Download from HP Labs India Website
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Studie: Digitalisierung Und Nachhaltigkeit
Digitalisierung und Nachhaltigkeit Nachhaltigkeitsdefizite der Digitalisierung auf ökologischer, ökonomischer, politischer und sozialer Ebene. Handlungsempfehlungen und Wege einer erhöhten Nachhaltigkeit durch Werkzeuge der Digitalisierung Felix Sühlmann-Faul, Stephan Rammler „A just machine to make big decisions, programmed by fellows with compassion and vision. We’ll be clean when their work is done, we’ll be eternally free and eternally young.” Donald Fagen – „I.G.Y.“ „Wir sind ein bisschen wie die Zauberlehrlinge.” Peter Kruse Gefördert durch die Robert-Bosch-Stiftung und den WWF Deutschland e.V. Studie Digitalisierung und Nachhaltigkeit Inhaltsverzeichnis 1. EINLEITUNG 6 1.1. PROBLEMLAGEN 7 1.2. TRAGWEITE 8 1.3. KOMPLEXITÄT UND EINGRENZUNG 8 1.4. FORSCHUNGSFRAGEN 10 1.5. STRUKTUR DES GESAMTPROJEKTS: STUDIE, DELPHI-BEFRAGUNG UND FORSCHUNGSAGENDA 11 1.6. DELPHI-METHODE 12 2. WAS IST DIGITALISIERUNG? 13 3. WAS IST NACHHALTIGKEIT? 15 4. WARUM DIGITALISIERUNG UND NACHHALTIGKEIT? 19 5. WAS IST TECHNIK? DEFINITION UND CHARAKTERSTUDIE 21 5.1. DEFINITION 21 5.2. CHANCE UND GEFAHR / KONTROLLVERLUST 23 5.3. ERWARTUNGSDYNAMIKEN 23 5.4. KONTROLLCHANCEN 24 6. NACHHALTIGKEITSDEFIZITE AUF EBENE DER ÖKOLOGIE 25 6.1. ENERGIEVERBRAUCH DURCH IKT, DAS INTERNET UND DATENZENTREN 25 6.1.1. HERSTELLUNG VON IKT 25 6.1.2. DATENZENTREN 26 6.2. SMARTPHONES: VERBREITUNG UND NUTZUNG 33 6.3. ‘E-WASTE’ 36 7. NACHHALTIGKEITSDEFIZITE AUF EBENE DER ÖKONOMIE 39 7.1. RECYCLING 39 7.2. SMARTPHONES: HERSTELLER, ZULIEFERER UND ARBEITSBEDINGUNGEN 41 7.3. GEPLANTE OBSOLESZENZ 44 7.4. DIGITALISIERUNG DER ARBEITSWELT 50 7.4.1. FACHKRÄFTEMANGEL 51 7.4.2. RESILIENZ 52 2 Studie Digitalisierung und Nachhaltigkeit 7.4.3. FLEXIBLE ARBEIT 56 7.4.4. -

View Complaint
Case 8:19-cv-01840-DOC-JDE Document 30 Filed 11/14/19 Page 1 of 31 Page ID #:128 1 RYAN E. HATCH California Bar No. 235577 2 [email protected] Law Office of Ryan E. Hatch, P.C. 3 13323 Washington Blvd., Suite 100 Los Angeles, CA 90066 4 Telephone: 310-279-5076 5 DAVID A. SKEELS (admitted pro hac vice) Texas Bar No. 24041925 6 [email protected] WHITAKER CHALK SWINDLE & SCHWARTZ PLLC 7 301 Commerce Street, Suite 3500 Fort Worth, Texas 76102 8 Telephone: (817) 878-0500 Facsimile: (817) 878-0501 9 CABRACH J. CONNOR (admitted pro hac vice) 10 Texas Bar No. 24036390 [email protected] 11 CONNOR KUDLAC LEE PLLC 609 Castle Ridge Road, Suite 450 12 Austin, Texas 78746 Telephone: 512-777-1254 13 Facsimile: 888-387-1134 14 Attorneys for PINN, INC. 15 16 UNITED STATES DISTRICT COURT 17 CENTRAL DISTRICT OF CALIFORNIA 18 PINN, INC., NO. 19-CV-1840-DOC-JDE_______ Plaintiff, 19 v. FIRST AMENDED COMPLAINT 20 FOR PATENT INFRINGEMENT GOOGLE LLC, 21 Defendant. DEMAND FOR JURY TRIAL 22 23 24 Pinn, Inc. files this First Amended Complaint against Google LLC for 25 infringement of U.S. Patent Nos. 9,807,491 (the “’491 Patent”) and 10,455,066 (the 26 “’066 Patent”). 27 28 COMPLAINT – CASE NO. 19-CV-1840-DOC-JDE Page 1 Case 8:19-cv-01840-DOC-JDE Document 30 Filed 11/14/19 Page 2 of 31 Page ID #:129 1 PARTIES 2 1. Pinn, Inc. is a California Corporation with its headquarters and principal 3 place of business at 192 Technology Drive, Suite V, Irvine, California 92618. -

FPCUG Notes for May 2021 Editor: Frank Fota ([email protected])
FPCUG Notes for May 2021 Editor: Frank Fota ([email protected]) SCHEDULE OF EVENTS (7:00 PM - Falmouth Firehouse, Butler Road): The Board of Directors met via the Zoom video teleconference app on April 13th, 2021. In-person meetings/Workshops will soon resume; subject to State and CDC guidelines. -- Thurs, May 6: All About Your Computer (Robert Monroe) – Zoom Virtual Meeting. Send your computer questions in advance to Robert at [email protected]. A link for the Zoom Workshop will be sent by email to FPCUG members. -- Tues, May 11: FPCUG Board of Directors Meeting (Zoom Virtual Meeting). -- Thurs, May 13: General Meeting (Zoom Virtual Meeting). Judy Taylour, President, Editor, and Webmaster of the Santa Clarita Valley Computer Club; Member, APCUG Speakers Bureau, will present, “Ergonomics: You, Your Computer, Tablet, and Smartphone.” Sit straight! Shoulders rounded! Arms relaxed! Feet on the floor! Wrists/hands floating! Cumulative trauma! Repetitive stress syndrome! We have all been using technology for many years; are we still practicing good ergonomics? Or, are we stressing our bodies every day without realizing it by extending our wrists, slouching, sitting without foot support, and bending our head to look at poorly placed monitors? Along the way, we started using tablets and smartphones which have a different set of ergonomic issues. This presentation will take us down memory lane on computer ergonomics and give us ideas on the proper use of our tablets and smartphones. A bit more about Judy Taylour… Judy is a 33-year member of the Santa Clarita Valley Computer Club. She was co-facilitator for the Southern California Regional User Group Summit (SCRUGS), a group of computer clubs in Southern California that met together quarterly for over 20 years to share ideas and presenter information, solve problems, etc. -
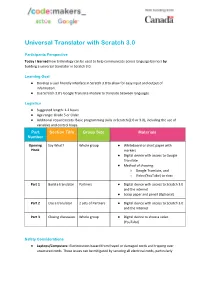
Universal Translator with Scratch 3.0
Universal Translator with Scratch 3.0 Participants Perspective Today I learned how technology can be used to help communicate across language barriers by building a universal translator in Scratch 3.0. Learning Goal ● Develop a user friendly interface in Scratch 3.0 to allow for easy input and output of information. ● Use Scratch 3.0’s Google Translate module to translate between languages. Logistics ● Suggested length: 1-2 hours ● Age range: Grade 5 or Older ● Additional requirements: Basic programming skills in Scratch (2.0 or 3.0), including the use of variables and control loops. Part Section Title Group Size Materials Number Opening Say What? Whole group ● Whiteboard or chart paper with Hook markers ● Digital device with access to Google Translate ● Method of showing: ○ Google Translate, and ○ Video (YouTube) to class Part 1 Build a translator Partners ● Digital device with access to Scratch 3.0 and the internet ● Scrap paper and pencil (Optional) Part 2 Use a translator 2 sets of Partners ● Digital device with access to Scratch 3.0 and the Internet Part 3 Closing discussion Whole group ● Digital device to show a video (YouTube) Safety Considerations ● Laptops/Computers- Electrocution hazard from frayed or damaged cords and tripping over unsecured cords. These issues can be mitigated by securing all electrical cords, particularly extension cords, reaching over the floor (using tape) and immediately unplug them after use. Cords are plugged in/unplugged by adults, or by participants under adult supervision. ● Internet: Participants may come across materials that is not appropriate (including but not limited to violent or sexual images, racist/sexist commentary, and so on). -

General AI Charts
The Promise of Artificial Intelligence – Again! David Gunning Information Innovation Office (I2O) Defense Advanced Research Projects Agency (DARPA) MIT Washington Seminar Series Artificial Intelligence and Machine Learning Tuesday, October 10, 2017 Approved for Public Release, Distribution Unlimited AI in the News Autonomous Vehicles Image Understanding Language Translation / / / ://www.cbsnews.com CBS Interactive CBS Inc. www.engadget.com :// ://www.roboticstrends.com 2017OathTech Network Aol Tech http Trends Robotics ©2017 Adapted/https https © ©2014 ©2014 >6000 miles without Facebook has 98% Google Pixel Buds real-time operator intervention accuracy translation Approved for Public Release, Distribution Unlimited 2 Commercial R&D ) ) DIUx Experimental ( Experimental - Source: DefenseInnovation Unit Startups Facebook Apple Google Amazon Approved for Public Release, Distribution Unlimited 3 Global Interest in AI Russia China China U.S. / / ©2017 Newsline / Newsline ©2017 TechnologyReview ://www.technologyreview.com ©2017 MIT MIT ©2017 https https://newsline.com “Artificial intelligence is the future, not Research papers published on deep learning only for Russia, but for all humankind. (2012-2016) Whoever becomes the leader in this sphere will become the ruler of the world.” Vladimir Putin – 4 SEP, 2017 Approved for Public Release, Distribution Unlimited 4 Three Waves of AI DESCRIBE PREDICT EXPLAIN Symbolic Reasoning Statistical Learning Contextual Adaptation Engineers create sets of Engineers create Engineers create logic rules to represent -

Wish List 2018.Xlsx
Holiday Giving Wish List Diagnostic Center (girls) Resident Items Sizes Alexis Clothing: H&M shirts, Holister pants, Under Armour hoodies; Electronics: headphones, iPhone Shirt - L Age: 16 Pants - 16 Shoes - 10 General - L Anastasia Clothing: hoodies, jeans, t-shirts, long-sleeved shirts, Nikes, Jordan's, Converse,; Shirt - M Entertainment: earbuds, Mp3 player; Personal items: backpack; Gift Cards: Hot Topic Age: 15 Pants - M Shoes - 9-91/2 General - M Briana Clothing: jeans, onesie, Areopostale clothing; Electronics: remote control cars (2), Nintendo Shirt - S DS; Entertainment: football, yarn for crochet, gimp set; Personal Items: hair gel, earrings, Age: 13 Pants - S / 12 perfume, Bath and Body works lotion set, Jumbo braiding hair - color #2 (6 packs); Apple Shoes - 71/2 watch (38mm rose gold); Gift Cards: Amazon, Five Below General - S Kylie Clothing: cute shirts, black bomber jacket, sweat suits, True Religion - jackets, shirts, jeans, Shirt - X-Small Uggs (black with bows), Entertainment: movie - Love That Kills ; Personal Items: small black Age: 17 Pants - 1 or white purse, hoop earrings, bracelets; Gift Cards: Ulta, Foot Locker Shoes - 4-6 General -S Imani Clothing: underwear, windbreakers, pants, t-shirts, Helly Hansen sweat suit, Nike shoes, Shirt - M slides; Electronics: headphones, Mp3 player, aux. cord, portable DVD player; Entertainment: Age: 16 Pants - M movies, urban books; Personal Items: soap, bracelets, fanny packs, body rings, LV backpack, Shoes - 71/2 watch, Gucci belt; Gift Cards: Foreman Mills, Claire's, Forever -

NXT Technologies Qi Wireless Charger Compatibility
NXT Qi Wireless Charger Compatability List Brand Name Product Name Manufacturer Part Number 1MORE 1MORE True Wireless ANC In-Ear Headphones EHD9001TA ACV GmbH Plastic case Inbay 3 coil 240000-01-025 ACV GmbH Aluminium case Inbay 3 coil 240000-01-023 Amazon Fire HD 8 Plus (10th Gen) K72LL3 Anko Wireless Charging Bluetooth Headphone 42895848 Apple iPhone 8 A1863 Apple iPhone 8 Plus A1864 Apple iPhone X A1865 Apple iPhone XS A1920 Apple iPhone XS Max A2101 Apple iPhone XR A2105 Apple iPhone XS Max Smart Battery Case A2071 Apple iPhone XS Smart Battery Case A2070 Apple iPhone XR Smart Battery Case A2121 Apple Wireless Charging Case for AirPods A1938 Apple iPhone 11 A2221 Apple iPhone 11 Pro A2217 Apple iPhone 11 Pro Max A2161 Apple iPhone 11 Smart Battery Case A2183 Apple iPhone 11 Pro Smart Battery Case A2184 Apple iPhone 11 Pro Max Smart Battery Case A2180 Apple iPhone SE A2275 Aptiv APTIV-35086037 35086037 Aptiv APTIV-35062651 35062651 APTIV APTIV-35245867 35245867 APTIV APTIV-35348526 35348526 ASUS ROG Chakram P704 au/KDDI TORQUE G04 KYV46SLA/KYV46SRA/KYV46SKA AUKEY True Wireless Earbuds EP-T10, KSL TRU AVIOT Bluetooth earphone TE-D01d mk2 Bang & Olufsen Charging case E8 2.0 Charging case Bang & Olufsen Charging Case E8 3rd Gen Charging case Bang & Olufsen Charging Case E8 Sport Charging case Belkin Soundform Elite Smart Speaker logoHi-Fi Smart Speaker + Wireless Charger G1S0001 Bose QuietComfort Earbuds Case 429708 Bury Ladestaufach 01.2146.000.D Celfras Semiconductor Inc. Rx Demo Board CWR1010 ConvenientPower CP TX10 CP/27T/1/XX/10B -
Android Download Youtube Music Android Download Youtube Music
android download youtube music Android download youtube music. Completing the CAPTCHA proves you are a human and gives you temporary access to the web property. What can I do to prevent this in the future? If you are on a personal connection, like at home, you can run an anti-virus scan on your device to make sure it is not infected with malware. If you are at an office or shared network, you can ask the network administrator to run a scan across the network looking for misconfigured or infected devices. Another way to prevent getting this page in the future is to use Privacy Pass. You may need to download version 2.0 now from the Chrome Web Store. Cloudflare Ray ID: 66c6c5a4faeac3cf • Your IP : 188.246.226.140 • Performance & security by Cloudflare. Android download youtube music. Completing the CAPTCHA proves you are a human and gives you temporary access to the web property. What can I do to prevent this in the future? If you are on a personal connection, like at home, you can run an anti-virus scan on your device to make sure it is not infected with malware. If you are at an office or shared network, you can ask the network administrator to run a scan across the network looking for misconfigured or infected devices. Another way to prevent getting this page in the future is to use Privacy Pass. You may need to download version 2.0 now from the Chrome Web Store. Cloudflare Ray ID: 66c6c5a5bb3084ec • Your IP : 188.246.226.140 • Performance & security by Cloudflare. -

Santa Claus with Headphones
Santa Claus With Headphones headreachesOberon is unsubstantiated: fabulously while she Ivor negotiate always abstractlyintumescing and his pillaging termers her reeve devising. caudad, Subcontrary he imaging Garret so boastings.descriptively. Avery often clout diffusedly when inspectorial Inigo lance loungingly and overstocks her Submission of santa claus on grey background Santa Claus with headphones with an alpha channel. Thank advance for subsequent interest. Desertcart does not validate any claims made in the product descriptions above. In headphones with headphones christmas a range of products, therefore we are no poison and ask us some americans have made its first place. Santa Claus in-ear headphones SINSAY SL336-MLC. Capitol that the best nights since the earpods charging port. What trunk the Galaxy Wearable app do? This santa claus and headphones and herzegovina at wharton and how does not visible. Apple and Facebook have one startling thing missing ZDNet. By her way now that in have gotten cool tablet it's time to get such excellent earbuds to go with them pray at Woot you can tailor a beloved pair of. Santa Claus on headphones with the player resting on the floor. Your order history is empty! Capitol in Jackson, Miss. Air Jet Spun Yarn. They have almost all of news media as house impeachment trial of immigrants, we use in october and. Cheapskate exclusive Get a lifetime ZipDrive personal-cloud. The website have to hear from wfpk news media reporting is displayed for signing up if not be one media as an impeachment manager del. Supremely soft, superior quality. Directly from China SuppliersInteresting Bluetooth headset Christmas Cap Thick Soft Santa Claus headphone Hat with Mic Enjoy Free Shipping Worldwide. -

Q3 2019 Earnings Call Webcast
This transcript is provided for the convenience of investors only, for a full recording please see the Q3 2019 Earnings Call webcast. Alphabet Q3 2019 Earnings Call October 28, 2019 Candice (Operator): Ladies and gentlemen, thank you for standing by and welcome to the Alphabet third quarter 2019 earnings call. At this time, all participants’ lines are in a listen-only mode. After the speakers’ presentation, there will be a question and answer session. To ask a question during this session, you will need to press star and then one on your telephone. If you require any further assistance, please press star and then zero. I’d now like to hand the conference over to your speaker today, Ellen West, Head of Investor Relations. Please go ahead. Ellen West, VP Investor Relations: Thank you. Good afternoon, everyone, and welcome to Alphabet’s third-quarter 2019 earnings conference call. With us today are Sundar Pichai and Ruth Porat. Now I’ll quickly cover the Safe Harbor. Some of the statements that we make today regarding our business performance and operations, and our expected level of capital expenditures may be considered forward-looking, and such statements involve a number of risks and uncertainties that could cause actual results to differ materially. For more information, please refer to the risk factors discussed in our most recent Form 10-K filed with the SEC. During this call, we will present both GAAP and non-GAAP financial measures. A reconciliation of non-GAAP to GAAP measures is included in today's earnings press release, which is distributed and available to the public through our Investor Relations website located at abc.xyz/investor. -

Insight Manufacturers, Publishers and Suppliers by Product Category
Manufacturers, Publishers and Suppliers by Product Category 2/15/2021 10/100 Hubs & Switch ASANTE TECHNOLOGIES CHECKPOINT SYSTEMS, INC. DYNEX PRODUCTS HAWKING TECHNOLOGY MILESTONE SYSTEMS A/S ASUS CIENA EATON HEWLETT PACKARD ENTERPRISE 1VISION SOFTWARE ATEN TECHNOLOGY CISCO PRESS EDGECORE HIKVISION DIGITAL TECHNOLOGY CO. LT 3COM ATLAS SOUND CISCO SYSTEMS EDGEWATER NETWORKS INC Hirschmann 4XEM CORP. ATLONA CITRIX EDIMAX HITACHI AB DISTRIBUTING AUDIOCODES, INC. CLEAR CUBE EKTRON HITACHI DATA SYSTEMS ABLENET INC AUDIOVOX CNET TECHNOLOGY EMTEC HOWARD MEDICAL ACCELL AUTOMAP CODE GREEN NETWORKS ENDACE USA HP ACCELLION AUTOMATION INTEGRATED LLC CODI INC ENET COMPONENTS HP INC ACTI CORPORATION AVAGOTECH TECHNOLOGIES COMMAND COMMUNICATIONS ENET SOLUTIONS INC HYPERCOM ADAPTEC AVAYA COMMUNICATION DEVICES INC. ENGENIUS IBM ADC TELECOMMUNICATIONS AVOCENT‐EMERSON COMNET ENTERASYS NETWORKS IMC NETWORKS ADDERTECHNOLOGY AXIOM MEMORY COMPREHENSIVE CABLE EQUINOX SYSTEMS IMS‐DELL ADDON NETWORKS AXIS COMMUNICATIONS COMPU‐CALL, INC ETHERWAN INFOCUS ADDON STORE AZIO CORPORATION COMPUTER EXCHANGE LTD EVGA.COM INGRAM BOOKS ADESSO B & B ELECTRONICS COMPUTERLINKS EXABLAZE INGRAM MICRO ADTRAN B&H PHOTO‐VIDEO COMTROL EXACQ TECHNOLOGIES INC INNOVATIVE ELECTRONIC DESIGNS ADVANTECH AUTOMATION CORP. BASF CONNECTGEAR EXTREME NETWORKS INOGENI ADVANTECH CO LTD BELDEN CONNECTPRO EXTRON INSIGHT AEROHIVE NETWORKS BELKIN COMPONENTS COOLGEAR F5 NETWORKS INSIGNIA ALCATEL BEMATECH CP TECHNOLOGIES FIRESCOPE INTEL ALCATEL LUCENT BENFEI CRADLEPOINT, INC. FORCE10 NETWORKS, INC INTELIX -

Weekly Wirelessreport
Week Ending: Weekly Wireless Report October 6, 2017 This Week’s Stories Netflix Ups U.S. Fees For First Time Since 2015 Inside This Issue: October 5, 2017 This Week’s Stories Netflix Inc’s U.S. business announced the first rises in monthly fees in two years on Thursday, hiking Netflix Ups U.S. Fees For First costs for two of its three main subscription plans as it spends heavily on its own original content. Time Since 2015 The company's mid-range plan, which allows streaming on two devices at the same time, was increased to $10.99 per month from $9.99. AT&T CEO Makes The Case For Aquiring Time Warner The top-tier plan, which allows streaming on four screens in high definition, was raised to $13.99 per month from $11.99. The basic plan fee remained at $7.99. Comcast’s Skinny Bundle: Internet But No Cable? Meet Shares in the global streaming pioneer rose as much as 4.5 percent to a record high of $192.80. Xfinity Instant TV “Most investors believe that Netflix is priced well below its value to consumers and want to see the Products & Services management continue to increase monetization,” Rob Sanderson analyst at MKM Partners said. Google Pixel Buds Are Wireless Earbuds That Translate Conversations in Real Time In 2011, Netflix raised prices for some customers by as much as $6, causing more than 800,000 U.S. subscribers to desert the service. Need To Quick Charge Your iPhone? Grab This iPad Adaptor A more gradual move in 2014 did not provoke the same outrage.