Game Data Mining Competition on Churn Prediction and Survival Analysis Using Commercial Game Log Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

John Douglas Owens
John Douglas Owens Electrical and Computer Engineering, University of California One Shields Avenue, Davis, CA - USA +--- / [email protected] http://www.ece.ucdavis.edu/~jowens/ R Computer systems; parallel computing, general-purpose computation on graphics hardware / I GPU computing, parallel algorithms and data structures, graphics architectures, parallel architec- tures and programming models. E Stanford University Stanford, California Department of Electrical Engineering – Ph.D., Electrical Engineering, January M.S., Electrical Engineering, March Advisors: Professors William J. Dally and Pat Hanrahan Dissertation Topic: “Computer Graphics on a Stream Architecture” University of California, Berkeley Berkeley, California Department of Electrical Engineering and Computer Sciences – B.S., Highest Honors, Electrical Engineering and Computer Sciences, June P University of California, Davis Davis, California A Child Family Professor of Engineering and Entrepreneurship – Associate Professor – Assistant Professor – Professor in the Department of Electrical and Computer Engineering; member of Graduate Groups of Electrical and Computer Engineering and Computer Science. Visiting Scientist, Lawrence Berkeley National Laboratory. Twitter San Francisco, California So ware Engineer (Sabbatical) July–December Engineer in Core System Libraries group in Twitter’s Runtime Systems division. Stanford University Stanford, California Research Assistant – An architect of the Imagine Stream Processor under the direction of Professor William J. Dally. Responsible for major portions of hardware and so ware design for Imagine and its tools and applications. Stanford University Stanford, California Teaching Assistant Fall Teaching assistant for Computer Science , “e Coming Revolution in Computer Architecture”, under Professor William J. Dally. Designed course with Professor Dally, including lecture topics, readings, and laboratories. Interval Research Corporation Palo Alto, California Consultant – Investigated new graphics architectures under the direction of Dr. -

DVD/Video Game Entertainment System
DVD/Video Game Entertainment System Owner's Manual wireless input .mp3 RES R integrated SURROUND SOUND VIDEOGAMES s SATELLITE Table of Contents Getting Started ......................................................................................................................................................................................................................... 4 Switching On, Lowering and Adjusting the Screen, Finding the Remote Control Buttons You Need, Listening Over the Vehicle Speakers Introduction .............................................................................................................................................................................................................................. 6 Discs Played ............................................................................................................................................................................................................................ 7 Changing Display Settings, Using the Dome Lights ................................................................................................................................................................ 8 Using the Remote Control ........................................................................................................................................................................................................ 9 Basic Remote Control Buttons ............................................................................................................................................................................................. -

PRESS RELEASE Media Contact Michael Prefontaine | Silicon Studio
PRESS RELEASE Media Contact Michael Prefontaine | Silicon Studio | [email protected] |+81 (0)3 5488 7070 From Silicon Studio and MISTWALKER New game "Terra Battle 2" under joint development Teaser site, trailer, and social media released Tokyo, Japan, (June 22, 2017) –Middleware and game development company, Silicon Studio Corporation are excited to announce their joint development with renowned game developer MISTWALKER COPRPORATION, to develop the next game in the hit “Terra Battle” series, “Terra Battle 2” for smartphones and PC. The official trailer and social media sites are set to open June 22, 2017. About Terra Battle 2 The battle gameplay that wowed so many players in the original "Terra Battle" remains, but now it is complimented by a full role-playing game in which every system has evolved to deliver a more deeply enriched story and experience. The adoption of the dynamic field map allows you direct and travel with your characters throughout the world. Intense emotion abounds from fated encounters, bitter farewells, the joy of glory won, pain and heartbreak, and more heated battles that will have your hands sweating. 1 | Can the people of "Terra" ever uncover the illusive truth of their world? A spectacular journey is waiting for you. ●Gameplay screenshot(Depicted is still under development) Screenshots from left to right: Title Screen, Field Map, Battle Scene, Event Scene ●Character/ Guardian Left:Roland(Guardian)/Right:Sarah(Character) 2 | Trailer, Teaser site, Social Media Ahead of the release the teaser site, trailer, and official Twitter and Facebook accounts will open. For now, these are only available in Japanese, but users are welcome to check in for more information. -

Stock Market Game DECA Competition
KNOWLEDGE AND SKILLS DEVELOPED Participants will demonstrate knowledge and skills needed STOCK MARKET GAME to address the components of the project as described in the STOCK MARKET GAME SMG content outline and evaluation forms. Participants in the SIFMA Foundation Stock Market Game develop and manage a virtual investment Participants will also develop portfolio of stocks, bonds, and mutual funds. The Stock Market Game is conducted via the internet many 21st Century Skills, in the and allows DECA members to test their knowledge and skills against other DECA members in an online following categories, desired competition. Each participating team manages all aspects of the portfolio including asset selection, buying by today’s employers: and selling. The goal of the competition is to increase the value of the portfolio. • Communication and During the course of the Stock Market Game, participants will: Collaboration • develop investment strategies based on expectations of growth, diversification and stability • attempt to avoid the pitfalls of market decline, mergers and overextension • Creativity and Innovation • Critical Thinking and EVENT OVERVIEW Problem Solving It is the responsibility of the advisor and participating teams to familiarize themselves with the Rules of The • Flexibility and Adaptability Stock Market Game. Rules are accessible through a link on the home pages of the team portfolio and in the Teacher Support Center. • Information Literacy In addition to the general rules of the Stock Market Game, DECA advisors and their teams should be aware of • Initiative and Self-direction the following: • Leadership and • This event consists of a written document describing the investment project and the oral presentation. -

Introducing the Game Design Matrix: a Step-By-Step Process for Creating Serious Games
Air Force Institute of Technology AFIT Scholar Theses and Dissertations Student Graduate Works 3-2020 Introducing the Game Design Matrix: A Step-by-Step Process for Creating Serious Games Aaron J. Pendleton Follow this and additional works at: https://scholar.afit.edu/etd Part of the Educational Assessment, Evaluation, and Research Commons, Game Design Commons, and the Instructional Media Design Commons Recommended Citation Pendleton, Aaron J., "Introducing the Game Design Matrix: A Step-by-Step Process for Creating Serious Games" (2020). Theses and Dissertations. 4347. https://scholar.afit.edu/etd/4347 This Thesis is brought to you for free and open access by the Student Graduate Works at AFIT Scholar. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of AFIT Scholar. For more information, please contact [email protected]. INTRODUCING THE GAME DESIGN MATRIX: A STEP-BY-STEP PROCESS FOR CREATING SERIOUS GAMES THESIS Aaron J. Pendleton, Captain, USAF AFIT-ENG-MS-20-M-054 DEPARTMENT OF THE AIR FORCE AIR UNIVERSITY AIR FORCE INSTITUTE OF TECHNOLOGY Wright-Patterson Air Force Base, Ohio DISTRIBUTION STATEMENT A APPROVED FOR PUBLIC RELEASE; DISTRIBUTION UNLIMITED. The views expressed in this document are those of the author and do not reflect the official policy or position of the United States Air Force, the United States Department of Defense or the United States Government. This material is declared a work of the U.S. Government and is not subject to copyright protection in the United States. AFIT-ENG-MS-20-M-054 INTRODUCING THE GAME DESIGN MATRIX: A STEP-BY-STEP PROCESS FOR CREATING LEARNING OBJECTIVE BASED SERIOUS GAMES THESIS Presented to the Faculty Department of Electrical and Computer Engineering Graduate School of Engineering and Management Air Force Institute of Technology Air University Air Education and Training Command in Partial Fulfillment of the Requirements for the Degree of Master of Science in Cyberspace Operations Aaron J. -

Competition Versus Cooperation: the Sociological Uses of Musical Chairs*
NOTES THE CHAIRS GAME- COMPETITION VERSUS COOPERATION: THE SOCIOLOGICAL USES OF MUSICAL CHAIRS* SUSANR. TAKATA Universityof Wisconsin,Parkside MY TEACHINGAPPROACH is not traditional techniques to use in my classes, I acciden- "lectures-and-quietly-take-notes"where stu- tally came across one in Robert Fulghum's dents are the passive recipients of knowl- Maybe (MaybeNot): Second Thoughtsfrom edge. In recent years, I have become in- a Secret Life (1993:117-21). As an ice- creasingly interested in active student- breaker in his high school philosophy involved, process-based learning. Yvone classes, he presented two versions of musi- Lenard reminds us that "Learningis messy. cal chairs. The first version is the one we Performance is neat,"' which reflects the are all familiar with, but the second version initial struggles that occur when studentsare has one rule change that demonstrates the problem solving or grasping a new sociolog- value of cooperation. I use the same ap- ical concept. Founded on the principles of proach as Fulghum, which emphasizes com- cooperative learning (Johnson, Johnson, and petition versus cooperation, but I have ex- Holubec 1991), the taxonomy of learning panded the focus of this teaching technique (Bloom 1956), divergent production to include the application of a variety of (Guilford 1967), and affect (Hall 1959), the sociological concepts. The Chairs Game is Chairs Game demonstrates how students an excellent active learning tool, which be- learn about competition versus cooperation comes the focus of class discussions as well as a variety of sociological concepts throughoutthe semester. This technique ap- and theories. This process does not occur plies to a wide variety of courses within neatly or in a straight line progression. -

In-Game Advertising Measurement Guidelines
In-Game Advertising Measurement Guidelines Released September 2009 IAB In-Game Advertising Measurement Guidelines These Guidelines have been developed by the IAB In-Game Ad Measurement Working Group with guidance from the IAB Games Committee. About the IAB In-Game Ad Measurement Working Group: The IAB In-Game Ad Measurement Working Group worked to develop a transparent methodology that will support growth and stability in the industry as advertisers will have consistent and reliable metrics across various providers. Key Contributors: 2KGames Extent PointRoll Activision Google Range Online Atlas IAC Real Networks Deloitte IGA SkyWorks Double Fusion IGN Sony Playstation Dynamic Logic IM Services THQ Electronic Arts Jogo Media Ubisoft Ernst & Young Microsoft Unicast About the IAB Games Committee: The mission of this committee is to articulate the value of gaming as an advertising platform. A full list of Council member companies can be found at: http://www.iab.net/games_committee IAB Contact Information: IAB Ad Technology Team [email protected] 116 East 27th St 7th Floor New York, NY 10016 © 2009 Interactive Advertising Bureau - 2 - IAB In-Game Advertising Measurement Guidelines Table of Contents: 1. Scope and Applicability of these Guidelines ........................................................................................ 4 2. Glossary ................................................................................................................................................... 4 3. Measurement Definitions and Other Metrics -

Rules of Play - Game Design Fundamentals
Table of Contents Table of Contents Table of Contents Rules of Play - Game Design Fundamentals.....................................................................................................1 Foreword..............................................................................................................................................................1 Preface..................................................................................................................................................................1 Chapter 1: What Is This Book About?............................................................................................................1 Overview.................................................................................................................................................1 Establishing a Critical Discourse............................................................................................................2 Ways of Looking.....................................................................................................................................3 Game Design Schemas...........................................................................................................................4 Game Design Fundamentals...................................................................................................................5 Further Readings.....................................................................................................................................6 -

NOT JUST a GAME Featuring Dave Zirin
MEDIA EDUCATION FOUNDATION STUDY GUIDE NOT JUST A GAME Featuring Dave Zirin Study Guide Written by SCOTT MORRIS please visit www.mediaed.org/wp/notjustagame for updated materials & resources 2 CONTENTS Note to Educators ………………………………………………………………………………………3 Program Overview ……………………………………………………………………………………...4 Pre-viewing Questions …………………………………………………………………………………4 Introduction ……………………………………………………………………………………………...5 Key Points …………………………………………………………………………………………5 Questions for Discussion & Writing …………………………………………………………….5 Assignments ………………………………………………………………………………………6 In the Arena ……………………………………………………………………………………………..7 Key Points …………………………………………………………………………………………7 Questions for Discussion & Writing …………………………………………………………….8 Assignments ………………………………………………………………………………………9 Like a Girl ………………………………………………………………………………………………10 Key Points ……………………………………………………………………………………….10 Questions for Discussion & Writing …………………………………………………………...12 Assignments …………………………………………………………………………………….13 Breaking the Color Barrier ……………………………………………………………………………15 Key Points ……………………………………………………………………………………….15 Questions for Discussion & Writing …………………………………………………………...15 Assignments …………………………………………………………………………………….16 The Courage of Athletes ……………………………………………………………………………..18 Key Points ……………………………………………………………………………………….18 Questions for Discussion & Writing …………………………………………………………...19 Assignments …………………………………………………………………………………….20 3 NOTE TO EDUCATORS This study guide is designed to help you and your students engage and manage the information presented in this video. -

Game and Sport Administration No Student Who Has Played on a College Team Is Eligible to Play on a High School Team
Game and Sport Administration No student who has played on a college team is eligible to play on a high school team. A student who has enrolled and attended class in a college will not be eligible for high school competition, but this does not affect a regularly enrolled high school student who is merely taking the college course(s) for advanced credit. GAME AND SPORT ADMINISTRATION 17. PRACTICE TIME: There shall be no athletic practice during the regular school day. This means no individual or team practice may begin until after the last regularly scheduled instructional period. No authorized practice, contest, or workouts may occur during the work day for teachers during the ten-month teaching calendar, and coaches may not use their vaca- tion or leave time to hold a practice during the teacher work day. On the day following the end of the academic school year calendar, non-mandatory teacher workdays are governed by local policy. This rule also applies to non-faculty coaches. Exception: if a superintendent gives permis- sion for schools in his/her unit to practice prior to the end of a work day DUE TO INCLEMENT WEATHER ONLY. Team practice in any sport is prohibited after the sports season ends until the first day following the final day of the school year. 18. GAME RULES: All high schools participating in interscholastic athletics shall use the game rules as set forth by the National Federation of State High School Associations. Golf and tennis shall use USGA and USTA rules respectively, except where local modifications apply. -
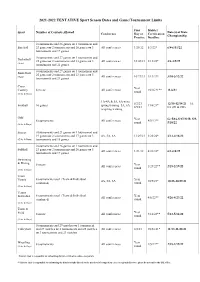
2021-2022 TENTATIVE Sport Season Dates and Game/Tournament Limits
2021-2022 TENTATIVE Sport Season Dates and Game/Tournament Limits First District Sport Number of Contests Allowed Date(s) of State Conference Day of Certification Championship Practice Deadline 0 tournaments and 26 games or 1 tournament and Baseball 23 games or 2 tournaments and 20 games or 3 All conferences 1/28/22 5/3/22* 6/8-6/11/22 tournaments and 17 games 0 tournaments and 27 games or 1 tournament and Basketball 25 games or 2 tournaments and 23 games or 3 All conferences 10/20/21 2/12/22* 3/3-3/5/22 (Girls) tournaments and 21 games 0 tournaments and 27 games or 1 tournament and Basketball 25 games or 2 tournaments and 23 games or 3 (Boys) All conferences 10/27/21 2/19/22* 3/10-3/12/22 tournaments and 21 games Cross Year Country 8 meets All conferences 10/16/21** 11/6/21 round (Girls & Boys) 1A-4A & 5A, 6A w/no 8/2/21 12/15-12/18/21—1A- Football 10 games spring training 5A, 6A 11/6/21* 8/9/21 6A (DI & DII) w/spring training Golf Year G: 5/16-5/17/22 B: 5/9- 8 tournaments All conferences 4/9/22** round 5/10/22 (Girls & Boys) Soccer 0 tournaments and 21 games or 1 tournament and 19 games or 2 tournaments and 17 games or 3 4A, 5A, 6A 11/29/21 3/22/22* 4/13-4/16/22 (Girls & Boys) tournaments and 15 games 0 tournaments and 26 games or 1 tournament and Softball 23 games or 2 tournaments and 20 games or 3 All conferences 1/21/22 4/26/22* 6/1-6/4/22 tournaments and 17 games Swimming & Diving 8 meets Year All conferences 1/29/22** 2/18-2/19/22 round (Girls & Boys) Team 8 tournaments total (Team & Individual Year Tennis 4A, 5A, 6A 10/9/21* -

Download 2021-22 Athletics Contest Rules
Section 1200: Purposes of High School Athletics 119 Subchapter C. HIGH SCHOOL ATHLETIC PLAN NOTE: Rules that list the sport or sports to which they (3) Accept decisions of sports and school officials apply shall apply only to the sport(s) listed. without protest and without questioning their honesty or integrity, and extend protection Section 1200: PURPOSES OF HIGH SCHOOL ATH- and courtesy to sports officials from par- LETICS ticipants, school personnel and spectators remembering that officials are guests. The purposes of the athletic program for the member (4) Regard opponents as guests, putting clean schools are: play and good sportsmanship above victory (a) to assist, advise and aid the member schools in at any cost. Win without boasting and lose organizing and conducting interschool athletics; without bitterness. Victory is important, but (b) to devise and prepare eligibility rules that will equal- the most important thing in sports is striving ize and stimulate wholesome competition between to excel and the positive feelings it fosters schools of similar size, and reinforce the curriculum; between those who play fair and have no (c) to regulate competition so that students, schools excuse when they lose. The development of and communities can secure the greatest educa- positive human relations should be stressed tional, social, recreational and aesthetic benefits in all competition. from the contests; (5) Remember that conduct that berates, intimi- (d) to reinforce the concept to all member schools that dates, or threatens competitors has no place athletics is an integral part of the educational pro- in interscholastic activities. gram; (6) Provide information or evidence as soon as (e) to preserve the game for the overall benefit of the possible regarding eligibility of any contes- contestant and not sacrifice the contestant to the tant or school to the local administration, game; then to the proper District Executive Com- (f) to promote the spirit of good sportsmanship and mittee.