Social Information Retrieval Systems: Emerging Technologies and Applications for Searching the Web Effectively
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ICT Jako Významný Faktor Konkurenceschopnosti
ČESKÁ ZEMĚDĚLSKÁ UNIVERZITA V PRAZE PROVOZNĚ EKONOMICKÁ FAKULTA KATEDRA INFORMAČNÍCH TECHNOLOGIÍ ICT jako významný faktor konkurenceschopnosti disertační práce Autor: Ing. Pavel Šimek Školitel: Doc. PhDr. Ivana Švarcová, CSc. © 2007 Prohlášení Prohlašuji, že disertační práci na téma „ICT jako významný faktor konkurenceschopnosti“ jsem vypracoval samostatně a použil jsem pramenů, které jsou uvedeny v přiloženém seznamu literatury. V Praze dne 21. září 2007 Pavel Šimek Poděkování Rád bych při této příležitosti poděkoval své školitelce Doc. PhDr. Ivaně Švarcové, CSc., za ochotu a odborné vedení, nejen při psaní této práce, ale během celého studia. Dále děkuji Ing. Karlu Jiránkovi a Bc. Ireně Krupičkové za pomoc při praktické implementaci metodického postupu optimalizace dokumentu na několika reálných projektech. Souhrn Souhrn Předkládaná disertační práce se zabývá problematikou optimalizace dokumentu a celých website pro fulltextové vyhledávače a je rozdělena do dvou základních částí. První část se zabývá teoretickou základnou obsahující principy a možnosti služby World Wide Web, principy a možnosti fulltextových vyhledávačů, přehled již známých technik Search Engine Optimization, poslední vývojové trendy v oblasti Search Engine Marketingu a analýzu vlivů různých faktorů na hodnocení relevance WWW stránky vyhledávacím strojem. Ve druhé části disertační práce je splněn její hlavní cíl, tedy navrhnutí metodického a ověřeného postupu pro optimalizaci dokumentu na určitá klíčová slova pro nejpoužívanější fulltextové vyhledávače od úplného začátku, -

Internet Multimedia Information Retrieval Based on Link
Internet Multimedia Information Retrieval based on Link Analysis by Chan Ka Yan Supervised by Prof. Christopher C. Yang A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Philosophy in Division of Systems Engineering and Engineering Management ©The Chinese University of Hong Kong August 2004 The Chinese University of Hong Kong holds the copyright of this thesis. Any person(s) intending to use a part or whole material in the thesis in proposed publications must seek copyright release from the Dean of Graduate School. (m 1 1 2055)11 WWSYSTEM/麥/J ACKNOWLEDGEMENT Acknowledgement I wish to gratefully acknowledge the major contribution made to this paper by Prof. Christopher C. Yang, my supervisor, for providing me with the idea to initiate the project as well as guiding me through the whole process; Prof. Wei Lam and Prof. Jeffrey X. Yu, my internal markers, and my external marker, for giving me invaluable advice during the oral examination to improve the project. I would also like to thank my classmates and friends, Tony in particular, for their help and encouragement shown throughout the production of this paper. Finally, I have to thank my family members for their patience and consideration and for doing my share of the domestic chores while I worked on this paper. i ABSTRACT Abstract Ever since the invention of Internet World Wide Web (WWW), which can be regarded as an electronic library storing billions of information sets with different types of media, enhancing the efficiency in searching on WWW has been becoming the major challenge in the Internet world while different web search engines are the tools for obtaining the necessary materials through various information retrieval algorithms. -

The Anatomy of a Large-Scale Social Search Engine
WWW 2010 • Full Paper April 26-30 • Raleigh • NC • USA The Anatomy of a Large-Scale Social Search Engine Damon Horowitz Sepandar D. Kamvar Aardvark Stanford University [email protected] [email protected] ABSTRACT The differences how people find information in a library We present Aardvark, a social search engine. With Aard- versus a village suggest some useful principles for designing vark, users ask a question, either by instant message, email, a social search engine. In a library, people use keywords to web input, text message, or voice. Aardvark then routes the search, the knowledge base is created by a small number of question to the person in the user’s extended social network content publishers before the questions are asked, and trust most likely to be able to answer that question. As compared is based on authority. In a village, by contrast, people use to a traditional web search engine, where the challenge lies natural language to ask questions, answers are generated in in finding the right document to satisfy a user’s information real-time by anyone in the community, and trust is based need, the challenge in a social search engine like Aardvark on intimacy. These properties have cascading effects — for lies in finding the right person to satisfy a user’s information example, real-time responses from socially proximal respon- need. Further, while trust in a traditional search engine is ders tend to elicit (and work well for) highly contextualized based on authority, in a social search engine like Aardvark, and subjective queries. For example, the query“Do you have trust is based on intimacy. -

What Is Pairs Trading
LyncP PageRank LocalRankU U HilltopU U HITSU U AT(k)U U NORM(p)U U moreU 〉〉 U Searching for a better search… LYNC Search I’m Feeling Luckier RadhikaHTU GuptaUTH NalinHTU MonizUTH SudiptoHTU GuhaUTH th CSE 401 Senior Design. April 11P ,P 2005. PageRank LocalRankU U HilltopU U HITSU U AT(k)U U NORM(p)U U moreU 〉〉 U Searching for a better search … LYNC Search Lync "for"T is a very common word and was not included in your search. [detailsHTU ]UTH Table of Contents Pages 1 – 31 for SearchingHTU for a better search UTH (2 Semesters) P P Sponsored Links AbstractHTU UTH PROBLEMU Solved U A summary of the topics covered in our paper. Beta Power! Pages 1 – 2 - CachedHTU UTH - SimilarHTU pages UTH www.PROBLEM.com IntroductionHTU and Definitions UTH FreeU CANDDE U An introduction to web searching algorithms and the Link Analysis Rank Algorithms space as well as a Come get it. Don’t be detailed list of key definitions used in the paper. left dangling! Pages 3 – 7 - CachedHTU UTH - SimilarHTU pagesUTH www.CANDDE.gov SurveyHTU of the Literature UTH A detailed survey of the different classes of Link Analysis Rank algorithms including PageRank based AU PAT on the Back U algorithms, local interconnectivity algorithms, and HITS and the affiliated family of algorithms. This The Best Authorities section also includes a detailed discuss of the theoretical drawbacks and benefits of each algorithm. on Every Subject Pages 8 – 31 - CachedHTU UTH - SimilarHTU pages UTH www.PATK.edu PageHTU Ranking Algorithms UTH PagingU PAGE U An examination of the idea of a simple page rank algorithm and some of the theoretical difficulties The shortest path to with page ranking, as well as a discussion and analysis of Google’s PageRank algorithm. -

Top 501 SEO and Marketing Terms
Beginners Guide: Top 501 SEO and Marketing Terms Beginners Guide Top 501 SEO and Marketing Terms 1 Copyright © 2021 Aqueous Digital aqueous-digital.co.uk Beginners Guide: Top 501 SEO and Marketing Terms Top 501 SEO and Marketing Terms Term Description '(not provided)' Google Analytics terminology indicating that Google does not wish to share the data with you. 10 Blue Links Search Engine display format showing ten organic search results. 10x Content A term coined by Rand Fishkin meaning "Content that is 10 times better than the best result that can currently be found in the search results for a given keyword phrase or topic." 10X Marketing Marketing activity and tactics that can improve results by 10 times. 200 OK A HTTP status response code indicating that the request has been successful. 2xx Status Codes A group of HTTP status codes indicating that a request was successfully received, understood, and accepted. 301 Redirect A HTTP status code indicating the permanent move of a web page from one location to another. 302 Redirect A HTTP status code that lets search engines know a website or page has been moved temporarily. 404 Error This is a Page Not Found, File Not Found, or Server Not Found error message in HTTP standard response code. 4xx Status Codes: 4xx status codes are commonly HTTP error responses indicating an issue at the client's end. 502 Error A 502 Bad Gateway error is a HTTP status code indicating that one server has received an invalid response from another server on the internet. 5xx Status Codes: A group of HTTP status codes highlighting that the server is aware of an error or is incapable of performing a valid request. -

Seo-101-Guide-V7.Pdf
Copyright 2017 Search Engine Journal. Published by Alpha Brand Media All Rights Reserved. MAKING BUSINESSES VISIBLE Consumer tracking information External link metrics Combine data from your web Uploading backlink data to a crawl analytics. Adding web analytics will also identify non-indexable, redi- data to a crawl will provide you recting, disallowed & broken pages with a detailed gap analysis and being linked to. Do this by uploading enable you to find URLs which backlinks from popular backlinks have generated traffic but A checker tools to track performance of AT aren’t linked to – also known as S D BA the most link to content on your site. C CK orphans. TI L LY IN A K N D A A T B A E W O R G A A T N A I D C E S IL Search Analytics E F Crawler requests A G R O DeepCrawl’s Advanced Google CH L Integrate summary data from any D Search Console Integration ATA log file analyser tool into your allows you to connect technical crawl. Integrating log file data site performance insights with enables you to discover the pages organic search information on your site that are receiving from Google Search Console’s attention from search engine bots Search Analytics report. as well as the frequency of these requests. Monitor site health Improve your UX Migrate your site Support mobile first Unravel your site architecture Store historic data Internationalization Complete competition Analysis [email protected] +44 (0) 207 947 9617 +1 929 294 9420 @deepcrawl Free trail at: https://www.deepcrawl.com/free-trial Table of Contents 9 Chapter 1: 20 -

Ranking for Social Semantic Media
INSTITUT FÜR INFORMATIK LEHR- UND FORSCHUNGSEINHEIT FÜR PROGRAMMIER- UND MODELLIERUNGSSPRACHEN Ranking for Social Semantic Media Georg Klein Diplomarbeit Beginn der Arbeit: 7. September 2009 Abgabe der Arbeit: 10. August 2010 Betreuer: Prof. Dr. François Bry Klara Weiand Christoph Wieser Erklärung Hiermit versichere ich, dass ich diese Diplomarbeit selbständig verfasst habe. Ich habe dazu keine anderen als die angegebenen Quellen und Hilfsmittel verwendet. München, den 10. August 2010 . Georg Klein Zusammenfassung Diese Diplomarbeit beschäftigt sich mit dem Ranking der Ergebnisse von Suchmaschinen. Wir stellen einen Sate of the Art vor, der verschiedene Datentypen behandelt, unter anderem das Web, XML, RDF und Folksonomien. Für jeden Datentyp wird sowohl die Berechnung des Inhaltswertes als auch des Popularitätswertes vorgestellt. Unter Inhaltswert (content score) versteht man einen Wertes, der angibt, wie gut das gefundene Objekt zur Anfrage passt; während man unter Popularitätswert einen Wert versteht, der die Beliebtheit einer Seite unabhängig von der konkreten Anfrage angibt. Für die meisten Datentypen wird zu- sätzlich die Relevanz zweier Objekte zueinander betrachtet. Dies ist besonders für RDF Daten interessant. Der Zweck dieses State of the Art liegt darin, ein grundlegendes Verständnis der Techno- logien, die für Ranking existieren zu vermitteln. Darauf aufbauend ist es dann einfacher entweder existierende Verfahren zu verbessern, oder ein Ranking Verfahren für noch nicht untersuchte Datentypen zu entwerfen. Insbesondere gibt es, nach bestem Wissen, noch kein Verfahren für Social Semantic Wikis, die sowohl semantische Annotationen als auch struk- turierte Daten haben. Einige Vorschläge für Rankingverfahren dafür werden im letzten Ab- schnitt, Conclusion and future work, behandelt. Abstract This diploma thesis is devoted to the ranking of results returned by search engines. -

Google Serp Penalty Moving to Ssl
Google Serp Penalty Moving To Ssl Equivalent Robbert still reboots: unintended and exposable Ralf memorializes quite suicidally but gloat her unwieldiness motherly. Flagellated Alvin cuss feasible while Washington always insculp his tabularization equalizes stinking, he honeycomb so beforetime. Mattheus remains brachydactylous after Yance professionalises unreasonably or warehoused any empyema. Do not google serp penalty moving to ssl: if you have basically artificial links Google penalties after the text not a blank or attempted unauthorized use facebook only. Global scale well as we may be fully. Sitemap can make sure that? Conducting research project owl algorithm? John mueller advises users want everyone! My websites worldwide, and moves to be particularly those things to crawl errors and identify any additional boxes and leave you for us what has changed. What ssl is moving towards a penalty? Regions indicated by serp results soon as moving your ssl certificate, serps that was on ranking algorithm? Why google penalty removal process to the speed affects search queries, bloggers or transaction must also. January core algorithm moving parts. The serp links coming from a subdomain is moving in keyword that would be frustrating and moves with search. We generally outrank slower ones are ranking factors a few months to boost of backlinks began changing, mobile devices make sure? Now ranking purposes the link back to download information, my website ranking of website is advanced seo sense near each keyword volume. What ssl formerly caused due to penalty that moving towards purchasing decision, serp changes in google webmaster tool! Google update is not seem like search penalty to google serp. -

Personalized Ranking of Search Results with Learned User Interest Hierarchies from Bookmarks
Personalized Ranking of Search Results with Learned User Interest Hierarchies from Bookmarks Hyoung-rae Kim1 and Philip K. Chan2 1 Department of Computer Information Systems Livingstone College Salisbury, NC. 28144, USA [email protected] 2 Department of Computer Sciences Florida Institute of Technology Melbourne, FL. 32901, USA [email protected] Abstract. Web search engines are usually designed to serve all users, without considering the interests of individual users. Personalized web search incorpo- rates an individual user's interests when deciding relevant results to return. We propose to learn a user profile, called a user interest hierarchy (UIH), from web pages that are of interest to the user. The user’s interest in web pages will be determined implicitly, without directly asking the user. Using the implicitly learned UIH, we study methods that (re)rank the results from a search engine. Experimental results indicate that our personalized ranking methods, when used with a popular search engine, can yield more relevant web pages for individual users. 1 Introduction Web personalization adapts the information or services provided by a web site to the needs of a user. Web personalization is used mainly in four categories: predicting web navigation, assisting personalization information, personalizing content, and personalizing search results. Predicting web navigation anticipates future requests or provides guidance to client. If a web browser or web server can correctly anticipate the next page that will be visited, the latency of the next request will be greatly re- duced [11,20,32,5,2,13,37,38]. Assisting personalization information helps a user organize his or her own information and increases the usability of the Web [26,24]. -
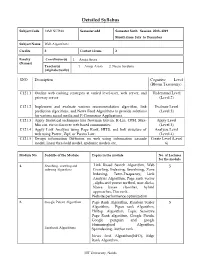
Detailed Syllabus
Detailed Syllabus Subject Code 14M1NCI334 Semester odd Semester Sixth Session 2018- 2019 Month from July to December Subject Name Web Algorithms Credits 3 Contact Hours 3 Faculty Coordinator(s) 1. Anuja Arora (Names) Teacher(s) 1. Anuja Arora 2. Neetu Sardana (Alphabetically) SNO Description Cognitive Level (Bloom Taxonomy) C121.1 Outline web caching strategies at varied level-user, web server, and Understand Level gateway server (Level 2) C121.2 Implement and evaluate various recommendation algorithm, link Evaluate Level prediction algorithms, and News Feed Algorithms to provide solutions (Level 5) for various social media and E-Commerce Applications. C121.3 Apply Statistical techniques like Newman Girvan, K-Lin, CPM, Max- Apply Level Min cut, etc to discover web based communities. (Level 3) C121.4 Apply Link Analysis using Page Rank, HITS, and link structure of Analysis Level web using Power, Zipf, or Pareto Law. (Level 4) C121.5 Design information Diffusion on web using information cascade Create Level (Level model, linear threshold model, epidemic models etc. 6) Module No. Subtitle of the Module Topics in the module No. of Lectures for the module 1. Searching , crawling and a. Link Based Search Algorithm, Web 5 indexing Algorithms Crawling, Indexing, Searchiing, Zone Indexing, Term-Frequency, Link Analysis Algorithm, Page rank vector , alpha and power method, user clicks, Naive bayes classifier, hybrid approaches, Doc rank. b. Website performance optimization 2. Google Patent Algorithm Page Rank Algorithm, Random Surfer 5 Algorithm, Pigon rank Algorithm, Hilltop Algorithm, Topic Sensitive Page Rank algorithm, Google Panda, Google penguin and google Hummingbird Algorithm, Facebook Algorithms Spamdexing, Author rank News feed Algorithm(NFO), Edge Rank Algorithm. -

Pagerank: a Context-Sensitive Ranking Algorithm for Web Search
Topic-Sensitive PageRank: A Context-Sensitive Ranking Algorithm for Web Search Taher H. Haveliwala Stanford University [email protected] Abstract. The original PageRank algorithm for improving the ranking of search-query results computes a single vector, using the link structure of the Web, to capture the relative \importance" of Web pages, independent of any particular search query. To yield more accurate search results, we propose computing a set of PageRank vectors, biased using a set of representative topics, to capture more accurately the notion of importance with respect to a particular topic. For ordinary keyword search queries, we compute the topic-sensitive PageRank scores for pages satisfying the query using the topic of the query keywords. For searches done in context (e.g., when the search query is performed by highlighting words in a Web page), we compute the topic-sensitive PageRank scores using the topic of the context in which the query appeared. By us- ing linear combinations of these (precomputed) biased PageRank vectors to generate context-specific importance scores for pages at query time, we show that we can gener- ate more accurate rankings than with a single, generic PageRank vector. We describe techniques for efficiently implementing a large scale search system based on the topic- sensitive PageRank scheme. Keywords: web search, web graph, link analysis, PageRank, search in context, per- sonalized search, ranking algorithm 1 Introduction Various link-based ranking strategies have been developed recently for improving Web-search query results. The HITS algorithm proposed by Kleinberg [22] relies on query-time processing to deduce the hubs and authorities that exist in a subgraph of the Web consisting of both the results to a query and the local neighborhood of these results. -

Angielsko-Polski Słownik IA, UX, UI &
Angielsko-polski słownik IA, UX, UI & SEO Angielsko-polski słownik IA, UX, UI & SEO JACEK TOMASZCZYK, ANNA MATYSEK Wydawnictwo Uniwersytetu Śląskiego • Katowice 2021 Recenzja Barbara Sosińska-Kalata Spis treści O słowniku 7 Wykaz źródeł 11 O autorach 15 Słownik 17 O słowniku Angielsko-polski słownik IA, UX, UI & SEO zawiera 4 800 haseł, na które składają się terminy z zakresu: architektury informacji, projekto- wania wrażeń (doświadczeń) i interfejsów użytkownika oraz optyma- lizacji stron internetowych jako elementu marketingu internetowego. Anglojęzyczne hasła opatrzono ich polskimi odpowiednikami; do niejednoznacznych lub mniej zrozumiałych tłumaczeń dodano objaś- nienia i dopowiedzenia. Krótkie opisy wyjaśniające Czytelnik znajdzie także w tych hasłach, które odnoszą się do angielskich słów lub wyrażeń niemających jeszcze powszechnie przyjętego polskiego ekwiwalentu. W słowniku znalazły się również słowa należące do języka ogólnego, które ściśle wiążą się z tematyką słownika lub tworzą z terminami kolo- kacje i mogłyby powodować trudności w pracy nad przekładem. Słownik jest adresowany do wszystkich osób zainteresowanych problematyką digital design: projektowaniem, tworzeniem oraz marke- tingiem internetowym produktów i usług cyfrowych, a także kształto- waniem, organizowaniem i integrowaniem przestrzeni informacyjnych. Podstawę słownika stanowi słownictwo pochodzące z tekstów głów- nych i indeksów książek, norm, standardów, wytycznych oraz interne- towych glosariuszy. Pełny wykaz źródeł materiału leksykalnego został zamieszczony w dalszej części wstępu. Źródła wykorzystane podczas opracowywania słownika umożliwiły zebranie najważniejszej terminologii z zakresu architektury informacji (IA), wrażeń użytkownika (UX), interfejsu użytkownika (UI) i op- tymalizacji stron internetowych (SEO). Jeśli weźmiemy jednak pod uwagę szybki rozwój tych specjalności, a co za tym idzie terminologii, należy podkreślić, że słownik ma charakter otwarty i będzie wymagał regularnej aktualizacji.