L2 Learners and the Intelligiblity of the Bostonian and Californian Accents
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

New England Phonology*
New England phonology* Naomi Nagy and Julie Roberts 1. Introduction The six states that make up New England (NE) are Vermont (VT), New Hampshire (NH), Maine (ME), Massachusetts (MA), Connecticut (CT), and Rhode Island (RI). Cases where speakers in these states exhibit differences from other American speakers and from each other will be discussed in this chapter. The major sources of phonological information regarding NE dialects are the Linguistic Atlas of New England (LANE) (Kurath 1939-43), and Kurath (1961), representing speech pat- terns from the fi rst half of the 20th century; and Labov, Ash and Boberg, (fc); Boberg (2001); Nagy, Roberts and Boberg (2000); Cassidy (1985) and Thomas (2001) describing more recent stages of the dialects. There is a split between eastern and western NE, and a north-south split within eastern NE. Eastern New England (ENE) comprises Maine (ME), New Hamp- shire (NH), eastern Massachusetts (MA), eastern Connecticut (CT) and Rhode Is- land (RI). Western New England (WNE) is made up of Vermont, and western MA and CT. The lines of division are illustrated in fi gure 1. Two major New England shibboleths are the “dropping” of post-vocalic r (as in [ka:] car and [ba:n] barn) and the low central vowel [a] in the BATH class, words like aunt and glass (Carver 1987: 21). It is not surprising that these two features are among the most famous dialect phenomena in the region, as both are characteristic of the “Boston accent,” and Boston, as we discuss below, is the major urban center of the area. However, neither pattern is found across all of New England, nor are they all there is to the well-known dialect group. -

Downloaded an Applet That Would Allow the Recordings to Be Collected Remotely
UC Berkeley UC Berkeley PhonLab Annual Report Title A Survey of English Vowel Spaces of Asian American Californians Permalink https://escholarship.org/uc/item/4w84m8k4 Journal UC Berkeley PhonLab Annual Report, 12(1) ISSN 2768-5047 Author Cheng, Andrew Publication Date 2016 DOI 10.5070/P7121040736 Peer reviewed eScholarship.org Powered by the California Digital Library University of California UC Berkeley Phonetics and Phonology Lab Annual Report (2016) A Survey of English Vowel Spaces of Asian American Californians Andrew Cheng∗ May 2016 Abstract A phonetic study of the vowel spaces of 535 young speakers of Californian English showed that participation in the California Vowel Shift, a sound change unique to the West Coast region of the United States, varied depending on the speaker's self- identified ethnicity. For example, the fronting of the pre-nasal hand vowel varied by ethnicity, with White speakers participating the most and Chinese and South Asian speakers participating less. In another example, Korean and South Asian speakers of Californian English had a more fronted foot vowel than the White speakers. Overall, the study confirms that CVS is present in almost all young speakers of Californian English, although the degree of participation for any individual speaker is variable on account of several interdependent social factors. 1 Introduction This is a study on the English spoken by Americans of Asian descent living in California. Specifically, it will look at differences in vowel qualities between English speakers of various ethnic -

Downeast New England and South Boston Dialects
Downeast New England and South Boston Dialects by Juraj Gašpar Geographical Location Geographical Location The Downeast dialect - coastal Maine - southern New Hampshire - working-class Boston north-shore - eastern Rhode Island The South Boston dialect - Boston The Downeast New England Dialect Signature sounds 1. In the lot and cloth lexical sets we hear [ɒ] or [ɑ]. [ɒ] is the older, more traditional vowel and is pronounced half-long [ɒˑ]. rotten, lost jobs, college, swan, waffle, knowledge, off, cough, froth, cross, soft, often, Australia, long, Communist 2. In the bath set we most commonly hear long [aː] bath, pass, card, chance, last, branch, demand, example, half-caste 3. In the nurse set we hear [ɜː], [ɝ] or [ɞ]. The non-rhotic versions are the older, more traditional sounds bird, curly, furniture, pernicious, certain, earth, herd, rehearsal, work, worst, sermon, turncoat 4. In the face set we hear [eː]. The vowel tends to be a single-stage vowel, monophthong rather than diphthong, close and tense in the vicinity of [e] tape, change, taper, april, gauge, weight, day, rain, great 5. In the thought set we hear a variety of sounds in the region, a not very lip-rounded [ɔ] and [ʌ], the best being [ɒə] with a slight offglide taught, odd, applaud, atom, gob, jaw, chalk, all, bald, hold, alter, fault, awful, naughty, broad, small 6. In the goat set we hear [o], a fairly pure single-stage vowel in the vicinity of [u] soap, road, hole, noble, bowl, soul, cult, role, sow, dough 7. In the price set we hear [ʌɪ], the prescriptive GenAm, and [eɪ] or [əɪ] – the most evocative of the traditional dialect mind, timely, bright-eyed, childlike, bicycle, tight, either, height, fight 8. -

Language Variation and Ethnicity in a Multicultural East London Secondary School
Language Variation and Ethnicity in a Multicultural East London Secondary School Shivonne Marie Gates Queen Mary, University of London April 2019 Abstract Multicultural London English (MLE) has been described as a new multiethnolect borne out of indirect language contact among ethnically-diverse adolescent friendship groups (Cheshire et al. 2011). Evidence of ethnic stratification was also found: for example, “non-Anglo” boys were more likely to use innovative MLE diphthong variants than other (male and female) participants. However, the data analysed by Cheshire and colleagues has limited ethnographic information and as such the role that ethnicity plays in language change and variation in London remains unclear. This is not dissimilar to other work on multiethnolects, which presents an orientation to a multiethnic identity as more salient than different ethnic identities (e.g. Freywald et al. 2011). This thesis therefore examines language variation in a different MLE-speaking adolescent community to shed light on the dynamics of ethnicity in a multicultural context. Data were gathered through a 12-month ethnography of a Year Ten (14-15 years old) cohort at Riverton, a multi-ethnic secondary school in Newham, East London, and include field notes and interviews with 27 students (19 girls, 8 boys). A full multivariate analysis of the face and price vowels alongside a quantitative description of individual linguistic repertoires sheds light on MLE’s status as the new London vernacular. Building on the findings of Cheshire et al. (2011), the present study suggests that language variation by ethnicity can have social meaning in multi-ethnic communities. There are apparent ethnolinguistic repertoires: ethnic minority boys use more advanced vowel realisations alongside high rates of DH-stopping, and the more innovative was/were levelling system. -

Variation in English /L
The University of Manchester Research Variation in English /l/ Link to publication record in Manchester Research Explorer Citation for published version (APA): Turton, D. (2014). Variation in English /l/: synchronic reections of the life cycle of phonological processes. University of Manchester. Citing this paper Please note that where the full-text provided on Manchester Research Explorer is the Author Accepted Manuscript or Proof version this may differ from the final Published version. If citing, it is advised that you check and use the publisher's definitive version. General rights Copyright and moral rights for the publications made accessible in the Research Explorer are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. Takedown policy If you believe that this document breaches copyright please refer to the University of Manchester’s Takedown Procedures [http://man.ac.uk/04Y6Bo] or contact [email protected] providing relevant details, so we can investigate your claim. Download date:08. Oct. 2021 Variation in English /l/: Synchronic reections of the life cycle of phonological processes A thesis submitted to The University of Manchester for the degree of Doctor of Philosophy in the Faculty of Humanities 2014 Danielle Turton School of Arts, Languages and Cultures Contents List of Figures 7 List of Tables 11 Abstract 15 Declaration 16 Copyright 17 Acknowledgements 18 1 Introduction 20 1.1 Goals of the thesis . 21 1.1.1 Theoretical issues . 21 1.1.2 Empirical issues . 22 1.1.3 Peripheral goals . -

Uptalk in Southern British English
See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/305684920 Uptalk in Southern British English Conference Paper · May 2016 DOI: 10.21437/SpeechProsody.2016-32 CITATION READS 1 332 2 authors, including: Amalia Arvaniti University of Kent 93 PUBLICATIONS 2,044 CITATIONS SEE PROFILE Some of the authors of this publication are also working on these related projects: Components of intonation and the structure of intonational meaning View project Modelling variability: gradience and categoriality in intonation View project All content following this page was uploaded by Amalia Arvaniti on 28 August 2016. The user has requested enhancement of the downloaded file. Speech Prosody 2016 31 May - 3 Jun 2106, Boston, USA Uptalk in Southern British English Amalia Arvaniti1, Madeleine Atkins1 1 University of Kent [email protected], [email protected] Abstract but with different melodies for each: L* L-H% is used primarily with statements, and H* H-H% and L* H-H% with questions The present study deals with the realization and function of [4]. New Zealand English also uses uptalk for both statements uptalk in Southern British English (SBE), a variety in which the and questions [3], with the tunes used for each function use of uptalk has been little investigated. Eight speakers (4 becoming increasingly distinct [5]. In Australian English, on the male, 4 female) were recorded while taking part in a Map Task other hand, uptalk is used with statements mostly when the and playing a board game. All speakers used uptalk for a variety speaker wishes to hold the floor [3]. -

The Real California1
THE REAL CALIFORNIA1 PENELOPE ECKERT AND NORMA MENDOZA-DENTON When most Americans think of California English, they might remember the stereotypes made famous by Frank and Moon Unit Zappa in their song "Valley Girl," circa 1982. "Like, totally! Gag me with a spoon! " intoned Moon Unit, instantly cementing a stereotype of California English as being primarily the province of Valley Girls and Surfer Dudes. But California is not just the land of beaches and blonds. While Hollywood images crowd our consciousness, the real California, with a population of nearly 34 million, is only 46.7% white (most of whom are not blond and most of whom don't live close to the beach or in the San Fernando Valley). California has for generations been home to a large Latino population Ð a population that today accounts for 32.4% of Californians. Also for generations it has been the home of a large Chinese-American and Japanese-American population and in recent years, with the influx of immigrants from other parts of Asia, it now boasts a large and diverse Asian American population (11.2%). Most of the sizeable African-American population (16.4%) in California speak some form of African-American Vernacular English, with few traces of surfer dude or valley girl. Each of these groups brings a distinctive style, which provides a rich set of linguistic resources for all inhabitants of the state. Ways of speaking are the outcome of stylistic activity Ð activity that people engage in collaboratively as they carve out a distinctive place for themselves in the social landscape. -

The Use of Regional Accent in Audio Health Communications
University of Otago The Use of Regional Accent in Audio Health Communications Rachel Leeson A thesis submitted in partial fulfilment of the requirements for the degree of Master of Science Communication Centre for Science Communication, University of Otago, Dunedin, New Zealand 28 June 2019 Abstract Cancer is a large and complex family of diseases with a variety of causes and risk factors. The health communication strategy needed to combat cancer may also need to be a large and complex family of communications. Podcasts are an easily made, readily accessible form of audio communication. However, little research has been done about the use of podcasts for health communications. Drawing on the body of literature that supports the efficacy of tailored and targeted health communications, this project looks at the use of audio cancer prevention communications tailored with three regional accents, the American Midwestern accent, the Southern Texan accent, or the Tejano (Texan Mexican American) accent, focusing on a cancer prevention message in two cohorts, Americans (excluding Texans) and Texans. After listening to any of the three audio communications, both cohorts had a strong comprehension of the message and intended to exercise more. The American population reported liking the Southern-accented narrator less and viewing the message as less valid compared to the other narrators, but this did not impact either comprehension or intention to exercise. The Texan population had no significant difference in response to any of the three accents. However, in both the Texan and American population, there was a difference in the response to accents between men and women. -

READ to Your Child!! Read in English OR in Your Home Language
Grades K-2 PARENTS: READ to your child!! Read in English OR in your home language. Any type of reading improves a child’s ability to understand how to read! For example, you child learns that sounds are represented by letters and that the text runs in a direction. SPEAK with your child often! Point out interesting items on a daily walk or around your house. This builds your child’s observational skills, enabling him or her to be more focused when learning English. Again, do this in English or in your home language. Do not worry if your English is not as good as you want it to be! Your child will learn from you! Children have a unique ability to learn a second language like a native speaker; what you don’t know will not interfere with your child’s progress. BE EXCITED about learning! Do not act as if learning is a chore. Children are natural learners and are only discouraged when the tasks seem overwhelming or unrelated to what really matters. Make learning a central part of WHAT YOUR FAMILY LOVES TO DO: talk enthusiastically about what YOU are learning, ASK your child what they are learning and be happy! Grades 3-12 STUDENTS: WATCH movies or TV shows with SUBTITLES! Watch a favorite movie in English with subtitles in your first language, or switch it up: Watch the movie in your first language with English subtitles. Then, watch it in English with English subtitles and finally watch it without any subtitles. You will learn not only words, but how people use informal language. -

Jody Fish BA Thesis
Gende(r) in the Boston Accent A linguistic analysis of Boston (r) from a gender perspective Jody Fish English Studies – Linguistics BA Thesis 15 Credits Spring 2018 Supervisor: Soraya Tharani Gende(r) in the Boston Accent i Table of Contents Abstract ………………………………………………………………………………………...... ii 1 Introduction ……………………………………………………………………………………. 1 2 Background ……………………………………………………………………………………. 2 2.1 Historical background ……………………………………………………………………. 2 2.2 Theoretical background …………………………………………………………………... 3 2.3 Previous studies …………………………………………………………………………... 7 3 Design of the present study …………………………………….………………….…………. 10 3.1 Participants …………………………………………………………………………….... 10 3.2 Data elicitation ………………………………………………………………………….. 11 3.3 Method ………………………………………………………………………………….. 13 4 Results and discussion …...……………….………………………………………………....... 14 4.1 Casual speech vs careful speech ……………………………………………………....... 14 4.2 Gender differences ……………………………………………………………………… 16 4.3 Other social factors ……………………………………………………………………... 17 5 Concluding remarks …………………………………….……………………………………. 20 References …………………………………………………………………………………........ 22 Gende(r) in the Boston Accent ii Abstract The Boston accent is one of the most famous accents in the United States and is known for its non-rhoticity, which essentially means that Bostonians do not normally pronounce their r’s after vowels. While most Boston locals would tell you to ‘pahk the cah ova hea’ when you arrive in the city, not every Bostonian has the same level of non-rhoticity; this variation is due to a number of different factors, but arguably one of the most interesting factors, which this paper focuses on, is gender. This study looks into how Boston non-rhoticity differs between males and females, as well the theories that explain these potential differences. This is done by collecting and analyzing the speech of Boston locals, following two previous studies on the same topic. In addition to gender, types of speech and other social factors are also analyzed. -
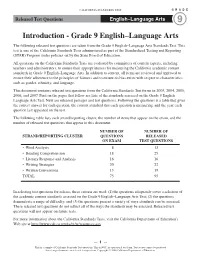
Grade 9 ELA Released Test Questions
CALIFORNIA STANDARDS TEST GRADE Released Test Questions English–Language Arts 9 Introduction - Grade 9 English–Language Arts The following released test questions are taken from the Grade 9 English–Language Arts Standards Test. This test is one of the California Standards Tests administered as part of the Standardized Testing and Reporting (STAR) Program under policies set by the State Board of Education. All questions on the California Standards Tests are evaluated by committees of content experts, including teachers and administrators, to ensure their appropriateness for measuring the California academic content standards in Grade 9 English–Language Arts. In addition to content, all items are reviewed and approved to ensure their adherence to the principles of fairness and to ensure no bias exists with respect to characteristics such as gender, ethnicity, and language. This document contains released test questions from the California Standards Test forms in 2003, 2004, 2005, 2006, and 2007. First on the pages that follow are lists of the standards assessed on the Grade 9 English– Language Arts Test. Next are released passages and test questions. Following the questions is a table that gives the correct answer for each question, the content standard that each question is measuring, and the year each question last appeared on the test. The following table lists each strand/reporting cluster, the number of items that appear on the exam, and the number of released test questions that appear in this document. NUMBER OF NUMBER OF STRAND/REPORTING -

(CA ELD) Standards Encourage Your Child to Read
Optional We’d like to hear from those who access this CA Standards document. We invite you to participate in a brief survey: Survey https://www.surveymonkey.com/r/CC_Doc_Use_Survey The Purpose of the Three Levels in the To help your student make progress in How Your English “ELD Proficiency Level Continuum” learning English: Learner Student Will The CA ELD Standards define three proficiency Keep speaking your first language with your child. levels—Emerging, Expanding, and Bridging*—to All the words children learn in their first language Learn English: describe the stages of English language development will be useful when they are learning English. through which ELs are expected to progress as they The California English improve their abilities in listening, speaking, reading, Tell your child stories you were told in your and writing English. Importantly, the language skills childhood, or read to your child in your first Language Development described in all three proficiency levels support language—or in English. ELs as they learn English language arts and develop (CA ELD) Standards Encourage your child to read. Make regular visits literacy in history–social science, mathematics, to the library to keep reading material available at science, and other school subjects. home. Independent reading is a great way to learn Kindergarten–Grade 12 The “ELD Proficiency Level Continuum” chart shows new vocabulary. how ELs progress as they become fluent in English. For more information on the CA ELD Standards Each proficiency level includes descriptions of the and ideas for helping your student succeed, knowledge, skills, and abilities of English as a new language and of the “entry” and “exit” stages of check out these resources: the proficiency level.