Recovering Residual Forensic Data from Smartphone Interactions with Cloud Storage Providers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Uila Supported Apps
Uila Supported Applications and Protocols updated Oct 2020 Application/Protocol Name Full Description 01net.com 01net website, a French high-tech news site. 050 plus is a Japanese embedded smartphone application dedicated to 050 plus audio-conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also 10086.cn classifies the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese web portal operated by YLMF Computer Technology Co. Chinese cloud storing system of the 115 website. It is operated by YLMF 115.com Computer Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr Korean shopping website 11st. It is operated by SK Planet Co. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt Lithuanian news portal Chinese web portal 163. It is operated by NetEase, a company which 163.com pioneered the development of Internet in China. 17173.com Website distributing Chinese games. 17u.com Chinese online travel booking website. 20 minutes is a free, daily newspaper available in France, Spain and 20minutes Switzerland. This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Shared 2shared is an online space for sharing and storage. -
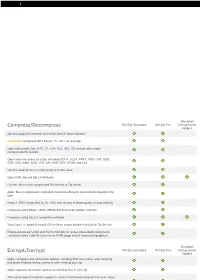
Compress/Decompress Encrypt/Decrypt
Windows Compress/Decompress WinZip Standard WinZip Pro Compressed Folders Zip and unzip files instantly with 64-bit, best-in-class software ENHANCED! Compress MP3 files by 15 - 20 % on average Open and extract Zipx, RAR, 7Z, LHA, BZ2, IMG, ISO and all other major compression file formats Open more files types as a Zip, including DOCX, XLSX, PPTX, XPS, ODT, ODS, ODP, ODG,WMZ, WSZ, YFS, XPI, XAP, CRX, EPUB, and C4Z Use the super picker to unzip locally or to the cloud Open CAB, Zip and Zip 2.0 Methods Convert other major compressed file formats to Zip format Apply 'Best Compression' method to maximize efficiency automatically based on file type Reduce JPEG image files by 20 - 25% with no loss of photo quality or data integrity Compress using BZip2, LZMA, PPMD and Enhanced Deflate methods Compress using Zip 2.0 compatible methods 'Auto Open' a zipped Microsoft Office file by simply double-clicking the Zip file icon Employ advanced 'Unzip and Try' functionality to review interrelated components contained within a Zip file (such as an HTML page and its associated graphics). Windows Encrypt/Decrypt WinZip Standard WinZip Pro Compressed Folders Apply encryption and conversion options, including PDF conversion, watermarking and photo resizing, before, during or after creating your zip Apply separate conversion options to individual files in your zip Take advantage of hardware support in certain Intel-based computers for even faster AES encryption Administrative lockdown of encryption methods and password policies Check 'Encrypt' to password protect your files using banking-level encryption and keep them completely secure Secure sensitive data with strong, FIPS-197 certified AES encryption (128- and 256- bit) Auto-wipe ('shred') temporarily extracted copies of encrypted files using the U.S. -

Inside Dropbox: Understanding Personal Cloud Storage Services
Inside Dropbox: Understanding Personal Cloud Storage Services → Idilio Drago → Marco Mellia → Maurizio M. Munafo` → Anna Sperotto → Ramin Sadre → Aiko Pras IRTF – Vancouver Motivation and goals 1 Personal cloud storage services are already popular Dropbox in 2012 “the largest deployed networked file system in history” “over 50 million users – one billion files every 48 hours” Little public information about the system How does Dropbox work? What are the potential performance bottlenecks? Are there typical usage scenarios? Methodology – How does Dropbox work? 2 Public information Native client, Web interface, LAN-Sync etc. Files are split in chunks of up to 4 MB Delta encoding, deduplication, encrypted communication To understand the client protocol MITM against our own client Squid proxy, SSL-bump and a self-signed CA certificate Replace a trusted CA certificate in the heap at run-time Proxy logs and decrypted packet traces How does Dropbox (v1.2.52) work? 3 Clear separation between storage and meta-data/client control Sub-domains identifying parts of the service sub-domain Data-center Description client-lb/clientX Dropbox Meta-data notifyX Dropbox Notifications api Dropbox API control www Dropbox Web servers d Dropbox Event logs dl Amazon Direct links dl-clientX Amazon Client storage dl-debugX Amazon Back-traces dl-web Amazon Web storage api-content Amazon API Storage HTTP/HTTPs in all functionalities How does Dropbox (v1.2.52) work? 4 Notification Kept open Not encrypted Device ID Folder IDs How does Dropbox (v1.2.52) work? 4 Client control Login File hash Meta-data How does Dropbox (v1.2.52) work? 4 Storage Amazon EC2 Retrieve vs. -

Secure Data Sharing in the Cloud
Eivind Nordal Gran Secure data sharing in the cloud Eivind Nordal Gran Eivind Nordal Master’s thesis in Communication Technology Supervisor: Colin Alexander Boyd, Gareth Thomas Davies & Clementine Gritti June 2019 Master’s thesis Master’s Secure data sharing in the cloud data Secure NTNU Engineering Communication Technology Communication Department of Information Security and Department of Information Faculty of Information Technology and Electrical Technology of Information Faculty Norwegian University of Science and Technology of Science University Norwegian Eivind Nordal Gran Secure data sharing in the cloud Master’s thesis in Communication Technology Supervisor: Colin Alexander Boyd, Gareth Thomas Davies & Clementine Gritti June 2019 Norwegian University of Science and Technology Faculty of Information Technology and Electrical Engineering Department of Information Security and Communication Technology Problem description: Data sharing using cloud platforms has become increasingly more popular over the last few years. With the increase in use comes a heightened demand for security and privacy. This project will conduct a thorough study of a key transport proto- col developed at NTNU, which targets strong security as its preeminent property, including a form of forward secrecy. More specifically, it will investigate how this escalation in security level affects the performance and usability of the protocol. How will the new protocol designed with security as its primary concern compare against other already established schemes when it comes to efficiency and practicality? Abstract Cloud sharing security is an important topic in today’s society. The majority of the most common cloud sharing solutions require that the user trust the Cloud Service Provider (CSP) to protect and conceal uploaded data. -

Lock-Free Collaboration Support for Cloud Storage Services With
Lock-Free Collaboration Support for Cloud Storage Services with Operation Inference and Transformation Jian Chen, Minghao Zhao, and Zhenhua Li, Tsinghua University; Ennan Zhai, Alibaba Group Inc.; Feng Qian, University of Minnesota - Twin Cities; Hongyi Chen, Tsinghua University; Yunhao Liu, Michigan State University & Tsinghua University; Tianyin Xu, University of Illinois Urbana-Champaign https://www.usenix.org/conference/fast20/presentation/chen This paper is included in the Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST ’20) February 25–27, 2020 • Santa Clara, CA, USA 978-1-939133-12-0 Open access to the Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST ’20) is sponsored by Lock-Free Collaboration Support for Cloud Storage Services with Operation Inference and Transformation ⇤ 1 1 1 2 Jian Chen ⇤, Minghao Zhao ⇤, Zhenhua Li , Ennan Zhai Feng Qian3, Hongyi Chen1, Yunhao Liu1,4, Tianyin Xu5 1Tsinghua University, 2Alibaba Group, 3University of Minnesota, 4Michigan State University, 5UIUC Abstract Pattern 1: Losing updates Alice is editing a file. Suddenly, her file is overwritten All studied This paper studies how today’s cloud storage services support by a new version from her collaborator, Bob. Sometimes, cloud storage collaborative file editing. As a tradeoff for transparency/user- Alice can even lose her edits on the older version. services friendliness, they do not ask collaborators to use version con- Pattern 2: Conflicts despite coordination trol systems but instead implement their own heuristics for Alice coordinates her edits with Bob through emails to All studied handling conflicts, which however often lead to unexpected avoid conflicts by enforcing a sequential order. -

Photos Copied" Box
Our photos have never been as scattered as they are now... Do you know where your photos are? Digital Photo Roundup Checklist www.theswedishorganizer.com Online Storage Edition Let's Play Digital Photo Roundup! Congrats on making the decision to start organizing your digital photos! I know the task can seem daunting, so hopefully this handy checklist will help get your moving in the right direction. LET'S ORGANIZE! To start organizing your digital photos, you must first gather them all into one place, so that you'll be able to sort and edit your collection. Use this checklist to document your family's online storage accounts (i.e. where you have photos saved online), and whether they are copied onto your Master hub (the place where you are saving EVERYTHING). It'll make the gathering process a whole lot easier if you keep a record of what you have already copied and what is still to be done. HERE'S HOW The services in this checklist are categorized, so that you only need to print out what applies to you. If you have an account with the service listed, simply check the "Have Account" box. When you have copied all the photos, check the "Photos Copied" box. Enter your login credentials under the line between the boxes for easy retrieval. If you don't see your favorite service on the list, just add it to one of the blank lines provided after each category. Once you are done, you should find yourself with all your digital images in ONE place, and when you do, check back on the blog for tools to help you with the next step in the organizing process. -
Online Backup & Sync
Online Backup & Sync Access all your Tresorit folders and files securely in your computer’s file browser, regardless of whether you synced it or not. Store & backup your files securely in the cloud Tresorit's end-to-end encrypted online storage solution extends the space on your local drive and protects your files in the cloud. Only you and those who you share with can access the content. • Extend your hard drive: Integrate Tresorit Drive to your local file manager to upload and access files without storing them locally. • Selective sync: Define which subfolders you want to keep synced on your device. Keep control how much space you use on your local drive. • Version recovery: Store and roll back to any previous version of your files. “Tresorit integrates very well into the system. You don't really have to do much about it. It simply works.” - Christian Zeyer, Co-Managing Director at Swisscleantech Upload your existing folder Upload & Sync Recover older versions of structure automatically files Keep the way you organize your Tresorit updates your files in Keep track of changes by your files when you upload them to the real-time and automatically adds collaborators, solve version cloud. No need to change what is any edits you make to the cloud. conflicts and use unlimited file already on your computer. Backup You can access the latest version versioning to roll back to any & Sync only takes a few clicks. of your data from any device. previous version. “After a partner's Dropbox account “Documents we place into Tresorit “Our most sensitive data are the ideas was compromised, switching to appear immediately on the client’s of our clients, so solving version Tresorit couldn't have been simpler laptop. -

4-BAY RACKMOUNT NAS Technical Specifications
4-BAY RACKMOUNT NAS Technical Specifications Operating System Seagate® NAS OS (embedded Linux) Number of Drive Bays 4 hot-swappable 3.5-inch SATA II/SATA III Processor Dual-core 2.13GHz Intel® 64-bit Atom™ processor Memory 2GB DDR III Networking Two (2) 10/100/1000 Base-TX (Gigabit Ethernet) • Two (2) USB 3.0 (rear) • Two (2) USB 2.0 (rear) External Ports • One (1) eSATA (rear) • One (1) USB 2.0 (front) Hard Drive Capacity Seagate NAS HDD 2TB, 3TB, 4TB for preconfigured models Total Capacity 4TB, 8TB, 12TB, 16TB Compatible Drives 3.5-inch SATA II or SATA III (see NAS Certified Drive list PDF for more details) Power 100V to 240V AC, 50/60Hz, 180W Power Supply and • Sleep mode for power saving • Scheduled power on/off Power Management • Wake-on-LAN Cooling Management Two (2) fans Transfer Rate 200MB/s reads and writes1 Network Protocols CIFS/SMB, NFS v3, AFP, HTTP(s), FTP, sFTP, iSCSI, Print serve, failover and load balancing and Services (LACP 802.3ad), Wuala file system integration (W:/ network drive), Active Directory™ • RAID 0, 1, 5, 6, 10 RAID • Hot spare • SimplyRAID™ technology with mixed capacity support, volume expansion and migration • Web-based interface through http/https • Hardware monitoring (S.M.A.R.T., casing cooling and temperature, CPU and RAM load) Management • Log management and email notification • NAS OS Installer for diskless setup, data recovery and restore to factory settings • Product discovery with Seagate Network Assistant 1 Tested in RAID 5 configuration utilizing load balancing for Ethernet ports. Actual performance may vary depending on system environment. -

The Application Usage and Risk Report an Analysis of End User Application Trends in the Enterprise
The Application Usage and Risk Report An Analysis of End User Application Trends in the Enterprise 8th Edition, December 2011 Palo Alto Networks 3300 Olcott Street Santa Clara, CA 94089 www.paloaltonetworks.com Table of Contents Executive Summary ........................................................................................................ 3 Demographics ............................................................................................................................................. 4 Social Networking Use Becomes More Active ................................................................ 5 Facebook Applications Bandwidth Consumption Triples .......................................................................... 5 Twitter Bandwidth Consumption Increases 7-Fold ................................................................................... 6 Some Perspective On Bandwidth Consumption .................................................................................... 7 Managing the Risks .................................................................................................................................... 7 Browser-based Filesharing: Work vs. Entertainment .................................................... 8 Infrastructure- or Productivity-Oriented Browser-based Filesharing ..................................................... 9 Entertainment Oriented Browser-based Filesharing .............................................................................. 10 Comparing Frequency and Volume of Use -

Building Large-Scale Distributed Applications on Top of Self-Managing Transactional Stores
Building large-scale distributed applications on top of self-managing transactional stores June 3, 2010 Peter Van Roy with help from SELFMAN partners Overview Large-scale distributed applications Application structure: multi-tier with scalable DB backend Distribution structure: peer-to-peer or cloud-based DHTs and transactions Basics of DHTs Data replication and transactions Scalaris and Beernet Programming model and applications CompOz library and Kompics component model DeTransDraw and Distributed Wikipedia Future work Mobile applications, cloud computing, data-intensive computing Programming abstractions for large-scale distribution Application structure What can be a general architecture for large-scale distributed applications? Start with a database backend (e.g., IBM’s “multitier”) Make it distributed with distributed transactional interface Keep strong consistency (ACID properties) Allow large numbers of concurrent transactions Horizontal scalability is the key Vertical scalability is a dead end “NoSQL”: Buzzword for horizontally scalable databases that typically don’t have a complete SQL interface Key/value store or column-oriented ↑ our choice (simplicity) The NoSQL Controversy NoSQL is a current trend in non-relational databases May lack table schemas, may lack ACID properties, no join operations Main advantages are excellent performance, with good horizontal scalability and elasticity (ideal fit to clouds) SQL databases have good vertical scalability but are not elastic Often only weak consistency guarantees, such as eventual consistency (e.g., Google BigTable) Some exceptions: Cassandra also provides strong consistency, Scalaris and Beernet provide a key-value store with transactions and strong consistency Distribution structure Two main infrastructures for large-scale applications Peer-to-peer: use of client machines ← our choice (loosely coupled) Very popular style, e.g., BitTorrent, Skype, Wuala, etc. -

Chapter 14 This Presentation Covers
Basic Operating Systems Chapter 14 This presentation covers: > Staying Current >Basic Operating Systems Overview > Command Prompts Qualities of a Good Technician “Soft skills” as they are known across many industries are essential Staying Current Benefits of staying current include: >(1) understanding and troubleshooting the latest technologies > (2) recommending upgrades or solutions to customers > (3) saving time troubleshooting (and time is money) > (4) being someone considered for a promotion Staying Current A variety of methods to stay current include: >Subscribe to a magazine or an online magazine > Subscribe to a news list that gives you an update in your email > Join or attend association meetings >Register for and attend a seminar > Attend an online webinar > Take a class > Read books > Talk to your department peers and supervisor Basic Operating Systems Overview Basic Operating Systems > Computers require software to operate >An operating system (OS) is software that coordinates the interaction between hardware and any software applications and the interaction between a user and the computer >An operating system can be a graphical user interface (GUI) or a command line interface, or both > It is responsible for handling file and disk management Popular Operating Systems > Microsoft Windows >Apple macOS > Linux > Chrome OS > Android (mobile) > Apple iOS (mobile) 32- vs 64-bit Operating Systems Windows 7 Editions Windows 10 Editions End-of-Life Concerns > Serious consequences if an operating system or application has reached its -

Snapchat Dropbox
LOS ANGELES | SAN FRANCISCO | NEW YORK | BOSTON | SEATTLE | MINNEAPOLIS | MILWAUKEE July 15, 2013 Michael Pachter Steve Koenig (213) 688-4474 (415) 274-6801 [email protected] [email protected] PRISM … Progress Report for Internet and Social Media In This Issue: Snapchat, Dropbox Snapchat Developer of the popular photo-messaging app, founded in 2011. Application allows photos to be sent between users. Photos can only be viewed for a few seconds, then self-delete. App has experienced rapid adoption, with 200 million pictures sent per day, up from 150 million in April of this year. Valuation has risen significantly, from approximately $70 million in February 2013 to $800 million today. Founders now in legal battle with a schoolmate claiming to be a third founder. Popularity may represent a cultural shift to less-permanent, more anonymous web services. Dropbox Announced at developer conference its intention to create a data platform for developers. Introduced new tools for deeper application integration. User count rises to 175 million from 100 million in November of last year. About Wedbush Securities Private Shares Group The Private Shares Group of Wedbush Securities is a leader in providing research and trading to the rapidly growing industry of privately traded securities, with an emphasis on companies in the social media space. We assist companies in raising growth capital through traditional private placements and provide liquidity options for existing and former employees through tailored selling programs. We also work with venture capital, private equity and hedge fund investors to help them adjust their holdings in some of the most dynamic companies.