Virlwind a Mobile Device for User-Centered Augmented Reality
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Modbook.Com Forward-Looking Statements Should Circumstances Or Management’S Estimates Or Opinions Change
Reinventing Professional Tools for the Creative Industries All statements in this presentation, other than those of October, 2014 historical fact, are forward-looking statements that involve various risks and uncertainties, including, without limitation, statements ! regarding the future plans and objectives of the Company. These risks and uncertainties include, but are not restricted to, the need Andreas Haas for adequate financing for future acquisitions and growth efforts. There can be no assurance that such statements will prove to be CEO & Inventor accurate. Actual results and future events could differ materially from those anticipated in such statements. These and all ! subsequent written and oral forward-looking statements are based on the estimates and opinions of management on the ! dates they are made and are expressly qualified in their entirety by this notice. The Company assumes no obligation to update [email protected] forward-looking statements should circumstances or management’s estimates or opinions change. © 2014 All Rights Reserved Confidential Introduction World Class Pedigree Modbook Inc (incorporated Feb 2012) 1997 2008 2012 2014 First First Most Powerful First Workstation-class Personal Digital Assistant Tablet Mac Pen Tablet (Mac&PC) Pen Tablet (Mac&PC) Impressive Kickstarter Top 100 Success Raising $ 500K at $ 4.5M pre-money valuation Fast-track product lines (technology development complete) © 2014 All Rights Reserved Confidential The Problem © 2014 All Rights Reserved Confidential The Problem There are no -

Macworld San Francisco 2009 in Review
MACWORLD 2009 The Final Edition? Washington Apple Pi General Meeting 24 January 09 www.wap.org Presented by: Travis Good APPLE PRODUCTS iLife ‘09 iPhoto ’09 iMovie ’09 iWeb ‘09 Garage Band ‘09 iPhoto ‘09 Faces Places Slideshow Themes Facebook and Flickr Support Resource Link Faces: face-detection and facial-recognition technology to automatically detect the faces of people in the pictures you take and determine which photos include the same faces. You can assign a name to a particular face, and iPhoto lets you quickly view all photos that include that person. Places: uses geotagging—GPS-based location-finding technology to determine locations; but can manually add locations using iPhoto's database of place names. You can then browse photos by location using a map with pins showing where your photos are located. Integration with Facebook and Flickr. New slideshow themes and the ability to export slideshows as videos for iTunes, iPods, or iPhones; and uses face detection technology to position faces in the middle of the screen during slideshows. iMovie ‘09 Image Stabilization Dynamic Themes Precision Editor Advanced Drag and Drop Video Effects Resource Link Image Stabilization: Helps reduce motion in shaky video. Dynamic Themes: Context-sensitive menus for clips, along with animated travel maps. Precision Editor: Video and audio Advanced Drag and Drop: For placing video wherever you want it in the timeline. Video Effects: Brings back special effects to iMovie iWeb ‘09 Drag and Drop Widgets Publish to any Server Update Facebook Resource Link - Drag and drop widgets: RSS feeds, iSight photos and videos, Google maps, a countdown timer, YouTube videos, HTML snippets - Publish using FTP - Update Facebook when changes GarageBand ‘09 Learn to Play Guitar Piano Resource Link GarageBand '09 - Learn to Play: Teaches how to play an instrument with video instruction from professionals/celebrities. -

MACWORLD 1 Working Mac 64 Unleash Google Drive Use Google’S Web Productivity Suite Effectively, with These Tips
You like the way it looks. You’ll love the way it feels. The award-winning design, quality craftsmanship and unprecedented performance of a Big Ass Fan® are always in style. Hidden behind a seamless fit and finish, Haiku’s revolutionary motor features Whoosh®, a proprietary algorithm that simulates a natural breeze to keep you feeling up to 40% cooler*. This Big Ass Fan is recognized by Popular Science as the world’s quietest ceiling fan and rated by ENERGY STAR® as the world’s most energy efficient. With 16 unique brightness settings and a digital dimmer, Haiku’s patent-pending LED module delivers 80% greater efficiency than traditional bulbs over a lifespan of 50,000 hours. Visit haikufan.com/OFFER and use promo code MW314 to receive a free Haiku® info kit. HAIKUFAN.COM/OFFER 877-835-9115 *Human thermal sensation to air movement frequency, Yizai Xia, Rongyi Zhao and Weiquan Xu (2000) Incorporating MacUser MARCH 2014 Features 42 What Everyone Should 12 Know About OS X Mavericks Get up to speed with the most useful new features of Apple’s latest operating system. 57 Mac Buying Guide We compare the features of Apple’s six current computers, to help you pick the right one. Opinion 5 From the Editor’s Desk The real enemy is complacency. 10 Feedback Readers respond. MacUser 12 New Mac Pro Really Is for Pros Apple’s new desktop computer is surprisingly small—and powerful. 18 Why Apple Put Maps in Mavericks 20 Consumer Faith in Apple Shaken 22 Orientation-Neutral USB Cables 24 Apple Buys Topsy, PrimeSense 25 Apple Wins $290 Million Suit PLUS: Hot Stuff 26 28 Mac Gems Apps for desktop Pandora, background sounds, and more. -

ESTTA800156 02/08/2017 in the UNITED STATES PATENT and TRADEMARK OFFICE BEFORE the TRADEMARK TRIAL and APPEAL BOARD Proceeding 9
Trademark Trial and Appeal Board Electronic Filing System. http://estta.uspto.gov ESTTA Tracking number: ESTTA800156 Filing date: 02/08/2017 IN THE UNITED STATES PATENT AND TRADEMARK OFFICE BEFORE THE TRADEMARK TRIAL AND APPEAL BOARD Proceeding 91220591 Party Plaintiff TCT Mobile International Limited Correspondence SUSAN M NATLAND Address KNOBBE MARTENS OLSON & BEAR LLP 2040 MAIN STREET , 14TH FLOOR IRVINE, CA 92614 UNITED STATES [email protected], [email protected] Submission Motion to Amend Pleading/Amended Pleading Filer's Name Jonathan A. Hyman Filer's e-mail [email protected], [email protected] Signature /jhh/ Date 02/08/2017 Attachments TCLC.004M-Opposer's Motion for Leave to Amend Notice of Opp and Motion to Suspend.pdf(1563803 bytes ) TCLC.004M-AmendNoticeofOpposition.pdf(1599537 bytes ) TCLC.004M-NoticeofOppositionExhibits.pdf(2003482 bytes ) EXHIBIT A 2/11/2015 Moving Definition and More from the Free MerriamWebster Dictionary An Encyclopædia Britannica Company Join Us On Dictionary Thesaurus Medical Scrabble Spanish Central moving Games Word of the Day Video Blog: Words at Play My Faves Test Your Dictionary SAVE POPULARITY Vocabulary! move Save this word to your Favorites. If you're logged into Facebook, you're ready to go. 13 ENTRIES FOUND: moving move moving average moving cluster movingcoil movingiron meter moving pictureSponsored Links Advertise Here moving sidewalkKnow Where You Stand moving staircaseMonitor your credit. Manage your future. Equifax Complete™ Premier. fastmovingwww.equifax.com -

Maccompanion February 2007
© MPN, LLC 2007 macCompanion Page 2 February 2007, Volume 5 Issue 2 Publisher Robert L. Pritchett from MPN, LLC Editor-in-Chief Robert L. Pritchett Editor Mike Hubbartt macCompanion Assistant Editor Harry (doc) Babad February 2007 Consultant Ted Bade Advertising and Marketing Wayne Lefevre Web Administrator James Meister This issue we talk about MacWorld Expo Desktop Publishing Mike Hubbartt 2007. We will review many of new or Graphics Design Michele Patterson, James Meister Contacts Webmaster at macCompanion dot com updated products - from Apple and third Feedback at macCompanion dot com party vendors - announced at the show in rpritchett at macCompanion dot com the upcoming issues of macCompanion. Correspondence macCompanion 1952 Thayer, Drive One of macCompanion’s staff writers - Richland, WA 99352 USA Eddie Hargreaves - attended the show and Telephone: 1-509-210-0217 gives his perspective of MacWorld Expo. 1-888-684-2161 We think you’ll enjoy Rick Sutcliffe’s macCompanion Contributors Harry {doc} Babad regular monthly column, which focuses Ted Bade on the show, and a couple of our columns Matt Brewer (MacFanatic) also focus on the keynote topics. Richard Campbell Ken Crockett (Apple News Now) During Steve Jobs much anticipated key- Kale Feelhaver (AppleMacPunk) note speech, he did reveal several items Dr. Eric Flescher of interest: tv, the iPhone and a new Eddie Hargreaves company name - Apple, Inc. Jonathan Hoyle III Mike Hubbartt What we didn’t hear about at MacWorld Daphne Kalfon (I Love My Mac) Expo were things we’ve come to expect: Wayne Lefevre new or updated hardware and software. Daniel MacKenzie We’re sure Apple has a few surprises Derek Meier planned for the immediate future, like the Michele Patterson new iPod shuffles (now in blue, green, Robert Pritchett orange and pink) announced 1/30/07. -

Notes on GPS, GNSS, and GIS for Cavers
Notes on GPS, GNSS, and GIS for Cavers William R. (Bill) Elliott, [email protected] Overview Here are some notes on tablets, cell phones, GPS (Global Positioning System), and apps that cavers might use for cave projects, especially apps that are free or not too pricey. GPS and GIS (Geographic Information System) are my sub-hobby within caving. I recently experimented with the Bad Elf GPS Pro and a Windows tablet among other things. The procedures to make these things work together are not completely spelled out in the user manuals, so I had to figure things out by testing. New devices are coming on the market. Maybe this article will save readers some time, and I welcome discussion of these topics. GPS, GNSS, and GLONASS Cavers use all sorts of GPS devices to record cave locations. Your iPhone or iPad will work, but your accuracy may be limited to ±10 m, that is within a radius of 10 m or 33 ft., but you can improve on that. Since the iPhone 4S model your iPhone can use both GPS (American) and GLONASS (Russian) satellite signals, both of which are part of the GNSS (Global Navigation Satellite System). You just need an app that gives you the best precision your phone can achieve. See more below. Nowadays a cell phone or handheld “GPS” receiver may achieve about ±3 m accuracy with WAAS (Wide Area Augmentation System) correction and “waypoint averaging.” Some units now display basic topographic maps on a small screen. See Other Apps below for details. For a project where you are accurately locating cave and karst features, it’s nice to be able to see where you are on a standard topographic map while you are away from internet networks. -
The One and Only Tablet Mac® the Axiotron™ Modbook™ Is a Revolutionary Slate-Style Tablet Mac That Enables Users to Draw and Write Directly on the Screen
The One and Only Tablet Mac® The Axiotron™ Modbook™ is a revolutionary slate-style tablet Mac that enables users to draw and write directly on the screen. Axiotron’s innovative design and manufacturing process converts an Apple® MacBook® computer into a complete tablet solution, the Axiotron Modbook, while retaining Apple MacBook functionality. Built for artists, mobile users, students and professionals, the Modbook’s condensed form factor and integrated pen-based user experience offer unprecedented flexibility and control over the creative process. Handwriting recognition built into Mac OS® X Leopard® converts handwriting into printed text in every application and provides extended system control through gesture recognition. Designed in California by Axiotron’s team of American and German engineers, the Modbook comes standard with built-in iSight® cam- era, integrated 24x Combo drive or 8x SuperDrive and full Apple MacBook connectivity via Gigabit Ethernet, USB 2.0, FireWire® 400, Bluetooth™ 2.0 and AirPort Extreme®. The Modbook is the only portable Mac solution that also features a built-in Global Positioning System (GPS). Slate-style Tablet Mac State-of-the-Art Pen Input Ideal for artists, mobile users, The Modbook uses Penabled® digitizer technology from Wacom®, the in- students and professionals. dustry leader in graphics tablets for professional artists. The Axiotron Digitizer Pen provides an intuitive, comfortable and flexible way to control your digital environment. Modified Apple MacBook Retains MacBook functionality in As you draw in applications such as Adobe® Photoshop® and Corel® Painter™ a unique tablet computer. the pen’s 512 levels of pressure sensitivity – twice the capability of any tablet PC – deliver precise and delicate control of renderings. -

Mac Rewind Das Wöchentliche Magazin Für Apple- Und Technikfans
Mac Rewind Das wöchentliche Magazin für Apple- und Technikfans Ausgabe 1 / 2007 Inhalt Editorial .............................................................. 2 Streichelmaus im Designerpelz ......................3 An Eye for an EyeTV ............................................ 9 Stories & Updates .............................................. 10 Bilder der Woche ............................................... 12 Impressum ......................................................... 13 © Synium Software GmbH 2007 Liebe Leser Neues Jahr, neues Spiel. Wie so oft gehen mit dem Jahreswechsel so man- che Änderungen einher, die unser Le- ben beeinflusst. Egal, ob höhere Steu- ern, neue Gesetze, oder vielleicht auch nur, dass man mit dem Rauchen auf- gehört hat (oder zumindest will); der Jahresanfang ist traditionell die Zeit für Neuanfänge und Umbrüche. Mac Rewind fängt nicht von vorne an, aber mit dieser Ausgabe haben wir unser Design etwas überarbeitet und die Nummerierung vereinfacht. Das ist nicht revolutionär, setzt aber ein deutliches Zeichen, dass Mac Rewind sich weiter entwickelt. Die ”Bilder der Woche“ auf der vorletzten Seite haben schon vor dem Jahreswechsel den An- fang gemacht. Das Format – DIN A4 Quer – hat sich bestens bewährt und wird somit beibehalten. Nun können wir uns wieder voll auf das Wesentliche konzentrieren und Ihnen hoffentlich viele interessante News und aufschlussreiche Praxistests im Laufe des Jahres 2007 präsentieren. Herzlichst Ihr Frank Borowski alias sonorman EDITORIAL Seite 2 Streichelmaus im Designerpelz Saitek Schnurlosmaus Obsidian im Praxistest bsidian ist ein natürlich vor- das ansonsten harmonische Ambi- ovales Fen- des Okommendes, vulkanisches ente zerstört. Nicht selten wurde bei ster dem Rech- Gesteinsglas. Es entsteht bei ra- diesen Versuchen jedoch die Ergo- Kunden im La- ners an- scher Abkühlung von Laven mit nomie außer acht gelassen und die den ihren Inhalt. stöpseln. Der einem Massenanteil an Wasser Funktion der Form untergeordnet. -

MBI-WF17 Offering Pitchdeck 201708A.Key
Modbook Inc 2017 Crowdfunding Campaign Offering PitchDeck August 2017 wefunder.com/modbook © 2017 All Rights Reserved MBI-WF17 Offering PitchDeck 201708a < Legal Disclaimer > Slide 2 of 24 Legal Disclaimer All statements in this presentation, other than those of historical fact, are forward-looking statements that involve various risks and uncertainties, including, without limitation, statements regarding the future plans and objectives of the Company. These risks and uncertainties include, but are not restricted to, the need for adequate financing for future acquisitions and growth efforts. There can be no assurance that such statements will prove to be accurate. Actual results and future events could differ materially from those anticipated in such statements. These and all subsequent written and oral forward-looking statements are based on the estimates and opinions of management on the dates they are made and are expressly qualified in their entirety by this notice. The Company assumes no obligation to update forward-looking statements should circumstances or management’s estimates or opinions change. © 2017 All Rights Reserved < Introduction > Slide 3 of 24 Introduction World Class Pedigree Modbook Inc (incorporated Feb 2012) 1998 2007 2012 2017 Andreas Haas, Apple 1st. Gen. Modbook 2nd. Gen. Modbook Pro 3rd. Gen. Modbook Pro X ready Newton Biz Unit Manager wins Best-of-Show launched to pave the way to become most powerful tablet Top100 Success Modbook Pro X only solution for a $1.9b pen hardware market opportunity Established consumer -
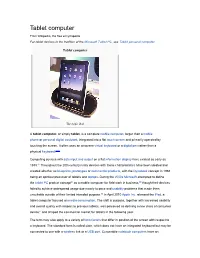
Tablet Computer
Tablet computer From Wikipedia, the free encyclopedia For tablet devices in the tradition of the Microsoft Tablet PC, see Tablet personal computer. Tablet computer The Apple iPad A tablet computer, or simply tablet, is a complete mobile computer, larger than a mobile phone or personal digital assistant, integrated into a flat touch screen and primarily operated by touching the screen. It often uses an onscreen virtual keyboard or a digital pen rather than a physical keyboard.[1][2] Computing devices with data input and output on a flat information display have existed as early as 1888.[3] Throughout the 20th century many devices with these characteristics have been ideated and created whether as blueprints, prototypes or commercial products, with the Dynabook concept in 1968 being an spiritual precursor of tablets and laptops. During the 2000s Microsoft attempted to define the tablet PC product concept[4] as a mobile computer for field work in business,[5] though their devices failed to achieve widespread usage due mainly to price and usability problems that made them unsuitable outside of their limited intended purpose.[6] In April 2010 Apple Inc. released the iPad, a tablet computer focused on media consumption. The shift in purpose, together with increased usability and overall quality with respect to previous tablets, was perceived as defining a new class of consumer device[7] and shaped the commercial market for tablets in the following year. The term may also apply to a variety of form factors that differ in position of the screen with respect to a keyboard. The standard form is called slate, which does not have an integrated keyboard but may be connected to one with a wireless link or a USB port. -

Virtual Reality Elimination of Unsightly Cables
PREFACE Everyday innumerable technologies are invented and developed all over the world in many fields. Added to this, many technologies have resulted in failure also. One, who is born, has to die one day. During this short span of life, the thrust for new technologies and developments have not quenched yet. As a result of this, many latest technologies were introduced. This magazine “ INFOLINE ” was aimed to provide basic necessary information about the latest technologies developed and it also creates awareness to the one who is reading this. Your comments and valuable suggestions for the improvement from the students, teachers and friends are warmly welcomed and will be gratefully acknowledged. Infoline Team | Acknowledgement We wish to thank Thiru A.Venkatachalam B.Sc., Correspondent, Kongu Arts And Science College, Erode and our Management for the support to publish the magazine Dr.N.Raman M.B.A., M.Com., M.Phil., B.Ed., PGDCA.,Ph.D., Principal, Kongu Arts And Science College, Erode has provided considerable support to us during this effort. We proudly thank our Chief Editor, Staff Advisor, Staff Members and the students of Department of Computer Technology and Information Technology for their guidance and suggestions to complete this magazine. Infoline Team | INFOLINE TECHNOLOGY NAVIGATOR Executive Committee Chief Patron : Thiru A.Venkatachalam B.Sc., Patron : Dr. N.Raman M.B.A., M.Com., M.Phil., B.Ed., PGDCA.,Ph.D., Editor in Chief : S.Muruganantham M.Sc., M.Phil., Staff Advisor: M.G.Annapoorani M.Sc., Assistant Professor, Department of CT & IT. Staff Editor: V.Dharani M.C.A., Assistant Professor, Department of CT & IT.