IBM Centers for Advanced Studies : CASCON
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SMART: Making DB2 (More) Autonomic
SMART: Making DB2 (More) Autonomic Guy M. Lohman Sam S. Lightstone IBM Almaden Research Center IBM Toronto Software Lab K55/B1, 650 Harry Rd. 8200 Warden Ave. San Jose, CA 95120-6099 Markham, L6G 1C7 Ontario U.S.A. Canada [email protected] [email protected] Abstract The database community has already made many significant contributions toward autonomic systems. IBM’s SMART (Self-Managing And Resource Separating the logical schema from the physical schema, Tuning) project aims to make DB2 self- permitting different views of the same data by different managing, i.e. autonomic, to decrease the total applications, and the entire relational model of data, all cost of ownership and penetrate new markets. simplified the task of building new database applications. Over several releases, increasingly sophisticated Declarative query languages such as SQL, and the query SMART features will ease administrative tasks optimizers that made them possible, further aided such as initial deployment, database design, developers. But with the exception of early research in system maintenance, problem determination, and the late 1970s and early 1980s on database design ensuring system availability and recovery. algorithms, little has been done to help the beleaguered database administrator (DBA) until quite recently, with 1. Motivation for Autonomic Databases the founding of the AutoAdmin project at Microsoft [http://www.research.microsoft.com/dmx/autoadmin/] and While Moore’s Law and competition decrease the per-unit the SMART project at IBM, described herein. cost of hardware and software, the shortage of skilled professionals that can comprehend the growing complexity of information technology (IT) systems 2. -

Minutes of the January 25, 2010, Meeting of the Board of Regents
MINUTES OF THE JANUARY 25, 2010, MEETING OF THE BOARD OF REGENTS ATTENDANCE This scheduled meeting of the Board of Regents was held on Monday, January 25, 2010, in the Regents’ Room of the Smithsonian Institution Castle. The meeting included morning, afternoon, and executive sessions. Board Chair Patricia Q. Stonesifer called the meeting to order at 8:31 a.m. Also present were: The Chief Justice 1 Sam Johnson 4 John W. McCarter Jr. Christopher J. Dodd Shirley Ann Jackson David M. Rubenstein France Córdova 2 Robert P. Kogod Roger W. Sant Phillip Frost 3 Doris Matsui Alan G. Spoon 1 Paul Neely, Smithsonian National Board Chair David Silfen, Regents’ Investment Committee Chair 2 Vice President Joseph R. Biden, Senators Thad Cochran and Patrick J. Leahy, and Representative Xavier Becerra were unable to attend the meeting. Also present were: G. Wayne Clough, Secretary John Yahner, Speechwriter to the Secretary Patricia L. Bartlett, Chief of Staff to the Jeffrey P. Minear, Counselor to the Chief Justice Secretary T.A. Hawks, Assistant to Senator Cochran Amy Chen, Chief Investment Officer Colin McGinnis, Assistant to Senator Dodd Virginia B. Clark, Director of External Affairs Kevin McDonald, Assistant to Senator Leahy Barbara Feininger, Senior Writer‐Editor for the Melody Gonzales, Assistant to Congressman Office of the Regents Becerra Grace L. Jaeger, Program Officer for the Office David Heil, Assistant to Congressman Johnson of the Regents Julie Eddy, Assistant to Congresswoman Matsui Richard Kurin, Under Secretary for History, Francisco Dallmeier, Head of the National Art, and Culture Zoological Park’s Center for Conservation John K. -

2011 Results 2011 Résultats Canadian Senior and Intermediate
The CENTRE for EDUCATION in MATHEMATICS and COMPUTING Le CENTRE d'EDUCATION´ en MATHEMATIQUES´ et en INFORMATIQUE www.cemc.uwaterloo.ca 2011 2011 Results R´esultats Canadian Senior and Intermediate Mathematics Contests Concours canadiens de math´ematiques de niveau sup´erieuret interm´ediaire c 2012 University of Waterloo Competition Organization Organisation du Concours Centre for Education in Mathematics and Computing Faculty and Staff / Personnel du Concours canadien de math´ematiques Ed Anderson Terry Bae Steve Brown Ersal Cahit Karen Cole Serge D'Alessio Frank DeMaio Jennifer Doucet Fiona Dunbar Mike Eden Barry Ferguson Barb Forrest Judy Fox Steve Furino John Galbraith Sandy Graham Angie Hildebrand Judith Koeller Joanne Kursikowski Bev Marshman Dean Murray Jen Nissen J.P. Pretti Linda Schmidt Kim Schnarr Jim Schurter Carolyn Sedore Ian VanderBurgh Troy Vasiga Problems Committees / Comit´esdes probl`emes Canadian Senior Mathematics Contest / Concours canadien de niveau sup´erieur Mike Eden (Chair / pr´esident), University of Waterloo, Waterloo, ON Kee Ip, Crescent School, Toronto, ON Paul Leistra, Guido de Bres Christian H.S., Hamilton, ON Daryl Tingley, University of New Brunswick, Fredericton, NB Joe West, University of Waterloo, Waterloo, ON Bruce White, Windsor, ON Canadian Intermediate Mathematics Contest / Concours canadien de niveau interm´ediaire John Galbraith (Chair / pr´esident), University of Waterloo, Waterloo, ON Ed Barbeau, Toronto, ON Alison Cornthwaite, Lo-Ellen Park S.S., Sudbury, ON Brian McBain, North Lambton S.S., Forest, ON Ginger Moorey, Abbey Park H.S., Oakville, ON Dean Murray, University of Waterloo, Waterloo, ON 2 Foreword Avant-Propos The Centre for Education in Mathematics and Computing is pleased to announce the results of the 2011 Canadian Senior and Intermediate Mathematics Contests. -

Onsite Program
2015 ASAP Global Alliance Summit Collaboration at the Core: Forging the Future of Partnering Onsite Program March 2 – 5, 2015 Orlando, Florida Hyatt Regency Orlando www.strategic-alliances.org/summit +1-774-256-1401 Platinum Sponsor Gold Sponsor Silver Sponsors Table of Contents Welcome to the 2015 ASAP Global Alliance Summit . .3 ASAP Executive Committee & Management Board & ASAP Program Committee . .4 Social Media Outlets & ASAP Global Staff . .5 Conference Agenda . .6 ASAP Global Members & Corporate Members . .11 Summit Sponsor Recognition . .12 ASAP Executive, Management & Advisory Board of Directors . .13 Overview of Sessions . .14 Alliance Excellence Awards Finalists . .16 Pre-Conference Professional Development Workshops . .18 Monday Session Descriptions . .21 Tuesday Session Descriptions . .22 Wednesday Session Descriptions . .27 Alliance Management Resource Center . .34 Conference Speakers . .36 2015 ASAP BioPharma Conference Call For Topics . .51 Floor Plan . .53 2 Stay up to date at www.strategic-alliances.org I March 2 – 5, 2015 I Orlando, Florida USA Welcome to the 2015 ASAP Global Alliance Summit On behalf of the Board of Directors and staff of the Association of Strategic Alliance Professionals, welcome to our 2015 Global Alliance Summit. We invite you to take the next three days to learn, engage, and experience the best the profession has to offer! We invite you to fully participate in this highly interactive experience where the learning comes as much from those assembled as from the many top-flight speakers and discussion leaders. Connect with your peers, partners, and industry executives to learn how others are confronting the challenges of our ever-changing business environment and forging the future of partnering. -

The X-Internet Invigorates Supply Chain Collaboration
AnalystAnalyst OutlookOutlook COLLABORATION5 http://radjou.ASCET.com Navi Radjou The X-Internet Invigorates Forrester Research Supply Chain Collaboration The X-Internet – an executable and extended Internet built from Rapid responses to unforeseen events. Web- post-Web technologies – will transform online collaboration based B2B apps like e-procurement rely on a between supply chain partners. rule-based workflow engine to automate rou- tine transactions between partners. But they’re not designed to let firms actively find Global firms pin big hopes on the Internet’s the world has changed: Empowered customers unplanned events like delayed parts or a capabilities to connect them with customers are more fickle and competitors challenge suc- looming equipment failure in a contractor’s and suppliers. For example, 84 percent of busi- cessful new products more quickly. Firms have plant, let alone resolve them in real time. To nesses surveyed by NAPM/Forrester in come to rely more on partners to improve their provide preemptive customer support and October 2001 view the Internet as a critical ele- supply net performance and customer service. continually optimize asset usage, firms need ment of their purchasing strategy. Many firms To meet the new realities of B2B collaboration, to sense and respond to unforeseen events are stepping up investments in business appli- business apps need to support: without human intervention. cations (apps) that promise to move their Rich, real-time collaboration. Web- offline supply chain transactions to the Web. anchored supply chain apps like those from The X-Internet Reshapes But so far, these Web-centric B2B apps have Manugistics Group can’t rapidly reflect Supply Chain Collaboration failed to deliver the promised benefits because changes in partners’ production schedules Since its birth 30 years ago, the Internet has they are undependable and sluggish. -

2008 Results Pascal Contest Cayley Contest Fermat Contest 2008
Canadian Concours Mathematics canadien de Competition math´ematiques An activity of the Centre for Une activit´edu Centre d’´education Education in Mathematics and Computing, en math´ematiques et en informatique, University of Waterloo, Waterloo, Ontario Universit´ede Waterloo, Waterloo, Ontario 2008 2008 Results R´esultats Pascal Contest Concours Pascal (Grade 9) (9e ann´ee– Sec. III) Cayley Contest Concours Cayley (Grade 10) (10e ann´ee– Sec. IV) Fermat Contest Concours Fermat (Grade 11) (11e ann´ee– Sec. V) C.M.C. Sponsors C.M.C. Supporter Chartered Accountants c 2008 Centre for Education in Mathematics and Computing Competition Organization Organisation du Concours Centre for Education in Mathematics and Computing Faculty and Staff / Personnel du Concours canadien de math´ematiques Ed Anderson Lloyd Auckland Terry Bae Janet Baker Steve Brown Jennifer Couture Fiona Dunbar Jeff Dunnett Mike Eden Barry Ferguson Judy Fox Sandy Graham Angie Hildebrand Judith Koeller Joanne Kursikowski Dean Murray J.P. Pretti Linda Schmidt Kim Schnarr Jim Schurter Carolyn Sedore Ian VanderBurgh Troy Vasiga 2 Competition Organization Organisation du Concours Problems Committees / Comit´esdes probl`emes Pascal Contest / Concours Pascal Wally Webster (Chair / pr´esident), Exeter, ON Lloyd Auckland, Waterloo, ON Janet Christ, Walter Murray C.I., Saskatoon, SK Nerissa Coronel, St. Marguerite d’Youville C.S.S., Brampton, ON JP Pretti, University of Waterloo, Waterloo, ON Jim Schurter, University of Waterloo, Waterloo, ON Tyler Somer, Kitchener, ON Anna Spanik, -

2013 Canadian Computing Competition Results
2013 Canadian Computing Competition Results Sponsor: 1 Comments Commentaires The 2013 CCC was another year of change. In a way similar to 2012, the averages this year were very good, reinforcing that both the Junior and Senior competitions are approachable for the majority of students. Again, there is a large clump of Junior competitors who acheived 60/75, which is a very good score. We launched a live version of the on-line CCC grader (expanding from the pilot version in 2012) that about half of the competitors registered for this year. With a few glitches now sorted out (including Java memory errors and timing issues), I think the on-line grader will become the de-facto standard for contest writers, due to the feedback it provides. We will still allow teachers and students to choose to grade off-line, but the selection of languages (C, C++, Pascal, Java, Python, Perl and PHP) will hopefully cover the vast majority of competitors. Again, if students want to learn Python, check out the CS Cirlces On-line Resource at: cscircles.cemc.uwaterloo.ca We continued the collaboration with Tsinghua University in Beijing and the University of Hong Kong to offer the contest to Beijing and Hong Kong high school students. More information (including results) can be found at: http://ccc.cs.tsinghua.edu.cn/ and http://www.cs.hku.hk/ccc2013/. As in previous years, the organizers from Tsinghua and HKU collaborated with UW to create a contest different than the Canadian CCC. Below, a qualitative summary of both the Junior and Senior contest is presented. -
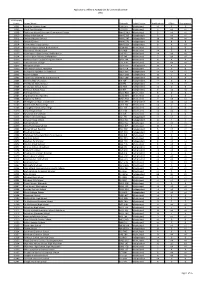
2009 Admissions Cycle
Applications, Offers & Acceptances by UCAS Apply Centre 2009 UCAS Apply Centre School Name Postcode School Sector Applications Offers Acceptances 10001 Ysgol Syr Thomas Jones LL68 9TH Maintained <4 0 0 10002 Ysgol David Hughes LL59 5SS Maintained 4 <4 <4 10008 Redborne Upper School and Community College MK45 2NU Maintained 5 <4 <4 10010 Bedford High School MK40 2BS Independent 7 <4 <4 10011 Bedford Modern School MK41 7NT Independent 18 <4 <4 10012 Bedford School MK40 2TU Independent 20 8 8 10014 Dame Alice Harpur School MK42 0BX Independent 8 4 <4 10018 Stratton Upper School, Bedfordshire SG18 8JB Maintained 5 0 0 10020 Manshead School, Luton LU1 4BB Maintained <4 0 0 10022 Queensbury Upper School, Bedfordshire LU6 3BU Maintained <4 <4 <4 10024 Cedars Upper School, Bedfordshire LU7 2AE Maintained 7 <4 <4 10026 St Marylebone Church of England School W1U 5BA Maintained 8 4 4 10027 Luton VI Form College LU2 7EW Maintained 12 <4 <4 10029 Abingdon School OX14 1DE Independent 15 4 4 10030 John Mason School, Abingdon OX14 1JB Maintained <4 0 0 10031 Our Lady's Abingdon Trustees Ltd OX14 3PS Independent <4 <4 <4 10032 Radley College OX14 2HR Independent 15 7 6 10033 The School of St Helen & St Katharine OX14 1BE Independent 22 9 9 10035 Dean College of London N7 7QP Independent <4 0 0 10036 The Marist Senior School SL57PS Independent <4 <4 <4 10038 St Georges School, Ascot SL5 7DZ Independent <4 0 0 10039 St Marys School, Ascot SL5 9JF Independent 6 <4 <4 10041 Ranelagh School RG12 9DA Maintained 8 0 0 10043 Ysgol Gyfun Bro Myrddin SA32 8DN Maintained -

2008 2008 Results R´Esultats
Canadian Concours Mathematics canadien de Competition math´ematiques An activity of the Centre for Une activit´edu Centre d’´education Education in Mathematics and Computing, en math´ematiques et en informatique, University of Waterloo, Waterloo, Ontario Universit´ede Waterloo, Waterloo, Ontario 2008 2008 Results R´esultats Fryer Contest Concours Fryer (Grade 9) (9e ann´ee– Sec. III) Galois Contest Concours Galois (Grade 10) (10e ann´ee– Sec. IV) Hypatia Contest Concours Hypatie (Grade 11) (11e ann´ee– Sec. V) C.M.C. Sponsors C.M.C. Supporter Chartered Accountants c 2008 Centre for Education in Mathematics and Computing Competition Organization Organisation du Concours Centre for Education in Mathematics and Computing Faculty and Staff / Personnel du Centre d’´education en math´ematiques et informatique Ed Anderson Lloyd Auckland Terry Bae Janet Baker Steve Brown Jennifer Couture Fiona Dunbar Jeff Dunnett Mike Eden Barry Ferguson Judy Fox Sandy Graham Angie Hildebrand Judith Koeller Joanne Kursikowski Dean Murray J.P. Pretti Linda Schmidt Kim Schnarr Jim Schurter Carolyn Sedore Ian VanderBurgh Troy Vasiga Problems Committee / Comit´edes probl`emes Judith Koeller (Chair / pr´esident), University of Waterloo, Waterloo, ON Peter Crippin, Havergal College, Toronto, ON Rad de Peiza, Toronto, ON Sandy Emms Jones, Forest Heights C.I., Kitchener, ON Barry Ferguson, University of Waterloo, Waterloo, ON Nerissa Coronel, St. Marguertie d’Youville Catholic S.S., Mississauga, ON Andr´eLadouceur, Gloucester, ON Peter O’Hara, Glendale H.S., Tilsonburg, ON Alex Pintilie, Crescent School, Toronto, ON Judy Shanks, Pickering H.S., Ajax, ON 2 Comments on the Papers Commentaires sur les ´epreuves Overall Comments The year 2008 marked the sixth writings of the Fryer, Galois and Hypatia Contests. -

Security Server RACF System Programmer's Guide
z/OS Version 2 Release 3 Security Server RACF System Programmer's Guide IBM SA23-2287-30 Note Before using this information and the product it supports, read the information in “Notices” on page 365. This edition applies to Version 2 Release 3 of z/OS (5650-ZOS) and to all subsequent releases and modifications until otherwise indicated in new editions. Last updated: 2019-02-16 © Copyright International Business Machines Corporation 1994, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents List of Figures....................................................................................................... xi List of Tables.......................................................................................................xiii About this document............................................................................................xv Intended audience..................................................................................................................................... xv Where to find more information................................................................................................................. xv RACF courses........................................................................................................................................ xv Other sources of information.................................................................................................................... xvi Internet sources...................................................................................................................................xvi -

Toronto Regional Showcase 2017
Toronto Regional Showcase 2017 April 6, 7 and 8 Hart House Theatre University of Toronto Page 1 Welcomes you to the Regional Showcase of the 71st Annual Sears Ontario Drama Festival! Sears Canada is proud to sponsor this exceptional event and to celebrate remarkable achievements in the arts by talented students, such as those you will see on the stage this evening. These performances are a reflection of the dedicated and talented students and teachers in the drama programs of our Ontario high schools. The Sears Charitable Foundation is a registered Canadian charity focused on the development of children and youth in areas of both health and education. The health component is centered on raising awareness and providing funds for research and treatment for the fight against childhood cancer. The education component is centered on after-school programs and initiatives such as the Sears Ontario Drama Festival, which enrich young people’s lives and allow them to reach their full potential. Please consider making a donation and help us continue to provide meaningful experiences. Together, we can make a difference in the lives of young people. Visit www.searsfoundation.ca Page 2 Welcome... to the 71st Toronto Regional Showcase of the Sears Ontario Drama Festival. The nine productions that you will see during the three evenings of the Showcase represent outstanding achievement in high school theatre from the three Toronto District Festivals. The presentations are accompanied by public and private adjudications that expand the participating students’ -

The Complete IMS HALDB Guide All You Need to Know to Manage Haldbs
Front cover The Complete IMS HALDB Guide All You Need to Know to Manage HALDBs Examine how to migrate databases to HALDB Explore the benefits of using HALDB Learn how to administer and modify HALDBs Jouko Jäntti Cornelia Hallmen Raymond Keung Rich Lewis ibm.com/redbooks International Technical Support Organization The Complete IMS HALDB Guide All You Need to Know to Manage HALDBs June 2003 SG24-6945-00 Note: Before using this information and the product it supports, read the information in “Notices” on page xi. First Edition (June 2003) This edition applies to IMS Version 7 (program number 5655-B01) and IMS Version 8 (program number 5655-C56) or later for use with the OS/390 or z/OS operating system. © Copyright International Business Machines Corporation 2003. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . .xi Trademarks . xii Preface . xiii The team that wrote this redbook. xiii Become a published author . xiv Comments welcome. xv Part 1. HALDB overview . 1 Chapter 1. HALDB introduction and structure . 3 1.1 An introduction to High Availability Large Databases . 4 1.2 Features and benefits . 5 1.3 Candidates for HALDB . 6 1.4 HALDB definition process . 7 1.4.1 Database Recovery Control (DBRC) . 9 1.5 DL/I processing . 9 1.6 Logical relationships with HALDB . 10 1.7 Partition selection . 10 1.7.1 Partition selection using key ranges . 10 1.7.2 Partition selection using a partition selection exit routine .