Lecture 6: Integration and the Mean Value Theorem 1 the Mean Value
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Directional Derivative the Derivative of a Real Valued Function (Scalar field) with Respect to a Vector
Math 253 The Directional Derivative The derivative of a real valued function (scalar field) with respect to a vector. f(x + h) f(x) What is the vector space analog to the usual derivative in one variable? f 0(x) = lim − ? h 0 h ! x -2 0 2 5 Suppose f is a real valued function (a mapping f : Rn R). ! (e.g. f(x; y) = x2 y2). − 0 Unlike the case with plane figures, functions grow in a variety of z ways at each point on a surface (or n{dimensional structure). We'll be interested in examining the way (f) changes as we move -5 from a point X~ to a nearby point in a particular direction. -2 0 y 2 Figure 1: f(x; y) = x2 y2 − The Directional Derivative x -2 0 2 5 We'll be interested in examining the way (f) changes as we move ~ in a particular direction 0 from a point X to a nearby point . z -5 -2 0 y 2 Figure 2: f(x; y) = x2 y2 − y If we give the direction by using a second vector, say ~u, then for →u X→ + h any real number h, the vector X~ + h~u represents a change in X→ position from X~ along a line through X~ parallel to ~u. →u →u h x Figure 3: Change in position along line parallel to ~u The Directional Derivative x -2 0 2 5 We'll be interested in examining the way (f) changes as we move ~ in a particular direction 0 from a point X to a nearby point . -

Cauchy Integral Theorem
Cauchy’s Theorems I Ang M.S. Augustin-Louis Cauchy October 26, 2012 1789 – 1857 References Murray R. Spiegel Complex V ariables with introduction to conformal mapping and its applications Dennis G. Zill , P. D. Shanahan A F irst Course in Complex Analysis with Applications J. H. Mathews , R. W. Howell Complex Analysis F or Mathematics and Engineerng 1 Summary • Cauchy Integral Theorem Let f be analytic in a simply connected domain D. If C is a simple closed contour that lies in D , and there is no singular point inside the contour, then ˆ f (z) dz = 0 C • Cauchy Integral Formula (For simple pole) If there is a singular point z0 inside the contour, then ˛ f(z) dz = 2πj f(z0) z − z0 • Generalized Cauchy Integral Formula (For pole with any order) ˛ f(z) 2πj (n−1) n dz = f (z0) (z − z0) (n − 1)! • Cauchy Inequality M · n! f (n)(z ) ≤ 0 rn • Gauss Mean Value Theorem ˆ 2π ( ) 1 jθ f(z0) = f z0 + re dθ 2π 0 1 2 Related Mathematics Review 2.1 Stoke’s Theorem ¨ ˛ r × F¯ · dS = F¯ · dr Σ @Σ (The proof is skipped) ¯ Consider F = (FX ;FY ;FZ ) 0 1 x^ y^ z^ B @ @ @ C r × F¯ = det B C @ @x @y @z A FX FY FZ Let FZ = 0 0 1 x^ y^ z^ B @ @ @ C r × F¯ = det B C @ @x @y @z A FX FY 0 dS =ndS ^ , for dS = dxdy , n^ =z ^ . By z^ · z^ = 1 , consider z^ component only for r × F¯ 0 1 x^ y^ z^ ( ) B @ @ @ C @F @F r × F¯ = det B C = Y − X z^ @ @x @y @z A @x @y FX FY 0 i.e. -

1 Mean Value Theorem 1 1.1 Applications of the Mean Value Theorem
Seunghee Ye Ma 8: Week 5 Oct 28 Week 5 Summary In Section 1, we go over the Mean Value Theorem and its applications. In Section 2, we will recap what we have covered so far this term. Topics Page 1 Mean Value Theorem 1 1.1 Applications of the Mean Value Theorem . .1 2 Midterm Review 5 2.1 Proof Techniques . .5 2.2 Sequences . .6 2.3 Series . .7 2.4 Continuity and Differentiability of Functions . .9 1 Mean Value Theorem The Mean Value Theorem is the following result: Theorem 1.1 (Mean Value Theorem). Let f be a continuous function on [a; b], which is differentiable on (a; b). Then, there exists some value c 2 (a; b) such that f(b) − f(a) f 0(c) = b − a Intuitively, the Mean Value Theorem is quite trivial. Say we want to drive to San Francisco, which is 380 miles from Caltech according to Google Map. If we start driving at 8am and arrive at 12pm, we know that we were driving over the speed limit at least once during the drive. This is exactly what the Mean Value Theorem tells us. Since the distance travelled is a continuous function of time, we know that there is a point in time when our speed was ≥ 380=4 >>> speed limit. As we can see from this example, the Mean Value Theorem is usually not a tough theorem to understand. The tricky thing is realizing when you should try to use it. Roughly speaking, we use the Mean Value Theorem when we want to turn the information about a function into information about its derivative, or vice-versa. -

MATH 25B Professor: Bena Tshishiku Michele Tienni Lowell House
MATH 25B Professor: Bena Tshishiku Michele Tienni Lowell House Cambridge, MA 02138 [email protected] Please note that these notes are not official and they are not to be considered as a sub- stitute for your notes. Specifically, you should not cite these notes in any of the work submitted for the class (problem sets, exams). The author does not guarantee the accu- racy of the content of this document. If you find a typo (which will probably happen) feel free to email me. Contents 1. January 225 1.1. Functions5 1.2. Limits6 2. January 247 2.1. Theorems about limits7 2.2. Continuity8 3. January 26 10 3.1. Continuity theorems 10 4. January 29 – Notes by Kim 12 4.1. Least Upper Bound property (the secret sauce of R) 12 4.2. Proof of the intermediate value theorem 13 4.3. Proof of the boundedness theorem 13 5. January 31 – Notes by Natalia 14 5.1. Generalizing the boundedness theorem 14 5.2. Subsets of Rn 14 5.3. Compactness 15 6. February 2 16 6.1. Onion ring theorem 16 6.2. Proof of Theorem 6.5 17 6.3. Compactness of closed rectangles 17 6.4. Further applications of compactness 17 7. February 5 19 7.1. Derivatives 19 7.2. Computing derivatives 20 8. February 7 22 8.1. Chain rule 22 Date: April 25, 2018. 1 8.2. Meaning of f 0 23 9. February 9 25 9.1. Polynomial approximation 25 9.2. Derivative magic wands 26 9.3. Taylor’s Theorem 27 9.4. -

The Mean Value Theorem) – Be Able to Precisely State the Mean Value Theorem and Rolle’S Theorem
Math 220 { Test 3 Information The test will be given during your lecture period on Wednesday (April 27, 2016). No books, notes, scratch paper, calculators or other electronic devices are allowed. Bring a Student ID. It may be helpful to look at • http://www.math.illinois.edu/~murphyrf/teaching/M220-S2016/ { Volumes worksheet, quizzes 8, 9, 10, 11 and 12, and Daily Assignments for a summary of each lecture • https://compass2g.illinois.edu/ { Homework solutions • http://www.math.illinois.edu/~murphyrf/teaching/M220/ { Tests and quizzes in my previous courses • Section 3.10 (Linear Approximation and Differentials) { Be able to use a tangent line (or differentials) in order to approximate the value of a function near the point of tangency. • Section 4.2 (The Mean Value Theorem) { Be able to precisely state The Mean Value Theorem and Rolle's Theorem. { Be able to decide when functions satisfy the conditions of these theorems. If a function does satisfy the conditions, then be able to find the value of c guaranteed by the theorems. { Be able to use The Mean Value Theorem, Rolle's Theorem, or earlier important the- orems such as The Intermediate Value Theorem to prove some other fact. In the homework these often involved roots, solutions, x-intercepts, or intersection points. • Section 4.8 (Newton's Method) { Understand the graphical basis for Newton's Method (that is, use the point where the tangent line crosses the x-axis as your next estimate for a root of a function). { Be able to apply Newton's Method to approximate roots, solutions, x-intercepts, or intersection points. -

Calculus Terminology
AP Calculus BC Calculus Terminology Absolute Convergence Asymptote Continued Sum Absolute Maximum Average Rate of Change Continuous Function Absolute Minimum Average Value of a Function Continuously Differentiable Function Absolutely Convergent Axis of Rotation Converge Acceleration Boundary Value Problem Converge Absolutely Alternating Series Bounded Function Converge Conditionally Alternating Series Remainder Bounded Sequence Convergence Tests Alternating Series Test Bounds of Integration Convergent Sequence Analytic Methods Calculus Convergent Series Annulus Cartesian Form Critical Number Antiderivative of a Function Cavalieri’s Principle Critical Point Approximation by Differentials Center of Mass Formula Critical Value Arc Length of a Curve Centroid Curly d Area below a Curve Chain Rule Curve Area between Curves Comparison Test Curve Sketching Area of an Ellipse Concave Cusp Area of a Parabolic Segment Concave Down Cylindrical Shell Method Area under a Curve Concave Up Decreasing Function Area Using Parametric Equations Conditional Convergence Definite Integral Area Using Polar Coordinates Constant Term Definite Integral Rules Degenerate Divergent Series Function Operations Del Operator e Fundamental Theorem of Calculus Deleted Neighborhood Ellipsoid GLB Derivative End Behavior Global Maximum Derivative of a Power Series Essential Discontinuity Global Minimum Derivative Rules Explicit Differentiation Golden Spiral Difference Quotient Explicit Function Graphic Methods Differentiable Exponential Decay Greatest Lower Bound Differential -

Calculus Formulas and Theorems
Formulas and Theorems for Reference I. Tbigonometric Formulas l. sin2d+c,cis2d:1 sec2d l*cot20:<:sc:20 +.I sin(-d) : -sitt0 t,rs(-//) = t r1sl/ : -tallH 7. sin(A* B) :sitrAcosB*silBcosA 8. : siri A cos B - siu B <:os,;l 9. cos(A+ B) - cos,4cos B - siuA siriB 10. cos(A- B) : cosA cosB + silrA sirrB 11. 2 sirrd t:osd 12. <'os20- coS2(i - siu20 : 2<'os2o - I - 1 - 2sin20 I 13. tan d : <.rft0 (:ost/ I 14. <:ol0 : sirrd tattH 1 15. (:OS I/ 1 16. cscd - ri" 6i /F tl r(. cos[I ^ -el : sitt d \l 18. -01 : COSA 215 216 Formulas and Theorems II. Differentiation Formulas !(r") - trr:"-1 Q,:I' ]tra-fg'+gf' gJ'-,f g' - * (i) ,l' ,I - (tt(.r))9'(.,') ,i;.[tyt.rt) l'' d, \ (sttt rrJ .* ('oqI' .7, tJ, \ . ./ stll lr dr. l('os J { 1a,,,t,:r) - .,' o.t "11'2 1(<,ot.r') - (,.(,2.r' Q:T rl , (sc'c:.r'J: sPl'.r tall 11 ,7, d, - (<:s<t.r,; - (ls(].]'(rot;.r fr("'),t -.'' ,1 - fr(u") o,'ltrc ,l ,, 1 ' tlll ri - (l.t' .f d,^ --: I -iAl'CSllLl'l t!.r' J1 - rz 1(Arcsi' r) : oT Il12 Formulas and Theorems 2I7 III. Integration Formulas 1. ,f "or:artC 2. [\0,-trrlrl *(' .t "r 3. [,' ,t.,: r^x| (' ,I 4. In' a,,: lL , ,' .l 111Q 5. In., a.r: .rhr.r' .r r (' ,l f 6. sirr.r d.r' - ( os.r'-t C ./ 7. /.,,.r' dr : sitr.i'| (' .t 8. tl:r:hr sec,rl+ C or ln Jccrsrl+ C ,f'r^rr f 9. -

Approaching Green's Theorem Via Riemann Sums
APPROACHING GREEN’S THEOREM VIA RIEMANN SUMS JENNIE BUSKIN, PHILIP PROSAPIO, AND SCOTT A. TAYLOR ABSTRACT. We give a proof of Green’s theorem which captures the underlying intuition and which relies only on the mean value theorems for derivatives and integrals and on the change of variables theorem for double integrals. 1. INTRODUCTION The counterpoint of the discrete and continuous has been, perhaps even since Eu- clid, the essence of many mathematical fugues. Despite this, there are fundamental mathematical subjects where their voices are difficult to distinguish. For example, although early Calculus courses make much of the passage from the discrete world of average rate of change and Riemann sums to the continuous (or, more accurately, smooth) world of derivatives and integrals, by the time the student reaches the cen- tral material of vector calculus: scalar fields, vector fields, and their integrals over curves and surfaces, the voice of discrete mathematics has been obscured by the coloratura of continuous mathematics. Our aim in this article is to restore the bal- ance of the voices by showing how Green’s Theorem can be understood from the discrete point of view. Although Green’s Theorem admits many generalizations (the most important un- doubtedly being the Generalized Stokes’ Theorem from the theory of differentiable manifolds), we restrict ourselves to one of its simplest forms: Green’s Theorem. Let S ⊂ R2 be a compact surface bounded by (finitely many) simple closed piecewise C1 curves oriented so that S is on their left. Suppose that M F = is a C1 vector field defined on an open set U containing S. -
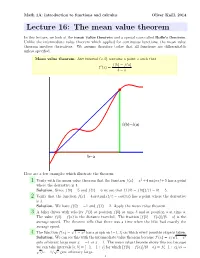
The Mean Value Theorem
Math 1A: introduction to functions and calculus Oliver Knill, 2014 Lecture 16: The mean value theorem In this lecture, we look at the mean value theorem and a special case called Rolle's theorem. Unlike the intermediate value theorem which applied for continuous functions, the mean value theorem involves derivatives. We assume therefore today that all functions are differentiable unless specified. Mean value theorem: Any interval (a; b) contains a point x such that f(b) − f(a) f 0(x) = : b − a f b -f a H L H L b-a Here are a few examples which illustrate the theorem: 1 Verify with the mean value theorem that the function f(x) = x2 +4 sin(πx)+5 has a point where the derivative is 1. Solution. Since f(0) = 5 and f(1) = 6 we see that (f(1) − f(0))=(1 − 0) = 5. 2 Verify that the function f(x) = 4 arctan(x)/π − cos(πx) has a point where the derivative is 3. Solution. We have f(0) = −1 and f(1) = 2. Apply the mean value theorem. 3 A biker drives with velocity f 0(t) at position f(b) at time b and at position a at time a. The value f(b) − f(a) is the distance traveled. The fraction [f(b) − f(a)]=(b − a) is the average speed. The theorem tells that there was a time when the bike had exactly the average speed. p 2 4 The function f(x) = 1 − x has a graph on (−1; 1) on which every possible slope isp taken. -

The Mean Value Theorem and Analytic Functions of a Complex Variable
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector J. Math. Anal. Appl. 324 (2006) 30–38 www.elsevier.com/locate/jmaa The mean value theorem and analytic functions of a complex variable M.A. Qazi Department of Mathematics, Tuskegee University, Tuskegee, AL 36088, USA Received 9 August 2005 Available online 10 January 2006 Submitted by A.V. Isaev Abstract The mean value theorem for real-valued differentiable functions defined on an interval is one of the most fundamental results in Analysis. When it comes to complex-valued functions the theorem fails even if the function is differentiable throughout the complex plane. we illustrate this by means of examples and also present three results of a positive nature. © 2005 Elsevier Inc. All rights reserved. Keywords: Mean value theorem; Entire functions; Quadrinomials; Univalent functions We start by recalling the mean value theorem [8, p. 93] of real analysis. Theorem A. Let f be a real continuous function on a closed interval [a,b] which is differentiable in the open interval (a, b). Then there is a point ξ ∈ (a, b) at which f(b)− f(a)= f (ξ)(b − a). This result extends to functions whose domains lie in the complex plane provided their ranges are on the real line.Infact,ifΩ is a convex domain in the n-dimensional Euclidean space, and f is real-valued and differentiable on Ω, then f(b)− f(a)= Df (ξ ) · (b − a) = grad f(ξ),b− a (a ∈ Ω, b ∈ Ω), E-mail address: [email protected]. -

Mean Value Theorem on Manifolds
MEAN VALUE THEOREMS ON MANIFOLDS Lei Ni Abstract We derive several mean value formulae on manifolds, generalizing the clas- sical one for harmonic functions on Euclidean spaces as well as the results of Schoen-Yau, Michael-Simon, etc, on curved Riemannian manifolds. For the heat equation a mean value theorem with respect to `heat spheres' is proved for heat equation with respect to evolving Riemannian metrics via a space-time consideration. Some new monotonicity formulae are derived. As applications of the new local monotonicity formulae, some local regularity theorems concerning Ricci flow are proved. 1. Introduction The mean value theorem for harmonic functions plays an central role in the theory of harmonic functions. In this article we discuss its generalization on manifolds and show how such generalizations lead to various monotonicity formulae. The main focuses of this article are the corresponding results for the parabolic equations, on which there have been many works, including [Fu, Wa, FG, GL1, E1], and the application of the new monotonicity formula to the study of Ricci flow. Let us start with the Watson's mean value formula [Wa] for the heat equation. Let U be a open subset of Rn (or a Riemannian manifold). Assume that u(x; t) is 2 a C solution to the heat equation in a parabolic region UT = U £ (0;T ). For any (x; t) de¯ne the `heat ball' by 8 9 jx¡yj2 < ¡ 4(t¡s) = e ¡n E(x; t; r) := (y; s) js · t; n ¸ r : : (4¼(t ¡ s)) 2 ; Then Z 1 jx ¡ yj2 u(x; t) = n u(y; s) 2 dy ds r E(x;t;r) 4(t ¡ s) for each E(x; t; r) ½ UT . -

Multivariable Calculus Review
Outline Multi-Variable Calculus Point-Set Topology Compactness The Weierstrass Extreme Value Theorem Operator and Matrix Norms Mean Value Theorem Multivariable Calculus Review Multivariable Calculus Review Outline Multi-Variable Calculus Point-Set Topology Compactness The Weierstrass Extreme Value Theorem Operator and Matrix Norms Mean Value Theorem Multi-Variable Calculus Point-Set Topology Compactness The Weierstrass Extreme Value Theorem Operator and Matrix Norms Mean Value Theorem Multivariable Calculus Review n I ν(x) ≥ 0 8 x 2 R with equality iff x = 0. n I ν(αx) = jαjν(x) 8 x 2 R α 2 R n I ν(x + y) ≤ ν(x) + ν(y) 8 x; y 2 R We usually denote ν(x) by kxk. Norms are convex functions. lp norms 1 Pn p p kxkp := ( i=1 jxi j ) ; 1 ≤ p < 1 kxk1 = maxi=1;:::;n jxi j Outline Multi-Variable Calculus Point-Set Topology Compactness The Weierstrass Extreme Value Theorem Operator and Matrix Norms Mean Value Theorem Multi-Variable Calculus Norms: n n A function ν : R ! R is a vector norm on R if Multivariable Calculus Review n I ν(αx) = jαjν(x) 8 x 2 R α 2 R n I ν(x + y) ≤ ν(x) + ν(y) 8 x; y 2 R We usually denote ν(x) by kxk. Norms are convex functions. lp norms 1 Pn p p kxkp := ( i=1 jxi j ) ; 1 ≤ p < 1 kxk1 = maxi=1;:::;n jxi j Outline Multi-Variable Calculus Point-Set Topology Compactness The Weierstrass Extreme Value Theorem Operator and Matrix Norms Mean Value Theorem Multi-Variable Calculus Norms: n n A function ν : R ! R is a vector norm on R if n I ν(x) ≥ 0 8 x 2 R with equality iff x = 0.