to the replacement of a part of a program with a new version at runtime. Increasing demands for on-line software upgrading in safety- and mission-critical systems drive the research. This thesis proposes a new hot swapping infrastructure for hot swapping software applications. A set of the issues facing hot swapping systems design is derived from state-of-the-art research. A hot swapping prototype for swappable JavaBeans is proposed. The prototype is implemented as SwapBox, which is a running environment and hot swapping management tool for swappable JavaBeans. The SwapBox allows implementation change, incremental and decremental interface change, as well as data structure change between versions. It is designed as an extensible framework so that future research could add new hot swapping strategies into it. Two sample applications are developed to completely test the SwapBox. -

Large-Scale Computing in Erlang
Large-Scale Computing in Erlang Stephen Franklin, Brook Tamir, Gregory Chang ● Where Erlang is Used Agenda ● History ● Language Features ● Basics ● Distributed Computing ● Whatsapp Where Erlang is ● Goldman Sachs Used ● BT Mobile ● Discord ● Ericsson ● Cisco ● Nintendo ● Erlang was developed at the Ericsson and History Ellemtel Computer Science Laboratories. ● Erlang was created as an experiment to see if declarative programming techniques could be applied to large industrial scale telecom switching systems that needed to be incredibly reliable and scalable. ● Scientists at Ericsson realized that many of the problems related to telecommunications could also be applied to a wide variety of real-time control problems faced in other industries and released it as a general purpose language. Erlang, while also being a syllabic abbreviation of "Ericsson Language", is named after Danish mathematician and engineer Agner Krarup Source: https://erlang.org/download/erlang-book-part1.pdf Erlang. Erlang is a declarative, general purpose, functional Language Features programming language, built with concurrency in mind. Main features: ● Declarative ● Concurrent ● Real-time (Soft) ● Continuous operation ● Robust ● VM/Real-time Garbage Collected ● No shared memory ● Easily Integrate with programs written in other languages. ● Hot Swapping Source: https://erlang.org/download/erlang-book-part1.pdf Basics Erlang is primarily a functional programming language. A core difference between Erlang and an imperative language like Java is that there is a heavy focus on processes. Variables are immutable. Individual blocks of code produces consistent output values. Basic program syntax and execution ● Since the language employs pattern matching the Erlang VM will decide which function to employ based pattern matching of the parameters. -

Download File
Columbia University Department of Computer Science Tech Report CUCS-015-05 Multi-Language Edit-and-Continue for the Masses Marc Eaddy Steven Feiner Department of Computer Science Columbia University New York, NY 10027 +1-212-939-7000 {eaddy,feiner}@cs.columbia.edu April 4, 2005 ABSTRACT We present an Edit-and-Continue implementation that allows regular source files to be treated like interactively updatable, compiled scripts, coupling the speed of compiled na- tive machine code, with the ability to make changes without restarting. Our implementa- tion is based on the Microsoft .NET Framework and allows applications written in any .NET language to be dynamically updatable. Our solution works with the standard ver- sion of the Microsoft Common Language Runtime, and does not require a custom com- piler or runtime. Because no application changes are needed, it is transparent to the appli- cation developer. The runtime overhead of our implementation is low enough to support updating real-time applications (e.g., interactive 3D graphics applications). Categories and Subject Descriptors D.3.3 [Software Engineering]: Programming Environments—Interactive environments; Testing and Debugging—Debugging aids; D.1 [Software]: Programming Techniques— Dynamic Software Updating; D.3.3 [Programming Languages]: Processors— Incremental compilers, dynamic compilers General Terms Experimentation, Languages, Performance Keywords dynamic software updating, online reconfiguration, patching, edit-and-continue, hot- swapping, rapid application development, .NET 1. INTRODUCTION Edit-and-Continue is a common debugging feature found in many integrated develop- ment environments (IDEs). It refers to the ability to pause an application, usually via a breakpoint, make changes to the source code that are recompiled in the background, and then continue execution with the modified application.