C Compiler for the VERSAT Reconfigurable Processor Thesis To
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Versa 8051 Mcus TB102 – Using Versa 8051 Include Files Rev 1.0
Versa 8051 MCUs TB102 – Using Versa 8051 Include Files Rev 1.0 How to Use Include Files for Versa 8051 MCUs 1 Introduction For compilers/assemblers that do not allow long file names, the naming convention is as follows: This technical bulletin addresses the include files developed for each of Ramtron’s fast and flexible AAFFDDDD.EXT Versa 8051 microcontrollers. Include files contain code AA: The initials of the compiler or assembler, such as for the MCU’s special function registers (SFRs). This ML for the MetaLink Cross Assembler. code is compatible with most popular 8051 compilers and assemblers. FF: The family of the target device: RS for the Versa 8051 family. 2 Supported Compilers DDDD: The first digit grouping of the device name, for Currently, include files exist for the following 8051 example the VRS51L2070 will use 2070. compilers and assemblers: EXT: The extension for the target programming language, such as .H for the C language, or .inc for an • MetaLink Macro Assembler assembler. • RIDE 51 (RKit) MA51 Macro Assembler • RIDE 51 (RKit) RC51 C Compiler 3.2 Location and Installation • Keil µVision3 A51 Macro Assembler All the files are placed in a zipped folder labeled with • Keil µVision3 C51 C Compiler the device name (for example, VRS51L3074.ZIP). • SDCC (Small Device C Compiler) When downloaded, the necessary file(s) can be moved • ASX8051 cross assembler to two possible locations: If you are using a different compiler, apply one of the • The compiler/assembler source directory provided files as a template or contact Ramtron for • The folder of the current project assistance. -

Operating System Components for an Embedded Linux System
INSTITUTEFORREAL-TIMECOMPUTERSYSTEMS TECHNISCHEUNIVERSITATM¨ UNCHEN¨ PROFESSOR G. F ARBER¨ Operating System Components for an Embedded Linux System Martin Hintermann Studienarbeit ii Operating System Components for an Embedded Linux System Studienarbeit Executed at the Institute for Real-Time Computer Systems Technische Universitat¨ Munchen¨ Prof. Dr.-Ing. Georg Farber¨ Advisor: Prof.Dr.rer.nat.habil. Thomas Braunl¨ Author: Martin Hintermann Kirchberg 34 82069 Hohenschaftlarn¨ Submitted in February 2007 iii Acknowledgements At first, i would like to thank my supervisor Prof. Dr. Thomas Braunl¨ for giving me the opportunity to take part at a really interesting project. Many thanks to Thomas Sommer, my project partner, for his contribution to our good work. I also want to thank also Bernard Blackham for his assistance by email and phone at any time. In my opinion, it was a great cooperation of all persons taking part in this project. Abstract Embedded systems can be found in more and more devices. Linux as a free operating system is also becoming more and more important in embedded applications. Linux even replaces other operating systems in certain areas (e.g. mobile phones). This thesis deals with the employment of Linux in embedded systems. Various architectures of embedded systems are introduced and the characteristics of common operating systems for these devices are reviewed. The architecture of Linux is examined by looking at the particular components such as kernel, standard C libraries and POSIX tools for embedded systems. Furthermore, there is a survey of real-time extensions for the Linux kernel. The thesis also treats software development for embedded Linux ranging from the prerequi- sites for compiling software to the debugging of binaries. -

Anatomy of Cross-Compilation Toolchains
Embedded Linux Conference Europe 2016 Anatomy of cross-compilation toolchains Thomas Petazzoni free electrons [email protected] Artwork and Photography by Jason Freeny free electrons - Embedded Linux, kernel, drivers - Development, consulting, training and support. http://free-electrons.com 1/1 Thomas Petazzoni I CTO and Embedded Linux engineer at Free Electrons I Embedded Linux specialists. I Development, consulting and training. I http://free-electrons.com I Contributions I Kernel support for the Marvell Armada ARM SoCs from Marvell I Major contributor to Buildroot, an open-source, simple and fast embedded Linux build system I Living in Toulouse, south west of France Drawing from Frank Tizzoni, at Kernel Recipes 2016 free electrons - Embedded Linux, kernel, drivers - Development, consulting, training and support. http://free-electrons.com 2/1 Disclaimer I I am not a toolchain developer. Not pretending to know everything about toolchains. I Experience gained from building simple toolchains in the context of Buildroot I Purpose of the talk is to give an introduction, not in-depth information. I Focused on simple gcc-based toolchains, and for a number of examples, on ARM specific details. I Will not cover advanced use cases, such as LTO, GRAPHITE optimizations, etc. I Will not cover LLVM free electrons - Embedded Linux, kernel, drivers - Development, consulting, training and support. http://free-electrons.com 3/1 What is a cross-compiling toolchain? I A set of tools that allows to build source code into binary code for -

Remote-Controlled Ambidextrous Robot Hand Actuated by Pneumatic Muscles: from Feasibility Study to Design and Control Algorithms
Remote-Controlled Ambidextrous Robot Hand Actuated by Pneumatic Muscles: from Feasibility Study to Design and Control Algorithms A thesis submitted for the Degree of Doctor of Philosophy By Emre Akyürek Department of Electronic and Computer Engineering School of Engineering and Design Brunel University June 2015 Declaration of Authorship I, Emre Akyürek, certify that the work introduced in this thesis entitled “Remote- Controlled Ambidextrous Robot Hand Actuated by Pneumatic Muscles: from Feasibility Study to Design and Control” is my own. I confirm that: -This work was entirely achieved while in candidature for a Doctor of Philosophy degree at Brunel University. -The works done by my colleagues or achieved as teamwork are clearly defined and specified. -The articles I have consulted for my research are referenced. Signed: Date: 10/06/2015 i To my ex-brothers in arms Kim-Hwa Khoo, Michaël Rouart and Daniel Truong By the sides of whom I fought these evil monsters called exams and assignments. To those by the sides of whom I bled and suffered, Learning the true meanings of distress and agony. To those who were always at my side To heal my wounds and to repair my weapons, Teaching me the true meanings of friendship and solidarity. To my dear friends Kim-Hwa, Michaël and Daniel, Who were my only family on the battlefield. To my ex-brothers in arms, By the sides of whom I have become the warrior I am. ii Abstract This thesis relates to the development of the Ambidextrous Robot Hand engineered in Brunel University. Assigned to a robotic hand, the ambidextrous feature means that two different behaviours are accessible from a single robot hand, because of its fingers architecture which permits them to bend in both ways. -

C for a Tiny System Implementing C for a Tiny System and Making the Architecture More Suitable for C
Abstract We have implemented support for Padauk microcontrollers, tiny 8-Bit devices with 60 B to 256 B of RAM, in the Small Device C Compiler (SDCC), showing that the use of (mostly) standard C to program such minimal devices is feasible. We report on our experience and on the difficulties in supporting the hardware multithreading present on some of these devices. To make the devices a better target for C, we propose various enhancements of the architecture, and empirically evaluated their impact on code size. arXiv:2010.04633v1 [cs.PL] 9 Oct 2020 1 C for a tiny system Implementing C for a tiny system and making the architecture more suitable for C Philipp Klaus Krause, Nicolas Lesser October 12, 2020 1 The architecture Padauk microcontrollers use a Harvard architecture with an OTP or Flash pro- gram memory and an 8 bit wide RAM data memory. There also is a third address space for input / output registers. These three memories are accessed using separate instructions. Figure 1 shows the 4 architecture variants, which are commonly called pdk13, pdk14, pdk15 and pdk16 (these names are different from the internal names found in files from the manufacturer-provided IDE) by the width of their program memory. Each instruction is exactly one word in program memory. Most instructions execute in a single cycle, the few excep- tions take 2 cycles. Most instructions use either implicit addressing or direct addressing; the latter usually use the accumulator and one memory operand and write their result into the accumulator or memory. On the pdk13, pdk14 and pdk15, the bit set, reset and test instructions, which use direct addressing, can only access the lower half of the data address space. -

Embedded Linux Size Reduction Techniques
Embedded Linux Conference 2017 Embedded Linux size reduction techniques Michael Opdenacker free electrons [email protected] free electrons - Embedded Linux, kernel, drivers - Development, consulting, training and support. http://free-electrons.com 1/1 Michael Opdenacker I Michael Opdenacker I Founder and Embedded Linux engineer at free electrons I Embedded Linux expertise I Development, consulting and training I Strong open-source focus I Long time interest in embedded Linux boot time, and one of its prerequisites: small system size. I From Orange, France Penguin from Justin Ternet (https://openclipart.org/detail/182875/pinguin) free electrons - Embedded Linux, kernel, drivers - Development, consulting, training and support. http://free-electrons.com 2/1 Why reduce size? There are multiple reasons for having a small kernel and system I Run on very small systems (IoT) I Run Linux as a bootloader I Boot faster (for example on FPGAs) I Reduce power consumption Even conceivable to run the whole system in CPU internal RAM or cache (DRAM is power hungry and needs refreshing) I Security: reduce the attack surface I Cloud workloads: optimize instances for size and boot time. I Spare as much RAM as possible for applications and maximizing performance. See https://tiny.wiki.kernel.org/use_cases free electrons - Embedded Linux, kernel, drivers - Development, consulting, training and support. http://free-electrons.com 3/1 Reasons for this talk I No talk about size since ELCE 2015 I Some projects stalled (Linux tinification, LLVM Linux...) I Opportunity to have a look at solutions I didn’t try: musl library, Toybox, gcc LTO, new gcc versions, compiling with Clang.. -

La Diffusione Del Software Open-Source Nei Sistemi Embedded
Matteo Vellere - La Diffusione del software Open-Source nei Sistemi Embedded Università degli studi di Padova Dipartimento di Tecnica e Gestione dei Sistemi Industriali Corso di Laurea Triennale in Ingegneria Meccanica e Meccatronica LA DIFFUSIONE DEL SOFTWARE OPEN-SOURCE NEI SISTEMI EMBEDDED THE SPREAD OF OPEN-SOURCE SOFTWARE IN EMBEDDED SYSTEMS RELATORE: CH.MO PROF. Reggiani Monica LAUREANDO: Vellere Matteo ANNO ACCADEMICO: 2013/2014 Pag. 1 Matteo Vellere - La Diffusione del software Open-Source nei Sistemi Embedded Pag. 2 Matteo Vellere - La Diffusione del software Open-Source nei Sistemi Embedded INDICE GENERALE INTRODUZIONE.......................................................................................................................4 1.I Sistemi Embedded.................................................................................................................6 1.1.Generalità sui Sistemi Embedded.....................................................................................6 1.2.Evoluzione storica dei dispositivi.....................................................................................8 1.3.Caratteristiche.................................................................................................................10 1.3.1.Microcontrollori e Microprocessori........................................................................10 1.3.2.Field Programmable Gate Array (FPGA)...............................................................11 1.3.3.Digital Signal Processors (DSP).............................................................................11 -

Abkürzungs-Liste ABKLEX
Abkürzungs-Liste ABKLEX (Informatik, Telekommunikation) W. Alex 1. Juli 2021 Karlsruhe Copyright W. Alex, Karlsruhe, 1994 – 2018. Die Liste darf unentgeltlich benutzt und weitergegeben werden. The list may be used or copied free of any charge. Original Point of Distribution: http://www.abklex.de/abklex/ An authorized Czechian version is published on: http://www.sochorek.cz/archiv/slovniky/abklex.htm Author’s Email address: [email protected] 2 Kapitel 1 Abkürzungen Gehen wir von 30 Zeichen aus, aus denen Abkürzungen gebildet werden, und nehmen wir eine größte Länge von 5 Zeichen an, so lassen sich 25.137.930 verschiedene Abkür- zungen bilden (Kombinationen mit Wiederholung und Berücksichtigung der Reihenfol- ge). Es folgt eine Auswahl von rund 16000 Abkürzungen aus den Bereichen Informatik und Telekommunikation. Die Abkürzungen werden hier durchgehend groß geschrieben, Akzente, Bindestriche und dergleichen wurden weggelassen. Einige Abkürzungen sind geschützte Namen; diese sind nicht gekennzeichnet. Die Liste beschreibt nur den Ge- brauch, sie legt nicht eine Definition fest. 100GE 100 GBit/s Ethernet 16CIF 16 times Common Intermediate Format (Picture Format) 16QAM 16-state Quadrature Amplitude Modulation 1GFC 1 Gigabaud Fiber Channel (2, 4, 8, 10, 20GFC) 1GL 1st Generation Language (Maschinencode) 1TBS One True Brace Style (C) 1TR6 (ISDN-Protokoll D-Kanal, national) 247 24/7: 24 hours per day, 7 days per week 2D 2-dimensional 2FA Zwei-Faktor-Authentifizierung 2GL 2nd Generation Language (Assembler) 2L8 Too Late (Slang) 2MS Strukturierte -
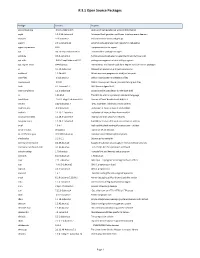
R 3.1 Open Source Packages
R 3.1 Open Source Packages Package Version Purpose accountsservice 0.6.15-2ubuntu9.3 query and manipulate user account information acpid 1:2.0.10-1ubuntu3 Advanced Configuration and Power Interface event daemon adduser 3.113ubuntu2 add and remove users and groups apport 2.0.1-0ubuntu12 automatically generate crash reports for debugging apport-symptoms 0.16 symptom scripts for apport apt 0.8.16~exp12ubuntu10.27 commandline package manager aptitude 0.6.6-1ubuntu1 Terminal-based package manager (terminal interface only) apt-utils 0.8.16~exp12ubuntu10.27 package managment related utility programs apt-xapian-index 0.44ubuntu5 maintenance and search tools for a Xapian index of Debian packages at 3.1.13-1ubuntu1 Delayed job execution and batch processing authbind 1.2.0build3 Allows non-root programs to bind() to low ports base-files 6.5ubuntu6.2 Debian base system miscellaneous files base-passwd 3.5.24 Debian base system master password and group files bash 4.2-2ubuntu2.6 GNU Bourne Again Shell bash-completion 1:1.3-1ubuntu8 programmable completion for the bash shell bc 1.06.95-2 The GNU bc arbitrary precision calculator language bind9-host 1:9.8.1.dfsg.P1-4ubuntu0.16 Version of 'host' bundled with BIND 9.X binutils 2.22-6ubuntu1.4 GNU assembler, linker and binary utilities bsdmainutils 8.2.3ubuntu1 collection of more utilities from FreeBSD bsdutils 1:2.20.1-1ubuntu3 collection of more utilities from FreeBSD busybox-initramfs 1:1.18.5-1ubuntu4 Standalone shell setup for initramfs busybox-static 1:1.18.5-1ubuntu4 Standalone rescue shell with tons of built-in utilities bzip2 1.0.6-1 High-quality block-sorting file compressor - utilities ca-certificates 20111211 Common CA certificates ca-certificates-java 20110912ubuntu6 Common CA certificates (JKS keystore) checkpolicy 2.1.0-1.1 SELinux policy compiler command-not-found 0.2.46ubuntu6 Suggest installation of packages in interactive bash sessions command-not-found-data 0.2.46ubuntu6 Set of data files for command-not-found. -

SECUMOBI SERVER Technical Description
SECUMOBI SERVER Technical Description Contents SIP Server 3 Media Relay 10 Dimensioning of the Hardware 18 SIP server 18 Media Proxy 18 Page 2 of 18 SIP Server Operatingsystem: Debian https://www.debian.org/ Application: openSIPS http://www.opensips.org/ OpenSIPS is built and installed from source code. The operating system is installed with the following packages: Package Description acpi displays information on ACPI devices acpi-support-base scripts for handling base ACPI events such as the power button acpid Advanced Configuration and Power Interface event daemon adduser add and remove users and groups anthy-common input method for Japanese - common files and dictionary apt Advanced front-end for dpkg apt -utils APT utility programs aptitude terminal-based package manager (terminal interface only) autopoint The autopoint program from GNU gettext backup -manager command -line backup tool base-files Debian base system miscellaneous files base-passwd Debian base system master password and group files bash The GNU Bourne Again SHell bc The GNU bc arbitrary precision calculator language binutils The GNU assembler, linker and binary utilities bison A parser generator that is compatible with YACC bsdmainutils collection of more utilities from FreeBSD bsdutils Basic utilities from 4.4BSD-Lite build -essential Informational list of build -essential packages busybox Tiny utilities for small and embedded systems bzip2 high-quality block-sorting file compressor - utilities ca-certificates Common CA certificates console-setup console font and keymap -

Leiden University Computer Science
Leiden University Computer science Constructing an open-source toolchain and investigating sensor properties for radio tomography Name: Tim van der Meij Student number: 1115731 Date: June 22, 2014 1st supervisor: Walter Kosters (LIACS) 2nd supervisor: Joost Batenburg (CWI & MI) BACHELOR THESIS Leiden Institute of Advanced Computer Science (LIACS) Leiden University Niels Bohrweg 1 2333 CA Leiden The Netherlands Abstract In this bachelor thesis, we present an open-source toolchain for radio tomographic imaging (RTI) using radio signals with approximately the same frequencies as WiFi signals, as well as practical guidelines for setting up an effective sensor network. RTI is a technique for wirelessly detecting or tracking objects or persons in a sensor network using radio signals. It is an inverse problem whereby measurements need to be converted to information about objects or persons in the network. After discussing how to set up the wireless sensor network, we will go into detail on how the toolchain has been constructed and which experiments have been performed to determine the network setup guidelines. Measurements obtained from the sensor network allow us to make a reconstruction image of the network using imaging algorithms. One of the results of our research is that the shape of the network appears to have a large impact on the effectiveness of the sensor network. Keywords: radio tomographic imaging, sensor network, toolchain, wireless, WiFi 2 Contents 1 Introduction4 1.1 Motivation and applications..........................4 1.2 Research -

Software Infrastructure and Tools for the TRIPS Prototype
Software Infrastructure and Tools for the TRIPS Prototype Bill Yoder Jim Burrill Robert McDonald Kevin Bush KatherineCoons MarkGebhart SibiGovindan BertrandMaher Ramadas Nagarajan Behnam Robatmili Karthikeyan Sankaralingam SadiaSharif AaronSmith DougBurger StephenW.Keckler KathrynS.McKinley Computer Architecture and Technology Laboratory Department of Computer Sciences The University of Texas at Austin [email protected] - www.cs.utexas.edu/users/cart/trips ABSTRACT between the motherboard and chips. A key theme of software development has been to adapt The TRIPS hardware prototype is the first instantiation of an Explicit off-the-shelf solutions when possible and to create homegrown Data Graph Execution (EDGE) architecture. Building the compiler, solutions when necessary. toolset, and system software for the prototype required supporting the The remainder of this paper is organized as follows. Sec- system’s unique dataflow construction, its banked register and memory tion 2 discusses the TRIPS language toolchain and the ap- configurations, and its novel Instruction Set Architecture. In particu- proach we used to implement a full-featured software devel- lar, the TRIPS ISA includes (i) a block atomic execution model, (ii) ex- opment kit. Section 3 discusses several of the TRIPS software plicit mappings of instructions to execution units, and (iii) predicated simulators, enabling us to prove out a number of design ideas instructions which may or may not fire, depending on the outcome during every stage of development. Section 4 discusses the of preceding instructions. Our primary goal has been to construct TRIPS operating environment, with its use of a host-based re- tools to consume standard C and Fortran source code and generate source manager to download, execute, and control TRIPS bi- binaries both for the TRIPS software simulators and hardware proto- naries on the target processors.