Transcription Factor Footprinting Using Chromatin Accessibility Data And
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Down-Regulation of Stem Cell Genes, Including Those in a 200-Kb Gene Cluster at 12P13.31, Is Associated with in Vivo Differentiation of Human Male Germ Cell Tumors
Research Article Down-Regulation of Stem Cell Genes, Including Those in a 200-kb Gene Cluster at 12p13.31, Is Associated with In vivo Differentiation of Human Male Germ Cell Tumors James E. Korkola,1 Jane Houldsworth,1,2 Rajendrakumar S.V. Chadalavada,1 Adam B. Olshen,3 Debbie Dobrzynski,2 Victor E. Reuter,4 George J. Bosl,2 and R.S.K. Chaganti1,2 1Cell Biology Program and Departments of 2Medicine, 3Epidemiology and Biostatistics, and 4Pathology, Memorial Sloan-Kettering Cancer Center, New York, New York Abstract on the degree and type of differentiation (i.e., seminomas, which Adult male germ cell tumors (GCTs) comprise distinct groups: resemble undifferentiated primitive germ cells, and nonseminomas, seminomas and nonseminomas, which include pluripotent which show varying degrees of embryonic and extraembryonic embryonal carcinomas as well as other histologic subtypes patterns of differentiation; refs. 2, 3). Nonseminomatous GCTs are exhibiting various stages of differentiation. Almost all GCTs further subdivided into embryonal carcinomas, which show early show 12p gain, but the target genes have not been clearly zygotic or embryonal-like differentiation, yolk sac tumors and defined. To identify 12p target genes, we examined Affymetrix choriocarcinomas, which exhibit extraembryonal forms of differ- (Santa Clara, CA) U133A+B microarray (f83% coverage of 12p entiation, and teratomas, which show somatic differentiation along genes) expression profiles of 17 seminomas, 84 nonseminoma multiple lineages (3). Both seminomas and embryonal carcinoma GCTs, and 5 normal testis samples. Seventy-three genes on 12p are known to express stem cell markers, such as POU5F1 (4) and were significantly overexpressed, including GLUT3 and REA NANOG (5). -

Machine-Learning and Chemicogenomics Approach Defi Nes and Predicts Cross-Talk of Hippo and MAPK Pathways
Published OnlineFirst November 18, 2020; DOI: 10.1158/2159-8290.CD-20-0706 RESEARCH ARTICLE Machine -Learning and Chemicogenomics Approach Defi nes and Predicts Cross-Talk of Hippo and MAPK Pathways Trang H. Pham 1 , Thijs J. Hagenbeek 1 , Ho-June Lee 1 , Jason Li 2 , Christopher M. Rose 3 , Eva Lin 1 , Mamie Yu 1 , Scott E. Martin1 , Robert Piskol 2 , Jennifer A. Lacap 4 , Deepak Sampath 4 , Victoria C. Pham 3 , Zora Modrusan 5 , Jennie R. Lill3 , Christiaan Klijn 2 , Shiva Malek 1 , Matthew T. Chang 2 , and Anwesha Dey 1 ABSTRACT Hippo pathway dysregulation occurs in multiple cancers through genetic and non- genetic alterations, resulting in translocation of YAP to the nucleus and activation of the TEAD family of transcription factors. Unlike other oncogenic pathways such as RAS, defi ning tumors that are Hippo pathway–dependent is far more complex due to the lack of hotspot genetic alterations. Here, we developed a machine-learning framework to identify a robust, cancer type–agnostic gene expression signature to quantitate Hippo pathway activity and cross-talk as well as predict YAP/TEAD dependency across cancers. Further, through chemical genetic interaction screens and multiomics analyses, we discover a direct interaction between MAPK signaling and TEAD stability such that knockdown of YAP combined with MEK inhibition results in robust inhibition of tumor cell growth in Hippo dysregulated tumors. This multifaceted approach underscores how computational models combined with experimental studies can inform precision medicine approaches including predictive diagnostics and combination strategies. SIGNIFICANCE: An integrated chemicogenomics strategy was developed to identify a lineage- independent signature for the Hippo pathway in cancers. -

The Title of the Dissertation
UNIVERSITY OF CALIFORNIA SAN DIEGO Novel network-based integrated analyses of multi-omics data reveal new insights into CD8+ T cell differentiation and mouse embryogenesis A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Bioinformatics and Systems Biology by Kai Zhang Committee in charge: Professor Wei Wang, Chair Professor Pavel Arkadjevich Pevzner, Co-Chair Professor Vineet Bafna Professor Cornelis Murre Professor Bing Ren 2018 Copyright Kai Zhang, 2018 All rights reserved. The dissertation of Kai Zhang is approved, and it is accept- able in quality and form for publication on microfilm and electronically: Co-Chair Chair University of California San Diego 2018 iii EPIGRAPH The only true wisdom is in knowing you know nothing. —Socrates iv TABLE OF CONTENTS Signature Page ....................................... iii Epigraph ........................................... iv Table of Contents ...................................... v List of Figures ........................................ viii List of Tables ........................................ ix Acknowledgements ..................................... x Vita ............................................. xi Abstract of the Dissertation ................................. xii Chapter 1 General introduction ............................ 1 1.1 The applications of graph theory in bioinformatics ......... 1 1.2 Leveraging graphs to conduct integrated analyses .......... 4 1.3 References .............................. 6 Chapter 2 Systematic -

2017.08.28 Anne Barry-Reidy Thesis Final.Pdf
REGULATION OF BOVINE β-DEFENSIN EXPRESSION THIS THESIS IS SUBMITTED TO THE UNIVERSITY OF DUBLIN FOR THE DEGREE OF DOCTOR OF PHILOSOPHY 2017 ANNE BARRY-REIDY SCHOOL OF BIOCHEMISTRY & IMMUNOLOGY TRINITY COLLEGE DUBLIN SUPERVISORS: PROF. CLIONA O’FARRELLY & DR. KIERAN MEADE TABLE OF CONTENTS DECLARATION ................................................................................................................................. vii ACKNOWLEDGEMENTS ................................................................................................................... viii ABBREVIATIONS ................................................................................................................................ix LIST OF FIGURES............................................................................................................................. xiii LIST OF TABLES .............................................................................................................................. xvii ABSTRACT ........................................................................................................................................xix Chapter 1 Introduction ........................................................................................................ 1 1.1 Antimicrobial/Host-defence peptides ..................................................................... 1 1.2 Defensins................................................................................................................. 1 1.3 β-defensins ............................................................................................................. -

Genetic Variability in the Italian Heavy Draught Horse from Pedigree Data and Genomic Information
Supplementary material for manuscript: Genetic variability in the Italian Heavy Draught Horse from pedigree data and genomic information. Enrico Mancin†, Michela Ablondi†, Roberto Mantovani*, Giuseppe Pigozzi, Alberto Sabbioni and Cristina Sartori ** Correspondence: [email protected] † These two Authors equally contributed to the work Supplementary Figure S1. Mares and foal of Italian Heavy Draught Horse (IHDH; courtesy of Cinzia Stoppa) Supplementary Figure S2. Number of Equivalent Generations (EqGen; above) and pedigree completeness (PC; below) over years in Italian Heavy Draught Horse population. Supplementary Table S1. Descriptive statistics of homozygosity (observed: Ho_obs; expected: Ho_exp; total: Ho_tot) in 267 genotyped individuals of Italian Heavy Draught Horse based on the number of homozygous genotypes. Parameter Mean SD Min Max Ho_obs 35,630.3 500.7 34,291 38,013 Ho_exp 35,707.8 64.0 35,010 35,740 Ho_tot 50,674.5 93.8 49,638 50,714 1 Definitions of the methods for inbreeding are in the text. Supplementary Figure S3. Values of BIC obtained by analyzing values of K from 1 to 10, corresponding on the same amount of clusters defining the proportion of ancestry in the 267 genotyped individuals. Supplementary Table S2. Estimation of genomic effective population size (Ne) traced back to 18 generations ago (Gen. ago). The linkage disequilibrium estimation, adjusted for sampling bias was also included (LD_r2), as well as the relative standard deviation (SD(LD_r2)). Gen. ago Ne LD_r2 SD(LD_r2) 1 100 0.009 0.014 2 108 0.011 0.018 3 118 0.015 0.024 4 126 0.017 0.028 5 134 0.019 0.031 6 143 0.021 0.034 7 156 0.023 0.038 9 173 0.026 0.041 11 189 0.029 0.046 14 213 0.032 0.052 18 241 0.036 0.058 Supplementary Table S3. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Glioblastoma Stem Cells Induce Quiescence in Surrounding Neural Stem Cells Via Notch Signalling
bioRxiv preprint doi: https://doi.org/10.1101/856062; this version posted November 29, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Glioblastoma stem cells induce quiescence in surrounding neural stem cells via Notch signalling. Katerina Lawlor1, Maria Angeles Marques-Torrejon2, Gopuraja Dharmalingham3, Yasmine El-Azhar1, Michael D. Schneider1, Steven M. Pollard2§ and Tristan A. Rodríguez1§ 1National Heart and Lung Institute, Imperial College London, Hammersmith Hospital Campus, Du Cane Road, London W12 0NN, United Kingdom. 2 MRC Centre for Regenerative Medicine & Edinburgh Cancer Research UK Centre, University of Edinburgh, Edinburgh, UK. 3MRC London Institute of Medical Sciences, Institute of Clinical Sciences, Imperial College London, UK §Authors for correspondence: [email protected] and [email protected] Running title: Glioblastoma stem cell competition Keyword: Neural stem cells, quiescence, glioblastoma, Notch, cell competition 1 bioRxiv preprint doi: https://doi.org/10.1101/856062; this version posted November 29, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 1 Abstract 2 There is increasing evidence suggesting that adult neural stem cells (NSCs) are a cell of 3 origin of glioblastoma, the most aggressive form of malignant glioma. The earliest stages of 4 hyperplasia are not easy to explore, but likely involve a cross-talk between normal and 5 transformed NSCs. How normal cells respond to this cross-talk and if they expand or are 6 outcompeted is poorly understood. -

4-6 Weeks Old Female C57BL/6 Mice Obtained from Jackson Labs Were Used for Cell Isolation
Methods Mice: 4-6 weeks old female C57BL/6 mice obtained from Jackson labs were used for cell isolation. Female Foxp3-IRES-GFP reporter mice (1), backcrossed to B6/C57 background for 10 generations, were used for the isolation of naïve CD4 and naïve CD8 cells for the RNAseq experiments. The mice were housed in pathogen-free animal facility in the La Jolla Institute for Allergy and Immunology and were used according to protocols approved by the Institutional Animal Care and use Committee. Preparation of cells: Subsets of thymocytes were isolated by cell sorting as previously described (2), after cell surface staining using CD4 (GK1.5), CD8 (53-6.7), CD3ε (145- 2C11), CD24 (M1/69) (all from Biolegend). DP cells: CD4+CD8 int/hi; CD4 SP cells: CD4CD3 hi, CD24 int/lo; CD8 SP cells: CD8 int/hi CD4 CD3 hi, CD24 int/lo (Fig S2). Peripheral subsets were isolated after pooling spleen and lymph nodes. T cells were enriched by negative isolation using Dynabeads (Dynabeads untouched mouse T cells, 11413D, Invitrogen). After surface staining for CD4 (GK1.5), CD8 (53-6.7), CD62L (MEL-14), CD25 (PC61) and CD44 (IM7), naïve CD4+CD62L hiCD25-CD44lo and naïve CD8+CD62L hiCD25-CD44lo were obtained by sorting (BD FACS Aria). Additionally, for the RNAseq experiments, CD4 and CD8 naïve cells were isolated by sorting T cells from the Foxp3- IRES-GFP mice: CD4+CD62LhiCD25–CD44lo GFP(FOXP3)– and CD8+CD62LhiCD25– CD44lo GFP(FOXP3)– (antibodies were from Biolegend). In some cases, naïve CD4 cells were cultured in vitro under Th1 or Th2 polarizing conditions (3, 4). -

Supplemental Materials ZNF281 Enhances Cardiac Reprogramming
Supplemental Materials ZNF281 enhances cardiac reprogramming by modulating cardiac and inflammatory gene expression Huanyu Zhou, Maria Gabriela Morales, Hisayuki Hashimoto, Matthew E. Dickson, Kunhua Song, Wenduo Ye, Min S. Kim, Hanspeter Niederstrasser, Zhaoning Wang, Beibei Chen, Bruce A. Posner, Rhonda Bassel-Duby and Eric N. Olson Supplemental Table 1; related to Figure 1. Supplemental Table 2; related to Figure 1. Supplemental Table 3; related to the “quantitative mRNA measurement” in Materials and Methods section. Supplemental Table 4; related to the “ChIP-seq, gene ontology and pathway analysis” and “RNA-seq” and gene ontology analysis” in Materials and Methods section. Supplemental Figure S1; related to Figure 1. Supplemental Figure S2; related to Figure 2. Supplemental Figure S3; related to Figure 3. Supplemental Figure S4; related to Figure 4. Supplemental Figure S5; related to Figure 6. Supplemental Table S1. Genes included in human retroviral ORF cDNA library. Gene Gene Gene Gene Gene Gene Gene Gene Symbol Symbol Symbol Symbol Symbol Symbol Symbol Symbol AATF BMP8A CEBPE CTNNB1 ESR2 GDF3 HOXA5 IL17D ADIPOQ BRPF1 CEBPG CUX1 ESRRA GDF6 HOXA6 IL17F ADNP BRPF3 CERS1 CX3CL1 ETS1 GIN1 HOXA7 IL18 AEBP1 BUD31 CERS2 CXCL10 ETS2 GLIS3 HOXB1 IL19 AFF4 C17ORF77 CERS4 CXCL11 ETV3 GMEB1 HOXB13 IL1A AHR C1QTNF4 CFL2 CXCL12 ETV7 GPBP1 HOXB5 IL1B AIMP1 C21ORF66 CHIA CXCL13 FAM3B GPER HOXB6 IL1F3 ALS2CR8 CBFA2T2 CIR1 CXCL14 FAM3D GPI HOXB7 IL1F5 ALX1 CBFA2T3 CITED1 CXCL16 FASLG GREM1 HOXB9 IL1F6 ARGFX CBFB CITED2 CXCL3 FBLN1 GREM2 HOXC4 IL1F7 -

Glucocorticoid Receptor Signaling Activates TEAD4 to Promote Breast
Published OnlineFirst July 9, 2019; DOI: 10.1158/0008-5472.CAN-19-0012 Cancer Molecular Cell Biology Research Glucocorticoid Receptor Signaling Activates TEAD4 to Promote Breast Cancer Progression Lingli He1,2, Liang Yuan3,Yang Sun1,2, Pingyang Wang1,2, Hailin Zhang4, Xue Feng1,2, Zuoyun Wang1,2, Wenxiang Zhang1,2, Chuanyu Yang4,Yi Arial Zeng1,2,Yun Zhao1,2,3, Ceshi Chen4,5,6, and Lei Zhang1,2,3 Abstract The Hippo pathway plays a critical role in cell growth and to the TEAD4 promoter to boost its own expression. Func- tumorigenesis. The activity of TEA domain transcription factor tionally, the activation of TEAD4 by GC promoted breast 4 (TEAD4) determines the output of Hippo signaling; how- cancer stem cells maintenance, cell survival, metastasis, and ever, the regulation and function of TEAD4 has not been chemoresistance both in vitro and in vivo. Pharmacologic explored extensively. Here, we identified glucocorticoids (GC) inhibition of TEAD4 inhibited GC-induced breast cancer as novel activators of TEAD4. GC treatment facilitated gluco- chemoresistance. In conclusion, our study reveals a novel corticoid receptor (GR)-dependent nuclear accumulation and regulation and functional role of TEAD4 in breast cancer and transcriptional activation of TEAD4. TEAD4 positively corre- proposes a potential new strategy for breast cancer therapy. lated with GR expression in human breast cancer, and high expression of TEAD4 predicted poor survival of patients with Significance: This study provides new insight into the role breast cancer. Mechanistically, GC activation promoted GR of glucocorticoid signaling in breast cancer, with potential for interaction with TEAD4, forming a complex that was recruited clinical translation. -
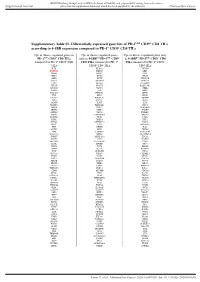
Supplementary Table S5. Differentially Expressed Gene Lists of PD-1High CD39+ CD8 Tils According to 4-1BB Expression Compared to PD-1+ CD39- CD8 Tils
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Immunother Cancer Supplementary Table S5. Differentially expressed gene lists of PD-1high CD39+ CD8 TILs according to 4-1BB expression compared to PD-1+ CD39- CD8 TILs Up- or down- regulated genes in Up- or down- regulated genes Up- or down- regulated genes only PD-1high CD39+ CD8 TILs only in 4-1BBneg PD-1high CD39+ in 4-1BBpos PD-1high CD39+ CD8 compared to PD-1+ CD39- CD8 CD8 TILs compared to PD-1+ TILs compared to PD-1+ CD39- TILs CD39- CD8 TILs CD8 TILs IL7R KLRG1 TNFSF4 ENTPD1 DHRS3 LEF1 ITGA5 MKI67 PZP KLF3 RYR2 SIK1B ANK3 LYST PPP1R3B ETV1 ADAM28 H2AC13 CCR7 GFOD1 RASGRP2 ITGAX MAST4 RAD51AP1 MYO1E CLCF1 NEBL S1PR5 VCL MPP7 MS4A6A PHLDB1 GFPT2 TNF RPL3 SPRY4 VCAM1 B4GALT5 TIPARP TNS3 PDCD1 POLQ AKAP5 IL6ST LY9 PLXND1 PLEKHA1 NEU1 DGKH SPRY2 PLEKHG3 IKZF4 MTX3 PARK7 ATP8B4 SYT11 PTGER4 SORL1 RAB11FIP5 BRCA1 MAP4K3 NCR1 CCR4 S1PR1 PDE8A IFIT2 EPHA4 ARHGEF12 PAICS PELI2 LAT2 GPRASP1 TTN RPLP0 IL4I1 AUTS2 RPS3 CDCA3 NHS LONRF2 CDC42EP3 SLCO3A1 RRM2 ADAMTSL4 INPP5F ARHGAP31 ESCO2 ADRB2 CSF1 WDHD1 GOLIM4 CDK5RAP1 CD69 GLUL HJURP SHC4 GNLY TTC9 HELLS DPP4 IL23A PITPNC1 TOX ARHGEF9 EXO1 SLC4A4 CKAP4 CARMIL3 NHSL2 DZIP3 GINS1 FUT8 UBASH3B CDCA5 PDE7B SOGA1 CDC45 NR3C2 TRIB1 KIF14 TRAF5 LIMS1 PPP1R2C TNFRSF9 KLRC2 POLA1 CD80 ATP10D CDCA8 SETD7 IER2 PATL2 CCDC141 CD84 HSPA6 CYB561 MPHOSPH9 CLSPN KLRC1 PTMS SCML4 ZBTB10 CCL3 CA5B PIP5K1B WNT9A CCNH GEM IL18RAP GGH SARDH B3GNT7 C13orf46 SBF2 IKZF3 ZMAT1 TCF7 NECTIN1 H3C7 FOS PAG1 HECA SLC4A10 SLC35G2 PER1 P2RY1 NFKBIA WDR76 PLAUR KDM1A H1-5 TSHZ2 FAM102B HMMR GPR132 CCRL2 PARP8 A2M ST8SIA1 NUF2 IL5RA RBPMS UBE2T USP53 EEF1A1 PLAC8 LGR6 TMEM123 NEK2 SNAP47 PTGIS SH2B3 P2RY8 S100PBP PLEKHA7 CLNK CRIM1 MGAT5 YBX3 TP53INP1 DTL CFH FEZ1 MYB FRMD4B TSPAN5 STIL ITGA2 GOLGA6L10 MYBL2 AHI1 CAND2 GZMB RBPJ PELI1 HSPA1B KCNK5 GOLGA6L9 TICRR TPRG1 UBE2C AURKA Leem G, et al. -

Accompanies CD8 T Cell Effector Function Global DNA Methylation
Global DNA Methylation Remodeling Accompanies CD8 T Cell Effector Function Christopher D. Scharer, Benjamin G. Barwick, Benjamin A. Youngblood, Rafi Ahmed and Jeremy M. Boss This information is current as of October 1, 2021. J Immunol 2013; 191:3419-3429; Prepublished online 16 August 2013; doi: 10.4049/jimmunol.1301395 http://www.jimmunol.org/content/191/6/3419 Downloaded from Supplementary http://www.jimmunol.org/content/suppl/2013/08/20/jimmunol.130139 Material 5.DC1 References This article cites 81 articles, 25 of which you can access for free at: http://www.jimmunol.org/content/191/6/3419.full#ref-list-1 http://www.jimmunol.org/ Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists by guest on October 1, 2021 • Fast Publication! 4 weeks from acceptance to publication *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2013 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. The Journal of Immunology Global DNA Methylation Remodeling Accompanies CD8 T Cell Effector Function Christopher D. Scharer,* Benjamin G. Barwick,* Benjamin A. Youngblood,*,† Rafi Ahmed,*,† and Jeremy M.