A Quaternion Gated Recurrent Unit Neural Network for Sensor Fusion
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Data Science Initiative 1
Data Science Initiative 1 3 credits in data and computational science, 1 credit in societal implications and opportunities, Data Science Initiative 1 elective credit to be drawn from a wide range of focused applications or deeper theoretical exploration, and 1 credit capstone experience. Director We also offer an option as a 5-th Year Master's Program if you are an Sohini Ramachandran undergraduate at Brown. This allows you to substitute maximally 2 credits Direfctor of Graduate Studies with courses you have already taken. Samuel S. Watson Master of Science in Data Science Brown University's Data Science Initiative serves as a campus hub Semester I for research and education in data science. Engaging partners across DATA 1010 Probability, Statistics, and Machine 2 campus and beyond, the DSI 's mission is to facilitate and conduct both Learning domain-driven and fundamental research in data science, increase data DATA 1030 Hands-on Data Science 1 fluency and educate the next generation of data scientists, and ultimately DATA 1050 Data Engineering 1 explore the impact of the data revolution on culture, society, and social justice. We envision our role in the university and beyond as something to Semester II build over time, with the flexibility to meet the changing needs of Brown’s DATA 2020 Statistical Learning 1 students and research community. DATA 2040 Deep Learning and Special Topics in Data 1 The Master’s Program in Data Science (Master of Science, Science ScM) prepares students from a wide range of disciplinary backgrounds DATA 2080 Data and Society 1 for distinctive careers in data science. -

Data Science (ML-DL-Ai)
Data science (ML-DL-ai) Statistics Multiple Regression Model Building and Evaluation Introduction to Statistics Model post fitting for Inference Types of Statistics Examining Residuals Analytics Methodology and Problem- Regression Assumptions Solving Framework Identifying Influential Observations Populations and samples Detecting Collinearity Parameter and Statistics Uses of variable: Dependent and Categorical Data Analysis Independent variable Describing categorical Data Types of Variable: Continuous and One-way frequency tables categorical variable Association Cross Tabulation Tables Descriptive Statistics Test of Association Probability Theory and Distributions Logistic Regression Model Building Picturing your Data Multiple Logistic Regression and Histogram Interpretation Normal Distribution Skewness, Kurtosis Model Building and scoring for Outlier detection Prediction Introduction to predictive modelling Inferential Statistics Building predictive model Scoring Predictive Model Hypothesis Testing Introduction to Machine Learning and Analytics Analysis of variance (ANOVA) Two sample t-Test Introduction to Machine Learning F-test What is Machine Learning? One-way ANOVA Fundamental of Machine Learning ANOVA hypothesis Key Concepts and an example of ML ANOVA Model Supervised Learning Two-way ANOVA Unsupervised Learning Regression Linear Regression with one variable Exploratory data analysis Model Representation Hypothesis testing for correlation Cost Function Outliers, Types of Relationship, -

Data Science: the Big Picture Data Science with R Exploratory Data Analysis with R Data Visualization with R (3-Part)
Deep Learning: The Future of AI @MatthewRenze #DevoxxUK Human Cat Dog Car Job Postings for Machine Learning Source: Indeed.com Average Salary by Job Type (USA) $108,000 $101,000 $100,000 Source: Stack Overflow 2017 What is deep learning? What can it do for me? How do I get started? What is deep learning? Deep Learning Deep Learning Artificial intelligence Machine learning Neural network Multiple hidden layers Hierarchical representations Makes predictions with data Deep Learning Artificial intelligence Machine learning Neural network Multiple hidden layers Hierarchical representations Makes predictions with data Artificial Machine Deep Intelligence Learning Learning Artificial Intelligence Explicit programming Explicit programming Encoding domain knowledge Explicit programming Encoding domain knowledge Statistical patterns detection Machine Learning Machine Learning Artificial Machine Statistics Intelligence Learning 푓 푥 푓 푥 Prediction Data Function 푓 푥 Prediction Data Function Cat Dog 푓 푥 Prediction Data Function Cat Dog Is cat? 푓 푥 Prediction Data Function Cat Dog Is cat? Yes Artificial Neuron 푥1 푥2 푦 푥3 inputs neuron outputs Artificial Neuron Σ Artificial Neuron Σ Artificial Neuron 휔1 휔2 휔3 Artificial Neuron 휔0 Artificial Neuron 휔0 휔1 휔2 휔3 Artificial Neuron 푥 1 휔0 휔1 푥2 휑 휔2 Σ 푦 푚 휔3 푥3 푦푘 = 휑 푤푘푗푥푗 푗=0 Artificial Neural Network Artificial Neural Network input hidden output Artificial Neural Network Forward propagation Artificial Neural Network Forward propagation Backward propagation Artificial Neural Network Artificial Neural Network -

Explainable Deep Learning Models in Medical Image Analysis
Journal of Imaging Review Explainable Deep Learning Models in Medical Image Analysis Amitojdeep Singh 1,2,* , Sourya Sengupta 1,2 and Vasudevan Lakshminarayanan 1,2 1 Theoretical and Experimental Epistemology Laboratory, School of Optometry and Vision Science, University of Waterloo, Waterloo, ON N2L 3G1, Canada; [email protected] (S.S.); [email protected] (V.L.) 2 Department of Systems Design Engineering, University of Waterloo, Waterloo, ON N2L 3G1, Canada * Correspondence: [email protected] Received: 28 May 2020; Accepted: 17 June 2020; Published: 20 June 2020 Abstract: Deep learning methods have been very effective for a variety of medical diagnostic tasks and have even outperformed human experts on some of those. However, the black-box nature of the algorithms has restricted their clinical use. Recent explainability studies aim to show the features that influence the decision of a model the most. The majority of literature reviews of this area have focused on taxonomy, ethics, and the need for explanations. A review of the current applications of explainable deep learning for different medical imaging tasks is presented here. The various approaches, challenges for clinical deployment, and the areas requiring further research are discussed here from a practical standpoint of a deep learning researcher designing a system for the clinical end-users. Keywords: explainability; explainable AI; XAI; deep learning; medical imaging; diagnosis 1. Introduction Computer-aided diagnostics (CAD) using artificial intelligence (AI) provides a promising way to make the diagnosis process more efficient and available to the masses. Deep learning is the leading artificial intelligence (AI) method for a wide range of tasks including medical imaging problems. -

An Overview of Deep Learning Strategies for Time Series Prediction
An Overview of Deep Learning Strategies for Time Series Prediction Rodrigo Neves Instituto Superior Tecnico,´ Lisboa, Portugal [email protected] June 2018 Abstract—Deep learning is getting a lot of attention in the last Jenkins methodology [2] and were developed mainly in the few years, mainly due to the state-of-the-art results obtained in area of econometrics and statistics. different areas like object detection, natural language processing, Driven by the rise of popularity and attention in the area sequential modeling, among many others. Time series problems are a special case of sequential data, where deep learning models of deep learning, due to the state-of-the-art results obtained can be applied. The standard option to this type of problems in several areas, Artificial Neural Networks (ANN), which are are Recurrent Neural Networks (RNNs), but recent results are non-linear function approximator, have also been receiving an supporting the idea that Convolutional Neural Networks (CNNs) increasing attention in time series field. This rise of popularity can also be applied to time series with good results. This raises is associated with the breakthroughs achieved in this area, with the following question - Which are the best attributes and architectures to apply in time series prediction problems? It was the successful application of CNNs and RNNs to sequential assessed which is the current state on deep learning applied to modeling problems, with promising results [3]. RNNs are a time-series and studied which are the most promising topologies type of artificial neural networks that were specially designed and characteristics on sequential tasks that are worth it to to deal with sequential tasks, and thus can be used on time be explored. -

Reinforcement Learning Data Science Africa 2018 Abuja, Nigeria (12 Nov - 16 Nov 2018)
Reinforcement Learning Data Science Africa 2018 Abuja, Nigeria (12 Nov - 16 Nov 2018) Chika Yinka-Banjo, PhD Ayorkor Korsah, PhD University of Lagos Ashesi University Nigeria Ghana Outline • Introduction to Machine learning • Reinforcement learning definitions • Example reinforcement learning problems • The Markov decision process • The optimal policy • Value function & Q-value function • Bellman Equation • Q-learning • Building a simple Q-learning agent (coding) • Recap • Where to go from here? Introduction to Machine learning • Artificial Intelligence (AI) is the study and design of Intelligent agents. • An Intelligent agent can perceive its environment through sensors and it can act on its environment through actuators. • E.g. Agent: Humanoid robot • Environment: Earth? • Sensors: Camera, tactile sensor etc. • Actuators: Motors, grippers etc. • Machine learning is a subfield of Artificial Intelligence Branches of AI Introduction to Machine learning • Machine learning techniques learn from data without being explicitly programmed to do so. • Machine learning models enable the agent to learn from its own experience by extracting useful information from feedback from its environment. • Three types of learning feedback: • Supervised learning • Unsupervised learning • Reinforcement learning Branches of Machine learning Supervised learning • Supervised learning: the machine learning model is trained on many labelled examples of input-output pairs. • Such that when presented with a novel input, the model can estimate accurately what the correct output should be. • Data(x, y): x is input data, y is label Supervised learning task in the form of classification • Goal: learn a function to map x -> y • Examples include; Classification, regression object detection, image captioning etc. Unsupervised learning • Unsupervised learning: here the model extract useful information from unlabeled and unstructured data. -
Improving Gated Recurrent Unit Predictions with Univariate Time Series Imputation Techniques
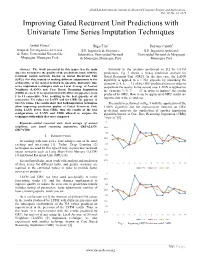
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 10, No. 12, 2019 Improving Gated Recurrent Unit Predictions with Univariate Time Series Imputation Techniques 1 Anibal Flores Hugo Tito2 Deymor Centty3 Grupo de Investigación en Ciencia E.P. Ingeniería de Sistemas e E.P. Ingeniería Ambiental de Datos, Universidad Nacional de Informática, Universidad Nacional Universidad Nacional de Moquegua Moquegua, Moquegua, Perú de Moquegua, Moquegua, Perú Moquegua, Perú Abstract—The work presented in this paper has its main Similarly to the analysis performed in [1] for LSTM objective to improve the quality of the predictions made with the predictions, Fig. 1 shows a 14-day prediction analysis for recurrent neural network known as Gated Recurrent Unit Gated Recurrent Unit (GRU). In the first case, the LANN (GRU). For this, instead of making different adjustments to the algorithm is applied to a 1 NA gap-size by rebuilding the architecture of the neural network in question, univariate time elements 2, 4, 6, …, 12 of the GRU-predicted series in order to series imputation techniques such as Local Average of Nearest outperform the results. In the second case, LANN is applied for Neighbors (LANN) and Case Based Reasoning Imputation the elements 3, 5, 7, …, 13 in order to improve the results (CBRi) are used. It is experimented with different gap-sizes, from produced by GRU. How it can be appreciated GRU results are 1 to 11 consecutive NAs, resulting in the best gap-size of six improve just in the second case. consecutive NA values for LANN and for CBRi the gap-size of two NA values. -

Sentiment Analysis with Gated Recurrent Units
Advances in Computer Science and Information Technology (ACSIT) Print ISSN: 2393-9907; Online ISSN: 2393-9915; Volume 2, Number 11; April-June, 2015 pp. 59-63 © Krishi Sanskriti Publications http://www.krishisanskriti.org/acsit.html Sentiment Analysis with Gated Recurrent Units Shamim Biswas1, Ekamber Chadda2 and Faiyaz Ahmad3 1,2,3Department of Computer Engineering Jamia Millia Islamia New Delhi, India E-mail: [email protected], 2ekamberc @gmail.com, [email protected] Abstract—Sentiment analysis is a well researched natural language learns word embeddings from unlabeled text samples. It learns processing field. It is a challenging machine learning task due to the both by predicting the word given its surrounding recursive nature of sentences, different length of documents and words(CBOW) and predicting surrounding words from given sarcasm. Traditional approaches to sentiment analysis use count or word(SKIP-GRAM). These word embeddings are used for frequency of words in the text which are assigned sentiment value by some expert. These approaches disregard the order of words and the creating dictionaries and act as dimensionality reducers in complex meanings they can convey. Gated Recurrent Units are recent traditional method like tf-idf etc. More approaches are found form of recurrent neural network which have the ability to store capturing sentence level representations like recursive neural information of long term dependencies in sequential data. In this tensor network (RNTN) [2] work we showed that GRU are suitable for processing long textual data and applied it to the task of sentiment analysis. We showed its Convolution neural network which has primarily been used for effectiveness by comparing with tf-idf and word2vec models. -

An Artificial Neural Networks Primer with Financial Applications Examples in Financial Distress Predictions and Foreign Exchange Hybrid Trading System ’
‘An Artificial Neural Networks Primer with Financial Applications Examples in Financial Distress Predictions and Foreign Exchange Hybrid Trading System ’ by Dr Clarence N W Tan, PhD Bachelor of Science in Electrical Engineering Computers (1986), University of Southern California, Los Angeles, California, USA Master of Science in Industrial and Systems Engineering (1989), University of Southern California Los Angeles, California, USA Masters of Business Administration (1989) University of Southern California Los Angeles, California, USA Graduate Diploma in Applied Finance and Investment (1996) Securities Institute of Australia Diploma in Technical Analysis (1996) Australian Technical Analysts Association Doctor of Philosophy Bond University (1997) URL: http://w3.to/ctan/ E-mail: [email protected] School of Information Technology, Bond University, Gold Coast, QLD 4229, Australia Table of Contents Table of Contents 1. INTRODUCTION TO ARTIFICIAL INTELLIGENCE AND ARTIFICIAL NEURAL NETWORKS ..........................................................................................................................................2 1.1 INTRODUCTION ...........................................................................................................................2 1.2 ARTIFICIAL INTELLIGENCE ..........................................................................................................2 1.3 ARTIFICIAL INTELLIGENCE IN FINANCE .......................................................................................4 1.3.1 Expert System -
![Lecture 23: Recurrent Neural Network [SCS4049-02] Machine Learning and Data Science](https://docslib.b-cdn.net/cover/5074/lecture-23-recurrent-neural-network-scs4049-02-machine-learning-and-data-science-675074.webp)
Lecture 23: Recurrent Neural Network [SCS4049-02] Machine Learning and Data Science
Lecture 23: Recurrent Neural Network [SCS4049-02] Machine Learning and Data Science Seongsik Park ([email protected]) AI Department, Dongguk University Tentative schedule week topic date (수 / 월) 1 Machine Learning Introduction & Basic Mathematics 09.02 / 09.07 2 Python Practice I & Regression 09.09 / 09.14 3 AI Department Seminar I & Clustering I 09.16 / 09.21 4 Clustering II & Classification I 09.23 / 09.28 5 Classification II (추석) / 10.05 6 Python Practice II & Support Vector Machine I 10.07 / 10.12 7 Support Vector Machine II & Decision Tree and Ensemble Learning 10.14 / 10.19 8 Mid-Term Practice & Mid-Term Exam 10.21 / 10.26 9 휴강 & Dimensional Reduction I 10.28 / 11.02 10 Dimensional Reduction II & Neural networks and Back Propagation I 11.04 / 11.09 11 Neural networks and Back Propagation II & III 11.11 / 11.16 12 AI Department Seminar II & Convolutional Neural Network 11.18 / 11.23 13 Python Practice III & Recurrent Neural network 11.25 / 11.30 14 Model Optimization & Autoencoders 12.02 / 12.07 15 Final exam (휴강)/ 12.14 1/22 Introduction of recurrent neural network (RNN) • Rumelhart, et. al., Learning Internal Representations by Error Propagation (1986) • fx(1); :::; x(t−1); x(t); x(t+1); :::; x(N)g와 같은 sequence를 처리하는데 특화 • RNN 은 긴 시퀀스를 처리할 수 있으며, 길이가 변동적인 시퀀스도 처리 가능 • Parameter sharing: 전체 sequence에서 파라미터를 공유함 • CNN은 시퀀스를 다룰 수 없나? • 시간 축으로 1-D convolution ) 시간 지연 신경망도 가능하지만 깊이가 얕음 (shallow) • RNN은 깊은 구조(deep)가 가능함 • Data type • 일반적으로 xt 는 시계열 데이터 (time series, temporal data) • 여기서 t = 1; 2; :::; N은 time step 또는 sequence 내에서의 순서 • 전체 길이 N은 변동적 2/22 Recurrent Neurons Up to now we have mostly looked at feedforward neural networks, where the activa‐ tions flow only in one direction, from the input layer to the output layer (except for a few networks in Appendix E). -

Budgeted Reinforcement Learning in Continuous State Space
Budgeted Reinforcement Learning in Continuous State Space Nicolas Carrara∗ Edouard Leurent∗ SequeL team, INRIA Lille – Nord Europey SequeL team, INRIA Lille – Nord Europey [email protected] Renault Group, France [email protected] Romain Laroche Tanguy Urvoy Microsoft Research, Montreal, Canada Orange Labs, Lannion, France [email protected] [email protected] Odalric-Ambrym Maillard Olivier Pietquin SequeL team, INRIA Lille – Nord Europe Google Research - Brain Team [email protected] SequeL team, INRIA Lille – Nord Europey [email protected] Abstract A Budgeted Markov Decision Process (BMDP) is an extension of a Markov Decision Process to critical applications requiring safety constraints. It relies on a notion of risk implemented in the shape of a cost signal constrained to lie below an – adjustable – threshold. So far, BMDPs could only be solved in the case of finite state spaces with known dynamics. This work extends the state-of-the-art to continuous spaces environments and unknown dynamics. We show that the solution to a BMDP is a fixed point of a novel Budgeted Bellman Optimality operator. This observation allows us to introduce natural extensions of Deep Reinforcement Learning algorithms to address large-scale BMDPs. We validate our approach on two simulated applications: spoken dialogue and autonomous driving3. 1 Introduction Reinforcement Learning (RL) is a general framework for decision-making under uncertainty. It frames the learning objective as the optimal control of a Markov Decision Process (S; A; P; Rr; γ) S×A with measurable state space S, discrete actions A, unknown rewards Rr 2 R , and unknown dynamics P 2 M(S)S×A , where M(X ) denotes the probability measures over a set X . -

Jesford Senior Data Scientist
JesFord Senior Data Scientist contact profile [email protected] Experienced Data Scientist with a passion for applied machine learning and open source soft- linkedin.com/in/jesford ware. I bring a practical product driven mindset, an obsession with best practices, and a 206.446.6874 demonstrated ability to collaborate effectively across teams to achieve goals. I am a regular website conference speaker at events including PyCon, PluralsightLIVE, and VisInPractice. jesford.github.io experience GitHub 2018–current Recursion Salt Lake City, UT @jesford Senior Data Scientist 11/2019–current Data Scientist 4/2018–11/2019 tech skills • Trained, optimized, and benchmarked deep neural networks (CNNs and Python graph NNs) to solve problems in drug discovery. pandas, numpy, scipy, • Technical lead on teams that productionized the first machine learning pytorch, keras, xgboost, models at Recursion, responsible for directing a small team of data sci- scikit-learn, jupyter, entists, and providing regular updates to VPs. seaborn, matplotlib, prefect, dash, plotly • Model interpretability including saliency maps, GradCAM, DeepDream. • Pioneered use of MCMC for Bayesian parameter fitting of experimental Git & GitHub data, and developed new visualizations to inform biologists. Bash • Active Learning for improving class imbalance & minimizing model bias. SQL • Owned creation of cleaned & standardized labelsets from noisy data, en- C/C++ abling comparison of ML models across data science teams. Travis-CI • Designed & built custom Google Cloud database for storing ML models, AWS & GCP metrics, labels, and predictions; created resources for data science users. Sphinx • Led data science team to adopt software best practices for reproducible HTML/CSS research and clean production quality code.