Towards Big Active Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lightweight Django USING REST, WEBSOCKETS & BACKBONE
Lightweight Django USING REST, WEBSOCKETS & BACKBONE Julia Elman & Mark Lavin Lightweight Django LightweightDjango How can you take advantage of the Django framework to integrate complex “A great resource for client-side interactions and real-time features into your web applications? going beyond traditional Through a series of rapid application development projects, this hands-on book shows experienced Django developers how to include REST APIs, apps and learning how WebSockets, and client-side MVC frameworks such as Backbone.js into Django can power the new or existing projects. backend of single-page Learn how to make the most of Django’s decoupled design by choosing web applications.” the components you need to build the lightweight applications you want. —Aymeric Augustin Once you finish this book, you’ll know how to build single-page applications Django core developer, CTO, oscaro.com that respond to interactions in real time. If you’re familiar with Python and JavaScript, you’re good to go. “Such a good idea—I think this will lower the barrier ■ Learn a lightweight approach for starting a new Django project of entry for developers ■ Break reusable applications into smaller services that even more… the more communicate with one another I read, the more excited ■ Create a static, rapid prototyping site as a scaffold for websites and applications I am!” —Barbara Shaurette ■ Build a REST API with django-rest-framework Python Developer, Cox Media Group ■ Learn how to use Django with the Backbone.js MVC framework ■ Create a single-page web application on top of your REST API Lightweight ■ Integrate real-time features with WebSockets and the Tornado networking library ■ Use the book’s code-driven examples in your own projects Julia Elman, a frontend developer and tech education advocate, started learning Django in 2008 while working at World Online. -

Cherrypy Documentation Release 8.5.1.Dev0+Ng3a7e7f2.D20170208
CherryPy Documentation Release 8.5.1.dev0+ng3a7e7f2.d20170208 CherryPy Team February 08, 2017 Contents 1 Foreword 1 1.1 Why CherryPy?.............................................1 1.2 Success Stories..............................................2 2 Installation 5 2.1 Requirements...............................................5 2.2 Supported python version........................................5 2.3 Installing.................................................5 2.4 Run it...................................................6 3 Tutorials 9 3.1 Tutorial 1: A basic web application...................................9 3.2 Tutorial 2: Different URLs lead to different functions.......................... 10 3.3 Tutorial 3: My URLs have parameters.................................. 11 3.4 Tutorial 4: Submit this form....................................... 12 3.5 Tutorial 5: Track my end-user’s activity................................. 12 3.6 Tutorial 6: What about my javascripts, CSS and images?........................ 13 3.7 Tutorial 7: Give us a REST....................................... 15 3.8 Tutorial 8: Make it smoother with Ajax................................. 17 3.9 Tutorial 9: Data is all my life...................................... 19 3.10 Tutorial 10: Make it a modern single-page application with React.js.................. 22 3.11 Tutorial 11: Organize my code...................................... 25 4 Basics 27 4.1 The one-minute application example.................................. 28 4.2 Hosting one or more applications................................... -

Indigenous Language Revitalization in Montana: Perspectives from Four Nations
University of Montana ScholarWorks at University of Montana Graduate Student Theses, Dissertations, & Professional Papers Graduate School 2003 Indigenous language revitalization in Montana: Perspectives from four nations Mary Groom-Hall The University of Montana Follow this and additional works at: https://scholarworks.umt.edu/etd Let us know how access to this document benefits ou.y Recommended Citation Groom-Hall, Mary, "Indigenous language revitalization in Montana: Perspectives from four nations" (2003). Graduate Student Theses, Dissertations, & Professional Papers. 9458. https://scholarworks.umt.edu/etd/9458 This Dissertation is brought to you for free and open access by the Graduate School at ScholarWorks at University of Montana. It has been accepted for inclusion in Graduate Student Theses, Dissertations, & Professional Papers by an authorized administrator of ScholarWorks at University of Montana. For more information, please contact [email protected]. Maureen and Mike MANSFIELD LIBRARY The University o f MONTANA Permission is granted by the author to reproduce this material in its entirety, provided that tin's material is used for scholarly purposes and is properly cited in published works and reports. ** Please check "Yes" or "No" and provide signature ** Yes, I grant permission ^ No, I do not grant permission _____ Author's Signature Date S)2-V o3> Any copying for commercial purposes or financial gain may be undertaken only with the author's explicit consent. Reproduced with permission of the copyright owner. Further reproduction prohibited without permission. Reproduced with permission of the copyright owner. Further reproduction prohibited without permission. INDIGENOUS LANGUAGE REVITALIZATION IN MONTANA PERSPECTIVES FROM FOUR NATIONS Mary Groom Hall B.A. -

Download Slide (PDF Document)
When Django is too bloated Specialized Web-Applications with Werkzeug EuroPython 2017 – Rimini, Italy Niklas Meinzer @NiklasMM Gotthard Base Tunnel Photographer: Patrick Neumann Python is amazing for web developers! ● Bottle ● BlueBream ● CherryPy ● CubicWeb ● Grok ● Nagare ● Pyjs ● Pylons ● TACTIC ● Tornado ● TurboGears ● web2py ● Webware ● Zope 2 Why would I want to use less? ● Learn how stuff works Why would I want to use less? ● Avoid over-engineering – Wastes time and resources – Makes updates harder – It’s a security risk. Why would I want to use less? ● You want to do something very specific ● Plan, manage and document chemotherapy treatments ● Built with modern web technology ● Used by hospitals in three European countries Patient Data Lab Data HL7 REST Pharmacy System Database Printers Werkzeug = German for “tool” ● Developed by pocoo team @ pocoo.org – Flask, Sphinx, Jinja2 ● A “WSGI utility” ● Very lightweight ● No ORM, No templating engine, etc ● The basis of Flask and others Werkzeug Features Overview ● WSGI – WSGI 1.0 compatible, WSGI Helpers ● Wrapping of requests and responses ● HTTP Utilities – Header processing, form data parsing, cookies ● Unicode support ● URL routing system ● Testing tools – Testclient, Environment builder ● Interactive Debugger in the Browser A simple Application A simple Application URL Routing Middlewares ● Separate parts of the Application as wsgi apps ● Combine as needed Request Static files DB Part of Application conn with DB access User Dispatcher auth Part of Application without DB access Response HTTP Utilities ● Work with HTTP dates ● Read and dump cookies ● Parse form data Using the test client Using the test client - pytest fixtures Using the test client - pytest fixtures Interactive debugger in the Browser Endless possibilities ● Connect to a database with SQLalchemy ● Use Jinja2 to render documents ● Use Celery to schedule asynchronous tasks ● Talk to 3rd party APIs with requests ● Make syscalls ● Remote control a robot to perform tasks at home Thank you! @NiklasMM NiklasMM Photographer: Patrick Neumann. -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -
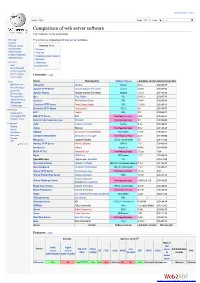
Comparison of Web Server Software from Wikipedia, the Free Encyclopedia
Create account Log in Article Talk Read Edit ViewM ohrisetory Search Comparison of web server software From Wikipedia, the free encyclopedia Main page This article is a comparison of web server software. Contents Featured content Contents [hide] Current events 1 Overview Random article 2 Features Donate to Wikipedia 3 Operating system support Wikimedia Shop 4 See also Interaction 5 References Help 6 External links About Wikipedia Community portal Recent changes Overview [edit] Contact page Tools Server Developed by Software license Last stable version Latest release date What links here AOLserver NaviSoft Mozilla 4.5.2 2012-09-19 Related changes Apache HTTP Server Apache Software Foundation Apache 2.4.10 2014-07-21 Upload file Special pages Apache Tomcat Apache Software Foundation Apache 7.0.53 2014-03-30 Permanent link Boa Paul Phillips GPL 0.94.13 2002-07-30 Page information Caudium The Caudium Group GPL 1.4.18 2012-02-24 Wikidata item Cite this page Cherokee HTTP Server Álvaro López Ortega GPL 1.2.103 2013-04-21 Hiawatha HTTP Server Hugo Leisink GPLv2 9.6 2014-06-01 Print/export Create a book HFS Rejetto GPL 2.2f 2009-02-17 Download as PDF IBM HTTP Server IBM Non-free proprietary 8.5.5 2013-06-14 Printable version Internet Information Services Microsoft Non-free proprietary 8.5 2013-09-09 Languages Jetty Eclipse Foundation Apache 9.1.4 2014-04-01 Čeština Jexus Bing Liu Non-free proprietary 5.5.2 2014-04-27 Galego Nederlands lighttpd Jan Kneschke (Incremental) BSD variant 1.4.35 2014-03-12 Português LiteSpeed Web Server LiteSpeed Technologies Non-free proprietary 4.2.3 2013-05-22 Русский Mongoose Cesanta Software GPLv2 / commercial 5.5 2014-10-28 中文 Edit links Monkey HTTP Server Monkey Software LGPLv2 1.5.1 2014-06-10 NaviServer Various Mozilla 1.1 4.99.6 2014-06-29 NCSA HTTPd Robert McCool Non-free proprietary 1.5.2a 1996 Nginx NGINX, Inc. -

Django-Tornado-Websockets Documentation Release 0.2.2 Hugo ALLIAUME
Django-tornado-websockets Documentation Release 0.2.2 Hugo ALLIAUME Nov 17, 2017 Contents 1 Architecture 3 2 Documentation 5 2.1 Installation................................................5 2.1.1 Automatic installation.....................................5 2.1.2 Manual installation.......................................5 2.2 Django integration and configuration..................................5 2.2.1 Integration............................................6 2.2.2 Configuration..........................................6 2.3 Usage...................................................7 2.3.1 Run Tornado server.......................................8 2.3.2 Using WebSockets (server side)................................8 2.3.3 Using WebSockets (client side)................................. 10 2.4 Modules................................................. 12 2.4.1 Module............................................. 12 2.4.2 Progress bar........................................... 12 2.5 API.................................................... 14 2.5.1 WebSocket........................................... 14 2.5.2 WebSocketHandler....................................... 15 2.5.3 TornadoWrapper........................................ 15 Python Module Index 17 i ii Django-tornado-websockets Documentation, Release 0.2.2 Django-tornado-websockets is a useful solution to provide an easy way to use Tornado WebSockets with a Django application. Important: Django-tornado-websockets is actually in alpha version! Contents 1 Django-tornado-websockets Documentation, -

Cherrypy Documentation Release 3.2.4
CherryPy Documentation Release 3.2.4 CherryPy Team Jun 30, 2017 Contents 1 Foreword 1 1.1 Why CherryPy?.............................................1 1.2 Success Stories..............................................2 2 Installation 5 2.1 Requirements...............................................5 2.2 Supported python version........................................6 2.3 Installing.................................................6 2.4 Run it...................................................6 3 Tutorials 9 3.1 Tutorial 1: A basic web application................................... 10 3.2 Tutorial 2: Different URLs lead to different functions.......................... 10 3.3 Tutorial 3: My URLs have parameters.................................. 11 3.4 Tutorial 4: Submit this form....................................... 12 3.5 Tutorial 5: Track my end-user’s activity................................. 13 3.6 Tutorial 6: What about my javascripts, CSS and images?........................ 14 3.7 Tutorial 7: Give us a REST....................................... 15 3.8 Tutorial 8: Make it smoother with Ajax................................. 17 3.9 Tutorial 9: Data is all my life...................................... 19 3.10 Tutorial 10: Organize my code...................................... 22 4 Basics 23 4.1 The one-minute application example.................................. 24 4.2 Hosting one or more applications.................................... 25 4.3 Logging.................................................. 26 4.4 Configuring............................................... -

Disaster & Emergency Management
UAS APPLICATIONS: DISASTER & EMERGENCY MANAGEMENT Babak Ameri, David Meger, Keith Power GEOSYS Technology Solutions Ltd. Suite 1638, 1177 West Hastings, Vancouver, BC, Canada [email protected] , [email protected], [email protected] Dr. Yang Gao Department of Geomatics Engineering, The University of Calgary, Calgary, AB, Canada [email protected] ABSTRACT Decision makers in emergency management agencies must be able to access large volumes of highly current geospatial information to effectively respond to disaster situations and ensure strong collaboration between agencies. Current photogrammetric solutions using manned aircraft for data acquisition and post-mission processing are limited in their ability to meet these requirements. The use of Unmanned Aerial System (UAS) technology during acquisition, combined with state-of-the-art techniques for automated data processing and delivery, promise the ability to meet the requirements of decision makers. This paper discusses a number of innovative components that form such a system: a modular image acquisition payload equipped with radio communications suitable for UAS missions, two strategies for accurate estimation of camera poses, a fully automated and real-time ortho-mosaic production system, and a collaborative web-based interface to distribute map information. This system will radically advance emergency response capabilities and help to save human lives by providing information and intelligence to disaster managers in a safe, timely, and critical manner. INTRODUCTION When a disaster threatens lives and livelihoods, emergency responders require large volumes of information about the situation in order to inform their decision making. This information must be delivered into the hands of decision makers at the speed of the disaster and with sufficient accuracy to enable correct analysis of the situation. -

Analytical and Other Software on the Secure Research Environment
Analytical and other software on the Secure Research Environment The Research Environment runs with the operating system: Microsoft Windows Server 2016 DataCenter edition. The environment is based on the Microsoft Data Science virtual machine template and includes the following software: • R Version 4.0.2 (2020-06-22), as part of Microsoft R Open • R Studio Desktop 1.3.1093 working with R 4.0.2 • Anaconda 3, including an environment for Python 3.8.5 • Python, 3.8.5 as part of the Anaconda base environment • Jupyter Notebook, as part of the Anaconda3 environment • Microsoft Office 2016 Standard edition, including Word, Excel, PowerPoint, and OneNote (Access not included) • JuliaPro 0.5.1.1 and the Juno IDE for Julia • PyCharm Community Edition, 2020.3 • PLINK • JAGS • WinBUGS • OpenBUGS • stan and rstan • Apache Spark 2.2.0 • SparkML and pySpark • Apache Drill 1.11.0 • MAPR Drill driver • VIM 8.0.606 • TensorFlow • MXNet, MXNet Model Server • Microsoft Cognitive Toolkit (CNTK) • Weka • Vowpal Wabbit • xgboost • Team Data Science Process (TDSP) Utilities • VOTT (Visual Object Tagging Tool) 1.6.11 • Microsoft Machine Learning Server • PowerBI • Docker version 10.03.5, build 2ee0c57608 • SQL Server Developer Edition (2017), including Management Studio and SQL Server Integration Services (SSIS) • Visual Studio Code 1.17.1 • Nodejs • 7-zip • Evince PDF Viewer • Acrobat Reader • Microsoft Photo Viewer • PowerShell 6 March 2021 Version 1.2 And in the Premium research environments: • STATA 16.1 • SAS 9.4, m4 (academic license) Users also have the ability to bring in additional software if the software was specified in the data request, the software runs in the operating system described above, and the user can provide Vivli with any necessary licensing keys. -

Codestance Python Tornado Web Server with Websockets – Part I
11/3/2014 Python Tornado Web Server With WebSockets – Part I - Codestance Codestance PHP, Linux and Marketing Playground Home Articles Resources Tips Tutorials 2013 Middax | Rainbow Newsletter Me gusta 28 Tw eet 37 34 September 7, 2013 16 Comments Python Tornado Web Server With WebSockets – Part I Today i will show you and give you some input how to make a web and websocket server with Tornado, which is currently my favorite when i need “mockup” service so i can show it to someone. Anyway this article will mostly cover websockets then “standard” web. Tornado is a scalable, non-blocking web server and web application framework written in Python. It was developed for use by FriendFeed; the company was acquired by Facebook in 2009 and Tornado was open-sourced soon after. For installing Tornado on our machine we need Python first, anyhow, Python is installed on most Linux distros possibly because most Gnome and KDE apps using Python 2.5+ interpreters. For installing Python on Windows machine you can check it out here. After we have Python in place we should continue installing Tornado with easy_install tornado command which will install latest stable version. For running easy_install from Windows command prompt you can google a bit because this is covered on a lot of blogs. Also, i’m using Eclipse for Python development but you can use whatever you like. Now let’s get to the real, simple example. Let’s create a file called server.py : import tornado.ioloop import tornado.web from tornado.options import define, options, parse_command_line define("port", -

The Jumpgate Definitive Guide
THE JUMPGATE DEFINITIVE GUIDE Compiled by: Odiche Special Thanks to: NETDEVIL© NewDawn IkeProf RazorKiss Lady Dracoe SpaceDrake Zalty’s And all the Pilots I have forgotten to thank! FACTIONS Solrain: Medium-fast ships, heavy, fast-recharging shields. A little light on firepower, lots of flexibility in ship loadout because of a large number of MODx slots. (MODx are worth reading up on in JOSSH). All Solrain ships have buckets of cargo space... the Solrain Fighter-class ship, the Intensity can carry a full set of equipment in it's hold to re-equip a downed squadmate. The Solrain Bomber and Medium Fighter are top-of-the-line, and they have a good Light Transport as well. Solrain ships are fairly forgiving for a new pilot; the glut of Flashfire MODxes they can equip can ensure their survival in situations where any other ship would be gunned down before it could escape. Solrain ships often utilize hit and run techniques in combat to gain the maximum advantage from their fast-recharging shields. Solrain ships can generally re-equip to a fairly good degree from their home stations. Solrain are typically RPed (Roleplayed) as greedy, profiteering traders. Which they are. Assassins, Mercenaries, Pirates, Traders, or Factionalists. To piss off a Solrain pilot, call him a Smurf. Quantar: Usually have the fastest ships in a given class. They also have a medium load- out of MODx slots. Quantar ships rely on maneuvrability to evade incoming fire; the Quantar fighters, the Typhoon, is an ideal wolf-pack ship. Their speed can carry them out of most trouble; only scouts or an Intensity can really catch them up, and if you are a skilled pilot, you can evade and escape from those also.