A Sustainable Quantitative Stock Selection Strategy Based on Dynamic Factor Adjustment
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2021 Mid-Year Outlook July 2021 Economic Recovery, Updated Vaccine, and Portfolio Considerations
2021 Mid-Year Outlook July 2021 Economic recovery, updated vaccine, and portfolio considerations. Key Observations • Financial market returns year-to-date coincide closely with the premise of an expanding global economic recovery. Economic momentum and a robust earnings backdrop have fostered uniformly positive global equity returns while this same strength has been the impetus for elevated interest rates, hampering fixed income returns. • Our baseline expectation anticipates that the continuation of the economic revival is well underway but its relative strength may be shifting overseas, particularly to the Eurozone, where amplifying vaccination efforts and the prospects for additional stimulus reign. • Our case for thoughtful risk-taking remains intact. While the historically sharp and compressed pace of the recovery has spawned exceptionally strong returns across many segments of the capital markets and elevated valuations, the economic expansion should continue apace, fueled by still highly accommodative stimulus, reopening impetus and broader vaccination. Financial Market Conditions Economic Growth Forecasts for global economic growth in 2021 and 2022 remain robust with the World Bank projecting a 5.6 percent growth rate for 2021 and a 4.3 percent rate in 2022. If achieved, this recovery pace would be the most rapid recovery from crisis in some 80 years and provides a full reckoning of the extraordinary levels of stimulus applied to the recovery and of the herculean efforts to develop and distribute vaccines. GDP Growth Rates Source: FactSet Advisory services offered through Veracity Capital, LLC, a registered investment advisor. 1 While the case for further global economic growth remains compelling, we are mindful that near-term base effect comparisons and a bifurcated pattern of growth may be masking some complexities of the recovery. -

Relative Strength Index for Developing Effective Trading Strategies in Constructing Optimal Portfolio
International Journal of Applied Engineering Research ISSN 0973-4562 Volume 12, Number 19 (2017) pp. 8926-8936 © Research India Publications. http://www.ripublication.com Relative Strength Index for Developing Effective Trading Strategies in Constructing Optimal Portfolio Dr. Bhargavi. R Associate Professor, School of Computer Science and Software Engineering, VIT University, Chennai, Vandaloor Kelambakkam Road, Chennai, Tamilnadu, India. Orcid Id: 0000-0001-8319-6851 Dr. Srinivas Gumparthi Professor, SSN School of Management, Old Mahabalipuram Road, Kalavakkam, Chennai, Tamilnadu, India. Orcid Id: 0000-0003-0428-2765 Anith.R Student, SSN School of Management, Old Mahabalipuram Road, Kalavakkam, Chennai, Tamilnadu, India. Abstract Keywords: RSI, Trading, Strategies innovation policy, innovative capacity, innovation strategy, competitive Today’s investors’ dilemma is choosing the right stock for advantage, road transport enterprise, benchmarking. investment at right time. There are many technical analysis tools which help choose investors pick the right stock, of which RSI is one of the tools in understand whether stocks are INTRODUCTION overpriced or under priced. Despite its popularity and powerfulness, RSI has been very rarely used by Indian Relative Strength Index investors. One of the important reasons for it is lack of Investment in stock market is common scenario for making knowledge regarding how to use it. So, it is essential to show, capital gains. One of the major concerns of today’s investors how RSI can be used effectively to select shares and hence is regarding choosing the right securities for investment, construct portfolio. Also, it is essential to check the because selection of inappropriate securities may lead to effectiveness and validity of RSI in the context of Indian stock losses being suffered by the investor. -

W E B R E V Ie W
TRADERS´ TOOLS 37 Professional Screening, Advanced Charting, and Precise Sector Analysis www.chartmill.com The website www.chartmill.com is a technical analysis (TA) website created by traders for traders. Its main features are charting applications, a stock screener and a sector analysis tool. Chartmill supports most of the classical technical analysis indicators along with some state-of-the-art indicators and concepts like Pocket Pivots, Effective Volume, Relative Strength and Anchored Volume Weighted Average Prices (VWAPs, MIDAS curves). First, we will discuss some of these concepts. After that, we will have a look at the screener and charting applications. Relative Strength different manner. This form of Strong Stocks flatten out again. “Strong stocks” Relative Strength is available in Relative Strength was used in The screener supports the filters the nicest steady trends WEBREVIEW different forms at chartmill.com. “Point and Figure Charting” by concept of “strong stocks”, in the market and does a terrific Two Relative Strength related Thomas Dorsey. which are stocks with a high job in mimicking IBD (Investor‘s indicators are available in the Relative Strength. But there is Business Daily) stock lists. charts and screener: Besides these two indicators, more. Not all stocks with a high there is also the Relative Strength Relative Strength ranking are also Effective Volume • Mansfield Relative Strength: Ranking Number. Here, each strong stocks. Relative Strength Effective Volume is an indicator This compares the stock gets assigned a number looks at the performance over that was introduced in the book performance of the stock to between zero and 100, indicating the past year. -

Point and Figure Relative Strength Signals
February 2016 Point and Figure Relative Strength Signals JOHN LEWIS / CMT, Dorsey, Wright & Associates Relative Strength, also known as momentum, has been proven to be one of the premier investment factors in use today. Numerous studies by both academics and investment ABOUT US professionals have demonstrated that winning securities continue to outperform. This phenomenon has been found Dorsey, Wright & Associates, a Nasdaq Company, is a in equity markets all over the globe as well as commodity registered investment advisory firm based in Richmond, markets and in asset allocation strategies. Momentum works Virginia. Since 1987, Dorsey Wright has been a leading well within and across markets. advisor to financial professionals on Wall Street and investment managers worldwide. Relative Strength strategies focus on purchasing securities that have already demonstrated the ability to outperform Dorsey Wright offers comprehensive investment research a broad market benchmark or the other securities in the and analysis through their Global Technical Research Platform investment universe. As a result, a momentum strategy and provides research, modeling and indexes that apply requires investors to purchase securities that have already Dorsey Wright’s expertise in Relative Strength to various appreciated quite a bit in price. financial products including exchange-traded funds, mutual funds, UITs, structured products, and separately managed There are many different ways to calculate and quantify accounts. Dorsey Wright’s expertise is technical analysis. The momentum. This is similar to a value strategy. There are Company uses Point and Figure Charting, Relative Strength many different metrics that can be used to determine a Analysis, and numerous other tools to analyze market data security’s value. -

Price Momentum Model Creat- Points at Institutionally Relevant John Brush Ed by Columbine Capital Services, Holding Periods
C OLUMBINE N EWSLETTER A PORTFOLIO M ANAGER’ S R ESOURCE SPECIAL EDITION—AUGUST 2001 From etary price momentum model creat- points at institutionally relevant John Brush ed by Columbine Capital Services, holding periods. Columbine Alpha's Inc. The Columbine Alpha price dominance comes from its exploita- Price Momentum momentum model has been in wide tion of some of the many complex- a Twenty Year use by institutions for more than ities of price momentum. Recent Research Effort twenty years, both as an overlay non-linear improvements to with fundamental measures, and as Columbine Alpha incorporating Summary and Overview a standalone idea-generating screen. adjustments for extreme absolute The evidence presented here sug- price changes and considerations of Even the most casual market watch - gests that price momentum is not a trading volume appear likely to add ers have observed anecdotal evi- generic ingredient. another 100 basis points to the dence of trend following in stock model's 1st decile active return. prices. Borrowing from the world of The Columbine Alpha approach physics, early analysts characterized is almost twice as powerful as the You will see in this paper that this behavior as stock price momen- best simple alternative and war- constructing a price momentum tum. Over the years, researchers and rants attention by any investment model involves compromises or practitioners have developed manager who cares about active tradeoffs driven by the fact that increasingly more sophisticated return. different past measurement peri- mathematical descriptions (models) ods produce different future of equity price momentum effects. Even simple price momentum return patterns. -
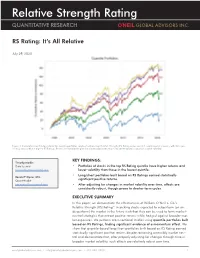
Relative Strength Rating QUANTITATIVE RESEARCH
Relative Strength Rating QUANTITATIVE RESEARCH RS Rating: It’s All Relative July 29, 2020 Figure 1: Cumulative monthly log returns for quantile portfolios constructed based on Relative Strength (RS) Rating across our U.S. equity market universe, with Q5 repre- senting stocks with the highest RS Ratings. Results are liquidity-weighted and normalized with respect to intertemporal changes in market volatility. KEY FINDINGS: Timothy Marble Data Scientist • Portfolios of stocks in the top RS Rating quintile have higher returns and [email protected] lower volatility than those in the lowest quintile. • Long/short portfolios built based on RS Ratings earned statistically Ronald P. Ognar, CFA Quant Analyst significant positive returns. [email protected] • After adjusting for changes in market volatility over time, effects are consistently robust, though prone to shorter-term cycles. EXECUTIVE SUMMARY In this paper, we demonstrate the effectiveness of William O’Neil + Co.’s Relative Strength (RS) Rating™ in picking stocks expected to outperform (or un- derperform) the market in the future such that they can be used to form market- neutral strategies that extract positive returns while hedged against broader mar- ket exposures. We perform cross-sectional studies using quantile portfolios built based on RS Ratings, finding significant evidence of a momentum effect. We show that quantile-based long/short portfolios built based on RS Rating earned statistically significant positive returns despite remaining ostensibly market neu- tral and demonstrate that, after properly adjusting for changes through time in broader market volatility, such effects are relatively robust over time. oneilglobaladvisors.com • [email protected] • 310.448.3800 1 Relative Strength Rating INTRODUCTION RELATIVE STRENGTH RATING™ (RS) William O’Neil + Co.’s proprietary Relative Strength Rating measures a stock’s relative price performance over the last 12 months against that of all stocks in our U.S. -

The Grand Finale: Choosing an Investment Philosophy
The Grand Finale: Choosing an Investment Philosophy! Aswath Damodaran Aswath Damodaran! 1! A Self Assessment! " To chose an investment philosophy, you first need to understand your own personal characteristics and financial characteristics, as well as as your beliefs about how markets work (or fail). " An investment philosophy that does not match your needs or your views about markets will ultimately fail. Aswath Damodaran! 2! Personal Characteristics! " Patience: Some investment strategies require a great deal of patience, a virtue that many of us lack. If impatient by nature, you should consider adopting an investment philosophy that provides payoffs in the short term. " Risk Aversion: If you are risk averse, adopting a strategy that entails a great deal of risk – trading on earnings announcements, for instance – will not be a strategy that works for you in the long term. " Individual or Group Thinker: Some investment strategies require you to go along with the crowd and some against it. Which one will be better suited for you may well depend upon whether you are more comfortable going along with the conventional wisdom or whether you are a loner. " Time you are willing to spend on investing: Some investment strategies are much more time and resource intensive than others. Generally, short-term strategies that are based upon pricing patterns or on trading on information are more time and information intensive than long-term buy and hold strategies. " Age: As you age, you may find that your willingness to take risk, especially with your retirement savings, decreases.. It is true, though, that even as a successful investor, you will have learnt lessons from prior investment experiences that will both constrain and guide your choice of philosophy. -

Relative Strength Index (RSI)
Understanding Technical Analysis : Relative Strength Index (RSI) Understanding Relative Strength Index Hi 74.57 Relative Strength Index (RSI) is a technical indicator that is categorised under Potential supply momentum indicator. Basically, all momentum indicators measures thedisruption rate dueof riseto and fall of the financial instrument's price. Usually, momentum attacksindicators on two oilare dependent indicators as they are best used with other indicators sincetankers they near do Iran not tell the traders or analysts the potential direction of the financial instrument. Among Brent the popular type of momentum indicators are Stochastic Indicator, Commodity Channel Index and Relative Strength Index. In this factsheet, we will explore the Relative Strength Index or better known as RSI. What is RSI? WTI Developed by J. Welles Wilder Jr. in his seminal 1978 book, "New Concepts in Technical Trading WTI Systems." Measures the speed and change of price movement of the financial instruments. As RSI is a type of oscillator, thisLo 2,237.40indicator is represented as a set of line that has(24 values Mar 2020) from 0 to 100. Generally, a reading below 30 indicatesLo 18,591.93 an oversold condition, while a value above (2470 Mar signals 2020) an overbought condition. Leading vs Lagging Indicator RSI is a leading type of indicator. A leading type of indicator is an indicator that can provide the traders or analyst with future price movement. Another example of leading indicator is Stochastic Indicator. In contrast, a lagging indicator is an indicator that follows the price movement of the financial instruments. Despite their lagging nature in providing trading signals, traders or analysts prefer to use lagging indicators as they are more reliable. -

Momentum Is Not an Anomaly
Momentum is Not an Anomaly Robert F. Dittmar, Gautam Kaul, and Qin Lei October 2007 Dittmar is at the Ross School of Business, University of Michigan (email: [email protected]). Kaul is at the Ross School of Business, University of Michigan (email: [email protected]). Lei is at the Cox School of Business, Southern Methodist University (email: [email protected]). We thank Jennifer Conrad, Rex Thompson, and seminar participants at Southern Methodist University for thoughtful comments. We retain the responsibility for all remaining errors. Abstract In this paper, we develop a new approach to test whether momentum is indeed an anomaly in that it re‡ects delayed reactions, or continued overreactions, to …rm speci…c news. Our methodology does not depend on a speci…c model of expected returns and, more importantly, does not require a decomposition of momentum pro…ts. Yet we provide distinct testable predictions that can discrim- inate between the two diametrically opposed causes for the pro…tability of momentum strategies: time-series continuation in the …rm-speci…c component of returns, and cross-sectional di¤erences in expected returns and systematic risks of individual securities. Our results show that, contrary to the common belief in the profession, momentum is not an anomaly; we …nd no evidence of continuation in the idiosyncratic component of individual-security returns. The evidence is instead consistent with momentum being driven entirely by cross-sectional di¤erences in expected returns and risks of individual securities. 1 Introduction The proposition that the idiosyncratic component of individual …rms’returns displays continuation now appears to be widely accepted among academics and practitioners. -

Relative Strength and Have a Good Probability of Outperforming the Market
Dorsey Wright Reference Manual About the Company Dorsey, Wright & Associates (DWA) is an independent and privately owned registered investment advisory firm founded in 1987 whose business includes two areas -- investment research services for numerous broker-dealers and large institutions around the world, and professional management of equity portfolios for investors. The two principals of the firm, Thomas J. Dorsey and Watson H. Wright, have extensive experience in the equity markets, particularly in the field of risk management. Combined, Mr. Dorsey and Mr. Wright have over 45 years of experience in the equity and options markets. Tom Dorsey is the author of Point & Figure Charting: The Essential Applications for Forecasting and Tracking Market Prices, Thriving As A Stockbroker in the 21st Century and Tom Dorsey’s Trading Tips: A Play Book for Stock Market Success. As well, the second edition of Point & Figure Charting was released in the summer of 2001. Point & Figure Charting has been translated into German, Polish, two dialects of Chinese, Hindu, and Japan has just purchased the rights for translation. Tom Dorsey and Tammy DeRosier, Vice President, also appear regularly on CNBC’s “Taking Stock” Program and Bloomberg TV. Dorsey, Wright analysts are featured on several national radio shows weekly too. Dorsey, Wright research is conducted along technical lines, adhering to the relationship between supply and demand. We believe this simple economic theory is manifested as a constant battle between these two forces for control of the equity vehicle. It is this objective, logical approach which helps reduce uncertainty in the market. The mainstay of the research at DWA is the Point & Figure methodology which was first popularized by Charles Dow in the late 1800’s. -

Diversified Momentum Rooted in Relative Strength Achieving Capital Appreciation While Preserving Capital Is a Balancing Task That Is Never Easy to Perform
Diversified Momentum Rooted in Relative Strength Achieving capital appreciation while preserving capital is a balancing task that is never easy to perform. Although it is not necessarily a predictor of future performance, technical analysis can help identify patterns that may in turn create profit opportunities. Joe Barrato, portfolio manager of the Arrow DWA Tactical Fund, employs proprietary models to find relative strength across equities, bonds and alternative assets for his diversified portfolio. Joseph Barrato What is the history of the fund and the company? CEO, Director of Investment Strategies Joseph Barrato, CEO and Director of The Arrow DWA Tactical Fund was launched in 2008, and uses a tactical global macro strategy, Investment Strategies, is a Founding technical analysis, and proprietary models focused on relative strength to achieve long-term capital Member of Arrow Investment Advisors, LLC, appreciation as well as capital preservation. the adviser to Arrow Funds and ArrowShares. Since co-founding Arrow in 2006, he has Our company was founded ten years ago, when we partnered with the technical research firm overseen the firm’s growth from a single fund Dorsey Wright & Associates (DWA) to launch this fund’s precursor, the Balanced Fund. That fund provider to a boutique asset manager offering was one of the first tactically managed funds to use a relative strength model, and had exposure a unique lineup of tactical and alternative investment mutual funds and exchange to multiple asset classes through a balance of equities and bonds. traded funds (ETFs). We wanted to evolve and create another product. Our initial thoughts focused on developing an Joe’s more than twenty years of financial investment strategy that could tilt anywhere without worrying about the balance between equities industry experience entails six years at and bonds. -

Be Financially Secure: Predicting Auto Stock Prices with Past Data
Be Financially Secure: Predicting Auto Stock Prices with Past Data Rutvik Parikh Massachusetts Academy of Math & Science at WPI [email protected] Table of Contents Abstract 1 Introduction 1 Methods and Materials 3 Moving Average 3 Relative Strength Index (RSI) 4 Money Flow Index (MFI) 4 Rate of Change Indicator (ROC) 5 Models 5 Results 6 Discussion 9 References 13 Parikh 1 1. Abstract Deciding which auto stocks to invest in can be overwhelming and frightening for many individuals due to the great amount of past data available, and the ambiguity of its effects on future outcomes. Therefore, the goal of this project is to develop a model for auto stock price prediction using technical analysis based on multiple indicators. First, a few quantitative indicators were chosen to assist with prediction. Next, computer algorithms were used to calculate numerical values of these indicators using stock price data. These values were then employed to predict whether the closing price of a particular auto stock would rise or fall in the short term; distinct subsets of these indicators were tested in an effort to obtain the strongest and most helpful model. These models were tested on stock price data from several major auto companies, including General Motors, Subaru, and Ford. This data was from 2013 to 2018. The accuracies of the models were spread out over a range of 42% to 69%. The most successful model relied on the rate of change indicator, suggesting that this indicator may have been the most applicable to the auto industry during the aforementioned years. The performance of the models shows that technical analysis effectively gauges the future behavior of auto stocks.