Deriving Photometric Redshifts Using Fuzzy Archetypes and Self-Organizing Maps
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Quantitative Morphology of Galaxies in the Core of the Coma Cluster
To appear in Astrophys. Journal Quantitative Morphology of Galaxies in the Core of the Coma Cluster Carlos M. Guti´errez, Ignacio Trujillo1, Jose A. L. Aguerri Instituto de Astrof´ısica de Canarias, E-38205, La Laguna, Tenerife, Spain Alister W. Graham Department of Astronomy, University of Florida, Gainesville, Florida, USA and Nicola Caon Instituto de Astrof´ısica de Canarias, E-38205, La Laguna, Tenerife, Spain ABSTRACT We present a quantitative morphological analysis of 187 galaxies in a region covering the central 0.28 square degrees of the Coma cluster. Structural param- eters from the best-fitting S´ersic r1/n bulge plus, where appropriate, exponential disc model, are tabulated here. This sample is complete down to a magnitude of R=17 mag. By examining the Edwards et al. (2002) compilation of galaxy redshifts in the direction of Coma, we find that 163 of the 187 galaxies are Coma arXiv:astro-ph/0310527v1 19 Oct 2003 cluster members, and the rest are foreground and background objects. For the Coma cluster members, we have studied differences in the structural and kine- matic properties between early- and late-type galaxies, and between the dwarf and giant galaxies. Analysis of the elliptical galaxies reveals correlations among the structural parameters similar to those previously found in the Virgo and Fornax clusters. Comparing the structural properties of the Coma cluster disc galaxies with disc galaxies in the field, we find evidence for an environmental dependence: the scale lengths of the disc galaxies in Coma are 30% smaller. A kinematical analysis shows marginal differences between the velocity distri- butions of ellipticals with S´ersic index n < 2 (dwarfs) and those with n > 2 1Present address: Max–Planck–Institut f¨ur Astronomie, K¨onigstuhl 17, D–69117, Heidelberg, Germany –2– (giants); the dwarf galaxies having a greater (cluster) velocity dispersion. -

Spatially Resolved Spectroscopy of Coma Cluster Early–Type Galaxies
ASTRONOMY & ASTROPHYSICS FEBRUARY I 2000, PAGE 449 SUPPLEMENT SERIES Astron. Astrophys. Suppl. Ser. 141, 449–468 (2000) Spatially resolved spectroscopy of Coma cluster early–type galaxies I. The database ? D. Mehlert1,2,??,???,????, R.P. Saglia1,R.Bender1,andG.Wegner3 1 Universit¨atssternwarte M¨unchen, 81679 M¨unchen, Germany 2 Present address: Landessternwarte Heidelberg, 69117 Heidelberg, Germany 3 Department of Physics and Astronomy, 6127 Wilder Laboratory, Dartmouth College, Hanover, NH 03755-3528, U.S.A. Received March 8; accepted September 30, 1999 Abstract. We present long slit spectra for a magnitude Key words: galaxies: elliptical and lenticular, cD; limited sample of 35 E and S0 galaxies of the Coma cluster. kinematics and dynamics; stellar content; abundances; The high quality of the data allowed us to derive spatially formation resolved spectra for a substantial sample of Coma galaxies for the first time. From these spectra we obtained rota- tion curves, the velocity dispersion profiles and the H3 and H4 coefficients of the Hermite decomposition of the 1. Introduction line of sight velocity distribution. Moreover, we derive the radial line index profiles of Mg, Fe and Hβ line indices This is the first of a series of papers aiming at investi- out to R ≈ 1re − 3re with high signal-to-noise ratio. We gating the stellar populations, the radial distribution and describe the galaxy sample, the observations and data re- the dynamics of early-type galaxies as a function of the duction, and present the spectroscopic database. Ground- environmental density. Spanning about 4 decades in den- based photometry for a subsample of 8 galaxies is also sity, the Coma cluster is the ideal place to perform such a presented. -

Coma Cluster Object Populations Down to M R~-9.5
Astronomy & Astrophysics manuscript no. astrophadami c ESO 2018 November 5, 2018 ⋆ Coma cluster object populations down to MR ∼ −9.5 C. Adami1, J.P. Picat2, F. Durret3,4, A. Mazure1, R. Pell´o2, and M. West5,6 1 LAM, Traverse du Siphon, 13012 Marseille, France 2 Observatoire Midi-Pyr´en´ees, 14 Av. Edouard Belin, 31400 Toulouse, France 3 Institut d’Astrophysique de Paris, CNRS, Universit´ePierre et Marie Curie, 98bis Bd Arago, 75014 Paris, France 4 Observatoire de Paris, LERMA, 61 Av. de l’Observatoire, 75014 Paris, France 5 Department of Physics and Astronomy, University of Hawaii, 200 West Kawili Street, LS2, Hilo HI 96720-4091, USA 6 Gemini Observatory, Casilla 603, La Serena, Chile Accepted . Received ; Draft printed: November 5, 2018 ABSTRACT Context. This study follows a recent analysis of the galaxy luminosity functions and colour-magnitude red sequences in the Coma cluster (Adami et al. 2007). Aims. We analyze here the distribution of very faint galaxies and globular clusters in an east-west strip of ∼ 42 × 7 arcmin2 crossing the Coma cluster center (hereafter the CS strip) down to the unprecedented faint absolute magnitude of MR ∼−9.5. Methods. This work is based on deep images obtained at the CFHT with the CFH12K camera in the B, R, and I bands. Results. The analysis shows that the observed properties strongly depend on the environment, and thus on the cluster history. When the CS is divided into four regions, the westernmost region appears poorly populated, while the regions around the brightest galaxies NGC 4874 and NGC 4889 (NGC 4874 and NGC 4889 being masked) are dominated by faint blue galaxies. -

Ngc Catalogue Ngc Catalogue
NGC CATALOGUE NGC CATALOGUE 1 NGC CATALOGUE Object # Common Name Type Constellation Magnitude RA Dec NGC 1 - Galaxy Pegasus 12.9 00:07:16 27:42:32 NGC 2 - Galaxy Pegasus 14.2 00:07:17 27:40:43 NGC 3 - Galaxy Pisces 13.3 00:07:17 08:18:05 NGC 4 - Galaxy Pisces 15.8 00:07:24 08:22:26 NGC 5 - Galaxy Andromeda 13.3 00:07:49 35:21:46 NGC 6 NGC 20 Galaxy Andromeda 13.1 00:09:33 33:18:32 NGC 7 - Galaxy Sculptor 13.9 00:08:21 -29:54:59 NGC 8 - Double Star Pegasus - 00:08:45 23:50:19 NGC 9 - Galaxy Pegasus 13.5 00:08:54 23:49:04 NGC 10 - Galaxy Sculptor 12.5 00:08:34 -33:51:28 NGC 11 - Galaxy Andromeda 13.7 00:08:42 37:26:53 NGC 12 - Galaxy Pisces 13.1 00:08:45 04:36:44 NGC 13 - Galaxy Andromeda 13.2 00:08:48 33:25:59 NGC 14 - Galaxy Pegasus 12.1 00:08:46 15:48:57 NGC 15 - Galaxy Pegasus 13.8 00:09:02 21:37:30 NGC 16 - Galaxy Pegasus 12.0 00:09:04 27:43:48 NGC 17 NGC 34 Galaxy Cetus 14.4 00:11:07 -12:06:28 NGC 18 - Double Star Pegasus - 00:09:23 27:43:56 NGC 19 - Galaxy Andromeda 13.3 00:10:41 32:58:58 NGC 20 See NGC 6 Galaxy Andromeda 13.1 00:09:33 33:18:32 NGC 21 NGC 29 Galaxy Andromeda 12.7 00:10:47 33:21:07 NGC 22 - Galaxy Pegasus 13.6 00:09:48 27:49:58 NGC 23 - Galaxy Pegasus 12.0 00:09:53 25:55:26 NGC 24 - Galaxy Sculptor 11.6 00:09:56 -24:57:52 NGC 25 - Galaxy Phoenix 13.0 00:09:59 -57:01:13 NGC 26 - Galaxy Pegasus 12.9 00:10:26 25:49:56 NGC 27 - Galaxy Andromeda 13.5 00:10:33 28:59:49 NGC 28 - Galaxy Phoenix 13.8 00:10:25 -56:59:20 NGC 29 See NGC 21 Galaxy Andromeda 12.7 00:10:47 33:21:07 NGC 30 - Double Star Pegasus - 00:10:51 21:58:39 -

Galaxy Aggregates in the Coma Cluster
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by CERN Document Server Galaxy Aggregates in the Coma Cluster Christopher J. Conselice1 and John S. Gallagher III Department of Astronomy, University of Wisconsin, Madison, 475 N. Charter St., Madison, WI., 54706 ABSTRACT We present evidence for a new morphologically defined form of small-scale substructure in the Coma Cluster, which we call galaxy aggregates. These aggregates are dominated by a central galaxy, which is on average three magnitudes brighter than the smaller aggregate members, nearly all of which lie to one side of the central galaxy. We have found three such galaxy aggregates dominated by the S0 galaxies RB 55, RB 60, and the star-bursting SBb, NGC 4858. RB 55 and RB 60 are both equi-distant between the two dominate D galaxies NGC 4874 and NGC 4889, while NGC 4858 is located next to the larger E0 galaxy NGC 4860. All three central galaxies have redshifts consistent with Coma Cluster membership. We describe the spatial structures of these unique objects and suggest several possible mechanisms to explain their origin. These include: chance superpositions from background galaxies, interactions between other galaxies and with the cluster gravitational potential, and ram pressure. We conclude that the most probable scenario of creation is an interaction with the cluster through its potential. Subject headings: galaxies - clusters - individual (Coma, Abell 1656) : galaxies - formation : galaxies- interactions. 1. INTRODUCTION Due to its proximity and high density, the Coma Cluster is a good location to investigate evolutionary effects in galaxy clusters, and for deriving certain cosmological parameters (Crone et al. -

Mapping the Universe: Improving Photometric Redshift Accuracy and Computational Efficiency
Mapping the Universe: Improving Photometric Redshift Accuracy and Computational Efficiency A Thesis Presented by Joshua S. Speagle Submitted to The Department of Astronomy in partial fulfilment of the requirements for the degree of Bachelor of Arts Thesis Advisor: Daniel J. Eisenstein April 11, 2015 Mapping the Universe: Improving Photometric Redshift Accuracy and Computational Efficiency Joshua S. Speagle1;2 Abstract Correctly modeling and fitting the spectral energy distributions (SED) of galaxies is a crucial component of extracting accurate and reliable photometric redshifts (photo-z’s) from large-scale extragalactic photometric surveys. However, most codes today are unable to derive photo-z’s to the required precision needed for future surveys such as Euclid in feasible amounts of time. To better understand the general features an improved photo-z search should possess, we characterize the shape of the photo-z likelihood surface for several objects with a pre-generated grid of ∼ 2 million elements, finding that most surfaces are significantly “bumpy” with gradients dominated by large degeneracies outside the region(s) of peak probability. Based on these results, we design an algorithm to efficiently explore pre-computed grids that combines a swarm intelligence version of a Markov Chain Monte Carlo (MCMC)-driven approach with simulated annealing. Using a mock catalog of ∼ 380,000 COSMOS galaxies, we show that our new algorithm is at least 40 – 50 times more efficient compared to standard grid-based counterparts while retaining equivalent accuracy. Following this, we develop a new perturbative approach to generating SEDs from a set of “baseline” photometry that can rapidly generate photometry from continuous changes in redshift, reddening, and emission line strengths to sub-percent level accuracy. -

QUANTITATIVE MORPHOLOGY of GALAXIES in the CORE of the COMA CLUSTER Carlos M
The Astrophysical Journal, 602:664–677, 2004 February 20 A # 2004. The American Astronomical Society. All rights reserved. Printed in U.S.A. QUANTITATIVE MORPHOLOGY OF GALAXIES IN THE CORE OF THE COMA CLUSTER Carlos M. Gutie´rrez, Ignacio Trujillo,1 and Jose A. L. Aguerri Instituto de Astrofı´sica de Canarias, E-38205, La Laguna, Tenerife, Spain Alister W. Graham Department of Astronomy, University of Florida, Gainesville, FL 32611 and Nicola Caon Instituto de Astrofı´sica de Canarias, E-38205, La Laguna, Tenerife, Spain Received 2003 July 26; accepted 2003 October 17 ABSTRACT We present a quantitative morphological analysis of 187 galaxies in a region covering the central 0.28 deg2 of the Coma Cluster. Structural parameters from the best-fitting Se´rsic r1=n bulge plus, where appropriate, expo- nential disk model, are tabulated here. This sample is complete down to a magnitude of R ¼ 17 mag. By examining the recent compilation by Edwards et al. of galaxy redshifts in the direction of Coma, we find that 163 of the 187 galaxies are Coma Cluster members and that the rest are foreground and background objects. For the Coma Cluster members, we have studied differences in the structural and kinematic properties between early- and late-type galaxies and between the dwarf and giant galaxies. Analysis of the elliptical galaxies reveals correlations among the structural parameters similar to those previously found in the Virgo and Fornax Clusters. Comparing the structural properties of the Coma Cluster disk galaxies with disk galaxies in the field, we find evidence for an environmental dependence: the scale lengths of the disk galaxies in Coma are 30% smaller. -

Cover Illustration by JE Mullat the BIG BANG and the BIG CRUNCH
Cover Illustration by J. E. Mullat THE BIG BANG AND THE BIG CRUNCH From Public Domain: designed by Luke Mastin OBSERVATIONS THAT SEEM TO CONTRADICT THE BIG BANG MODEL WHILE AT THE SAME TIME SUPPORT AN ALTERNATIVE COSMOLOGY Forrest W. Noble, Timothy M. Cooper The Pantheory Research Organization Cerritos, California 90703 USA HUBBLE-INDEPENDENT PROCEDURE CALCULATING DISTANCES TO COSMOLOGICAL OBJECTS Joseph E. Mullat Project and Technical Editor: J. E. Mullat, Copenhagen 2019 ISBN‐13 978‐8740‐40‐411‐1 Private Publishing Platform Byvej 269 2650, Hvidovre, Denmark [email protected] The Postulate COSMOLOGY THAT CONTRADICTS THE BIG BANG THEORY The Standard and The Alternative Cosmological Models, Distances Calculation to Galaxies without Hubble Constant For the alternative cosmological models discussed in the book, distances are calculated for galaxies without using the Hubble constant. This proc‐ ess is mentioned in the second narrative and is described in detail in the third narrative. According to the third narrative, when the energy den‐ sity of space in the universe decreases, and the universe expands, a new space is created by a gravitational transition from dark energy. Although the Universe develops on the basis of this postulate about the appear‐ ance of a new space, it is assumed that matter arises as a result of such a gravitational transition into both new dark space and visible / baryonic matter. It is somewhat unimportant how we describe dark energy, call‐ ing it ether, gravitons, or vice versa, turning ether into dark energy. It should be clear to everyone that this renaming does not change the es‐ sence of this gravitational transition. -

The Distribution of Dark Matter and Stellar Orbits in Nine Coma Early-Type Galaxies Derived from Their Stellar Kinematics Jens Thomas
The distribution of dark matter and stellar orbits in nine Coma early-type galaxies derived from their stellar kinematics Jens Thomas M¨unchen 2006 The distribution of dark matter and stellar orbits in nine Coma early-type galaxies derived from their stellar kinematics Jens Thomas Dissertation an der Fakult¨at f¨ur Physik der Ludwig–Maximilians–Universit¨at M¨unchen vorgelegt von Jens Thomas aus Essen M¨unchen, den 05.04.2006 Erstgutachter: Prof. Dr. Ralf Bender Zweitgutachter: Prof. Dr. Ortwin Gerhard Tag der m¨undlichen Pr¨ufung: 27.10.2006 Contents Zusammenfassung xv 1 Introduction 1 1.1 General motivation .......................... 1 1.2 Dynamical modelling of early-type galaxies ............ 4 1.3 The orbit superposition technique .................. 7 1.4 State of affairs ............................ 9 1.5 Aims and structure of the thesis .................. 12 2 Mapping distribution functions by orbit superpositions 15 2.1 Introduction .............................. 15 2.2 The orbit library ........................... 17 2.2.1 Spatial and velocity binning ................. 18 2.2.2 Orbital properties ...................... 18 2.2.3 Choice of orbits ........................ 19 2.2.4 Use of the library ....................... 22 2.3 Orbital weights and phase-space densities ............. 22 2.3.1 Phase-space densities of orbits ............... 23 2.3.2 Orbital weights from DFs .................. 23 2.4 Orbital phase volumes ........................ 24 2.5 Mapping distribution functions onto the library .......... 28 2.5.1 Spherical γ-models ...................... 29 2.5.2 Flattened Plummer model .................. 32 2.5.3 Changing the spatial coverage of the library ........ 34 2.5.4 Changing the number of orbits in the library ....... 36 2.6 Fitting the library ......................... -
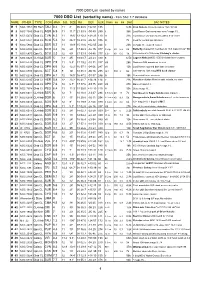
DSO List V2 Current
7000 DSO List (sorted by name) 7000 DSO List (sorted by name) - from SAC 7.7 database NAME OTHER TYPE CON MAG S.B. SIZE RA DEC U2K Class ns bs Dist SAC NOTES M 1 NGC 1952 SN Rem TAU 8.4 11 8' 05 34.5 +22 01 135 6.3k Crab Nebula; filaments;pulsar 16m;3C144 M 2 NGC 7089 Glob CL AQR 6.5 11 11.7' 21 33.5 -00 49 255 II 36k Lord Rosse-Dark area near core;* mags 13... M 3 NGC 5272 Glob CL CVN 6.3 11 18.6' 13 42.2 +28 23 110 VI 31k Lord Rosse-sev dark marks within 5' of center M 4 NGC 6121 Glob CL SCO 5.4 12 26.3' 16 23.6 -26 32 336 IX 7k Look for central bar structure M 5 NGC 5904 Glob CL SER 5.7 11 19.9' 15 18.6 +02 05 244 V 23k st mags 11...;superb cluster M 6 NGC 6405 Opn CL SCO 4.2 10 20' 17 40.3 -32 15 377 III 2 p 80 6.2 2k Butterfly cluster;51 members to 10.5 mag incl var* BM Sco M 7 NGC 6475 Opn CL SCO 3.3 12 80' 17 53.9 -34 48 377 II 2 r 80 5.6 1k 80 members to 10th mag; Ptolemy's cluster M 8 NGC 6523 CL+Neb SGR 5 13 45' 18 03.7 -24 23 339 E 6.5k Lagoon Nebula;NGC 6530 invl;dark lane crosses M 9 NGC 6333 Glob CL OPH 7.9 11 5.5' 17 19.2 -18 31 337 VIII 26k Dark neb B64 prominent to west M 10 NGC 6254 Glob CL OPH 6.6 12 12.2' 16 57.1 -04 06 247 VII 13k Lord Rosse reported dark lane in cluster M 11 NGC 6705 Opn CL SCT 5.8 9 14' 18 51.1 -06 16 295 I 2 r 500 8 6k 500 stars to 14th mag;Wild duck cluster M 12 NGC 6218 Glob CL OPH 6.1 12 14.5' 16 47.2 -01 57 246 IX 18k Somewhat loose structure M 13 NGC 6205 Glob CL HER 5.8 12 23.2' 16 41.7 +36 28 114 V 22k Hercules cluster;Messier said nebula, no stars M 14 NGC 6402 Glob CL OPH 7.6 12 6.7' 17 37.6 -03 15 248 VIII 27k Many vF stars 14.. -

1977Apj. . .213. .327A the Astrophysical Journal, 213:327-344
.327A .213. The Astrophysical Journal, 213:327-344, 1977 April 15 . © 1977. The American Astronomical Society. All rights reserved. Printed in U.S.A. 1977ApJ. THE LUMINOSITY FUNCTION AND STRUCTURE OF THE COMA CLUSTER G. O. Abell Department of Astronomy, University of California, Los Angeles Received 1976 August 6 ABSTRACT The luminosity function of the galaxies in the Coma cluster is determined by a procedure of extrafocal photographic photometry. The logarithmic integrated luminosity function rises sharply with increasing magnitude through the interval mv = 11.6 to 14.5, and then slowly for greater magnitudes to the limit mv = 19.4. The data suggest a moderate increase in the slope of the function for magnitudes fainter than mv = 17.5. The cluster is found, in projection, to be ellipsoidal in shape, centered at (1950) a = 12h56IP9; 0 5 = +28 14'. To the limit mv = 18.3 the cluster is estimated to have 1525 member galaxies. The brighter galaxies in the inner part of the cluster have a distribution resembling that of the iso- thermal polytrope, but there is no marked segregation of bright and faint galaxies, as would be required for complete statistical equilibrium. The luminosity of the cluster is estimated at 2 x 1013 L©. The mass-to-light ratio (in solar units) is found probably not to exceed 122. Subject headings: galaxies : clusters of—galaxies: photometry I. INTRODUCTION II. OBSERVATIONS The first important discussion of the galaxian a) Photometric Procedure luminosity function was by Hubble (1926), who Galaxian magnitudes are obtained here by a investigated the absolute magnitudes of 134 late method of extrafocal photographic photometry spirals and 11 irregular galaxies (most of which are described by Abell and Mihalas (1966). -

Spatially Resolved Spectroscopy of Coma Cluster Early–Type Galaxies
Dartmouth College Dartmouth Digital Commons Dartmouth Scholarship Faculty Work 2-1-2000 Spatially Resolved Spectroscopy of Coma Cluster Early–Type Galaxies D. Mehlert Universitäts-Sternwarte München R. P. Saglia Universitäts-Sternwarte München R. Bender Universitäts-Sternwarte München G. Wegner Dartmouth College Follow this and additional works at: https://digitalcommons.dartmouth.edu/facoa Part of the Stars, Interstellar Medium and the Galaxy Commons Dartmouth Digital Commons Citation Mehlert, D.; Saglia, R. P.; Bender, R.; and Wegner, G., "Spatially Resolved Spectroscopy of Coma Cluster Early–Type Galaxies" (2000). Dartmouth Scholarship. 541. https://digitalcommons.dartmouth.edu/facoa/541 This Article is brought to you for free and open access by the Faculty Work at Dartmouth Digital Commons. It has been accepted for inclusion in Dartmouth Scholarship by an authorized administrator of Dartmouth Digital Commons. For more information, please contact [email protected]. ASTRONOMY & ASTROPHYSICS FEBRUARY I 2000, PAGE 449 SUPPLEMENT SERIES Astron. Astrophys. Suppl. Ser. 141, 449–468 (2000) Spatially resolved spectroscopy of Coma cluster early–type galaxies I. The database ? D. Mehlert1,2,??,???,????, R.P. Saglia1,R.Bender1,andG.Wegner3 1 Universit¨atssternwarte M¨unchen, 81679 M¨unchen, Germany 2 Present address: Landessternwarte Heidelberg, 69117 Heidelberg, Germany 3 Department of Physics and Astronomy, 6127 Wilder Laboratory, Dartmouth College, Hanover, NH 03755-3528, U.S.A. Received March 8; accepted September 30, 1999 Abstract. We present long slit spectra for a magnitude Key words: galaxies: elliptical and lenticular, cD; limited sample of 35 E and S0 galaxies of the Coma cluster. kinematics and dynamics; stellar content; abundances; The high quality of the data allowed us to derive spatially formation resolved spectra for a substantial sample of Coma galaxies for the first time.