Expanding the High Performance Embedded Computing Tool Chest - Mixing C and Java™
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Multiplatformní Knihovna Pro Interakci S Grafickým Uživatelským Prostředím
Masarykova univerzita Fakulta}w¡¢£¤¥¦§¨ informatiky !"#$%&'()+,-./012345<yA| Multiplatformní knihovna pro interakci s grafickým uživatelským prostředím Bakalářská práce Jaromír Kala Brno, 2014 Prohlášení Prohlašuji, že tato bakalářská práce je mým původním autorským dílem, které jsem vypracoval samostatně. Všechny zdroje, prameny a literaturu, které jsem při vypracování používal nebo z nich čerpal, v práci řádně cituji s uvedením úplného odkazu na příslušný zdroj. Jaromír Kala Vedoucí práce: RNDr. Pavel Troubil ii Poděkování Rád bych poděkoval RNDr. Pavlu Troubilovi za cenné rady, věcné připomínky a ochotu při konzultacích a vypracování bakalářské práce. iii Shrnutí Cílem bakalářské práce bylo vytvořit multiplatformní knihovnu pro manipulaci s grafickým uživatelským rozhraním. Vzniklá knihovna WDDMan podporuje detekci připojených monitorů a jejich rozlišení, zjištění otevřených oken a manipulaci s nimi (zavření, změny velikostí a přesuny) a detekci virtuálních ploch. Knihovna WDDMan funguje na operačních systémech skupiny Windows, Linux a Mac OS. Kni- hovna s podobnou funkcionalitou doposud nebyla k dispozici a bude použita v middleware CoUniverse pro manipulaci s objekty videokon- ferenčních nástrojů. Prostředí CoUniverse se využije pro vzdálené tlu- močení přednášek pro Středisko pro pomoc studentům se specifickými nároky Masarykovy univerzity. Knihovna WDDMan bude zveřejněna pod otevřenou licencí k volnému užití. Součástí knihovny je i anglická dokumentace a ukázkový a testovací příklad. iv Klíčová slova CoUniverse, Windows API, XLib, JNA, AppleScript, GUI v Obsah 1 Úvod ...............................2 2 Popis použitých technologií .................4 2.1 Java Native Access .....................4 2.1.1 Popis knihovny Java Native Access . .4 2.1.2 Použití JNA v knihovně WDDMan . .7 2.2 Windows API ........................8 2.3 X Window System a Xlib .................9 2.4 AppleScript ........................ -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

T U M a Digital Wallet Implementation for Anonymous Cash
Technische Universität München Department of Informatics Bachelor’s Thesis in Information Systems A Digital Wallet Implementation for Anonymous Cash Oliver R. Broome Technische Universität München Department of Informatics Bachelor’s Thesis in Information Systems A Digital Wallet Implementation for Anonymous Cash Implementierung eines digitalen Wallets for anonyme Währungen Author Oliver R. Broome Supervisor Prof. Dr.-Ing. Georg Carle Advisor Sree Harsha Totakura, M. Sc. Date October 15, 2015 Informatik VIII Chair for Network Architectures and Services I conrm that this thesis is my own work and I have documented all sources and material used. Garching b. München, October 15, 2015 Signature Abstract GNU Taler is a novel approach to digital payments with which payments are performed with cryptographically generated representations of actual currencies. The main goal of GNU Taler is to allow taxable anonymous payments to non-anonymous merchants. This thesis documents the implementation of the Android version of the GNU Taler wallet, which allows users to create new Taler-based funds and perform payments with them. Zusammenfassung GNU Taler ist ein neuartiger Ansatz für digitales Bezahlen, bei dem Zahlungen mit kryptographischen Repräsentationen von echten Währungen getätigt werden. Das Hauptziel von GNU Taler ist es, versteuerbare, anonyme Zahlungen an nicht-anonyme Händler zu ermöglichen. Diese Arbeit dokumentiert die Implementation der Android-Version des Taler-Portemonnaies, der es Benutzern erlaubt, neues Taler-Guthaben zu erzeugen und mit ihnen Zahlungen zu tätigen. I Contents 1 Introduction 1 1.1 GNU Taler . .2 1.2 Goals of the thesis . .2 1.3 Outline . .3 2 Implementation prerequisites 5 2.1 Native libraries . .5 2.1.1 Libgcrypt . -

Developers Guide
jjPPrroodduuccttiivviittyy LLLLCC Protection User Guide Developers Guide Licensing Toolkit Protect your investments Protect your with Protection! http://www.jproductivity.com v 5 . 2 ! tm Revision 397 - 1/7/20 Notice of Copyright Published by jProductivity, LLC Copyright ©2003-2019 All rights reserved. Registered Trademarks and Proprietary Names Product names mentioned in this document may be trademarks or registered trademarks of jProductivity, LLC or other hardware, software, or service providers and are used herein for identification purposes only. Applicability This document applies to Protection! v5.2 software. 2 Protection! Developers Guide v5.2 Copyright © 2003-2019 jProductivity L.L.C. http://www. jproductivity.com Contents Contents ....................................................................................................................... 3 1. Protection! Licensing Toolkit Concepts ........................................................................... 6 1.1 Key Concepts ................................................................................................. 6 1.1.1 License File .............................................................................................. 6 1.1.2 Protection! Control Center ......................................................................... 6 1.1.3 Secret Storage ......................................................................................... 6 1.2 Protection! Process ......................................................................................... -
Third Party Version
Third Party Name Third Party Version Manufacturer License Type Comments Merge Product Merge Product Versions License details Software source autofac 3.5.2 Autofac Contributors MIT Merge Cardio 10.2 SOUP repository https://www.nuget.org/packages/Autofac/3.5 .2 Gibraltar Loupe Agent 2.5.2.815 eSymmetrix Gibraltor EULA Gibraltar Merge Cardio 10.2 SOUP repository https://my.gibraltarsoftware.com/Support/Gi Loupe Agent braltar_2_5_2_815_Download will be used within the Cardio Application to view events and metrics so you can resolve support issues quickly and easily. Modernizr 2.8.3 Modernizr MIT Merge Cadio 6.0 http://modernizr.com/license/ http://modernizr.com/download/ drools 2.1 Red Hat Apache License 2.0 it is a very old Merge PACS 7.0 http://www.apache.org/licenses/LICENSE- http://mvnrepository.com/artifact/drools/dro version of 2.0 ols-spring/2.1 drools. Current version is 6.2 and license type is changed too drools 6.3 Red Hat Apache License 2.0 Merge PACS 7.1 http://www.apache.org/licenses/LICENSE- https://github.com/droolsjbpm/drools/releases/ta 2.0 g/6.3.0.Final HornetQ 2.2.13 v2.2..13 JBOSS Apache License 2.0 part of JBOSS Merge PACS 7.0 http://www.apache.org/licenses/LICENSE- http://mvnrepository.com/artifact/org.hornet 2.0 q/hornetq-core/2.2.13.Final jcalendar 1.0 toedter.com LGPL v2.1 MergePacs Merge PACS 7.0 GNU LESSER GENERAL PUBLIC http://toedter.com/jcalendar/ server uses LICENSE Version 2. v1, and viewer uses v1.3. -

Ce0825a - Object Oriented Programming II 8: Memory, Java Native Access, Animation
CE0825a - Object Oriented Programming II 8: Memory, Java Native Access, Animation CE0825a - Object Oriented Programming II 8: Memory, Java Native Access, Animation James A Sutherland Abertay University Monday, 29th February 2016 CE0825a - Object Oriented Programming II 8: Memory, Java Native Access, Animation Memory Basics Generally, it’s just a single bunch of bytes, numbered from 0 upwards. (DEC Alpha is different!) Operating systems group them into pages, usually 4k. CE0825a - Object Oriented Programming II 8: Memory, Java Native Access, Animation Memory Basics Generally, it’s just a single bunch of bytes, numbered from 0 upwards. (DEC Alpha is different!) Operating systems group them into pages, usually 4k. CE0825a - Object Oriented Programming II 8: Memory, Java Native Access, Animation Memory Basics Generally, it’s just a single bunch of bytes, numbered from 0 upwards. (DEC Alpha is different!) Operating systems group them into pages, usually 4k. CE0825a - Object Oriented Programming II 8: Memory, Java Native Access, Animation Stacks and Heaps Usually, there is a stack – short term storage, arguments. Often where buffer overflows target: see Return Oriented Programming later on. Also a heap, for longer term allocations. Good news: Java takes care of all this for us! CE0825a - Object Oriented Programming II 8: Memory, Java Native Access, Animation Stacks and Heaps Usually, there is a stack – short term storage, arguments. Often where buffer overflows target: see Return Oriented Programming later on. Also a heap, for longer term allocations. Good news: Java takes care of all this for us! CE0825a - Object Oriented Programming II 8: Memory, Java Native Access, Animation Stacks and Heaps Usually, there is a stack – short term storage, arguments. -

MD COADS 2011 2 01.Pdf
UNIVERSIDADE TECNOLÓGICA FEDERAL DO PARANÁ – UTFPR CURSO SUPERIOR DE TECNOLOGIA EM ANÁLISE E DESENVOLVIMENTO DE SISTEMAS ANDRÉ RICARDO GNHOATO USO DA BIBLIOTECA DPLOT JR COM JAVA E UM COMPARATIVO ENTRE DUAS INTERFACES DE ACESSO: JAVA NATIVE INTERFACE E JAVA NATIVE ACCESS MEDIANEIRA 2011 ANDRE RICARDO GNHOATO USO DA BIBLIOTECA DPLOT JR COM JAVA E UM COMPARATIVO ENTRE DUAS INTERFACES DE ACESSO: JAVA NATIVE INTERFACE E JAVA NATIVE ACCESS Pré-Projeto apresentado à disciplina de Trabalho de Diplomação, do Curso Superior de Tecnologia em Análise e Desenvolvimento de Sistemas – COADS – da Universidade Tecnológica Federal do Paraná – UTFPR, como requisito parcial para obtenção do título de Tecnólogo. Orientador: Prof. Paulo Lopes de Menezes, MSc. MEDIANEIRA 2011 Ministério da Educação Universidade Tecnológica Federal do Paraná Diretoria de Graduação e Educação Profissional Curso Superior de Tecnologia em Análise e Desenvolvimento de Sistemas TERMO DE APROVAÇÃO USO DA BIBLIOTECA DPLOT JR COM JAVA E UM COMPARATIVO ENTRE DUAS INTERFACES DE ACESSO: JAVA NATIVE INTERFACE E JAVA NATIVE ACCESS Por André Ricardo Gnhoato Este Trabalho de Diplomação (TD) foi apresentado às 08:20 h do dia 29 de Novembro de 2011 como requisito parcial para a obtenção do título de Tecnólogo no Curso Superior de Tecnologia em Análise e Desenvolvimento de Sistemas, da Universidade Tecnológica Federal do Paraná, Campus Medianeira. O candidato foi arguido pela Banca Examinadora composta pelos professores abaixo assinados. Após deliberação, a Banca Examinadora considerou o trabalho aprovado. Prof. MSc. Paulo Lopes de Menezes Prof. Nelson Miguel Betzek UTFPR – Campus Medianeira UTFPR – Campus Medianeira (Orientador) (Convidado) Prof. M.Eng Juliano R Lamb Prof. -

Real-Time Resource Monitoring for Poly/ML Processes
IT 13 015 Examensarbete 15 hp Mars 2013 Real-Time Resource Monitoring for Poly/ML Processes Magnus Stenqvist Institutionen för informationsteknologi Department of Information Technology Abstract Real-Time Resource Monitoring for Poly/ML Processes Magnus Stenqvist Teknisk- naturvetenskaplig fakultet UTH-enheten Poly/ML, a run time system of the Standard ML language, has with its latest version 5.5 included a statistics feature which provides information about the running system and Besöksadress: ML programs running in that system. This feature provides information about the Ångströmlaboratoriet Lägerhyddsvägen 1 program threads running in the system, memory usages, garbage collection Hus 4, Plan 0 information and user defined data. The problem is that the statistics information is only accessible through the use of the language C. No way exist today that reads and Postadress: displays this data automatically. It would be very convenient for developers, to have Box 536 751 21 Uppsala an easy access to this statistic data, to better evaluate their ML programs running in the Poly/ML system. This report presents a Java application that collects the statistics Telefon: data of Poly/ML and displays it in a graphical environment easy to observe by the user. 018 – 471 30 03 This application will help developers develop programs with Poly/ML, by letting them Telefax: observe how their programs affect the Poly/ML run time system. 018 – 471 30 00 Hemsida: http://www.teknat.uu.se/student Handledare: Tjark Weber Ämnesgranskare: Justin Pearson Examinator: Olle Gällmo IT 13 015 Tryckt av: Reprocentralen ITC Contents 1 Introduction 2 1.1 Background . 2 1.2 Monitor programs . -

Towards a Dynamic Object Model Within Unix Processes
Published at Onward! 2015. Towards a Dynamic Object Model within Unix Processes Stephen Kell Computer Laboratory, University of Cambridge Cambridge, United Kingdom fi[email protected] Abstract Historically, the earliest Lisp and Smalltalk virtual ma- Programmers face much complexity from the co-existence chines (VMs) were conceived to eventually supplant Unix- of “native” (Unix-like) and virtual machine (VM) “man- like operating systems. For good or ill, this hasn’t happened: aged” run-time environments. Rather than having VMs re- their descendents today (including Java VMs) nearly al- place Unix processes, we investigate whether it makes sense ways occur within a Unix-like process. Although VMs’ in- for the latter to “become VMs”, by evolving Unix’s user- ternal uniformity can simplify many tasks, interoperating level services to subsume those of VMs. We survey the (little- with the wider world (including other VMs) remains an in- understood) VM-like features in modern Unix, noting com- evitable necessity—yet is a second-class concern to VM mon shortcomings: a lack of semantic metadata (“type in- implementers. The apparent abstraction gap between VMs formation”) and the inability to bind from objects “back” and the Unix “common denominator” leaves a wealth of to their metadata. We describe the design and implementa- programming tasks addressable only by manual or ad-hoc tion of a system, liballocs, which adds these capabilities in means: sharing code via brittle foreign function interfacing, a highly compatible way, and explore its consequences. sharing data (whether in memory or persistently) by manual translation between formats, and making do with a hodge- Categories and Subject Descriptors D.3.4 [Programming podge of per-silo tools for debugging, profiling and the like. -

Karol Wrótniak @Droidsonroids @GDG Wrocław
Karol Wrótniak @DroidsOnRoids @GDG Wrocław [email protected] koral-- karol-wrotniak JNI @karol.wrotniak Overview • Java Native Interface • Native: • Platform-specific shared library (.dll, .so, .dylib) • Non-hybrid mobile app, React Native • C, C++ • Call native functions from Java and vice versa • Other JVM languages supported • JNI ≠ JNA Foo.java: static { System.loadLibrary("foo"); } public native int getTextLength(String text); Foo.java: static { System.loadLibrary("foo"); } public native int getTextLength(String text); Foo.java: static { System.loadLibrary("foo"); } public native int getTextLength(String text); foo.c: #include <jni.h> JNIEXPORT jint JNICALL Java_pl_droidsonroids_ndkdemo_Foo_getTextLength( JNIEnv *env, jobject thiz, jstring text ) { return (*env)->GetStringUTFLength(env, text); } Foo.java: static { System.loadLibrary("foo"); } public native int getTextLength(String text); foo.c: #include <jni.h> JNIEXPORT jint JNICALL Java_pl_droidsonroids_ndkdemo_Foo_getTextLength( JNIEnv *env, jobject thiz, jstring text ) { return (*env)->GetStringUTFLength(env, text); } Foo.java: static { System.loadLibrary("foo"); } public native int getTextLength(String text); foo.c: #include <jni.h> JNIEXPORT jint JNICALL Java_pl_droidsonroids_ndkdemo_Foo_getTextLength( JNIEnv *env, jobject thiz, jstring text ) { return (*env)->GetStringUTFLength(env, text); } Foo.java: static { System.loadLibrary("foo"); } public native int getTextLength(String text); foo.c: #include <jni.h> JNIEXPORT jint JNICALL Java_pl_droidsonroids_ndkdemo_Foo_getTextLength( -
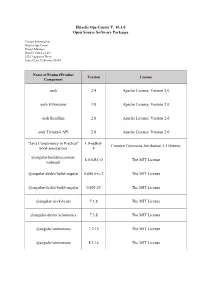
Open Source Software Packages
Hitachi Ops Center V. 10.3.0 Open Source Software Packages Contact Information: Hitachi Ops Center Project Manager Hitachi Vantara LLC 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component aesh 2.4 Apache License, Version 2.0 aesh Extensions 1.8 Apache License, Version 2.0 aesh Readline 2.0 Apache License, Version 2.0 aesh Terminal API 2.0 Apache License, Version 2.0 "Java Concurrency in Practice" 1.0-redhat- Creative Commons Attribution 2.5 Generic book annotations 4 @angular-builders/custom- 8.0.0-RC.0 The MIT License webpack @angular-devkit/build-angular 0.800.0-rc.2 The MIT License @angular-devkit/build-angular 0.803.25 The MIT License @angular-devkit/core 7.3.8 The MIT License @angular-devkit/schematics 7.3.8 The MIT License @angular/animations 7.2.15 The MIT License @angular/animations 8.2.14 The MIT License Name of Product/Product Version License Component @angular/cdk 7.3.7 The MIT License @angular/cli 8.0.0 The MIT License @angular/cli 8.3.25 The MIT License @angular/common 7.2.15 The MIT License @angular/common 8.2.14 The MIT License @angular/compiler 7.2.15 The MIT License @angular/compiler 8.2.14 The MIT License @angular/compiler-cli 8.2.14 The MIT License @angular/core 7.2.15 The MIT License @angular/forms 7.2.13 The MIT License @angular/forms 7.2.15 The MIT License @angular/forms 8.2.14 The MIT License @angular/forms 8.2.7 The MIT License @angular/language-service 8.2.14 The MIT License @angular/platform-browser 7.2.15 The MIT License Name of Product/Product Version License -

Bridging the Gap Between Haskell and Java
Bridging the Gap between Haskell and Java Julian Fleischer June 27, 2013 Abstract This thesis investigates the possibility of translating interfaces between Haskell and Java libraries. Furthermore a library and a tool are developed for invoking the virtual machine from within Haskell processes and for the automatic trans- lation of Java APIs into Haskell. In dieser Arbeit wird die M¨oglichkeit einer Ubersetzung¨ von Schnittstellen zwis- chen Haskell und Java Bibliotheken untersucht. Außerdem werden eine Bib- liothek und ein Werkzeug entwickelt um die virtuelle Maschine aus Haskell Prozessen heraus zu nutzen und um automatische Ubersetzungen¨ von Java APIs nach Haskell durchzuf¨uhren.vorgesetellt Selbstst¨andigkeitserkl¨arung Hiermit best¨atigeich, dass ich die vorliegende Ausarbeitung mit dem Titel: \Bridging the Gap between Haskell and Java" selbstst¨andigund ohne unerlaubte Hilfe angefer- tigt habe. Ich versichere, dass ich ausschließlich die angegebenen Quellen in Anspruch genommen habe. Zitate sind als solche gekennzeichnet, durch Anf¨uhrungszeichen und Fußnoten. ||||||||||| Julian Fleischer Contents 1 Introduction and Motivation5 1.1 Scope of this Thesis............................5 1.2 Organization of this Document......................5 2 Similarities and Differences between Haskell & Java7 2.1 A Brief Overview of the Haskell Programming Language........7 2.2 A Brief Overview of the Java Programming Language.........7 2.3 Syntax and Semantics...........................8 2.3.1 (Restricted) Polymorphism....................8 2.3.2 Higher-kinded Polymorphism...................9 2.3.3 Order, State, and Side Effects................... 10 2.3.4 Excecution Model......................... 10 2.4 The Awkward Squad............................ 12 2.4.1 Exceptions............................. 12 2.4.2 The Java Virtual Machine..................... 13 2.4.3 Haskell Implementations.....................