Advanced Research on Electronic Commerce, Part 1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Read Ebook {PDF EPUB} Tang China and the Collapse of the Uighur Empire a Documentary History by Michael R
Read Ebook {PDF EPUB} Tang China And The Collapse Of The Uighur Empire A Documentary History by Michael R. Drompp Tang China And The Collapse Of The Uighur Empire: A Documentary History by Michael R. Drompp. Our systems have detected unusual traffic activity from your network. Please complete this reCAPTCHA to demonstrate that it's you making the requests and not a robot. If you are having trouble seeing or completing this challenge, this page may help. If you continue to experience issues, you can contact JSTOR support. Block Reference: #640642a0-d013-11eb-8743-0da9024df238 VID: #(null) IP: 116.202.236.252 Date and time: Fri, 18 Jun 2021 08:58:46 GMT. Tang China And The Collapse Of The Uighur Empire: A Documentary History by Michael R. Drompp. Our systems have detected unusual traffic activity from your network. Please complete this reCAPTCHA to demonstrate that it's you making the requests and not a robot. If you are having trouble seeing or completing this challenge, this page may help. If you continue to experience issues, you can contact JSTOR support. Block Reference: #6411db60-d013-11eb-acd7-7bc3fb1b8127 VID: #(null) IP: 116.202.236.252 Date and time: Fri, 18 Jun 2021 08:58:46 GMT. The Destruction of the Medieval Chinese Aristocracy. In 845, Li Deyu 李德裕 (787–850), arguably the most powerful man of the realm at that time and scion of one of the great aristocratic clans of medieval China, submitted a ‘Stele Inscription for Commemorating the Sagely Deeds in Youzhou, with preface’ (‘Youzhou ji shenggong beiming bing xu’ 幽州紀聖功碑銘并序) to Emperor Li Yan 李炎 (r. -

Research on Talent Demand of Key Supporting Industries in Henan Province—Taking the Medical Industry As an Example
Creative Education, 2018, 9, 2604-2614 http://www.scirp.org/journal/ce ISSN Online: 2151-4771 ISSN Print: 2151-4755 Research on Talent Demand of Key Supporting Industries in Henan Province—Taking the Medical Industry as an Example Fang Cheng, Lu Wang, Qianqian Wang, Yanjie Fan, Hui Gao, Baojian Dong School of Business, Anyang Normal University, Anyang, China How to cite this paper: Cheng, F., Wang, Abstract L., Wang, Q. Q., Fan, Y. J., Gao, H., & Dong, B. J. (2018). Research on Talent As an important part of China’s national economy, the medical industry is a Demand of Key Supporting Industries in key support industry in Henan Province. In order to gain an advantage in the Henan Province—Taking the Medical fierce competition in the medical industry, the key lies in talents. Based on Industry as an Example. Creative Educa- tion, 9, 2604-2614. the development status and environment of Henan medical industry and the https://doi.org/10.4236/ce.2018.915196 demand of talents in Henan medical industry, this paper analyzes the prob- lems of talent demand in Henan medical industry and puts forward some Received: November 1, 2018 Accepted: November 20, 2018 suggestions for supporting the development of Henan medical industry. Published: November 23, 2018 Keywords Copyright © 2018 by authors and Scientific Research Publishing Inc. Henan Province, Medical Industry, R&D Talent, Marketing Talent This work is licensed under the Creative Commons Attribution International License (CC BY 4.0). http://creativecommons.org/licenses/by/4.0/ 1. Introduction Open Access With the economic development of all countries in the world, especially the economic development of emerging markets, and the improvement of people’s living standards, the global medical expenditure keeps increasing, which strong- ly promotes the development of the medical industry. -

Adaptive Fuzzy Pid Controller's Application in Constant Pressure Water Supply System
2010 2nd International Conference on Information Science and Engineering (ICISE 2010) Hangzhou, China 4-6 December 2010 Pages 1-774 IEEE Catalog Number: CFP1076H-PRT ISBN: 978-1-4244-7616-9 1 / 10 TABLE OF CONTENTS ADAPTIVE FUZZY PID CONTROLLER'S APPLICATION IN CONSTANT PRESSURE WATER SUPPLY SYSTEM..............................................................................................................................................................................................................1 Xiao Zhi-Huai, Cao Yu ZengBing APPLICATION OF OPC INTERFACE TECHNOLOGY IN SHEARER REMOTE MONITORING SYSTEM ...............................5 Ke Niu, Zhongbin Wang, Jun Liu, Wenchuan Zhu PASSIVITY-BASED CONTROL STRATEGIES OF DOUBLY FED INDUCTION WIND POWER GENERATOR SYSTEMS.................................................................................................................................................................................9 Qian Ping, Xu Bing EXECUTIVE CONTROL OF MULTI-CHANNEL OPERATION IN SEISMIC DATA PROCESSING SYSTEM..........................14 Li Tao, Hu Guangmin, Zhao Taiyin, Li Lei URBAN VEGETATION COVERAGE INFORMATION EXTRACTION BASED ON IMPROVED LINEAR SPECTRAL MIXTURE MODE.....................................................................................................................................................................18 GUO Zhi-qiang, PENG Dao-li, WU Jian, GUO Zhi-qiang ECOLOGICAL RISKS ASSESSMENTS OF HEAVY METAL CONTAMINATIONS IN THE YANCHENG RED-CROWN CRANE NATIONAL NATURE RESERVE BY SUPPORT -

Recent Articles from the China Journal of System Engineering Prepared
Recent Articles from the China Journal of System Engineering Prepared by the University of Washington Quantum System Engineering (QSE) Group.1 Bibliography [1] Mu A-Hua, Zhou Shao-Lei, and Yu Xiao-Li. Research on fast self-adaptive genetic algorithm and its simulation. Journal of System Simulation, 16(1):122 – 5, 2004. [2] Guan Ai-Jie, Yu Da-Tai, Wang Yun-Ji, An Yue-Sheng, and Lan Rong-Qin. Simulation of recon-sat reconing process and evaluation of reconing effect. Journal of System Simulation, 16(10):2261 – 3, 2004. [3] Hao Ai-Min, Pang Guo-Feng, and Ji Yu-Chun. Study and implementation for fidelity of air roaming system above the virtual mount qomolangma. Journal of System Simulation, 12(4):356 – 9, 2000. [4] Sui Ai-Na, Wu Wei, and Zhao Qin-Ping. The analysis of the theory and technology on virtual assembly and virtual prototype. Journal of System Simulation, 12(4):386 – 8, 2000. [5] Xu An, Fan Xiu-Min, Hong Xin, Cheng Jian, and Huang Wei-Dong. Research and development on interactive simulation system for astronauts walking in the outer space. Journal of System Simulation, 16(9):1953 – 6, Sept. 2004. [6] Zhang An and Zhang Yao-Zhong. Study on effectiveness top analysis of group air-to-ground aviation weapon system. Journal of System Simulation, 14(9):1225 – 8, Sept. 2002. [7] Zhang An, He Sheng-Qiang, and Lv Ming-Qiang. Modeling simulation of group air-to-ground attack-defense confrontation system. Journal of System Simulation, 16(6):1245 – 8, 2004. [8] Wu An-Bo, Wang Jian-Hua, Geng Ying-San, and Wang Xiao-Feng. -

The Structure and Circulation of the Elite in Late-Tang China
elite in late-tang china nicolas tackett Great Clansmen, Bureaucrats, and Local Magnates: The Structure and Circulation of the Elite in Late-Tang China he predominant paradigm describing Chinese elite society of the T first millennium ad was defined thirty years ago in carefully re- searched studies by Patricia Ebrey and David Johnson, both of whom partly built upon the foundation of earlier scholarship by Takeda Ryˆji 竹田龍兒, Moriya Mitsuo 守屋美都雄, Niida Noboru 仁井田陞, Sun Guodong 孫國棟, Mao Hanguang 毛漢光, and others.1 According to this model, a circumscribed number of aristocratic “great clans” were able to maintain their social eminence for nearly a thousand years while simultaneously coming to dominate the upper echelons of the government bureaucracy. The astonishing longevity of these families was matched in remarkability only by their sudden and complete disap- pearance after the fall of the Tang at the turn of the tenth century. In their place, a new civil-bureaucratic scholar-elite came to the fore, an elite described in enormous detail first by Robert Hartwell and Robert I would like to thank the anonymous reviewers for their very helpful comments, as well as all of the participants in the 2007 AAS panel where I first presented this paper, notably the discussants Robert Hymes and Beverly Bossler. To minimize the number of footnotes, references for epitaphs of individuals are not included in the main text and notes, but in- stead can be found in the appendix. All tables are located at the end of the article, after the appendix. 1 David Johnson, “The Last Years of a Great Clan: The Li Family of Chao chün in Late T’ang and Early Sung,” H JAS 37.1 (1977), pp. -

A Complete Collection of Chinese Institutes and Universities For
Study in China——All China Universities All China Universities 2019.12 Please download WeChat app and follow our official account (scan QR code below or add WeChat ID: A15810086985), to start your application journey. Study in China——All China Universities Anhui 安徽 【www.studyinanhui.com】 1. Anhui University 安徽大学 http://ahu.admissions.cn 2. University of Science and Technology of China 中国科学技术大学 http://ustc.admissions.cn 3. Hefei University of Technology 合肥工业大学 http://hfut.admissions.cn 4. Anhui University of Technology 安徽工业大学 http://ahut.admissions.cn 5. Anhui University of Science and Technology 安徽理工大学 http://aust.admissions.cn 6. Anhui Engineering University 安徽工程大学 http://ahpu.admissions.cn 7. Anhui Agricultural University 安徽农业大学 http://ahau.admissions.cn 8. Anhui Medical University 安徽医科大学 http://ahmu.admissions.cn 9. Bengbu Medical College 蚌埠医学院 http://bbmc.admissions.cn 10. Wannan Medical College 皖南医学院 http://wnmc.admissions.cn 11. Anhui University of Chinese Medicine 安徽中医药大学 http://ahtcm.admissions.cn 12. Anhui Normal University 安徽师范大学 http://ahnu.admissions.cn 13. Fuyang Normal University 阜阳师范大学 http://fynu.admissions.cn 14. Anqing Teachers College 安庆师范大学 http://aqtc.admissions.cn 15. Huaibei Normal University 淮北师范大学 http://chnu.admissions.cn Please download WeChat app and follow our official account (scan QR code below or add WeChat ID: A15810086985), to start your application journey. Study in China——All China Universities 16. Huangshan University 黄山学院 http://hsu.admissions.cn 17. Western Anhui University 皖西学院 http://wxc.admissions.cn 18. Chuzhou University 滁州学院 http://chzu.admissions.cn 19. Anhui University of Finance & Economics 安徽财经大学 http://aufe.admissions.cn 20. Suzhou University 宿州学院 http://ahszu.admissions.cn 21. -

FORMATO PDF Ranking Instituciones Acadã©Micas Por Sub Ã
Ranking Instituciones Académicas por sub área OCDE 2020 3. Ciencias Médicas y de la Salud > 3.02 Medicina Clínica PAÍS INSTITUCIÓN RANKING PUNTAJE USA Harvard University 1 5,000 CANADA University of Toronto 2 5,000 USA Johns Hopkins University 3 5,000 USA University of Pennsylvania 4 5,000 USA University of California San Francisco 5 5,000 UNITED KINGDOM University College London 6 5,000 USA Duke University 7 5,000 USA Stanford University 8 5,000 USA University of California Los Angeles 9 5,000 USA University of Washington Seattle 10 5,000 USA Yale University 11 5,000 USA University of Pittsburgh 12 5,000 USA University of Michigan 13 5,000 AUSTRALIA University of Sydney 14 5,000 USA Columbia University 15 5,000 USA Washington University (WUSTL) 16 5,000 USA Emory University 17 5,000 UNITED KINGDOM Imperial College London 18 5,000 USA Northwestern University 19 5,000 USA University of California San Diego 20 5,000 USA Vanderbilt University 21 5,000 GERMANY Ruprecht Karls University Heidelberg 22 5,000 SWEDEN Karolinska Institutet 23 5,000 USA Cornell University 24 5,000 BELGIUM KU Leuven 25 5,000 UNITED KINGDOM University of Oxford 26 5,000 USA Icahn School of Medicine at Mount Sinai 27 5,000 USA University of North Carolina Chapel Hill 28 5,000 FRANCE Sorbonne Universite 29 5,000 UNITED KINGDOM Kings College London 30 5,000 USA Ohio State University 31 5,000 FRANCE Universite Sorbonne Paris Cite-USPC (ComUE) 32 5,000 USA University of Colorado Health Science Center 33 5,000 SOUTH KOREA Seoul National University (SNU) 34 5,000 NETHERLANDS -

University of Leeds Chinese Accepted Institution List 2021
University of Leeds Chinese accepted Institution List 2021 This list applies to courses in: All Engineering and Computing courses School of Mathematics School of Education School of Politics and International Studies School of Sociology and Social Policy GPA Requirements 2:1 = 75-85% 2:2 = 70-80% Please visit https://courses.leeds.ac.uk to find out which courses require a 2:1 and a 2:2. Please note: This document is to be used as a guide only. Final decisions will be made by the University of Leeds admissions teams. -
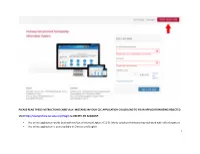
1 Please Read These Instructions Carefully
PLEASE READ THESE INSTRUCTIONS CAREFULLY. MISTAKES IN YOUR CSC APPLICATION COULD LEAD TO YOUR APPLICATION BEING REJECTED. Visit http://studyinchina.csc.edu.cn/#/login to CREATE AN ACCOUNT. • The online application works best with Firefox or Internet Explorer (11.0). Menu selection functions may not work with other browsers. • The online application is only available in Chinese and English. 1 • Please read this page carefully before clicking on the “Application online” tab to start your application. 2 • CLIC on the Edit Personal Details button. 3 • Fill out your personal information accurately. o Make sure to have a valid passport at the time of your application. o Use the name and date of birth that are on your passport. Use the name on your passport for all correspondences with the CLIC office or Chinese institutions. o List Canadian as your Nationality, even if you have dual citizenship. Only Canadian citizens are eligible for CLIC support. o Enter the mailing address for where you want your admission documents to be sent under Permanent Address. Leave Current Address blank. o Once you have completed this section click Verify and Save. 4 • Fill out your Education and Employment History accurately. o For Highest Education enter your current degree studies. o Once you have completed this section, click Verify and Save. 5 • Provide the contact information of the host Chinese university. o The contact information for summer programs is available on the CLIC website in the Program Finder. o For exchange programs, please contact your home university international office to get your host university contact information (http://clicstudyinchina.com/contact-us/). -

1. Brief Introduction to the Institute of Geology
-1- The Institute of Geology, Chinese Academy of Geological Sciences (CAGS) Preface The Institute of Geology, Chinese Academy of Geological Sciences (CAGS), is a national public scientific research institution and is mainly engaged in national fundamental, public, strategic and frontier geological survey and geoscientific research. Entering the new century, and in particular during the past 5 years, the Institute has made notable progress in scientific research, personnel training and international cooperation, with increasing cooperation and exchange activities, expanded fields of cooperation, abundant output of new research results, and an increased number of papers published in “Nature”, “Science” and other high-impact international scientific journals. In the light of this new situation and in order to publicize, in a timely manner, annual progress and achievements of the Institute to enhance its international reputation, an English version of the Institute’s Annual Report has been published since 2010. Similar to previous reports, the Annual Report 2015 includes the following 7 parts: (1) Introduction to the Institute of Geology, CAGS; (2) Ongoing Research Projects; (3) Research Achievements and Important Progress; (4) International Cooperation and Academic Exchange; (5) Important Academic Activities in 2015; (6) Postgraduate Education; (7) Publications. In order to avoid confusion in the meaning of Chinese and foreign names, all family names in this Report are capitalized. We express our sincere gratitude to colleagues of related research departments and centers of the Institute for their support and efforts in compiling this Report and providing related material – a written record of the hard work of the Institute’s scientific research personnel for the year 2015. -

Electronic Supporting Information
Electronic Supplementary Material (ESI) for Physical Chemistry Chemical Physics. This journal is © the Owner Societies 2017 Electronic Supporting Information Interaction between H2O, N2, CO, NO, NO2 and N2O molecules and the defective WSe2 monolayer Dongwei Ma1,, Benyuan Ma2, Zhiwen Lu2, Chaozheng He2,, Yanan Tang3,, Zhansheng Lu4 and Zongxian Yang4 1School of Physics, Anyang Normal University, Anyang 455000, China 2Physics and Electronic Engineering College, Nanyang Normal University, Nanyang 473061, China 3College of Physics and Electronic Engineering, Zhengzhou Normal University, Zhengzhou, 450044, China 4College of Physics and Materials Science, Henan Normal University, Xinxiang 453007, China Corresponding author. E-mail: [email protected] (Dongwei Ma). Corresponding author. E-mail: [email protected] (Chaozheng He). Corresponding author. E-mail: [email protected] (Yanan Tang). Table S1. The nearest atomic distance (d in Å) between the adsorbed molecule and the VSe surface for the physisorption state. From the reference (Dalton Transactions, 2008 (21): 2832-2838), the sum of the covalent radii of C, N, or O and W (Se) atoms is about 2.3 (1.9) Å, and that of H and W (Se) atoms is about 1.9 (1.5) Å. molecule H2O N2 CO NO NO2 N2O d 3.17 3.95 3.71 3.36 3.35 3.50 Fig. S1. The top and side views of the pristine WSe2 monolayer with the physisorbed H2O (a) and N2 (b) molecules. The adsorption energy, the number the transferred electrons, and the height of the adsorbed molecule with respect to the upper Se atomic plane are given. The isosurfaces for the CDD are 2×10-4 and 1×10-4 e bohr-3, respectively, for the adsorption of the H2O and N2 molecules. -

Electronic Supplementary Information (ESI)
Electronic Supplementary Material (ESI) for Journal of Materials Chemistry C. This journal is © The Royal Society of Chemistry 2015 Electronic Supplementary Information (ESI) CO catalytic oxidation on Al-doped graphene-like ZnO monolayer sheets: a first-principles study Dongwei Ma1,, Qinggao Wang1, Tingxian Li1, Zhenjie Tang1, Gui Yang1, Chaozheng He2,, and Zhansheng Lu3 1School of Physics, Anyang Normal University, Anyang 455000, China 2Physics and Electronic Engineering College, Nanyang Normal University, Nanyang 473061, China 3 College of Physics and Electronic Engineering, Henan Normal University, Xinxiang 453007, China Corresponding author. E-mail: [email protected] (Dongwei Ma). Corresponding author. E-mail: [email protected] (Chaozheng He). (a) Ea = 0.02 eV (b) Ea = 0.02 eV (c) Ea = 0.02 eV d = 3.23 Å d = 3.08 Å d = 2.97 Å (d) Ea = 0.03 eV (e) Ea = 0.01 eV d = 2.91 Å d = 3.22 Å Fig. S1. Several atomic configurations for the O ((a), (b), and (c)) and CO ((d) and Fig. S1 2 (e)) adsorption on the pristine g-ZnO monolayer sheet. The nearest distance between the adsorbed molecules and the sheet, and the adsorption energies are given. 2.12 Å 1.39 Å 2.13 Å 2.14 Å 1.39 Å 2.09 Å (a) Ea = 0.86 eV (b) Ea = 1.15 eV Fig. S2. Atomic configurations of two typical states for the O2 adsorption at the sites away from the doped Al atom on the Al-g-ZnO monolayer sheet. The adsorption energies are given. Fig. S2 (a) (d) Ea = 0.13 eV Ea = 0.04 eV (b) (e) Ea = 0.24 eV Ea = 0.11 eV (c) (f) Ea = 0.15 eV Ea = 0.23 eV Fig.