A Study of Memory Management for Web-Based Applications on Multicore Processors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Drupal Decision
The Drupal Decision Stephen Sanzo | Director of Marketing and Business Development | Isovera [email protected] www.isovera.com Agenda 6 Open Source 6 The Big Three 6 Why Drupal? 6 Overview 6 Features 6 Examples 6 Under the Hood 6 Questions (non-technical, please) Open Source Software “Let the code be available to all!” 6 Software that is available in source code form for which the source code and certain other rights normally reserved for copyright holders are provided under a software license that permits users to study, change, and improve the software. 6 Adoption of open-source software models has resulted in savings of about $60 billion per year to consumers. http://en.wikipedia.org/wiki/Open-source_software www.isovera.com Open Source Software However… Open source doesn't just mean access to the source code. The distribution terms of open-source software must comply criteria established by the Open Source Initiative. http://www.opensource.org/docs/osd www.isovera.com Open Source Software Free as in… Not this… www.isovera.com Open Source CMS Advantages for Open Source CMS 6 No licensing fees - allows you to obtain enterprise quality software at little to no cost 6 Vendor flexibility - you can choose whether or not you want to hire a vendor to help you customize, implement, and support it, or do this internally. If at any point along the way you decide you don’t like your vendor, you are free to find another. 6 Software flexibility – in many cases, proprietary software is slow to react to the markets needs. -
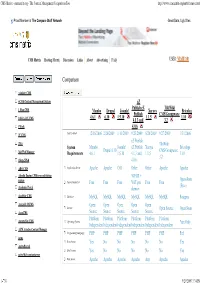
CMS Matrix - Cmsmatrix.Org - the Content Management Comparison Tool
CMS Matrix - cmsmatrix.org - The Content Management Comparison Tool http://www.cmsmatrix.org/matrix/cms-matrix Proud Member of The Compare Stuff Network Great Data, Ugly Sites CMS Matrix Hosting Matrix Discussion Links About Advertising FAQ USER: VISITOR Compare Search Return to Matrix Comparison <sitekit> CMS +CMS Content Management System eZ Publish eZ TikiWiki 1 Man CMS Mambo Drupal Joomla! Xaraya Bricolage Publish CMS/Groupware 4.6.1 6.10 1.5.10 1.1.5 1.10 1024 AJAX CMS 4.1.3 and 3.2 1Work 4.0.6 2F CMS Last Updated 12/16/2006 2/26/2009 1/11/2009 9/23/2009 8/20/2009 9/27/2009 1/31/2006 eZ Publish 2flex TikiWiki System Mambo Joomla! eZ Publish Xaraya Bricolage Drupal 6.10 CMS/Groupware 360 Web Manager Requirements 4.6.1 1.5.10 4.1.3 and 1.1.5 1.10 3.2 4Steps2Web 4.0.6 ABO.CMS Application Server Apache Apache CGI Other Other Apache Apache Absolut Engine CMS/news publishing 30EUR + system Open-Source Approximate Cost Free Free Free VAT per Free Free (Free) Academic Portal domain AccelSite CMS Database MySQL MySQL MySQL MySQL MySQL MySQL Postgres Accessify WCMS Open Open Open Open Open License Open Source Open Source AccuCMS Source Source Source Source Source Platform Platform Platform Platform Platform Platform Accura Site CMS Operating System *nix Only Independent Independent Independent Independent Independent Independent ACM Ariadne Content Manager Programming Language PHP PHP PHP PHP PHP PHP Perl acms Root Access Yes No No No No No Yes ActivePortail Shell Access Yes No No No No No Yes activeWeb contentserver Web Server Apache Apache -

Kosten Senken Dank Open Source?
View metadata, citation and similar papers at core.ac.uk brought to you by CORE Kosten senken dank Open Source? provided by Bern Open Repository andStrategien Information System (BORIS) | downloaded: 13.3.2017 https://doi.org/10.7892/boris.47380 source: 36 Nr. 01/02 | Februar 2014 Swiss IT Magazine Strategien Kosten senken dank Open Source? Mehr Geld im Portemonnaie und weniger Sorgen im Gepäck Der Einsatz von Open Source Software kann das IT-Budget schonen, wenn man richtig vorgeht. Viel wichtiger sind aber strategische Vorteile wie die digitale Nachhaltigkeit oder die Unabhängigkeit von Herstellern, die sich durch den konsequenten Einsatz von Open Source ergeben. V ON D R . M ATTHIAS S TÜR M ER ines vorweg: Open Source ist nicht gra- tis. Oder korrekt ausgedrückt: Der Download von Open Source Software (OSS) von den vielen Internet-Portalen wieE Github, Google Code, Sourceforge oder Freecode ist selbstverständlich kostenlos. Aber wenn Open-Source-Lösungen professionell eingeführt und betrieben werden, verursacht dies interne und/oder externe Kosten. Geschäftskritische Lösungen benötigen stets zuverlässige Wartung und Support, ansonsten steigt das Risiko erheblich, dass zentrale Infor- matiksysteme ausfallen oder wichtige Daten verloren gehen oder gestohlen werden. Für den sicheren Einsatz von Open Source Soft- ware braucht es deshalb entweder interne INHALT Ressourcen und Know-how, wie die entspre- chenden Systeme betrieben werden. Oder es MEHR GELD im PORTemoNNaie UND weNIGER SorgeN im GEPÄck 36 wird ein Service Level Agreement (SLA) bei- MarkTÜbersicHT: 152 SCHweiZer OPEN-SOUrce-SPEZialisTEN 40 spielsweise in Form einer Subscription mit einem kommerziellen Anbieter von Open- SpareN ODER NICHT spareN 48 Source-Lösungen abgeschlossen. -

DVD-Libre 2008-09 Os Wtd 47 Wwdes288 XMP167 As
(continuación 2) EasyTAG 2.1 - Eclipse 3.4 - Eclipse Graphical Editor Framework 3.4 - Eclipse Modeling Framework 2.4.1 - Eclipse PDT 1.0.3 - Eclipse UML2 2.2.0 - Eclipse Visual Editor 1.2.3 - Ekiga 2.0.11 beta - Elgg 1.0 - emesene 1.0 RC - EQAlign 2.0.4 - Eraser 5.86.a - Euler Math Toolbox 6.05 - eXe 1.04 - Exodus 0.9.1.0 - Explore2fs 1.08 beta9 - ez Components 2008.1 - eZ Publish 4.0.1 - Fast Floating Fractal Fun 3.2.3 - DVD-Libre FBReader 0.8.17 - FileZilla 3.1.2 - FileZilla Server 0.9.27 - Firebird 2.1.1.17910 - Firebug 1.2.0 - Firefox 3.0.1 - FLAC 1.2.1.b - FMSLogo 6.21.0 - Folder Size 2.4 - FractalForge 2.8.2 - Fraqtive 0.4.4 - Free Download Manager 2.5.758 - Free Pascal 2.2.2 - Free UCS Outline Fonts 2006.01.26 - Free1x2 0.70.2 - FreeCAD 0.7.1514 - FreeDOS 1.0 Disquete de arranque - FreeMat 3.6 - FreeMind 0.8.1 - FreePCB 1.2.0.0 - FreePCB 2008-09 1.353 - Fyre 1.0.0 - GAG 4.10 - Gambit 0.2007.12.04 - GanttProject 2.0.7 - GanttPV 0.9 - Gazpacho 0.7.2 - GCfilms 6.4 - GenealogyJ 2.4.4 - GeoGebra 3.0.0 - GeoLabo 1.25 - Geonext 1.71 - GIMP 2.4.7 - GIMP Animation package 2.2.0 - GIMPShop 2.2.8 - Git 1.5.5 - gmorgan 0.24 - GnuCash 2.2.6 - Gnumeric 1.9.1 DVD-Libre es una recopilación de programas libres para Windows. -

How to Create Ez Publish Forms / Articles / Developer / Ez.No - Content Management System Ez Publish (Open Source CMS)
How to Create eZ Publish Forms / Articles / Developer / ez.no - Content Management System eZ Publish (Open Source CMS) How to Create eZ Publish Forms Paul Wilson Friday 14 December 2007 10:35:00 pm This article is part of the eZ Publish “How to” series and provides a step-by-step guide to creating a custom form for an eZ Publish website. To integrate with other examples in this series, this article focuses on the creation of a membership application form for the “eZ Tennis Club” website. The procedures in this article apply to eZ Publish 3.10.0 with the Website Interface, although the overall principles should also apply to other versions of eZ Publish with and without the Website Interface. We assume that you are familiar with or have a basic understanding of the following three concepts, which we explored in the previous two articles in this series: the layout of the Administration Interface; the configuration system and INI settings files; and the template system. The first article in this series - How to Configure an eZ Publish Site - explained how to set up the site for the fictional eZ Tennis Club. The second article in this series - How to Use eZ Publish Extensions: Google Analytics - gave you some practical experience on installing and configuring an extension. Objects and information collection There are two methods in eZ Publish to collect and process information from site visitors: Information collection: creating forms using objects with attributes marked as information collectors This method uses the “information collection” features of eZ Publish. The most obvious example of this is the contact form (see below) present in a standard Website Interface installation. -

John Champaign 8-453 Albert St
John Champaign 8-453 Albert St. Waterloo, ON N2L 5A7 519-954-4218 [email protected] http://www.cs.uwaterloo.ca/~jchampai/ EDUCATION: Doctor of Philosophy, Computer Science University of Waterloo 2008-Present . Thesis: “Peer-Based Educational Tutoring Systems: A Corpus-Oriented Approach” . Supervised by Robin Cohen . Member of the Artificial Intelligence group . 2nd stage exam completed April 21st, 2010 . Research focused on User Modeling and Intelligent Tutoring Systems . Courses on Human-Computer Interaction (CS 889), Preference Elicitation (CS 886), Medical Image Processing (CS 870), and Bayesian Data Analysis (CS 886) . Computer Science Graduate Student Association Treasurer (Sept 2009 to Present) . Volunteered for activities such as Ontario Universities Fair, Fall Open House and new graduate student orientation. Masters of Mathematics, Computer Science University of Waterloo 2002-2004 . Thesis: “An Empirical Study of Software Packaging Stability” . Supervised by Andrew Malton . Member of the Software Architecture Group (SWAG) . Courses in Artificial Intelligence (CS 686), Component-Based Design (CS 854), Intelligent Computer Interfaces (CS 785), and Software Evolution (CS 846) Bachelor’s of Science in Computer Science Queen’s University 1995-2000 . Honours degree . Undergraduate thesis supervised by David Lamb . TA for “Software Abstraction and Specification” PRESENTATIONS: . Paper or poster presentations at each venue listed under publications . Presentations for NSERC Strategic Research Network hSITE (Healthcare Support through Information Technology Enhancements): September 2009 (Toronto), June 2010 (Montreal) (poster) . Presented results for feedback during Masters work at Consortium for Software Engineering Research (CSER) at the University of Victoria (2003). Lectured, based on Masters thesis, for two undergraduate classes that were discussing relevant material at the University of Waterloo. -

Frameworks PHP
Livre blanc ___________________________ Frameworks PHP Nicolas Richeton – Consultant Version 1.0 Pour plus d’information : www.smile.fr Tél : 01 41 40 11 00 Mailto : [email protected] Page 2 les frameworks PHP PREAMBULE Smile Fondée en 1991, Smile est une société d’ingénieurs experts dans la mise en œuvre de solutions Internet et intranet. Smile compte 150 collaborateurs. Le métier de Smile couvre trois grands domaines : ! La conception et la réalisation de sites Internet haut de gamme. Smile a construit quelques uns des plus grands sites du paysage web français, avec des références telles que Cadremploi ou Explorimmo. ! Les applicatifs Intranet, qui utilisent les technologies du web pour répondre à des besoins métier. Ces applications s’appuient sur des bases de données de grande dimension, et incluent plusieurs centaines de pages de transactions. Elles requièrent une approche très industrielle du développement. ! La mise en œuvre et l’intégration de solutions prêtes à l’emploi, dans les domaines de la gestion de contenus, des portails, du commerce électronique, du CRM et du décisionnel. www.smile.fr © Copyright Smile - Motoristes Internet – 2007 – Toute reproduction interdite sans autorisation Page 3 les frameworks PHP Quelques références de Smile Intranets - Extranets - Société Générale - Caisse d'Épargne - Bureau Veritas - Commissariat à l'Energie Atomique - Visual - Vega Finance - Camif - Lynxial - RATP - AMEC-SPIE - Sonacotra - Faceo - CNRS - AmecSpie - Château de Versailles - Banque PSA Finance - Groupe Moniteur - CIDJ - CIRAD - Bureau -

What Is Ez Publish?
eZ Publish Enterprise Tour Discover eZ Publish Enterprise solutions and services Version 4.4 - September 28th 2010 Table Of Content What is eZ Publish?................................................................................. 5 Introduction........................................................................................5 Why use eZ Publish ?........................................................................... 6 The eZ ecosystem is not just features and software !...............................7 eZ Publish Enterprise model..................................................................8 Content Management with eZ Publish .................................................... 9 Functional overview of eZ Publish.........................................................10 Flexible content engine................................................................... 10 The Administration Interface............................................................12 The Administration Interface's Dashboard..........................................13 Unsurpassed user experience in Content Management.........................13 Online Editor................................................................................. 14 Online Image editor........................................................................16 Front End editing............................................................................17 Search capabilities..........................................................................17 Auto-completing and suggesting search -

Escalabilidade E Performance De Aplicações
E S C O L A S U P E R I O R D E T E C N O L O G I A E G E S T Ã O D E S I G N A Ç Ã O D O M E S T R A D O A U T O R O R I E N T A D O R ( E S ) A N O w w w . e s t g f . i p p . p t AGRADECIMENTOS Gostaria de agradecer á ESTGF por me ter proporcionado as condições necessárias para efectuar a dissertação, numa área pela qual tenho um gosto especial, gostava também de agradecer a todas as pessoas do Centro de Informática, aos meus colegas do CIICESI e um agradecimento especial ao Professor João Paulo Magalhães, ao Professor Doutor Ricardo Costa e á Professora Doutora Dorabela Gamboa por terem possibilitado a elaboração da presente tese. RESUMO A performance das aplicações Web é um tópico extremamente importante. Estudos indicam que 37% a 49% dos utilizadores que sofrem de problemas de performance abandonam o site ou mudam para sites da concorrência. Destes, 77% partilham a sua experiência com outros prejudicando ainda mais a reputação da empresa. Para além do impacto na reputação há o impacto financeiro. Por exemplo um relatório tornado público recentemente indica que 100 milisegundos de perda de latência no acesso á Amazon contribui para uma quebra de 1% nas vendas. Considerando o papel das aplicações Web para o negócio das empresas, é vital adoptar um conjunto de boas práticas ao nível da programação e ao nível da infra-estrutura de forma a garantir um bom desempenho da aplicação e consequentemente a satisfação dos utilizadores. -

Programas Incluidos En El DVD DVD-Programación 2013-10
O 0 c 1 t - u 3 DVD-Programación 2013-10 b 1 r 0 e 2 Programas incluidos en el DVD d n e ó i (continuación) Eclipse PDT Helios SR2 - Elgg 1.8.16 - Erlang R16B02 - Etherpad Lite 1.2.11 - Euphoria 2 c 3.1.1 - eZ Publish Community 2013.07 - Feng Office 2.3.2.1 - FileZilla Server 0.9.41 - Firebird 2.5.2.26540 - 0 a 1 3 m Firebug 1.12.3 - FlameRobin 0.9.3 2013.10.03 - Free Pascal 2.6.2 - FreeBasic 0.90.1 - FreeDOS 1.1 Full CD a r - Gazpacho 0.7.2 - Geany 1.23 - gedit 2.30.1 - Git 1.8.4 - Glade 3.14.0 - GNAT Programming Studio 2013 - g GnuWin32 Indent 2.2.10 - GTK+ 2.14.7 - Guido van Robot 4.4 - gVim 7.4 - HM NIS Edit 2.0.3 - IE Tab 2.0 o r 2012.03.12 - Inno Setup 5.5.2 - Inno Setup Tool 5.3.0.1 - InstallJammer 1.2.15 - Instant Rails 2.0 - IzPack P - 4.3.5 - Java Runtime Environment 7 update 40 - jEdit 5.1.0 - Jelix Developer Edition 1.5.3 - Joomla! 2.5.11 - D Joomla! 3.1.5 - Komodo Edit 8.5.1 - Kompozer 0.8.b3 - Lazarus 1.0.12 - lightTPD 1.4.32.1 - LinkChecker 8.2 V D - MantisBT 1.2.15 - MariaDB 5.5.30 - MediaWiki 1.21.2 - Mercurial 2.7.2 - Minimum Profit 5.2.6 - MongoDB 2.4.6 - Mono 3.2.3 - monotone 1.0 - Moodle 2.5.2 - MS Windows Installer 4.5 - MySql 5.6.14 - MySQL WorkBench OSS 6.0.7 - NetBeans Java EE IDE 7.3.1 - nginx 1.5.6 - Notepad++ 6.5 - NSIS 2.46 - NumPy 1.7.1 (py 2.7) - NumPy 1.7.1 (py 3.3) - Open Watcom Fortran 1.9 - OpenLaszlo 4.9.0 - Parrot 5.7.0 - PECL 5.2.6 - pgAdmin3 1.18.0 - PHP 5.4.20 VC9 - PHP 5.5.4 VC11 - PHP-Fusion 7.02.07 - phpMyAdmin 4.0.8 - phpMyBackupPro 2.1 Castellano - phpMyBackupPro 2.4 - PIL 1.1.7 (py 2.7) - -

Livre Blanc : PHP En Entreprise
> Pourquoi ce livre blanc ? Les éditeurs de logiciels commerciaux disposent d’une force de frappe marketing et commerciale très importante qui leur permet d’informer, objectivement ou pas, leurs clients et prospects ainsi que la presse. A l’inverse, les outils Open Source tels que PHP ne disposent pas des structures nécessaires pour faire valoir leurs intérêts auprès des entreprises et de la presse spécialisée. Bien que concurrents dans leur activité quotidienne, des membres de l’AFUP, des experts PHP, .NET et J2EE se sont réunis pour compenser ce manque d’information et offrir aux entreprises et aux journalistes une synthèse de qualité sur PHP. Ont participé à la version 3 du livre blanc : Anaska Services, NeXenServices, No Parking, WaterProof SoftWare, MySQL, Mandriva Linux Ont participé à la version 1 et 2 du livre blanc : Anaska Services, Nexen Services, WaterProof Software, Clever Age, Globalis media systems, SaphirTech, Mandriva, ionCube. Publié sous licence Open Content, ce document peut être copié et diffusé autant de fois que vous le désirez. > Sommaire 1. Fiche d’identité de PHP 2 2. PHP en chiffres 3 3. Les atouts de PHP pour l’entreprise 5 4. Architecture technique 7 5. Une plate-forme qui s’ouvre aux problématiques d’intégration 9 6. PHP, J2EE et .NET : plus complémentaires que concurrents 11 7. L’écosystème PHP 13 8. Ce qu’en pensent les entreprises 15 1/18 > 1. Fiche d’identité de PHP PHP (PHP : Hypertext Preprocessor) est à la fois un langage de programmation (comme Java ou C#) et une plate-forme globale d’entreprise (comme J2EE et .NET). -

Ez Publish Website Interface User Guide Table of Contents 1.Introduction
eZ Publish Website Interface User Guide version 1.0 eZ Publish Website Interface User Guide Table of Contents 1.Introduction.......................................................................................................................4 1.1.About eZ Publish and eZ Publish Now......................................................................4 1.2.Target audience.........................................................................................................4 1.3.Conventions..............................................................................................................5 1.4.More resources.........................................................................................................5 1.5.Contacting eZ............................................................................................................5 1.6.Copyright and trademarks.........................................................................................6 2.Interface overview............................................................................................................7 2.1.The Website Interface ..............................................................................................7 2.2.The Administration Interface......................................................................................7 3.Managing user accounts..................................................................................................8 3.1.Creating a user account............................................................................................8