Accurate Floating Point Product and Exponentiation Stef Graillat
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Common Course Outline MATH 257 Linear Algebra 4 Credits
Common Course Outline MATH 257 Linear Algebra 4 Credits The Community College of Baltimore County Description MATH 257 – Linear Algebra is one of the suggested elective courses for students majoring in Mathematics, Computer Science or Engineering. Included are geometric vectors, matrices, systems of linear equations, vector spaces, linear transformations, determinants, eigenvectors and inner product spaces. 4 Credits: 5 lecture hours Prerequisite: MATH 251 with a grade of “C” or better Overall Course Objectives Upon successfully completing the course, students will be able to: 1. perform matrix operations; 2. use Gaussian Elimination, Cramer’s Rule, and the inverse of the coefficient matrix to solve systems of Linear Equations; 3. find the inverse of a matrix by Gaussian Elimination or using the adjoint matrix; 4. compute the determinant of a matrix using cofactor expansion or elementary row operations; 5. apply Gaussian Elimination to solve problems concerning Markov Chains; 6. verify that a structure is a vector space by checking the axioms; 7. verify that a subset is a subspace and that a set of vectors is a basis; 8. compute the dimensions of subspaces; 9. compute the matrix representation of a linear transformation; 10. apply notions of linear transformations to discuss rotations and reflections of two dimensional space; 11. compute eigenvalues and find their corresponding eigenvectors; 12. diagonalize a matrix using eigenvalues; 13. apply properties of vectors and dot product to prove results in geometry; 14. apply notions of vectors, dot product and matrices to construct a best fitting curve; 15. construct a solution to real world problems using problem methods individually and in groups; 16. -

Lesson 2: the Multiplication of Polynomials
NYS COMMON CORE MATHEMATICS CURRICULUM Lesson 2 M1 ALGEBRA II Lesson 2: The Multiplication of Polynomials Student Outcomes . Students develop the distributive property for application to polynomial multiplication. Students connect multiplication of polynomials with multiplication of multi-digit integers. Lesson Notes This lesson begins to address standards A-SSE.A.2 and A-APR.C.4 directly and provides opportunities for students to practice MP.7 and MP.8. The work is scaffolded to allow students to discern patterns in repeated calculations, leading to some general polynomial identities that are explored further in the remaining lessons of this module. As in the last lesson, if students struggle with this lesson, they may need to review concepts covered in previous grades, such as: The connection between area properties and the distributive property: Grade 7, Module 6, Lesson 21. Introduction to the table method of multiplying polynomials: Algebra I, Module 1, Lesson 9. Multiplying polynomials (in the context of quadratics): Algebra I, Module 4, Lessons 1 and 2. Since division is the inverse operation of multiplication, it is important to make sure that your students understand how to multiply polynomials before moving on to division of polynomials in Lesson 3 of this module. In Lesson 3, division is explored using the reverse tabular method, so it is important for students to work through the table diagrams in this lesson to prepare them for the upcoming work. There continues to be a sharp distinction in this curriculum between justification and proof, such as justifying the identity (푎 + 푏)2 = 푎2 + 2푎푏 + 푏 using area properties and proving the identity using the distributive property. -

21. Orthonormal Bases
21. Orthonormal Bases The canonical/standard basis 011 001 001 B C B C B C B0C B1C B0C e1 = B.C ; e2 = B.C ; : : : ; en = B.C B.C B.C B.C @.A @.A @.A 0 0 1 has many useful properties. • Each of the standard basis vectors has unit length: q p T jjeijj = ei ei = ei ei = 1: • The standard basis vectors are orthogonal (in other words, at right angles or perpendicular). T ei ej = ei ej = 0 when i 6= j This is summarized by ( 1 i = j eT e = δ = ; i j ij 0 i 6= j where δij is the Kronecker delta. Notice that the Kronecker delta gives the entries of the identity matrix. Given column vectors v and w, we have seen that the dot product v w is the same as the matrix multiplication vT w. This is the inner product on n T R . We can also form the outer product vw , which gives a square matrix. 1 The outer product on the standard basis vectors is interesting. Set T Π1 = e1e1 011 B C B0C = B.C 1 0 ::: 0 B.C @.A 0 01 0 ::: 01 B C B0 0 ::: 0C = B. .C B. .C @. .A 0 0 ::: 0 . T Πn = enen 001 B C B0C = B.C 0 0 ::: 1 B.C @.A 1 00 0 ::: 01 B C B0 0 ::: 0C = B. .C B. .C @. .A 0 0 ::: 1 In short, Πi is the diagonal square matrix with a 1 in the ith diagonal position and zeros everywhere else. -

Decimal Rounding
Mathematics Instructional Plan – Grade 5 Decimal Rounding Strand: Number and Number Sense Topic: Rounding decimals, through the thousandths, to the nearest whole number, tenth, or hundredth. Primary SOL: 5.1 The student, given a decimal through thousandths, will round to the nearest whole number, tenth, or hundredth. Materials Base-10 blocks Decimal Rounding activity sheet (attached) “Highest or Lowest” Game (attached) Open Number Lines activity sheet (attached) Ten-sided number generators with digits 0–9, or decks of cards Vocabulary approximate, between, closer to, decimal number, decimal point, hundredth, rounding, tenth, thousandth, whole Student/Teacher Actions: What should students be doing? What should teachers be doing? 1. Begin with a review of decimal place value: Display a decimal in the thousandths place, such as 34.726, using base-10 blocks. In pairs, have students discuss how to read the number using place-value names, and review the decimal place each digit holds. Briefly have students share their thoughts with the class by asking: What digit is in the tenths place? The hundredths place? The thousandths place? Who would like to share how to say this decimal using place value? 2. Ask, “If this were a monetary amount, $34.726, how would we determine the amount to the nearest cent?” Allow partners or small groups to discuss this question. It may be helpful if students underlined the place that indicates cents (the hundredths place) in order to keep track of the rounding place. Distribute the Open Number Lines activity sheet and display this number line on the board. Guide students to recall that the nearest cent is the same as the nearest hundredth of a dollar. -
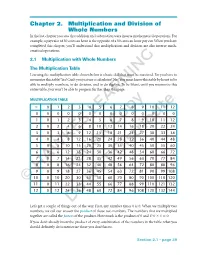
Chapter 2. Multiplication and Division of Whole Numbers in the Last Chapter You Saw That Addition and Subtraction Were Inverse Mathematical Operations
Chapter 2. Multiplication and Division of Whole Numbers In the last chapter you saw that addition and subtraction were inverse mathematical operations. For example, a pay raise of 50 cents an hour is the opposite of a 50 cents an hour pay cut. When you have completed this chapter, you’ll understand that multiplication and division are also inverse math- ematical operations. 2.1 Multiplication with Whole Numbers The Multiplication Table Learning the multiplication table shown below is a basic skill that must be mastered. Do you have to memorize this table? Yes! Can’t you just use a calculator? No! You must know this table by heart to be able to multiply numbers, to do division, and to do algebra. To be blunt, until you memorize this entire table, you won’t be able to progress further than this page. MULTIPLICATION TABLE ϫ 012 345 67 89101112 0 000 000LEARNING 00 000 00 1 012 345 67 89101112 2 024 681012Copy14 16 18 20 22 24 3 036 9121518212427303336 4 0481216 20 24 28 32 36 40 44 48 5051015202530354045505560 6061218243036424854606672Distribute 7071421283542495663707784 8081624324048566472808896 90918273HAWKESReview645546372819099108 10 0 10 20 30 40 50 60 70 80 90 100 110 120 ©11 0 11 22 33 44NOT 55 66 77 88 99 110 121 132 12 0 12 24 36 48 60 72 84 96 108 120 132 144 Do Let’s get a couple of things out of the way. First, any number times 0 is 0. When we multiply two numbers, we call our answer the product of those two numbers. -

Grade 7/8 Math Circles the Scale of Numbers Introduction
Faculty of Mathematics Centre for Education in Waterloo, Ontario N2L 3G1 Mathematics and Computing Grade 7/8 Math Circles November 21/22/23, 2017 The Scale of Numbers Introduction Last week we quickly took a look at scientific notation, which is one way we can write down really big numbers. We can also use scientific notation to write very small numbers. 1 × 103 = 1; 000 1 × 102 = 100 1 × 101 = 10 1 × 100 = 1 1 × 10−1 = 0:1 1 × 10−2 = 0:01 1 × 10−3 = 0:001 As you can see above, every time the value of the exponent decreases, the number gets smaller by a factor of 10. This pattern continues even into negative exponent values! Another way of picturing negative exponents is as a division by a positive exponent. 1 10−6 = = 0:000001 106 In this lesson we will be looking at some famous, interesting, or important small numbers, and begin slowly working our way up to the biggest numbers ever used in mathematics! Obviously we can come up with any arbitrary number that is either extremely small or extremely large, but the purpose of this lesson is to only look at numbers with some kind of mathematical or scientific significance. 1 Extremely Small Numbers 1. Zero • Zero or `0' is the number that represents nothingness. It is the number with the smallest magnitude. • Zero only began being used as a number around the year 500. Before this, ancient mathematicians struggled with the concept of `nothing' being `something'. 2. Planck's Constant This is the smallest number that we will be looking at today other than zero. -

Determinants Math 122 Calculus III D Joyce, Fall 2012
Determinants Math 122 Calculus III D Joyce, Fall 2012 What they are. A determinant is a value associated to a square array of numbers, that square array being called a square matrix. For example, here are determinants of a general 2 × 2 matrix and a general 3 × 3 matrix. a b = ad − bc: c d a b c d e f = aei + bfg + cdh − ceg − afh − bdi: g h i The determinant of a matrix A is usually denoted jAj or det (A). You can think of the rows of the determinant as being vectors. For the 3×3 matrix above, the vectors are u = (a; b; c), v = (d; e; f), and w = (g; h; i). Then the determinant is a value associated to n vectors in Rn. There's a general definition for n×n determinants. It's a particular signed sum of products of n entries in the matrix where each product is of one entry in each row and column. The two ways you can choose one entry in each row and column of the 2 × 2 matrix give you the two products ad and bc. There are six ways of chosing one entry in each row and column in a 3 × 3 matrix, and generally, there are n! ways in an n × n matrix. Thus, the determinant of a 4 × 4 matrix is the signed sum of 24, which is 4!, terms. In this general definition, half the terms are taken positively and half negatively. In class, we briefly saw how the signs are determined by permutations. -

28. Exterior Powers
28. Exterior powers 28.1 Desiderata 28.2 Definitions, uniqueness, existence 28.3 Some elementary facts 28.4 Exterior powers Vif of maps 28.5 Exterior powers of free modules 28.6 Determinants revisited 28.7 Minors of matrices 28.8 Uniqueness in the structure theorem 28.9 Cartan's lemma 28.10 Cayley-Hamilton Theorem 28.11 Worked examples While many of the arguments here have analogues for tensor products, it is worthwhile to repeat these arguments with the relevant variations, both for practice, and to be sensitive to the differences. 1. Desiderata Again, we review missing items in our development of linear algebra. We are missing a development of determinants of matrices whose entries may be in commutative rings, rather than fields. We would like an intrinsic definition of determinants of endomorphisms, rather than one that depends upon a choice of coordinates, even if we eventually prove that the determinant is independent of the coordinates. We anticipate that Artin's axiomatization of determinants of matrices should be mirrored in much of what we do here. We want a direct and natural proof of the Cayley-Hamilton theorem. Linear algebra over fields is insufficient, since the introduction of the indeterminate x in the definition of the characteristic polynomial takes us outside the class of vector spaces over fields. We want to give a conceptual proof for the uniqueness part of the structure theorem for finitely-generated modules over principal ideal domains. Multi-linear algebra over fields is surely insufficient for this. 417 418 Exterior powers 2. Definitions, uniqueness, existence Let R be a commutative ring with 1. -

IEEE Standard 754 for Binary Floating-Point Arithmetic
Work in Progress: Lecture Notes on the Status of IEEE 754 October 1, 1997 3:36 am Lecture Notes on the Status of IEEE Standard 754 for Binary Floating-Point Arithmetic Prof. W. Kahan Elect. Eng. & Computer Science University of California Berkeley CA 94720-1776 Introduction: Twenty years ago anarchy threatened floating-point arithmetic. Over a dozen commercially significant arithmetics boasted diverse wordsizes, precisions, rounding procedures and over/underflow behaviors, and more were in the works. “Portable” software intended to reconcile that numerical diversity had become unbearably costly to develop. Thirteen years ago, when IEEE 754 became official, major microprocessor manufacturers had already adopted it despite the challenge it posed to implementors. With unprecedented altruism, hardware designers had risen to its challenge in the belief that they would ease and encourage a vast burgeoning of numerical software. They did succeed to a considerable extent. Anyway, rounding anomalies that preoccupied all of us in the 1970s afflict only CRAY X-MPs — J90s now. Now atrophy threatens features of IEEE 754 caught in a vicious circle: Those features lack support in programming languages and compilers, so those features are mishandled and/or practically unusable, so those features are little known and less in demand, and so those features lack support in programming languages and compilers. To help break that circle, those features are discussed in these notes under the following headings: Representable Numbers, Normal and Subnormal, Infinite -

The Notion Of" Unimaginable Numbers" in Computational Number Theory
Beyond Knuth’s notation for “Unimaginable Numbers” within computational number theory Antonino Leonardis1 - Gianfranco d’Atri2 - Fabio Caldarola3 1 Department of Mathematics and Computer Science, University of Calabria Arcavacata di Rende, Italy e-mail: [email protected] 2 Department of Mathematics and Computer Science, University of Calabria Arcavacata di Rende, Italy 3 Department of Mathematics and Computer Science, University of Calabria Arcavacata di Rende, Italy e-mail: [email protected] Abstract Literature considers under the name unimaginable numbers any positive in- teger going beyond any physical application, with this being more of a vague description of what we are talking about rather than an actual mathemati- cal definition (it is indeed used in many sources without a proper definition). This simply means that research in this topic must always consider shortened representations, usually involving recursion, to even being able to describe such numbers. One of the most known methodologies to conceive such numbers is using hyper-operations, that is a sequence of binary functions defined recursively starting from the usual chain: addition - multiplication - exponentiation. arXiv:1901.05372v2 [cs.LO] 12 Mar 2019 The most important notations to represent such hyper-operations have been considered by Knuth, Goodstein, Ackermann and Conway as described in this work’s introduction. Within this work we will give an axiomatic setup for this topic, and then try to find on one hand other ways to represent unimaginable numbers, as well as on the other hand applications to computer science, where the algorith- mic nature of representations and the increased computation capabilities of 1 computers give the perfect field to develop further the topic, exploring some possibilities to effectively operate with such big numbers. -

Variables and Calculations
¡ ¢ £ ¤ ¥ ¢ ¤ ¦ § ¨ © © § ¦ © § © ¦ £ £ © § ! 3 VARIABLES AND CALCULATIONS Now you’re ready to learn your first ele- ments of Python and start learning how to solve programming problems. Although programming languages have myriad features, the core parts of any programming language are the instructions that perform numerical calculations. In this chapter, we’ll explore how math is performed in Python programs and learn how to solve some prob- lems using only mathematical operations. ¡ ¢ £ ¤ ¥ ¢ ¤ ¦ § ¨ © © § ¦ © § © ¦ £ £ © § ! Sample Program Let’s start by looking at a very simple problem and its Python solution. PROBLEM: THE TOTAL COST OF TOOTHPASTE A store sells toothpaste at $1.76 per tube. Sales tax is 8 percent. For a user-specified number of tubes, display the cost of the toothpaste, showing the subtotal, sales tax, and total, including tax. First I’ll show you a program that solves this problem: toothpaste.py tube_count = int(input("How many tubes to buy: ")) toothpaste_cost = 1.76 subtotal = toothpaste_cost * tube_count sales_tax_rate = 0.08 sales_tax = subtotal * sales_tax_rate total = subtotal + sales_tax print("Toothpaste subtotal: $", subtotal, sep = "") print("Tax: $", sales_tax, sep = "") print("Total is $", total, " including tax.", sep = ") Parts of this program may make intuitive sense to you already; you know how you would answer the question using a calculator and a scratch pad, so you know that the program must be doing something similar. Over the next few pages, you’ll learn exactly what’s going on in these lines of code. For now, enter this program into your Python editor exactly as shown and save it with the required .py extension. Run the program several times with different responses to the question to verify that the program works. -

Introduction to the Python Language
Introduction to the Python language CS111 Computer Programming Department of Computer Science Wellesley College Python Intro Overview o Values: 10 (integer), 3.1415 (decimal number or float), 'wellesley' (text or string) o Types: numbers and text: int, float, str type(10) Knowing the type of a type('wellesley') value allows us to choose the right operator when o Operators: + - * / % = creating expressions. o Expressions: (they always produce a value as a result) len('abc') * 'abc' + 'def' o Built-in functions: max, min, len, int, float, str, round, print, input Python Intro 2 Concepts in this slide: Simple Expressions: numerical values, math operators, Python as calculator expressions. Input Output Expressions Values In [...] Out […] 1+2 3 3*4 12 3 * 4 12 # Spaces don't matter 3.4 * 5.67 19.278 # Floating point (decimal) operations 2 + 3 * 4 14 # Precedence: * binds more tightly than + (2 + 3) * 4 20 # Overriding precedence with parentheses 11 / 4 2.75 # Floating point (decimal) division 11 // 4 2 # Integer division 11 % 4 3 # Remainder 5 - 3.4 1.6 3.25 * 4 13.0 11.0 // 2 5.0 # output is float if at least one input is float 5 // 2.25 2.0 5 % 2.25 0.5 Python Intro 3 Concepts in this slide: Strings and concatenation string values, string operators, TypeError A string is just a sequence of characters that we write between a pair of double quotes or a pair of single quotes. Strings are usually displayed with single quotes. The same string value is created regardless of which quotes are used.